


This article mainly analyzes from the perspective of InnoDB data storage structure, under what circumstances the SQL query efficiency will be reduced. I often see some articles complaining about it on the Internet. When the amount of data is large, the query efficiency will be reduced a lot. When there are many related tables, query efficiency will decrease. The amount of data in a single table should not exceed one million, etc.

Database version: 8.0 Engine: InnoDB Reference material: Nuggets booklet "Understanding Mysql from the Roots". If you have time, I suggest you read it yourself.
Sample table:
CREATE TABLE `hospital_info` ( `pk_id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `id` varchar(36) NOT NULL COMMENT '外键', `hospital_code` varchar(36) NOT NULL COMMENT '医院编码', `hospital_name` varchar(36) NOT NULL COMMENT '医院名称', `is_deleted` tinyint DEFAULT NULL COMMENT '是否删除 0否 1是', `gmt_created` datetime DEFAULT NULL COMMENT '创建时间', `gmt_modified` datetime DEFAULT NULL COMMENT 'gmt_modified', `gmt_deleted` datetime(3) DEFAULT '9999-12-31 23:59:59.000' COMMENT '删除时间', PRIMARY KEY (`pk_id`), KEY `hospital_code` (`hospital_code`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='医院信息';
Starting from one row of data, let’s first understand the storage format of a single row of data.
There are currently 4 row formats, namely Compact, Redundant, Dynamic and Compressed row formats.
There is generally no need to specify it deliberately when creating a table. Versions 5.7 and above will default to Dynamic.
Each row format is similar. Here we take Compact as an example to briefly understand how each row of data is recorded. 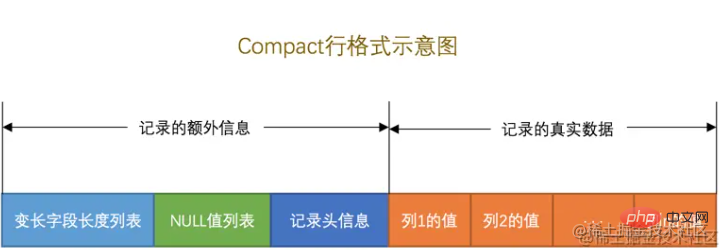
As shown in FIG. Divided into two parts: "Additional information" and "Real data".
This is more interesting. Generally, when defining a field, you need to specify the type and length# of the field. ##,
For example:hospital_code field definition VARCHAR(36) in the sample table. In actual use, the hospital_code field length only uses 32 bits.
What will happen to the remaining 4 characters? If you forcibly fill in empty characters, wouldn't it be a waste of 4 characters of memory. If it is not filled, how to determine how many characters are saved in the current field? How much memory does it take up? At this time, the variable length field list will be in reverse orderby field , using 1~2 bytes to record the actual length of each variable length field. This can effectively utilize memory space.
Similar fields:VARBINARY, various TEXT types, various BLOB types.
Correspondingly, there are also "fixed length fields", such as:CHAR(10). This type of field will occupy the space of the specified character length by default during initialization. If it is not enough Then fill in empty characters, so it is a waste of space. It is generally recommended to set the length as needed.
Of course, the "variable length field list" does not necessarily exist. If the defined field type does not have a "variable length field", it will not exist.Extension: For TEXT or BLOB type fields, the length may not be saved on one page. In this case, most of the data will be recorded in other pages and retained in the current record. The address of a page of data.
NULL values. If these values are all recorded in In real data, storage space will be wasted. In the Compact format, these columns with NULL values will be managed uniformly and stored in a NULL value list.
If no field in a row of data isNULL, this column will not be generated.
The storage method is also more interesting, it is binary modeReverse order record.
Using the sample table to analyze, there are three fields in the table:is_deleted, gmt_created, gmt_modified, which may be empty. Assuming that gmt_created and gmt_modified are both empty in a record, the corresponding NULL value list should look like the following.
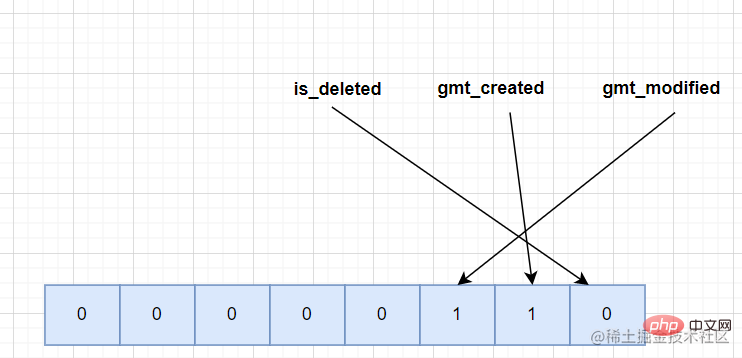
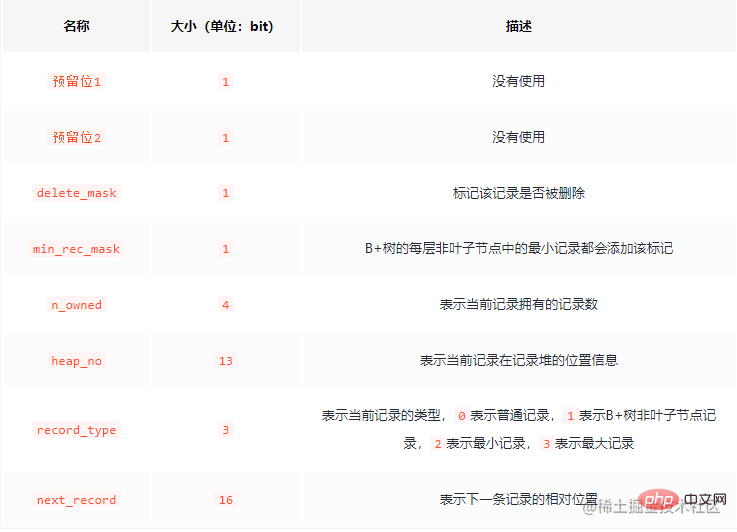
delete_mask Anyone who has used redis knows that the deleted data in redis will not It will be cleared immediately. The same is true in the same mysql. The deleted data will not be cleared immediately because the cleaning process will cause IO operations, which greatly affects efficiency. The deleted data will form a linked list, which can be used as a reusable space.
What happens if the primary key is not set?
Under InnoDB, the primary key is the unique identifier of a record. If the user does not specify it, mysql will select one from the Unique (unique) key as the primary key. If there is no Unique key, A hidden column named row_id will be added as the primary key.
In addition, the two columns transaction_id (transaction ID) and roll_pointer (rollback pointer) will be added.
The four row formats are very similar, so I won’t introduce them one by one. They are divided into two parts: “additional information” and “real data”. The difference is mainly in the content of the "extra information" record and the storage of variable-length fields.
I believe you are familiar with the concept of data page. It is the basic unit for InnoDB to manage storage space. The size of a single page is generally 16KB. Many different types of pages are designed according to different purposes, such as: pages that store table space header information, pages that store Insert Buffer information, pages that store INODE information, pages that store undoLog information page and so on.
The page space is divided as follows: 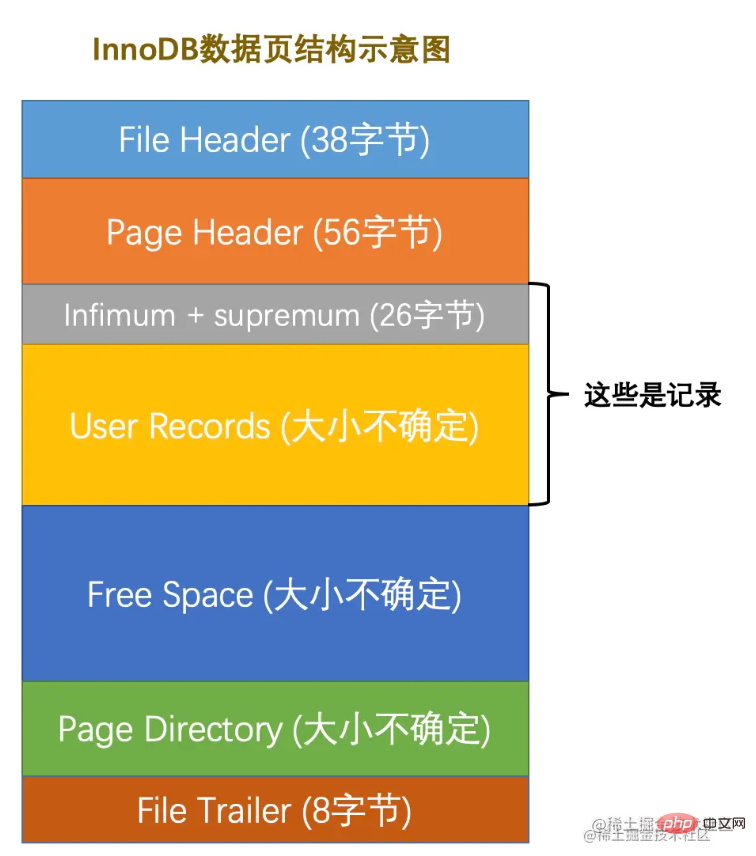
There are 7 components in total. Let’s roughly describe the 7 parts.
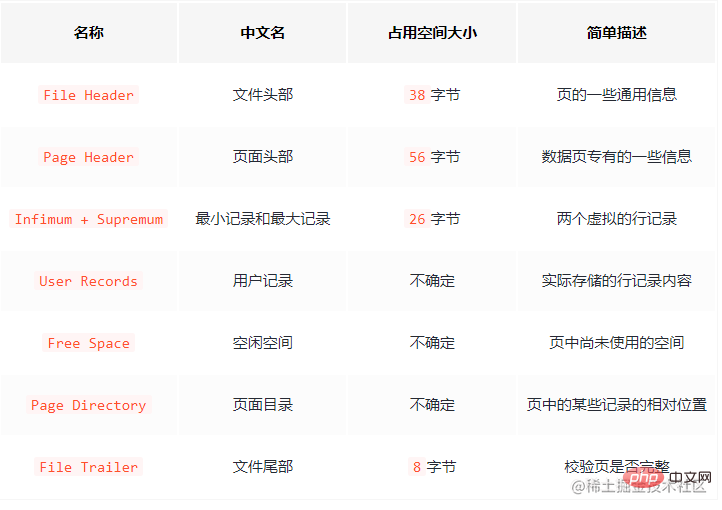
There are many attributes in File header and Page header. I won’t introduce them one by one here. As long as you know these two Locally record some attributes of page, such as: page number, page numbers of the previous and next pages, page type, and page memory usage, etc. Let me talk about it here, the pages are connected by double linked list. The data record is single-chained list.
File Trailer is used to verify the integrity of page data. When page data is rewritten from memory to disk, it needs to be verified to prevent data page damage.
Focus on User Records (used space) and Free Space (remaining space) , where the real data records are saved.
In addition, Infimum and Supremum identify the minimum record and the maximum record respectively. That is, when a page is generated, it will contain these two records by default, but don't worry, these two records are only used as the head and tail of the data linked list and do not affect the real data.
To sum up, the storage of records in the page is as follows:
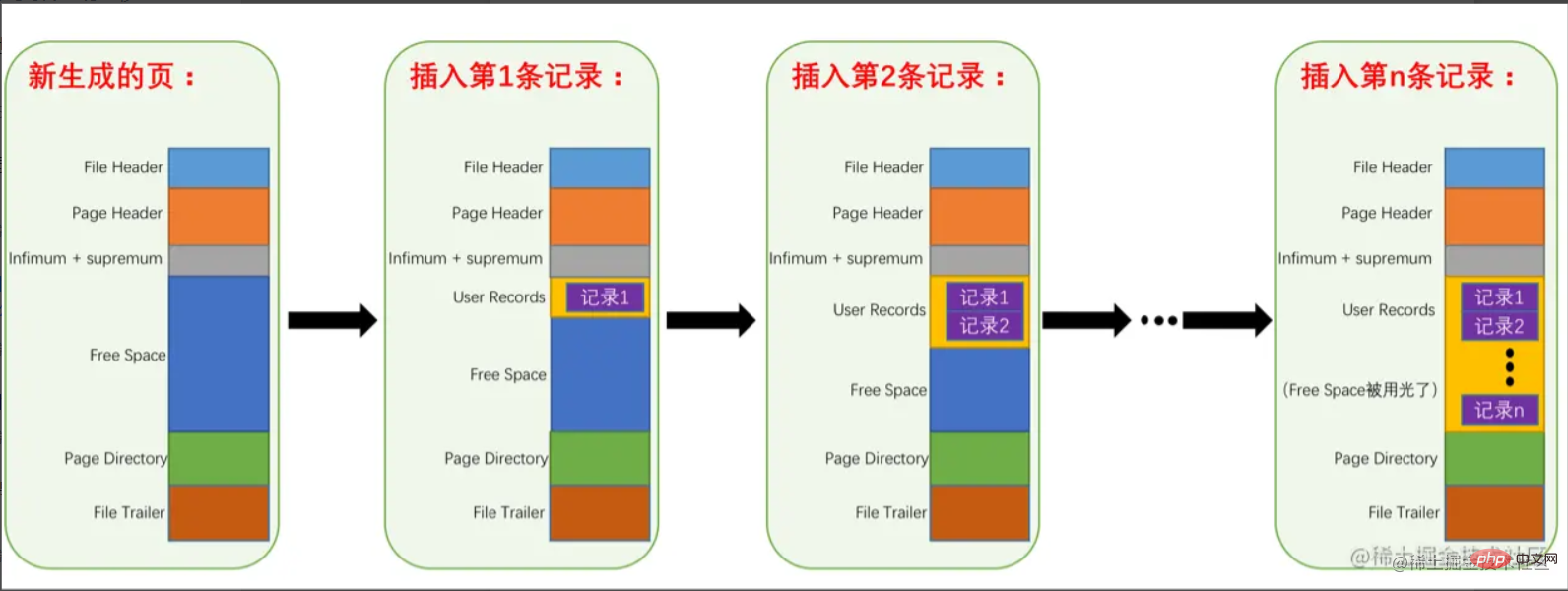 Simply speaking, it is the conversion from Free Space to User Records. When Free Space consumes When it is exhausted, the data page is considered to be full.
Simply speaking, it is the conversion from Free Space to User Records. When Free Space consumes When it is exhausted, the data page is considered to be full.
At this point, the data has been written into the data page. How to take it out? We know above that the data records are composed of a single-linked list. Do we need to start from the Infimum (minimum) record and traverse the linked list?
Obviously, the development boss of MySQL cannot be so stupid, otherwise I can do it, haha.
Here we will mention Page Directory (page directory). In the page, the data is grouped, and the address offset of the last record in each group is extracted separately and stored in order in the "page directory" near the end of the page. These address offsets in the page directory are The shift amount is called "slot". In addition, the last record header (n_owned) also stores how many records there are in the group.
The page directory is composed of slots.
The overall structure diagram is as follows: 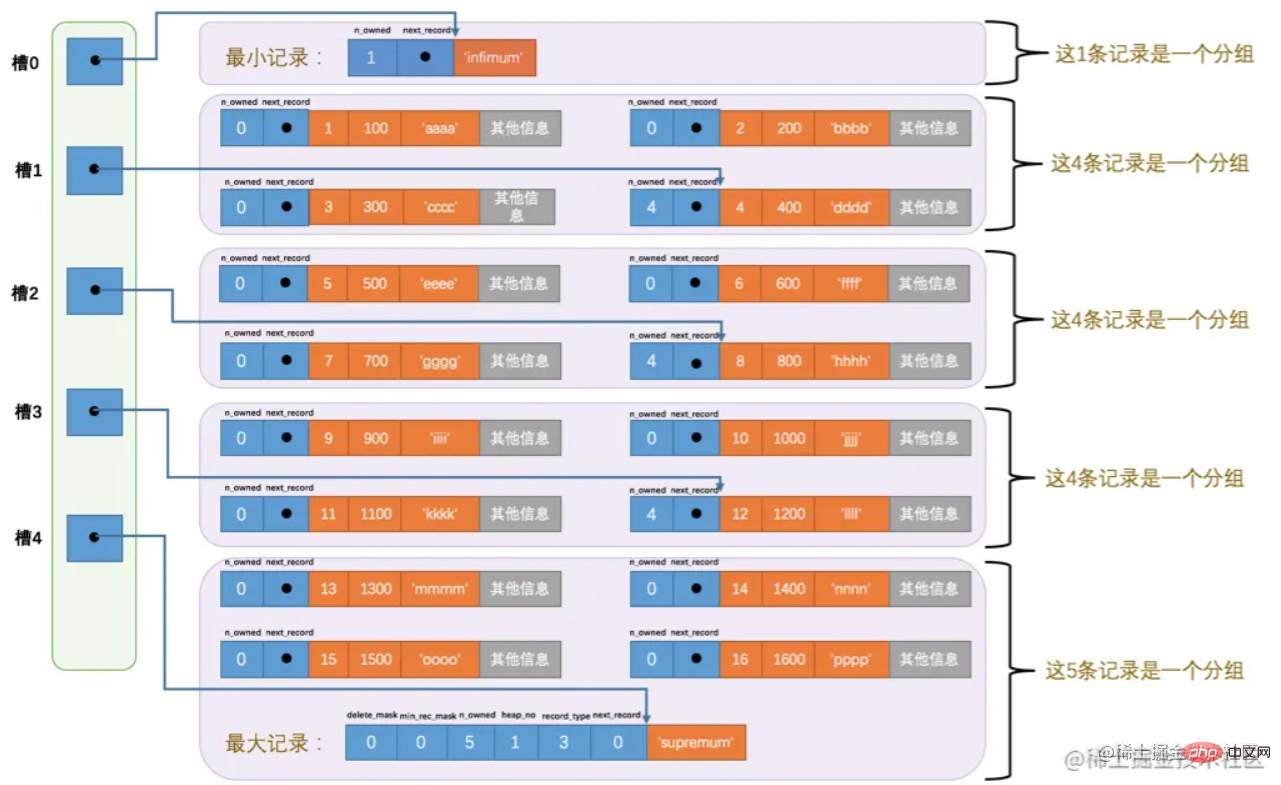
After having the directory, the query is relatively simple. You can use Dichotomy for quick search. In the above figure, we know that the minimum slot is 0 and the maximum is 4. For example:
Suppose you want to query the data whose primary key record is 6.
1) Calculate the position of the middle slot, which is (0 4)/2 = 2. The primary key of the record corresponding to the extracted slot is 8, because 8>6.
2) In the same way, set the largest slot to 2, that is, (0 2)/2 =1, the primary key corresponding to slot 1 is 4, because 4
In order to facilitate subsequent description, the data form of the page is simplified as shown in the figure below. 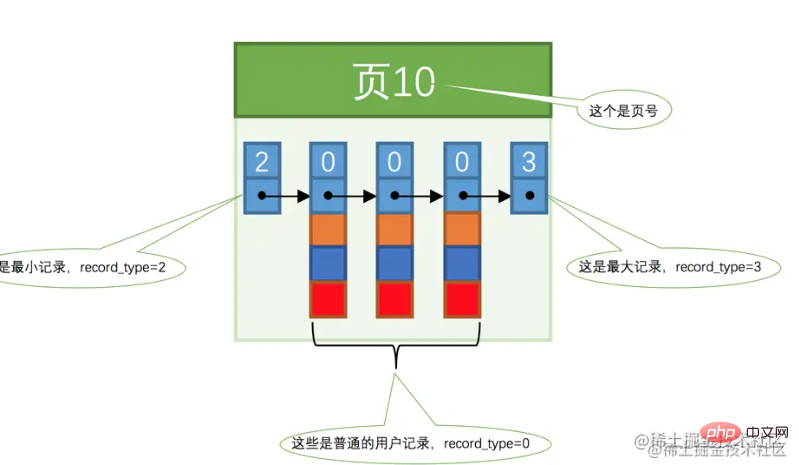
You might as well think about a question, as mentioned before. The data pages are linked using a doubly linked list, as shown in the figure below: 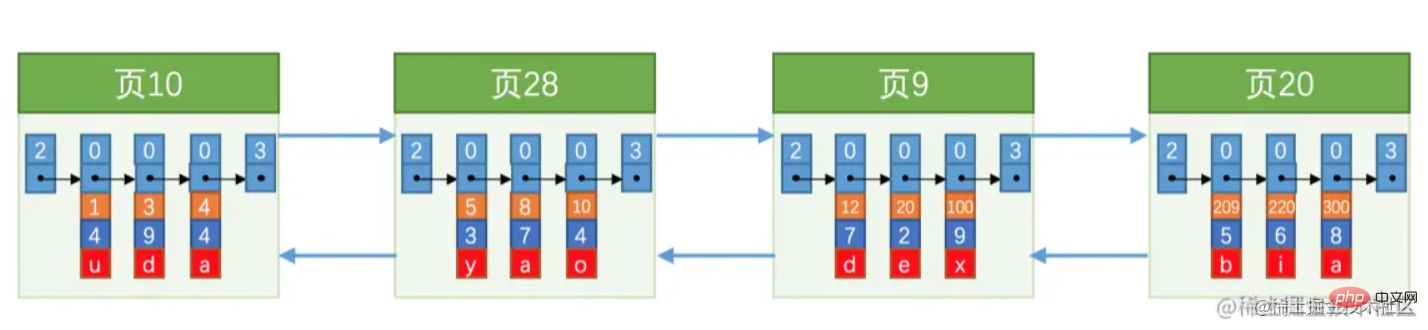 As can be seen from the above figure, the page numbers are not consecutive , and is not necessarily a continuous memory Space (remember this sentence will be mentioned later) .
As can be seen from the above figure, the page numbers are not consecutive , and is not necessarily a continuous memory Space (remember this sentence will be mentioned later) .
Assuming that each page can store 3 records, and now there are 100,000 records that need to be saved, more than 30,000 data pages will be needed. At this time, we will face the same query problem as too much data on a single page, and we cannot traverse them one by one. At this time, a directory that can be quickly queried is also needed. This directory is "index".
Based on the data page shown in the figure above, the following index structure can be formed: 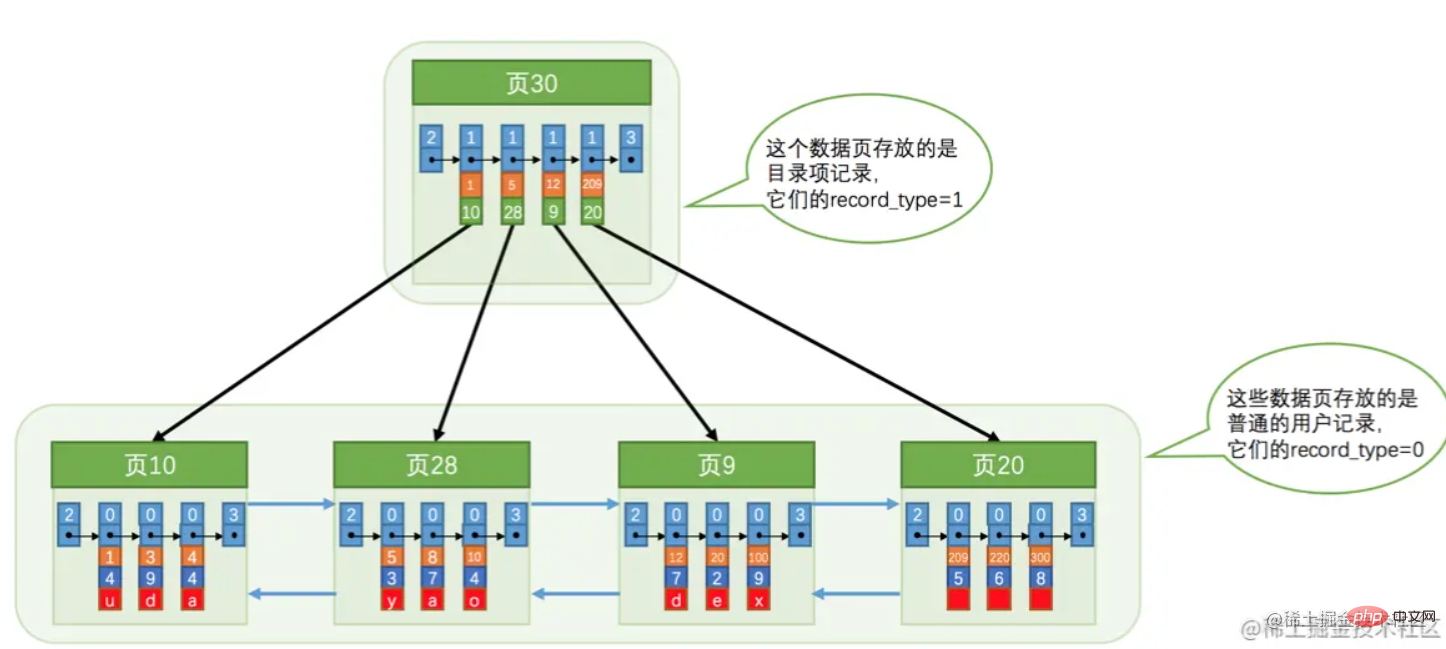 This is what is often called a clustered index, and the leaves are the data. One thing to note here is that "Page 30" stores the primary key and the page number where it is located.
If a single index page is full, it will be split. Produce a tree structure as shown below.
This is what is often called a clustered index, and the leaves are the data. One thing to note here is that "Page 30" stores the primary key and the page number where it is located.
If a single index page is full, it will be split. Produce a tree structure as shown below. 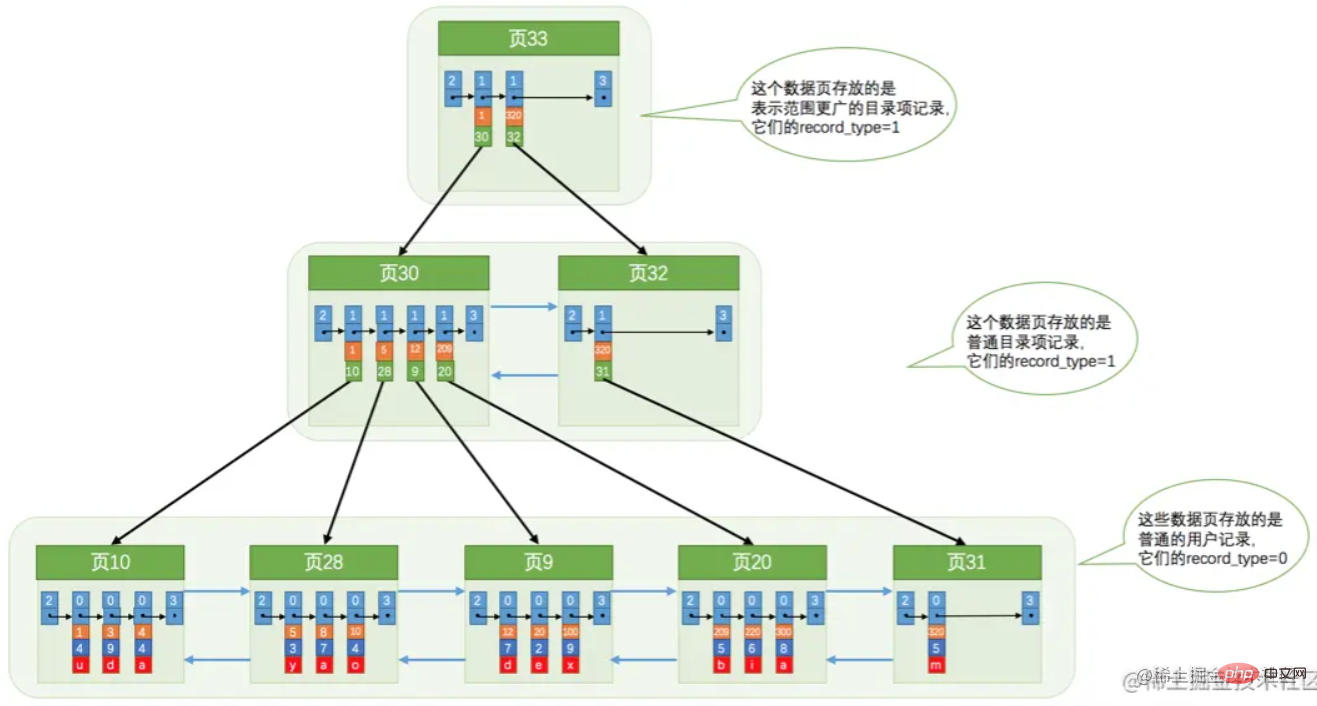 However, the above picture is not completely accurate for the convenience of identification. A root node should be generated first. When the root node is full, it will be split. The root node records the index page information after splitting.
However, the above picture is not completely accurate for the convenience of identification. A root node should be generated first. When the root node is full, it will be split. The root node records the index page information after splitting.
To put it simply, it is just like the growth of a tree, starting from the roots and then to the trunk, branches, leaves, etc.
Secondary indexThe idea is the same as the clustered index. The difference is that the leaf nodes of the secondary index are not real data, but the primary key of the data. A table return operation is required to obtain the real data.
So far, we have known the storage structure of a single piece of data and the smallest storage data unit page. The data pages are connected through a doubly linked list, and the data pages are not necessarily continuous.
At this time, a problem arises. What if the pages of records in the same table are too far apart in memory addresses? Imagine that in order to find three people, they go to Beijing, New York, and London respectively. You have to look for them one by one and waste a lot of time on the journey. If you gather them in a country or even a city, it will be much faster.
So the concept of 区 was born. An area is composed of 64 consecutive pages. By default, one area occupies 1M of memory. When applying for memory, 1M of space is occupied at one time, and the data pages are adjacent, which solves the random IO problem to a certain extent.
On the basis of areas, in order to more effectively improve query efficiency, the leaf nodes and non-leaf nodes of the B-tree are recorded in different areas. The set of these areas is called " segment (segment) )". Under this concept, to insert the first record, you need to apply for 2 area spaces, a clustered index root node, and a data page. This time, you need to apply for 2M of space! I haven’t done anything, and the 2M space is gone. Is this reasonable? Obviously, this is unreasonable.
So we came up with the concept of "Fragmentation Area". The fragmented area belongs directly to the table space and does not belong to any segment. The process of allocating memory changes to:
1) When data is first inserted, storage space is allocated as a single page from the fragment area.
2) When a segment has occupied 32 fragment area pages, space will be allocated as a complete area.
The table space is also divided into: System table space and Independent table space, in addition to the zone's XDES Entry data structure. The content is too much and complicated. If you need to know more, you can read the original book.
1) Are more indexes better? What impact will there be if there are more?
The more, the better. As you can see from the above, index records also require memory consumption. Each index corresponds to a B-tree, and each tree requires two segments to record leaf nodes and non-leaf nodes respectively. This will cause a lot of waste of memory. This is not unacceptable. After all, the meaning of the index itself is to exchange space for time. But we need to know that the addition, deletion and modification of data will lead to changes in the index, which requires the index to reallocate nodes and the recycling and allocation of page memory. These are all IO operations. If there are too many indexes, it will inevitably lead to a decrease in performance.
Therefore, reasonable use of joint indexes can solve the problem of too many single indexes. In addition, the index has a length limit, and fields that are too long are not suitable for indexing.
2) Why is the query efficiency of the index so high?
This is actually an algorithm problem. Take the clustered index as an example. Assume that the index pages of non-leaf nodes can each record 1,000 pieces of data, and each leaf node can record 500 pieces of data. A 3 The B-tree of the layer (not counting the root node) can store 10001000500 records. An index with a 3-layer structure can store so many records. It only takes a few queries to locate the data each time, so the efficiency is naturally high.
In fact, the data that can be recorded on a single index page is much larger than this.
Similarly, you can think about a problem here. If the single piece of data in the leaf node is very large, so large that a data page can only store 3 records, then the depth of the B-tree will increase, so it can be reasonably reduced. The size of a single record in the table is also an optimization.
3) If the amount of data is large, will SQL execute slowly?
In fact, I really want to complain about this issue. The query efficiency of millions of data is xx seconds, which is too slow. There is no denying that the performance of mysql is indeed weaker than that of some databases, but it will be slow with millions of data. Think about whether your SQL and table structure design is reasonable. Not to mention millions of levels, even tens of millions of levels can achieve millisecond-level queries. Just talking about the quantity is nonsense. You need to actually look at the memory size occupied by the lock. If there are hundreds of fields in your table, or there are fields with extremely long characters. Then even the gods can't save you.
This article mainly introduces the concept of MySql data structure. Most of the content comes from the book "Understanding Mysql from the Root". A lot of simplifications have been made, which can serve as a basis for understanding some concepts.
If there are any errors or omissions, thank you for correcting them.
[Related recommendations: mysql video tutorial]
The above is the detailed content of A brief analysis of the data storage structure in MySQL. For more information, please follow other related articles on the PHP Chinese website!










![MySQL query optimization solution [taught by architects from major manufacturers] [Getting Started with MySQL | Tuning | Indexing] Advanced Tutorial](https://img.php.cn/upload/course/000/000/068/6242a7d5be236814.png)








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



