

Detailed explanation of Redis Sentinel, Sentinel construction process, Sentinel operation process and election principle (subjective offline, objective offline, how to elect the Sentinel leader).

The whistleblower patrols and monitors whether the background master host is faulty. If it is faulty, it will automatically convert a slave database to a new master database based on the number ofvotesto continue external services. [Related recommendations:Redis video tutorial]
is commonly known as unattended operation and maintenance.
3 Sentinels: Automatically monitor and maintain the cluster. It does not store data and is just a whistleblower.
1 Master 2 Slave: used to read and store data
Copy sentinel.conf in the redis installation path to the myredis directory
cp sentinel.conf /myredis/sentinel26379.conf
Modify the configuration file
vim sentinel26379.conf bind 0.0.0.0 # protected-mode yes 修改为 protected-mode no protected-mode no # daemonize no 修改为 daemonize yes daemonize yes # port port 26379 # pid文件名字,pidfile pidfile /var/run/redis_26379.pid # log文件名字,logfile(修改 logfile "" 为 logfile "/myredis/26379.log") logfile "/myredis/26379.log" # 指定当前的工作目录(修改 dir /temp 为 dir /myredis) dir /myredis
Set the master server to be monitored
quorum: The minimum number of sentinels to confirm objective offline. Quorum of votes to approve failover.
# sentinel monitor
Set the password to connect to the master service
# sentinel auth-pass
We know that the network is unreliable. Sometimes a sentinel will mistakenly think that it is a new one due to network congestion. Master redis is dead. In a sentinel cluster environment, multiple sentinels need to communicate with each other to confirm whether a master is really dead. The quorum parameter is a basis for objective offline, which means that at least quorum sentinels think this If the master fails, the master will be offline and failed over. Because sometimes, a sentinel node may be unable to connect to the master due to its own network reasons, but the master is not faulty at this time. Therefore, multiple sentinels need to agree that there is a problem with the master before proceeding to the next step. operation, which ensures fairness and high availability.
ip and port are
# sentinel00 192.168.157.112 26379 # sentinel01 192.168.157.113 26380 # sentinel02 192.168.157.118 26381
sentinelxxxx.conf File
sentinel26379.conf
bind 0.0.0.0 daemonize yes protected-mode no port 26379 logfile "/myredis/sentinel26379.log" pidfile /var/run/redis-sentinel26379.pid dir /myredis sentinel monitor mymaster 192.168.157.115 6379 2 sentinel auth-pass mymaster 1234
sentinel26380.conf
bind 0.0.0.0 daemonize yes protected-mode no port 26380 logfile "/myredis/sentinel26380.log" pidfile /var/run/redis-sentinel26380.pid dir /myredis sentinel monitor mymaster 192.168.157.115 6379 2 sentinel auth-pass mymaster 1234
sentinel26381. conf
bind 0.0.0.0 daemonize yes protected-mode no port 26381 logfile "/myredis/sentinel26381.log" pidfile /var/run/redis-sentinel26381.pid dir /myredis sentinel monitor mymaster 192.168.157.115 6379 2 sentinel auth-pass mymaster 1234
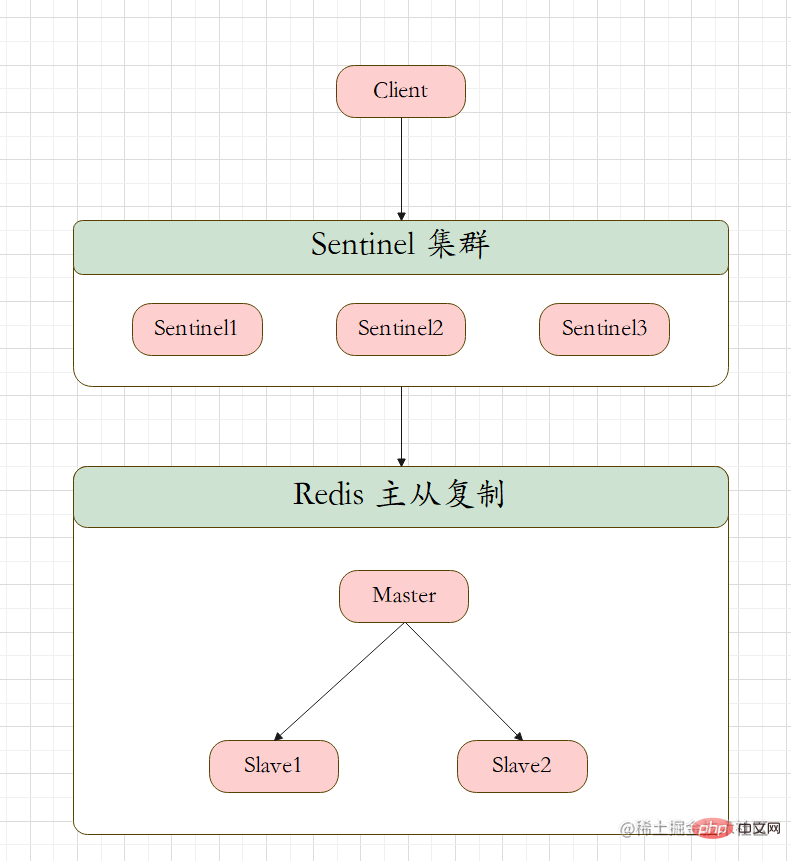
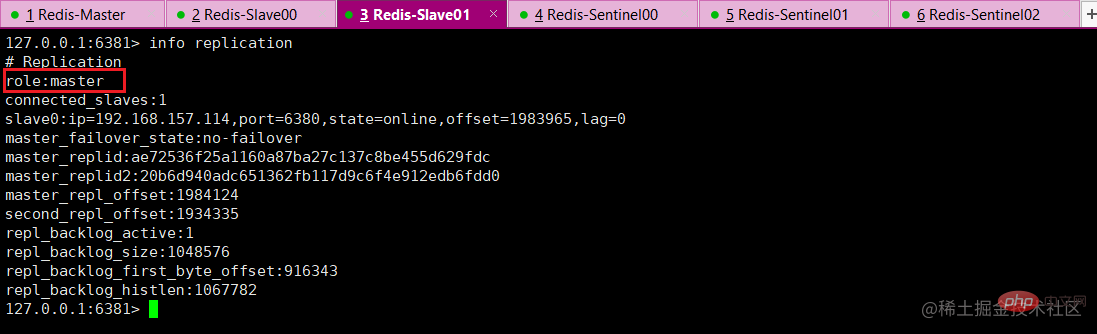
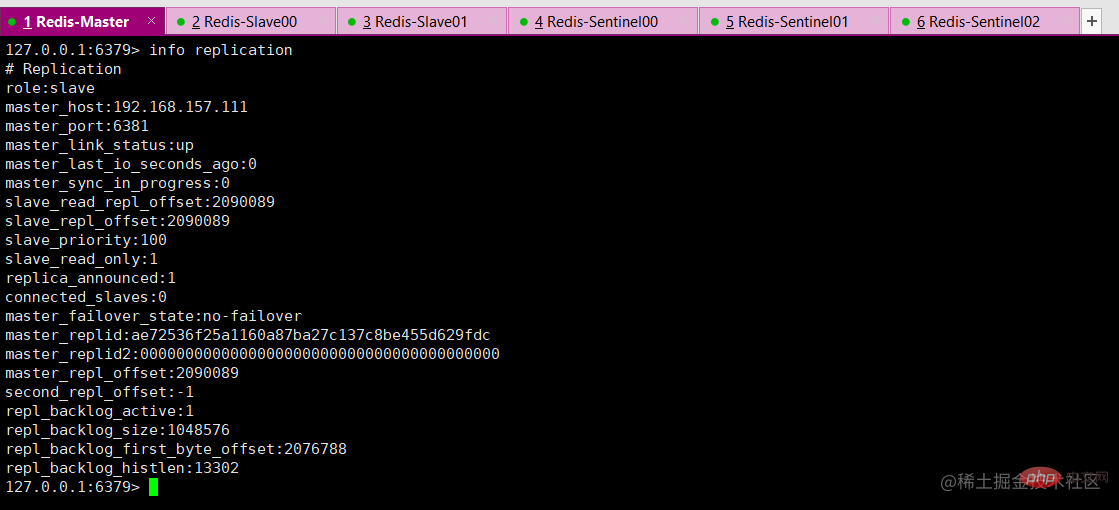
Based on the previous redis replication, start 1 master and 2 slaves to test whether the master-slave replication is normal, enter info replication to check whether it is normal
Start three sentries and complete monitoring
redis-sentinel /myredis/sentinel26379.conf --sentinel redis-sentinel /myredis/sentinel26380.conf --sentinel redis-sentinel /myredis/sentinel26381.conf --sentinel
Test master-slave replication, everything is fine
View log
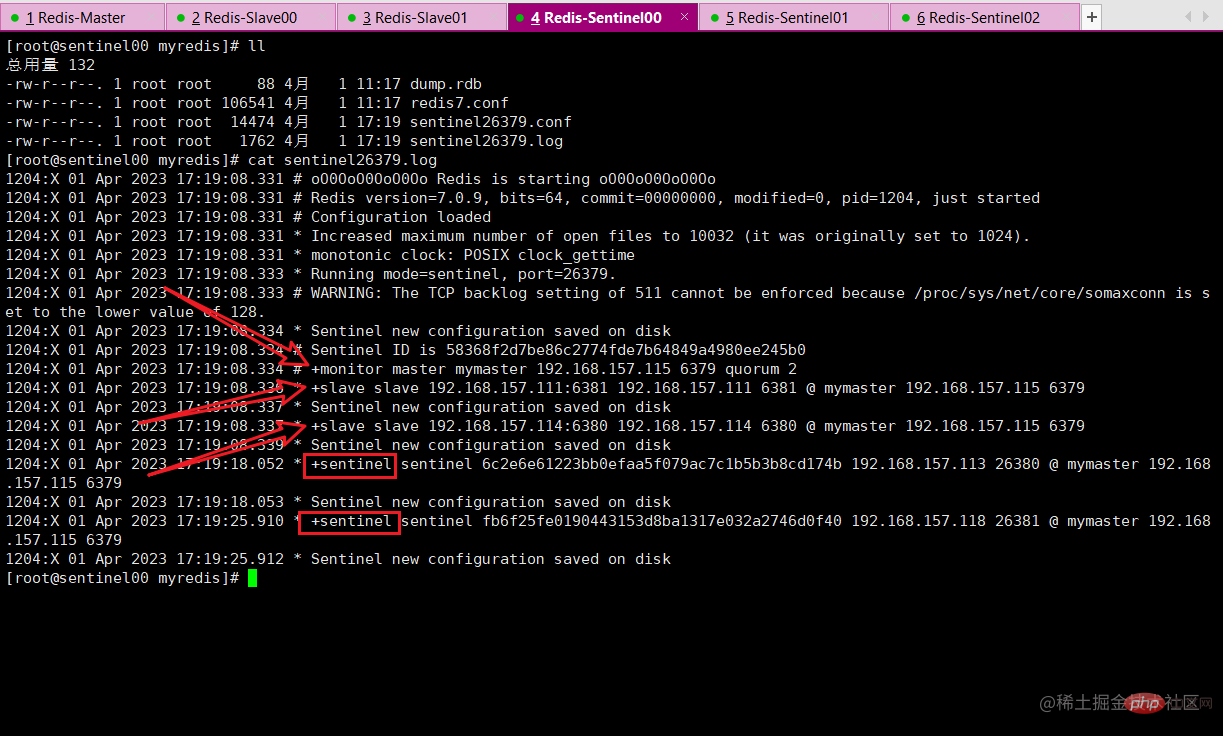
> 后面为自动新增内容
# 模拟宕机 shudown
Problem

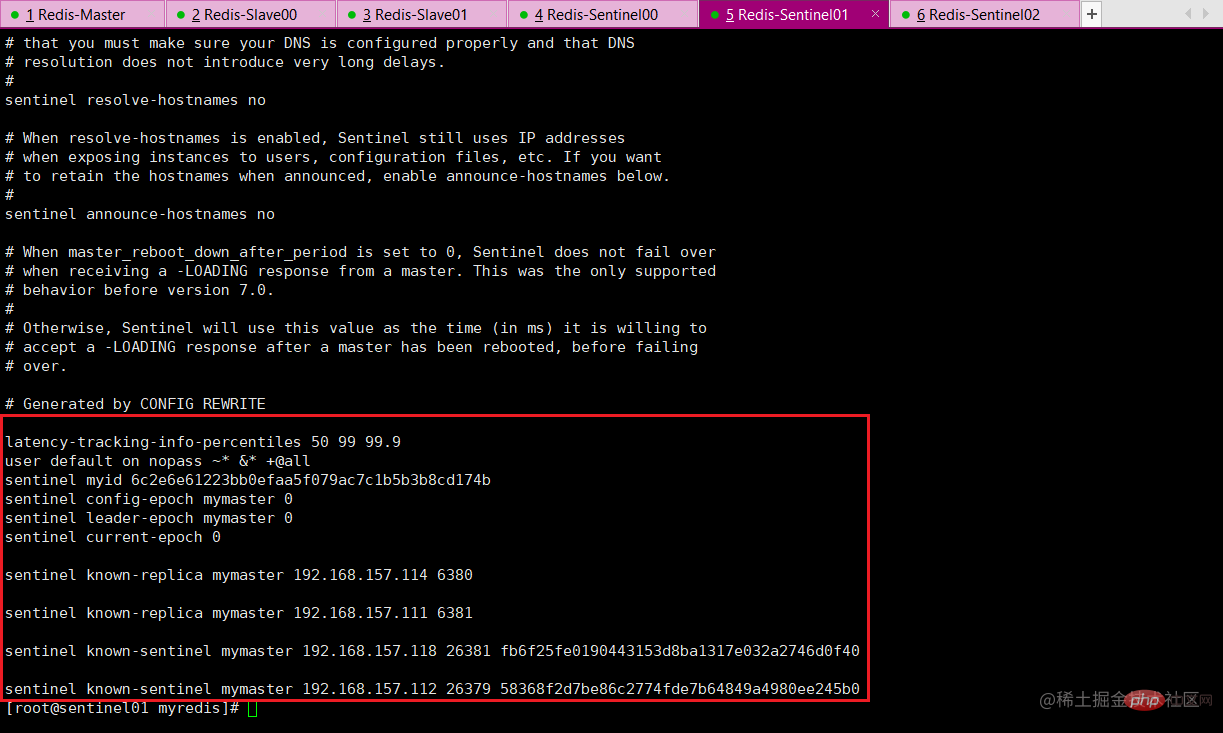
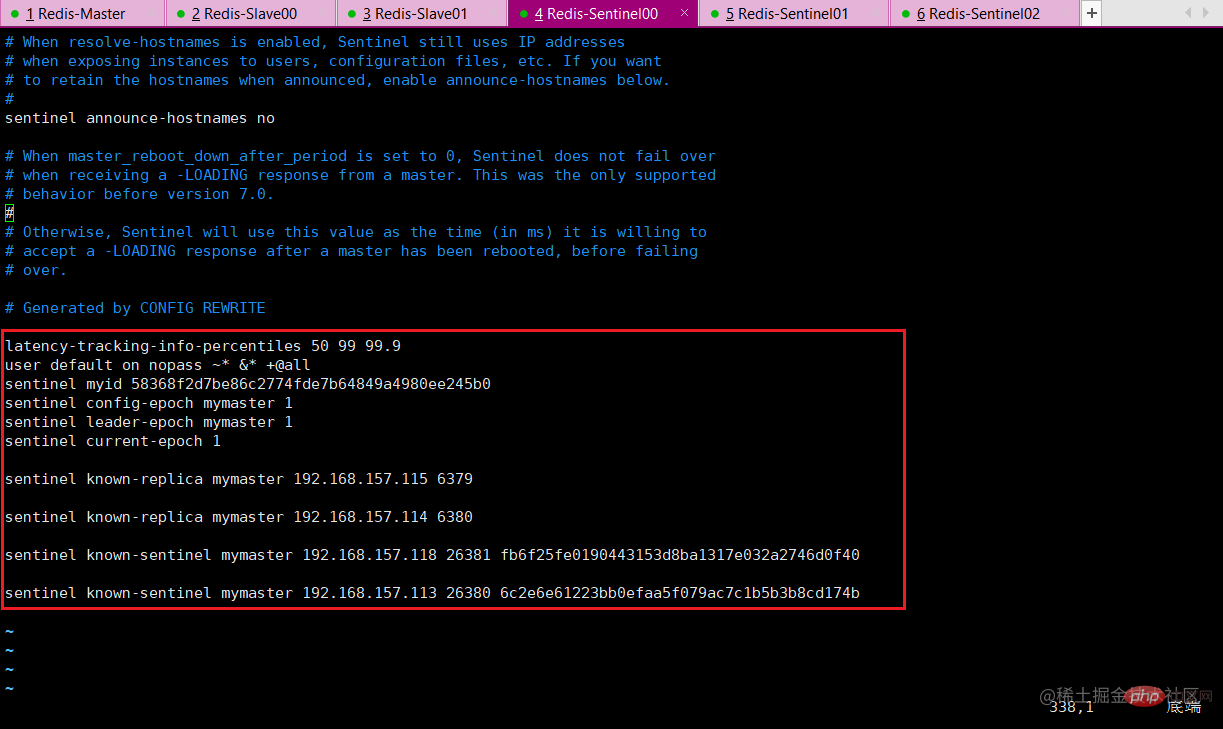
file will be dynamically modified by sentinel during operation. After the master-slave master-slave relationship is switched, the content of the configuration file will automatically change.
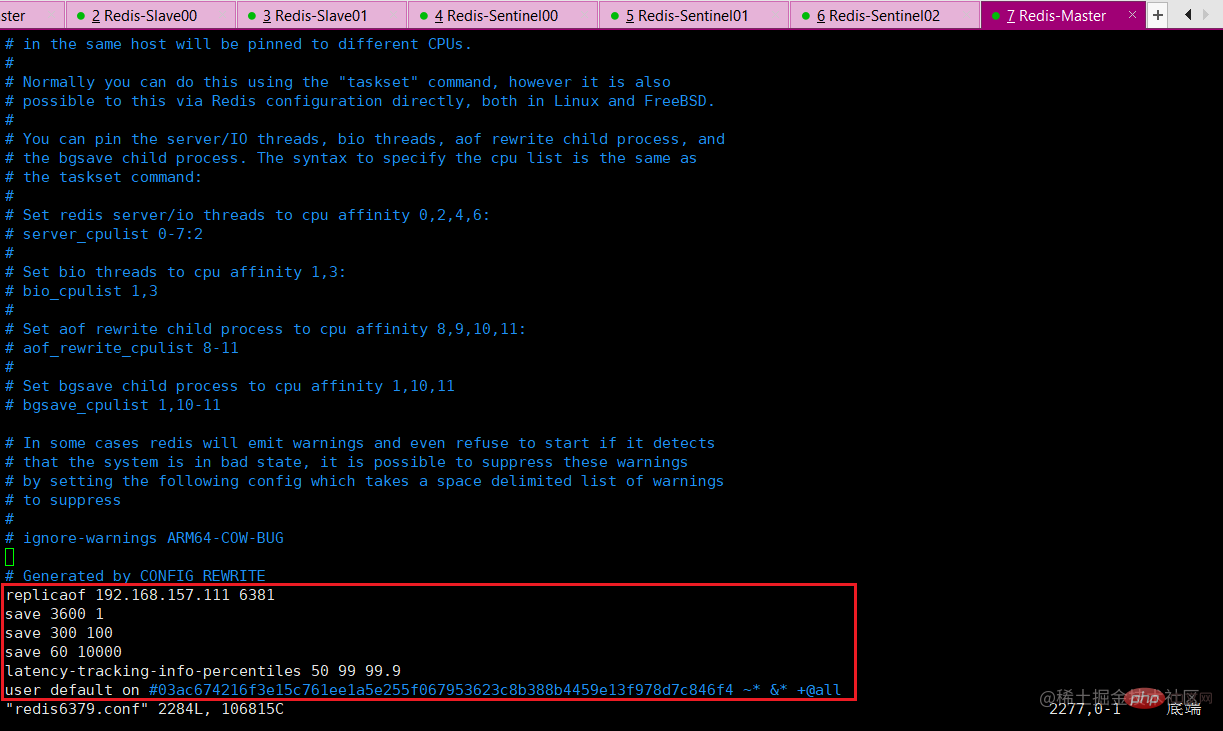
新master
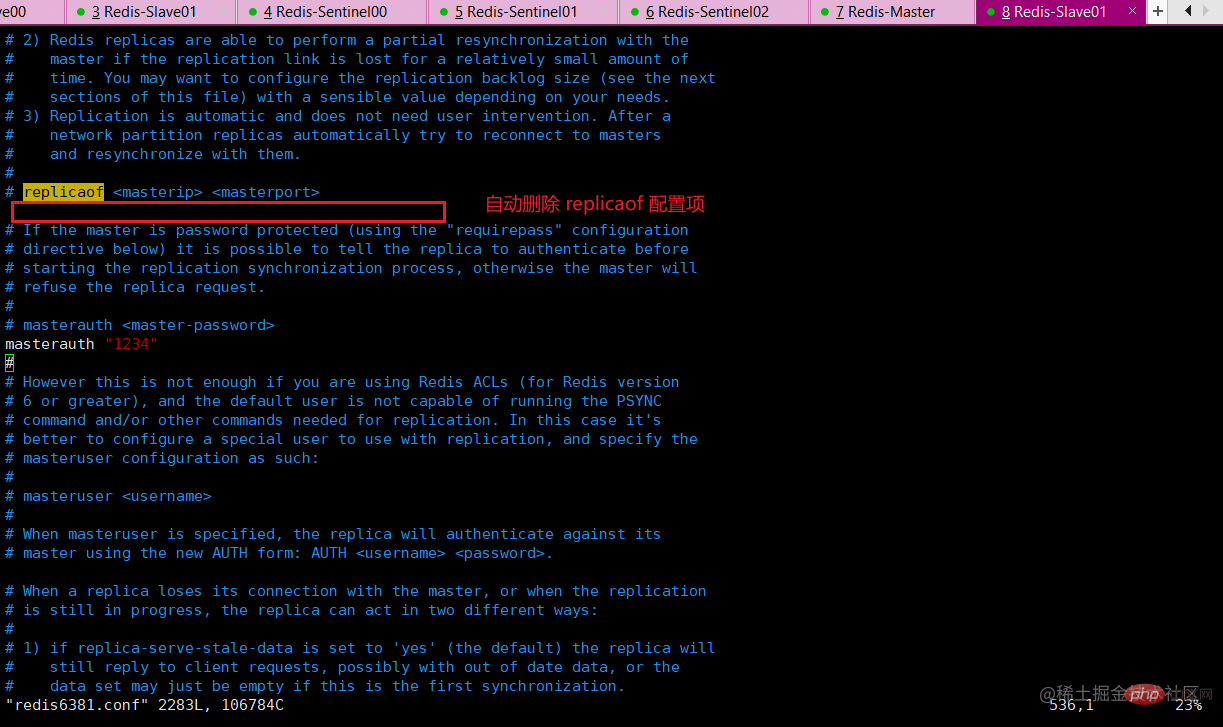
当一个主从配置中的master失效后,sentinel可以选举出一个新的master用于自动替换原master的工作,主从配置中的其他redis服务自动指向新的master同步数据,一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换。
SDOWN(主观不可用)是单个哨兵自己主观检测到的关于master的状态,从sentinel的角度来看,如果发送了PING心跳后,在一定时间内没有收到合法的回复,就到达了SDOQN的条件。
sentinel配置文件中的 down-after-milliseconds 设置了主观下线的时间长度(默认30秒)。
# sentinel down-after-millisecondssentinel down-after-milliseconds mymaster 30000
ODOWN需要一定数量的sentinel,多个哨兵达成一致意见才能确认一个master客观上已经宕机了。
# sentinel monitorsentinel monitor mymaster 127.0.0.1 6379 2
当主节点被判断客观下线后,各个哨兵节点会进行协商,先选举出一个领导者哨兵节点,并由该领导者哨兵节点进行failover(故障迁移)
Raft算法
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得,即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者。
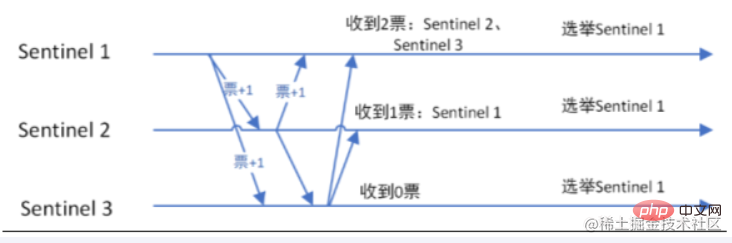
整个过程由sentinel自己独立完成,无需人工干涉。
某一个slave被选中成为master
选出新的master的规则,剩余slave节点健康的前提下
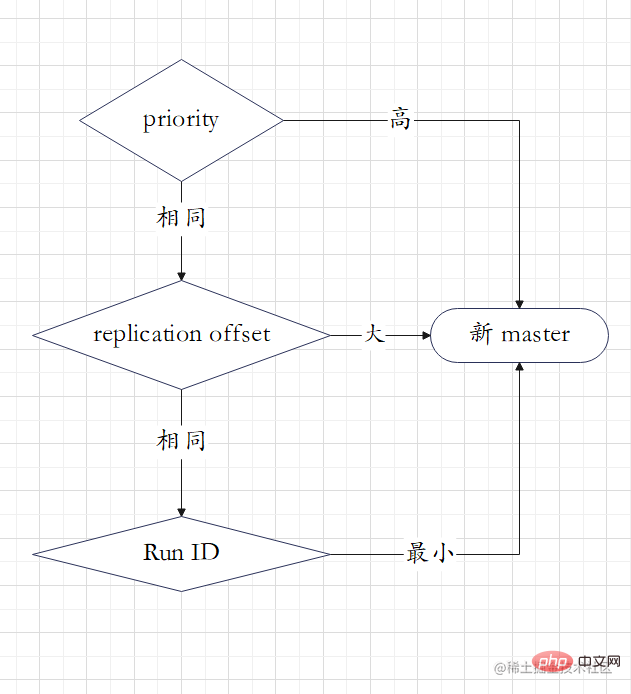
执行 slaveof no one 命令让选出来的从节点成为新的主节点,并通过 slaveof 命令让其他节点成为其从节点。
sentinel leader 会对选举出来的新 master 执行 slaveof no one,将其提升为master节点
sentinel leader 向其他slave发送命令,让剩余的slave成为新的master节点的slave。
更多编程相关知识,请访问:编程视频!!
The above is the detailed content of Understand the sentinel in Redis in depth. For more information, please follow other related articles on the PHP Chinese website!
































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



