Found a total of 15 related content

Meta continuously throws the AI to accelerate the ultimate move! The first AI inference chip, AI supercomputer specially designed for large model training
Article Introduction:Compiled | Edited by Li Shuiqing | News from Xin Yuan Zhi Dongxi on May 19. On May 18, local time, Meta issued an announcement on its official website. In order to cope with the sharp growth in demand for AI computing power in the next ten years, Meta is executing a grand plan—— Build next-generation infrastructure specifically for AI. Meta announced its latest progress in building next-generation infrastructure for AI, including the first custom chip for running AI models, a new AI-optimized data center design, the first video transcoding ASIC, and the integration of 16,000 GPUs, AI supercomputer RSC for accelerating AI training, etc. ▲Meta’s official website discloses details of AI infrastructure. Meta regards AI as the company’s core infrastructure. Since Meta’s 2010
2023-05-25
comment 0
1293

Google releases fifth-generation AI chip: accelerating the training and running speed of AI models by 5 times
Article Introduction:Google has launched the fifth-generation custom tensor processor (TPU) chip TPUv5e for training and inference of large models. The new chip makes it five times faster to train and run AI models. TPUv5e delivers 2x better training performance per dollar and 2.5x better inference performance per dollar compared to previous-generation chips Google’s fifth-generation custom tensor processor (TPU) chip, TPUv5e , is used for training and inference of large models, thereby increasing the speed of training and running artificial intelligence models by 5 times. At Google Cloud Next, the annual Google Cloud conference held in San Francisco, Google released a new artificial intelligence chip - the fifth Customized tensor processor (TPU) chip T
2023-09-15
comment 0
463

The world's largest AI chip breaks the record for single-device training of large models, Cerebras wants to 'kill” GPUs
Article Introduction:This article is reproduced from Lei Feng.com. If you need to reprint, please go to the official website of Lei Feng.com to apply for authorization. Cerebras, a company famous for creating the world's largest accelerator chip CS-2 WaferScaleEngine, announced yesterday that they have taken an important step in using "giant cores" for artificial intelligence training. The company has trained the world's largest NLP (natural language processing) AI model on a single chip. The model has 2 billion parameters and is trained on the CS-2 chip. The world's largest accelerator chip uses a 7nm process and is etched from a square wafer. It is hundreds of times larger than mainstream chips and has a power of 15KW. It integrates 2.6 trillion 7nm transistors and packages 850,000 cores
2023-04-25
comment 0
459
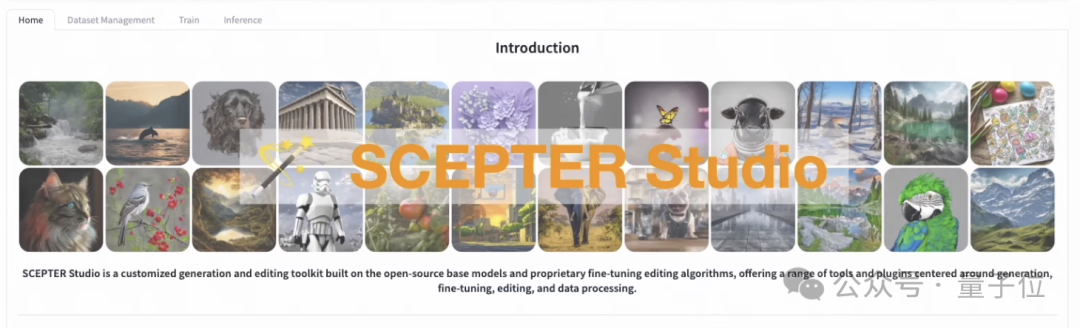
AI drawing model training to reasoning can be done with a web page
Article Introduction:You can train an AI painting model even if you don’t know how to write code! With the help of this framework, everything from training to inference can be handled in one stop, and multiple models can be managed at one time. The Alibaba team launched and open sourced SCEPTERStudio, a universal image generation workbench. With it, you can complete model training and fine-tuning directly in the web interface without coding, and manage related data. The team also launched a DEMO with three built-in models, allowing you to experience SCEPTER’s inference function online. So let’s take a look at what SCEPTER can do specifically! One-stop management of drawing models With SCEPTER, writing programs becomes no longer necessary. Training and fine-tuning can be completed simply by selecting the model and adjusting parameters on the web page.
2024-02-19
comment 0
769

How to use large visual models to accelerate training and inference?
Article Introduction:Hello everyone, I am Tao Li from the NVIDIA GPU computing expert team. I am very happy to have the opportunity to share with you today some of the work that my colleague Chen Yu and I have done on the model training and inference optimization of SwinTransformer, a large visual model. Some of these methods and strategies can be used in other model training and inference optimization to improve model throughput, improve GPU usage efficiency, and speed up model iteration. I will introduce the optimization of the training part of the SwinTransformer model. The work in the inference optimization part will be introduced in detail by my colleagues. Here is the directory we shared today, which is mainly divided into four parts. Since it is optimized for a specific model ,That
2023-05-07
comment 0
1001
Zhipu AI launches third-generation large base model, adapted to domestic chips
Article Introduction:·The third-generation large base model ChatGLM3 aims at the visual mode GPT-4V, which improves the ability to understand Chinese graphics and text, and has enhanced access to search. It can automatically search for relevant information on the Internet based on questions and provide references or article links when answering. The end test models ChatGLM3-1.5B and ChatGLM3-3B support vivo, Xiaomi, Samsung mobile phones and vehicle platforms. On October 27, at the 2023 China Computer Conference, the Chinese cognitive large model company Beijing Zhipu Huazhang Technology Co., Ltd. (hereinafter referred to as "Zhipu AI") launched the third-generation base large model ChatGLM3, using multi-stage enhanced pre-training method to make training more complete, and launch ChatGLM3-1.5B and ChatG that can be deployed on mobile phones
2023-10-27
comment 0
226

Reverse thinking: MetaMath new mathematical reasoning language model trains large models
Article Introduction:Complex mathematical reasoning is an important indicator for evaluating the reasoning ability of large language models. Currently, the commonly used mathematical reasoning data sets have limited sample sizes and insufficient problem diversity, resulting in the phenomenon of "reversal curse" in large language models, that is, a person trained on "A is B" "The language model cannot be generalized to "B is A" [1]. The specific form of this phenomenon in mathematical reasoning tasks is: given a mathematical problem, the language model is good at using forward reasoning to solve the problem but lacks the ability to solve the problem with reverse reasoning. Reverse reasoning is very common in mathematical problems, as shown in the following two examples. 1. Classic question - Forward reasoning of chickens and rabbits in the same cage: There are 23 chickens and 12 rabbits in the cage. How many heads and how many feet are there in the cage? Reverse reasoning: There are several chickens and rabbits in the same cage. Counting from the top, there are 3
2023-10-11
comment 0
560

Challenge NVIDIA! AMD launches AI chip that can run larger models and write poetry
Article Introduction:AMD, the second player in the AI computing power market and chip manufacturer, has launched a new artificial intelligence GPUMI300 series of chips to compete with Nvidia in the artificial intelligence computing power market. In the early morning of June 14th, Beijing time, AMD held the "AMD Data Center and Artificial Intelligence Technology Premiere" as scheduled, and launched the AI processor MI300 series at the meeting. Among them, MI300X, which is specially optimized for large language models, will begin shipping to some customers later this year. AMD CEO Su Zifeng first introduced MI300A, which is the world's first accelerated processor (APU) accelerator for AI and high-performance computing (HPC). There are 146 billion transistors spread across 13 chiplets. Compared with the previous generation MI250, the performance of MI300 has improved
2023-06-15
comment 0
354

Zhipu AI launches the third-generation large base model ChatGLM3 to adapt to more domestic chips
Article Introduction:The news on October 27, 2023 is that Zhipu AI released a new self-developed third-generation large base model ChatGLM3 and related series of products at the China Computer Conference (CNCC). This release marks a major breakthrough for Zhipu AI after launching the 100 billion base conversation model ChatGLM and ChatGLM2. ChatGLM3 was developed using an original multi-stage enhanced pre-training method. This method can make training more complete. According to the evaluation results, in 44 Chinese and English public data set tests, ChatGLM3 ranked first among domestic models of the same size. Zhang Peng, CEO of Zhipu AI, released new products at the press conference and demonstrated the latest product function ChatGLM in real time.
2023-10-30
comment 0
904

Launched new architecture Shengteng AI computing cluster to support large model training with over one trillion parameters
Article Introduction:According to news on September 20, during the Huawei Full Connection Conference 2023 held today, Wang Tao, Huawei's Managing Director, Director of the ICT Infrastructure Business Management Committee, and President of Enterprise BG, officially released the new architecture of the Ascend AI computing cluster - Atlas900 SuperCluster, which can support ultra- Large model training with trillions of parameters. According to reports, the new cluster uses the new Huawei Galaxy AI intelligent computing switch CloudEngineXH16800. With its high-density 800GE port capability, the two-layer switching network can realize ultra-large-scale non-convergence cluster networking with 2,250 nodes (equivalent to 18,000 cards). . The new cluster also uses an innovative super-node architecture, which greatly improves large model training capabilities. In addition, give full play to the Chinese
2023-09-21
comment 0
647

Huawei launches new architecture Ascend AI computing cluster to support large model training with over one trillion parameters
Article Introduction:IT House reported on September 20 that during the Huawei Full Connection Conference 2023 held today, Wang Tao, Huawei's Managing Director, Director of the ICT Infrastructure Business Management Committee, and President of Enterprise BG, officially released the new architecture of the Ascend AI computing cluster - Atlas900 SuperCluster. Can support large model training with over one trillion parameters. The new cluster uses Huawei Galaxy AI intelligent computing switch CloudEngineXH16800. This switch has high-density 800GE port capabilities, allowing the two-layer switching network to achieve ultra-large-scale non-convergence cluster networking with 2,250 nodes (equivalent to 18,000 cards). The new cluster simultaneously It uses an innovative super-node architecture, which greatly improves the training capabilities of large models. also,
2023-09-22
comment 0
244

Adobe's generative AI tool Firefly launches enterprise version, allowing large companies to train exclusive AI models | Forefront
Article Introduction:Author | Editor Zhou Yu | Deng Qian According to The Verge, on June 8, London time, Adobe launched the AI image generation tool Firefly Enterprise Edition at its EMEA2023 Summit. The new version is mainly aimed at large enterprises - enterprises can use their own data assets to train their own Firefly large models and quickly generate image content that is safe for commercial use. According to the official website, the enterprise version of Firefly will be officially released in the second half of this year, but enterprise users can already use Firefly's functions in the enterprise version of Adobe Express. Source: Adobe Like many large technology companies, Adobe is accelerating the deployment of AI in its products. Firefly is Adobe
2023-06-10
comment 0
642

Huawei Cloud provides out-of-the-box computing power for large model training and inference in Hong Kong
Article Introduction:Huawei Cloud successfully held the Huawei Cloud Summit on April 23, providing ready-to-use AI cloud services in Hong Kong to provide efficient, long-term, and reliable AI computing power for large model training and inference. Huawei Cloud stated that its infrastructure will support efficient migration, development, and efficient operation of large models through a full-link cloud tool chain, and will provide a large model area specially optimized for Ascend Cloud to enable rapid application of "hundreds of models and thousands of states" Landed. Shi Jilin, President of Huawei Cloud Global Marketing and Sales Services, was at the event. Shi Jilin, President of Huawei Cloud Global Marketing and Sales Services, said: Hong Kong has a good foundation for the development of the AI industry, with first-class university resources and scientific research institutions, as well as an open economic system and an international business environment, attracting top people from around the world.
2024-04-24
comment
200

Kimi Chat internal testing starts, Volcano Engine provides acceleration solutions, supports training and inference of Moonshot AI large model service
Article Introduction:On October 9, Beijing Dark Side of the Moon Technology Co., Ltd. (MoonshotAI) announced a breakthrough in the field of "long text" and launched KimiChat, the first intelligent assistant product that supports the input of 200,000 Chinese characters. This is the longest context input length that can be supported by a large model service that can be used commercially in the global market, marking MoonshotAI's world-leading level in this important technology. Volcano Engine has in-depth cooperation with MoonshotAI to exclusively provide it with highly stable and cost-effective AI training and inference acceleration solutions. The two parties jointly conduct technology research and development to jointly promote the application of large language models in vertical fields and general scenarios. At the same time, KimiChat is about to settle in Huoshan Yin
2023-10-11
comment 0
953
Microsoft launches 'Learn from Mistakes' model training method, claiming to 'imitate the human learning process and improve AI reasoning capabilities'
Article Introduction:Microsoft Research Asia, in collaboration with Peking University, Xi'an Jiaotong University and other universities, recently proposed an artificial intelligence training method called "Learning from Mistakes (LeMA)". This method claims to be able to improve the reasoning ability of artificial intelligence by imitating the human learning process. Currently, large language models such as OpenAIGPT-4 and Google aLM-2 are used in natural language processing (NLP) tasks and chain-of-thought. CoT) reasoning mathematical puzzle tasks have good performance. However, open source large models such as LLaMA-2 and Baichuan-2 need to be strengthened in dealing with related issues. In order to improve the thinking chain reasoning ability of these large language models in open source, the research team proposed the LeMA method
2023-11-07
comment 0
466
