



At the end of the Stream chapter, we are left with a question, what is the chunk output by the following code?
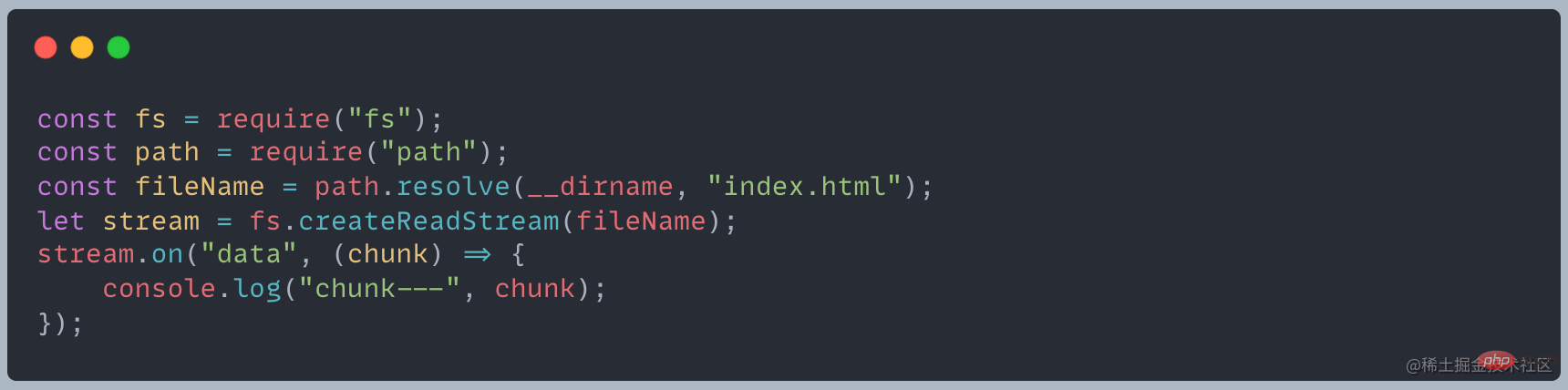
Through printing, we find that chunk is a Buffer object, the elements of which are hexadecimal two-digit numbers, that is, values from 0 to 255. [Related tutorial recommendations:nodejs video tutorial,Programming teaching]

Explain that the data flowing in the Stream is the Buffer, then Let's explore the true face of Buffer!
? Why is Buffer introduced in Node?
At the beginning, JS only ran on the browser side. Unicode-encoded strings were easy to process, but for binary Difficulty handling strings with non-Unicode encodings. And binary is the lowest level data format of the computer. Video/audio/program/network packets are all stored in binary. So Node needs to introduce an object to operate binary, so Buffer was born, which is used for TCP stream/file system and other operations to process binary bytes.
Since Buffer is too commonly used in Node, Buffer has been introduced when Node starts, and there is no need to use require()
ArrayBuffer is a piece of binary data in the memory. It cannot operate the memory itself. It needs to be operated through theTypedArray objectorDataView. Represent the data in the buffer into a specific format, and read and write the contents of the buffer through these formats. It deploys an array interface and can use the array to operate data
The most commonly used is the TypeArray view, which is used to read and write simple types of ArrayBuffer, such as Uint8Array (unsigned 8-bit integer) array view, Int16Array (16-bit integer) array view
The Buffer class in NodeJS is actually the implementation of Uint8Array.
Buffer is an object similar to Array, but it is mainly used to operate bytes
Buffer is a combination of JS and C The performance part of the module is implemented in C, and the non-performance part is implemented in JS.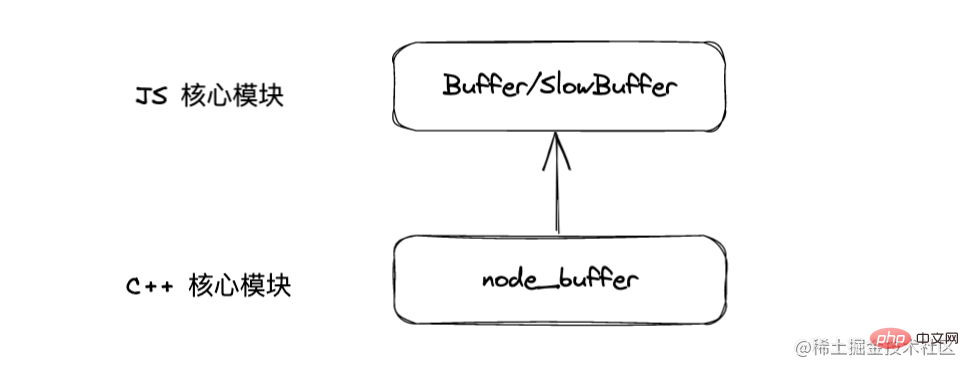
The memory occupied by Buffer is not allocated by V8 and belongs to off-heap memory.
The Buffer object is similar to an array, and its elements are two-digit hexadecimal digits, that is, values from 0 to 255
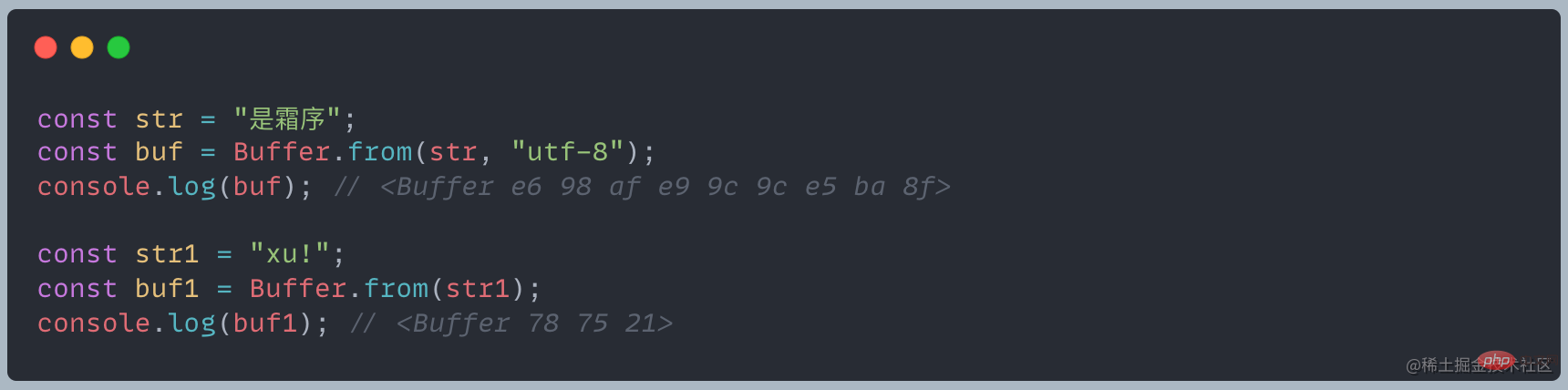
It can be seen from this example that different characters occupy different bytes in the Buffer. Under UTF-8 encoding, Chinese occupies 3 bytes, and English and half-width symbols occupy 1 byte.
? What will happen if the input element is a decimal/negative number/exceeds 255?
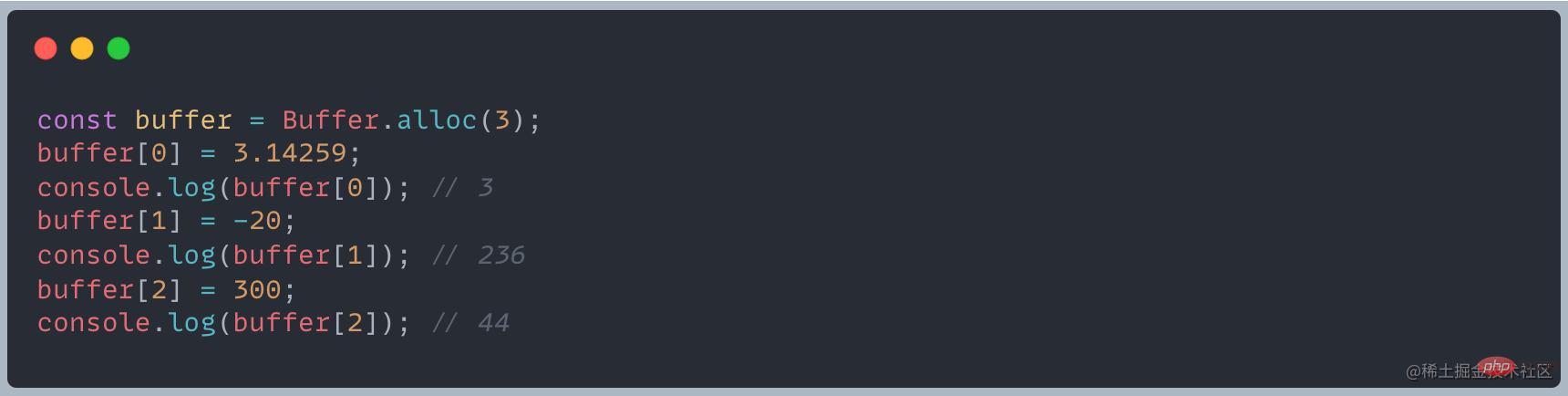
For the above situation, the processing of Buffer is:
Why does the Buffer display hexadecimal numbers
In fact, binary numbers are still stored in the memory, but the Buffer is displaying the memory The data uses a hexadecimal
buffer with a size of 2 bytes. There are 16 bits in total, such as00000001 00100011. If it is not convenient to display it directly like this, convert it to 16 bits. Base
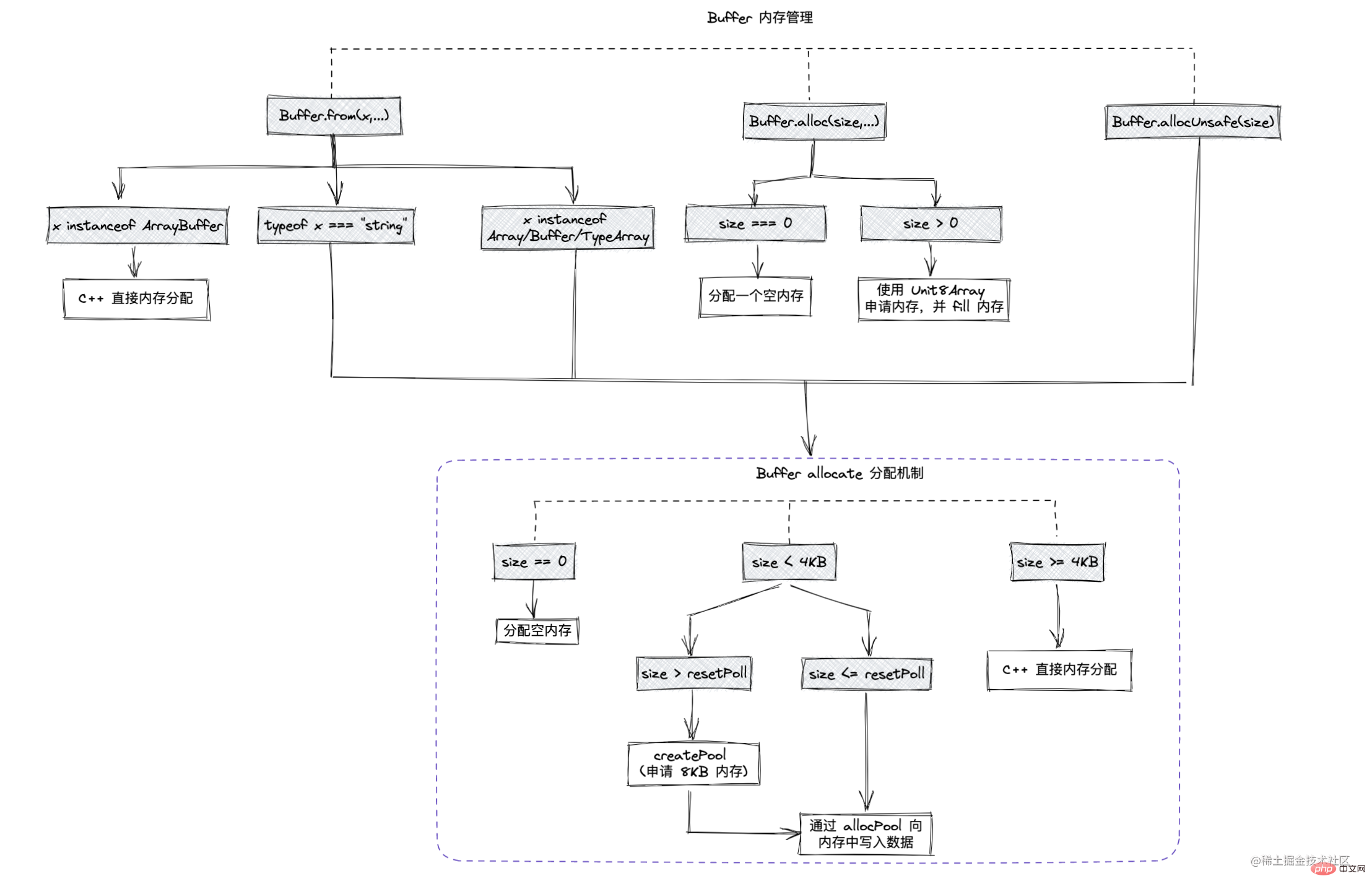
Create fixed size buffer

Allocate a Buffer of size bytes, allocUnsafe executes faster than alloc , we found that the results are not initialized to 00 like Buffer.alloc

The memory segment allocated when allocUnsafe is called has not yet been initialized, so the memory allocation speed is very slow, but The allocated memory segment may contain old data. If these old data are not overwritten during use, memory leaks may occur. Although it is fast, try to avoid using it.
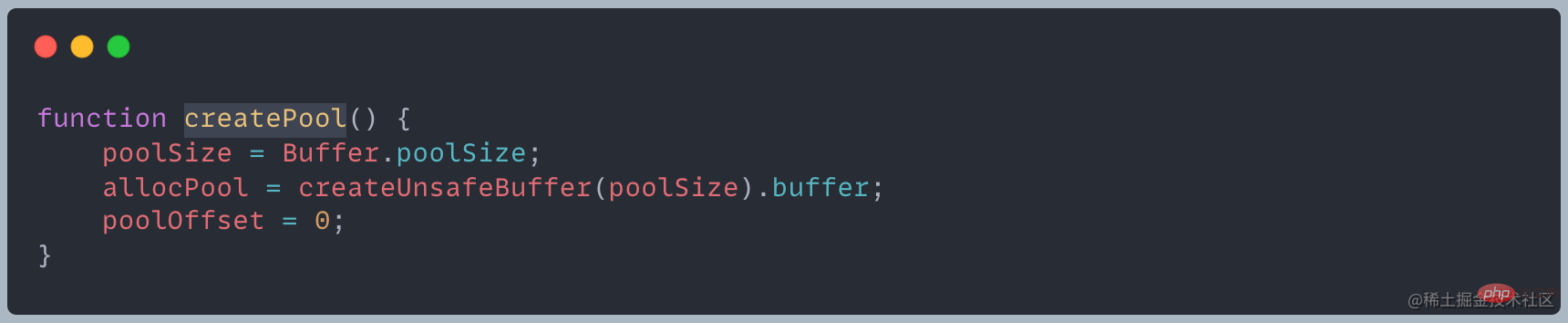
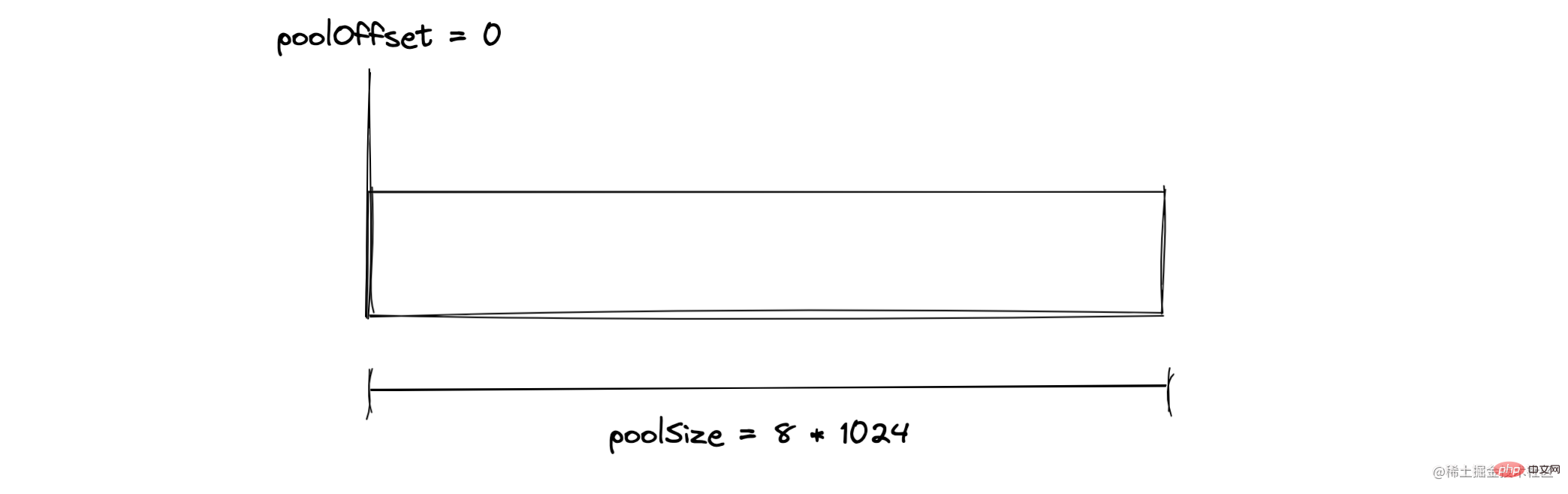
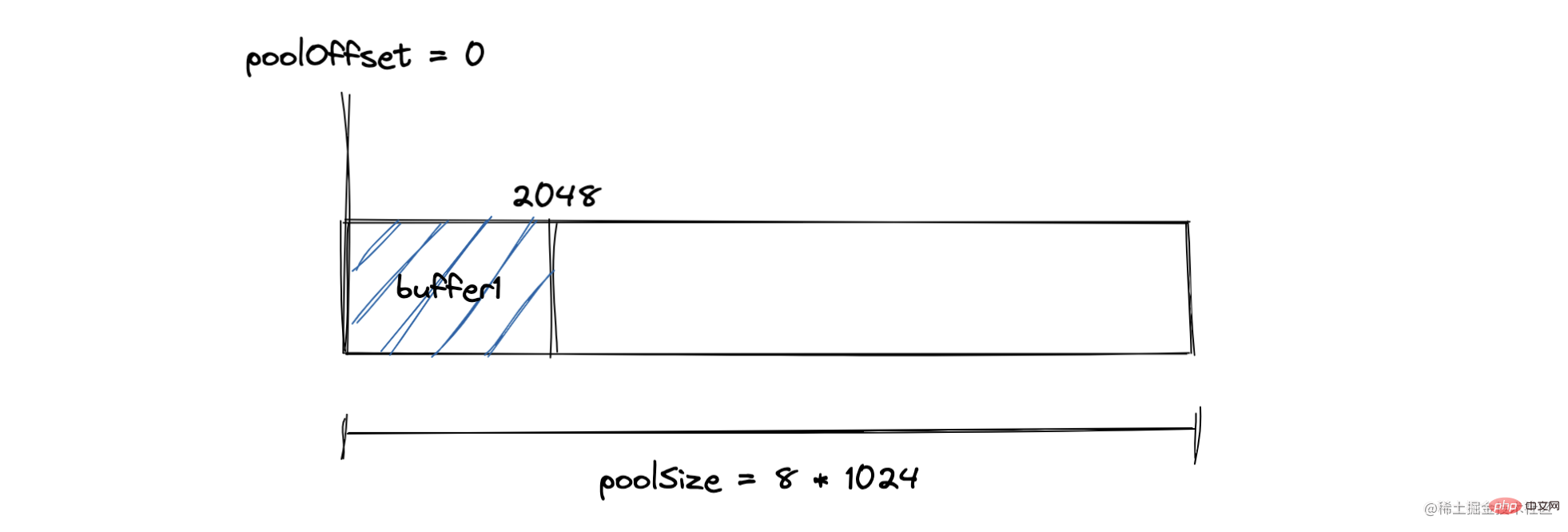
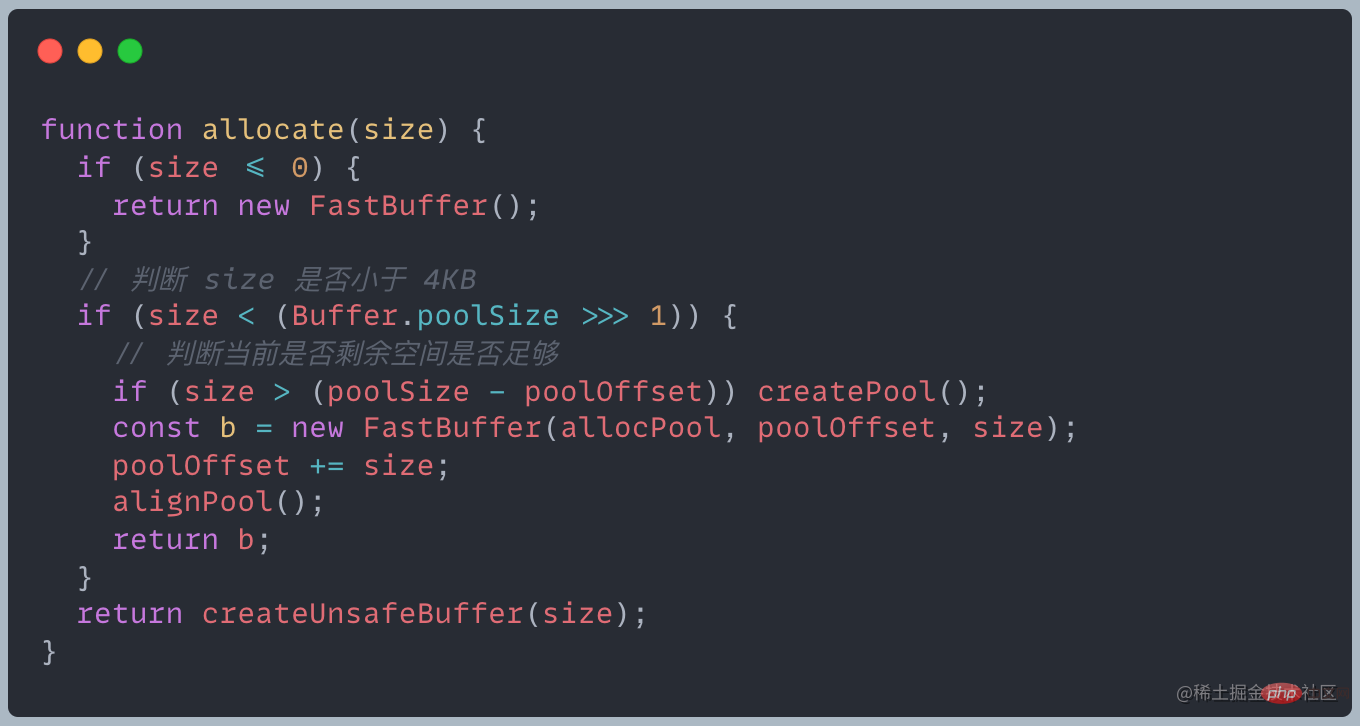
The Buffer module will pre-allocate an internal Buffer instance with a size of Buffer.poolSize as a quick allocation Memory pool, used to create new Buffer instances using allocUnsafe
Create Buffer directly based on the content


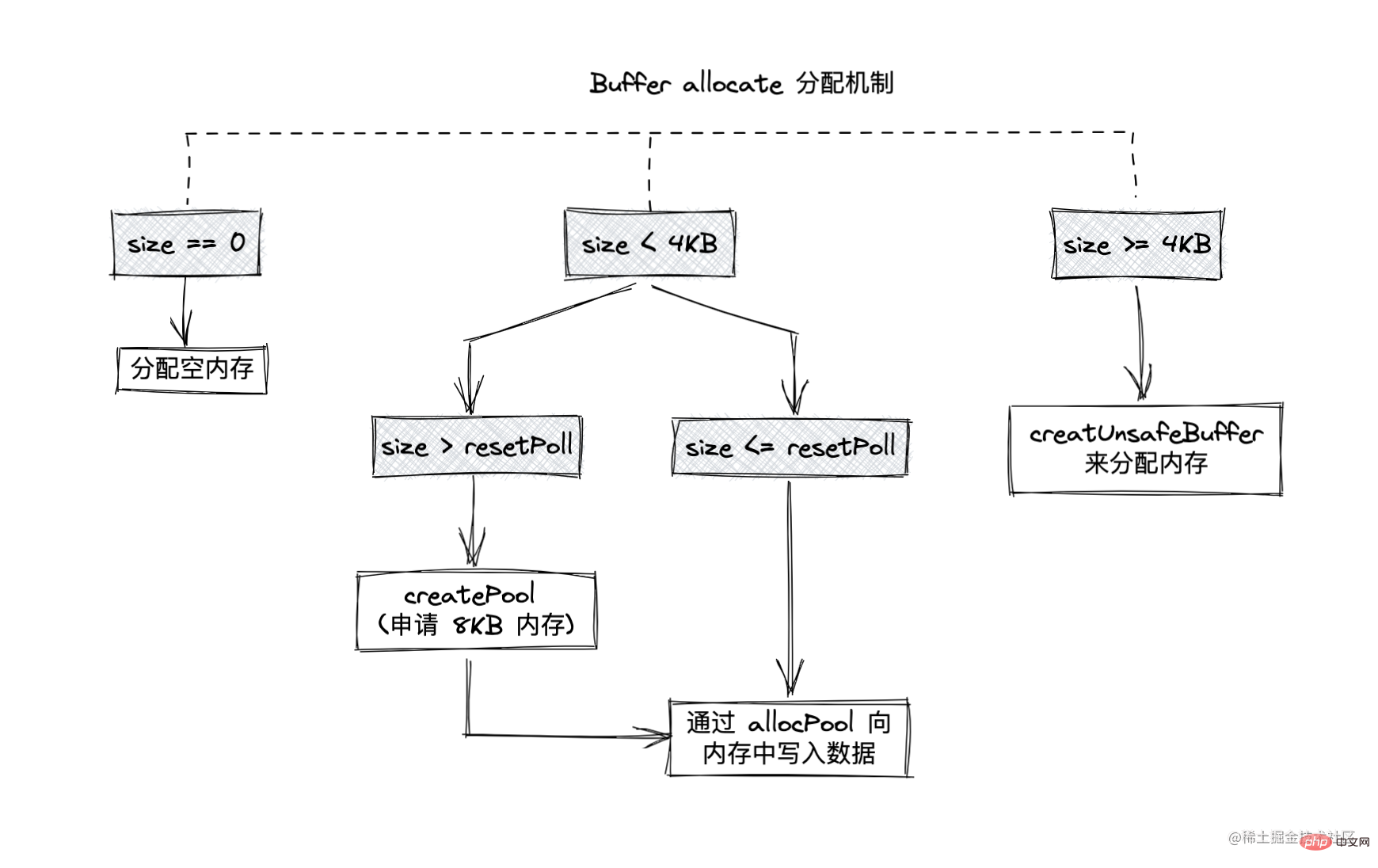
Buffer The size is determined when created and cannot be adjusted!Allocate small objects If the allocated object is less than 8KB, Node will allocate it as a small object The Buffer allocation process mainly uses a The local variable pool serves as an intermediate processing object, and all slab units in the allocated state point to it. The following is the operation of allocating a brand new slab unit, which will point the newly applied SlowBuffer object to it
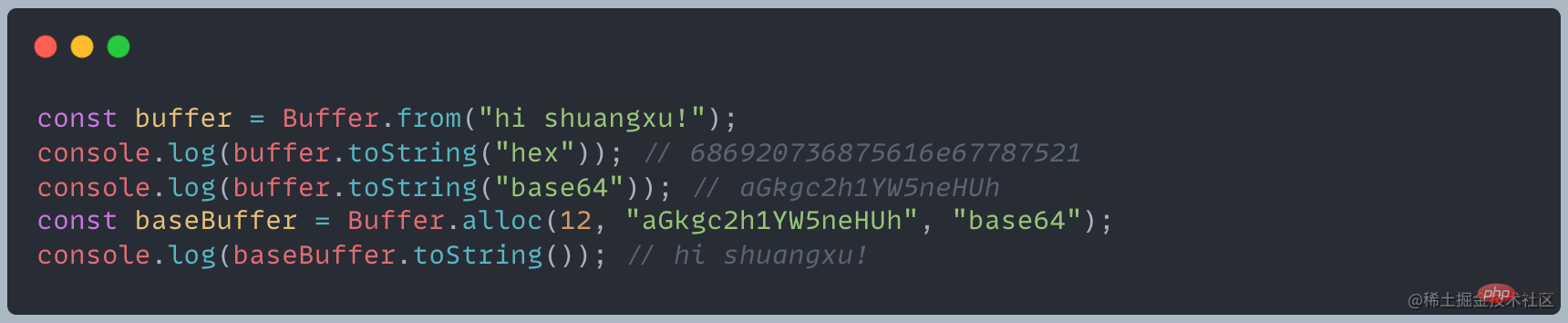
Node currently supports eight encoding methods: utf8, ucs2, utf16le, latin1, ascii, base64, hex, and base64Url.Specific implementation
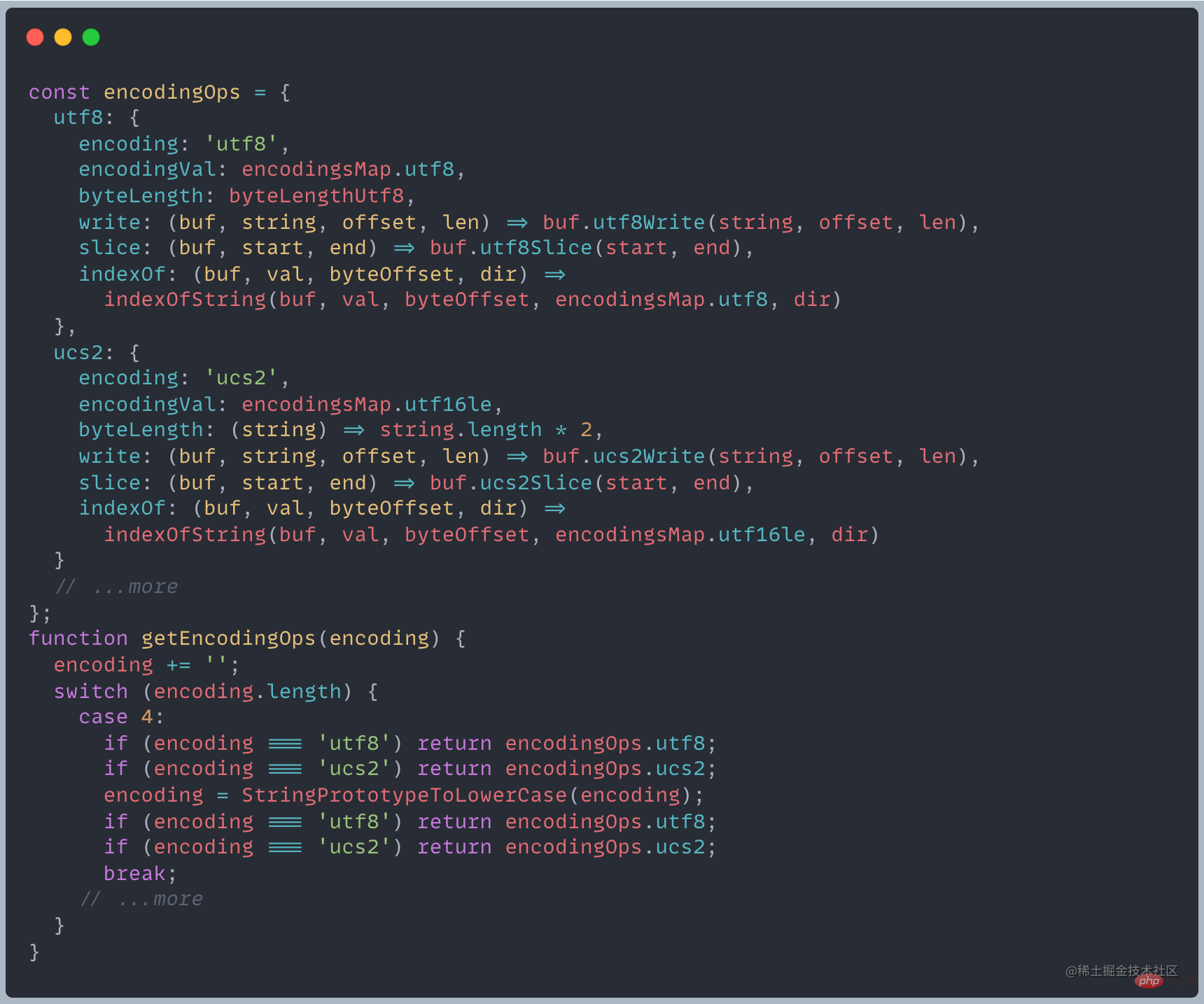
For each different encoding scheme, a series of APIs will be implemented, and different results will be returned. Node.js will return different objects according to the incoming encoding
Mainly through the Buffer.from method mentioned above, the default encoding method is utf-8
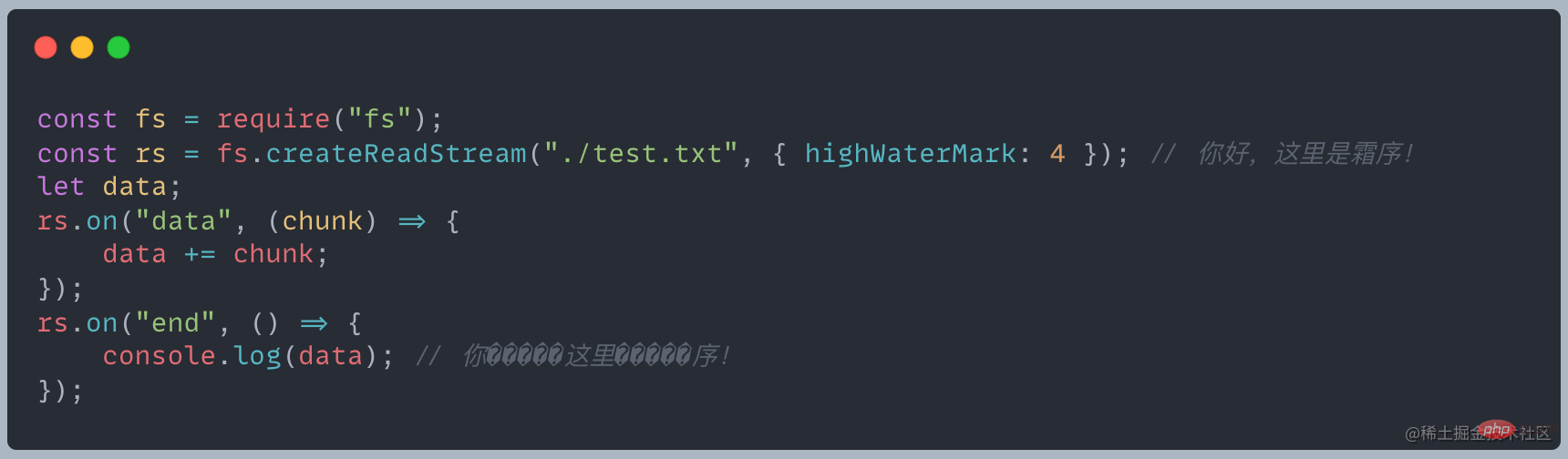
? Why are there garbled characters? How to solve this problem?
According to reading, the length of each read is 4, and the chunk output is as follows

Fordata = chunkis equivalent todata = data.toString chunk.toString
Since one Chinese character occupies three bytes, the fourth byte in the first chunk will display garbled characters. , the first and second bytes of the second chunk cannot form text, etc., so the garbled problem will be displayed
For more node-related knowledge, please visit:nodejs tutorial!
The above is the detailed content of Learn more about Buffers in Node. For more information, please follow other related articles on the PHP Chinese website!
 Is python front-end or back-end?
Is python front-end or back-end? node.js debugging
node.js debugging How to implement instant messaging on the front end
How to implement instant messaging on the front end The difference between front-end and back-end
The difference between front-end and back-end Introduction to the relationship between php and front-end
Introduction to the relationship between php and front-end Python online playback function implementation method
Python online playback function implementation method The purpose of rm-rf command in linux
The purpose of rm-rf command in linux Apple store cannot connect
Apple store cannot connect























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



