


HuggingFace is the most popular machine learning open source community, with 300,000 different machine learning models and 100,000 available applications.
What would it look like if the 300,000 models on HuggingFace could be freely combined to complete new learning tasks together?
In fact, in 2016, when HuggingFace came out, Professor Zhou Zhihua of Nanjing University proposed the concept of “Learnware” and drew such a blueprint.
Recently, the team of Professor Zhou Zhihua of Nanjing University launched such a platform-Beimingwu.
Address: https://bmwu.cloud/
Beimingwu not only provides researchers and users with the opportunity to upload their own models, but also Model matching and collaborative fusion can be performed according to user needs to efficiently handle learning tasks.

Paper address: https://arxiv.org/abs/2401.14427
Beimingwu System warehouse: https://www.gitlink.org.cn/beimingwu/beimingwu
Scientific research toolkit warehouse: https://www.gitlink.org.cn/beimingwu/learnware
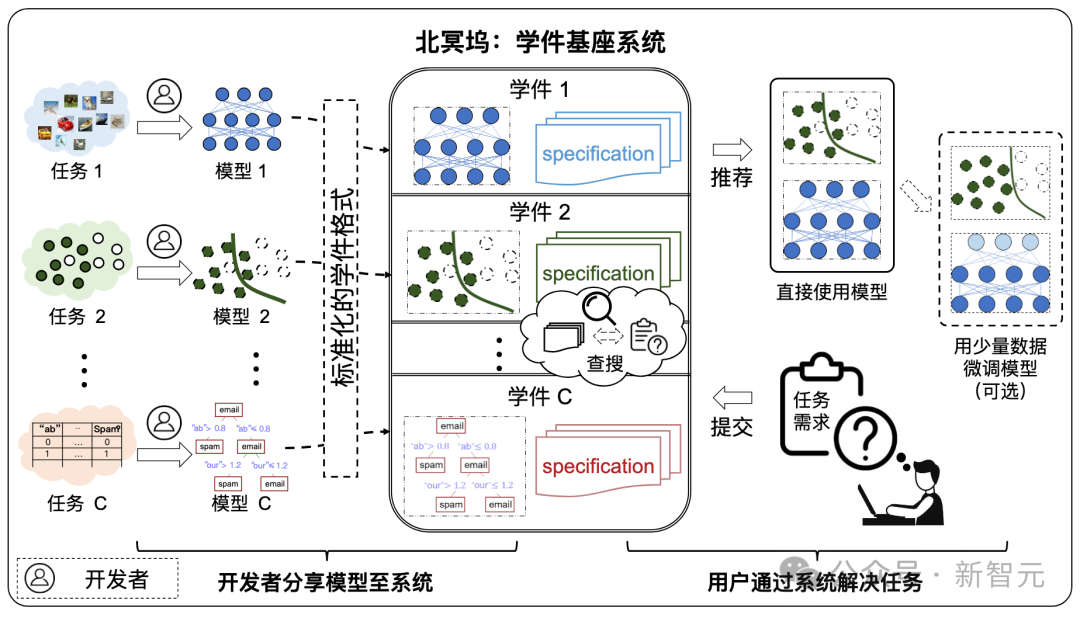
The biggest feature of this platform is the introduction of the Learnware system, which has achieved a breakthrough in model adaptive matching and collaboration capabilities based on user needs.
Learningware consists of a machine learning model and a specification describing the model, that is, "Learningware = Model Specification".
The specification of the learning software consists of two parts: "semantic specification" and "statistical specification":
The specification of the learningware describes the capabilities of the model so that the model can be fully recognized and reused in the future without the user knowing anything about the learningware in advance to meet user needs. .
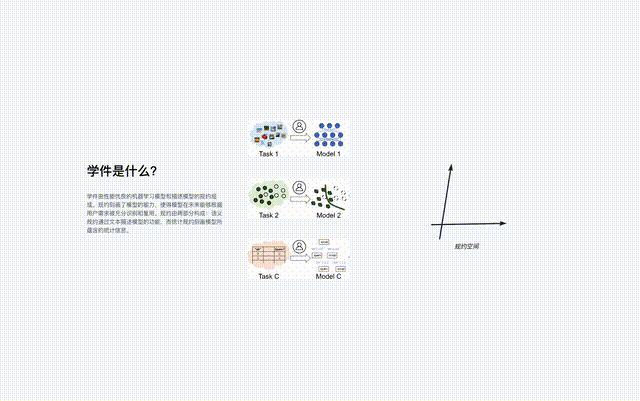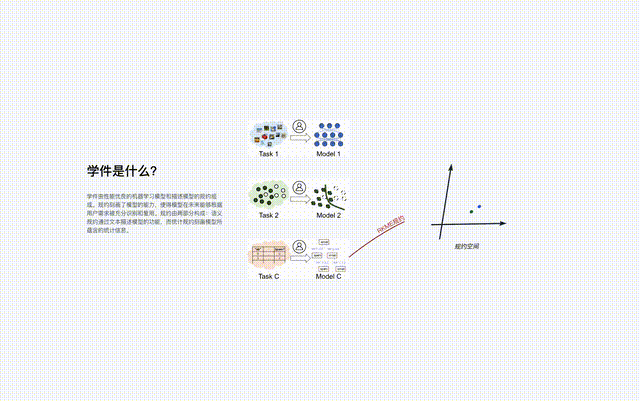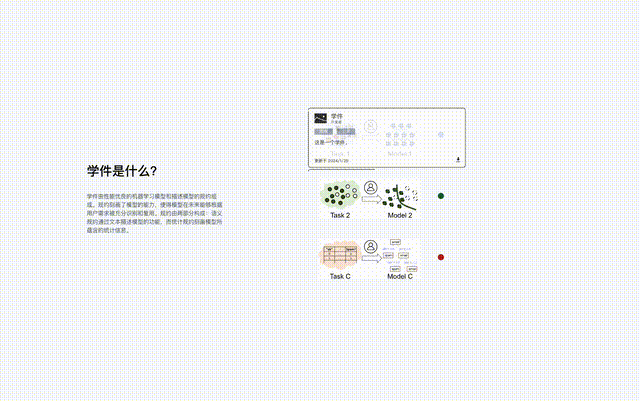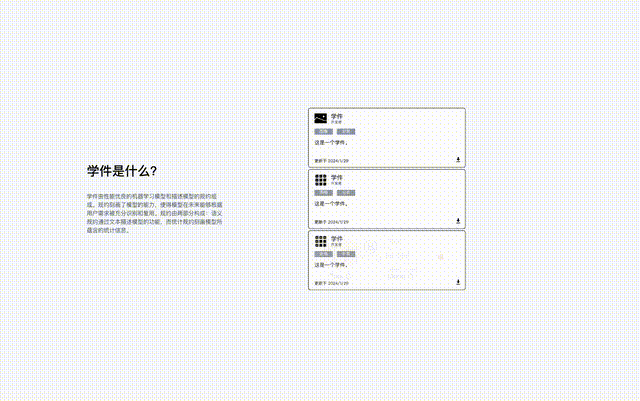
The protocol is the core component of the learningware base system, which connects all the learningware processes in the system, including learningware uploading, organization, Search, deploy and reuse.
Just like Yanziwu in "Dragon Babu" is composed of many small islands, the regulations in Beimingwu are also like small islands.
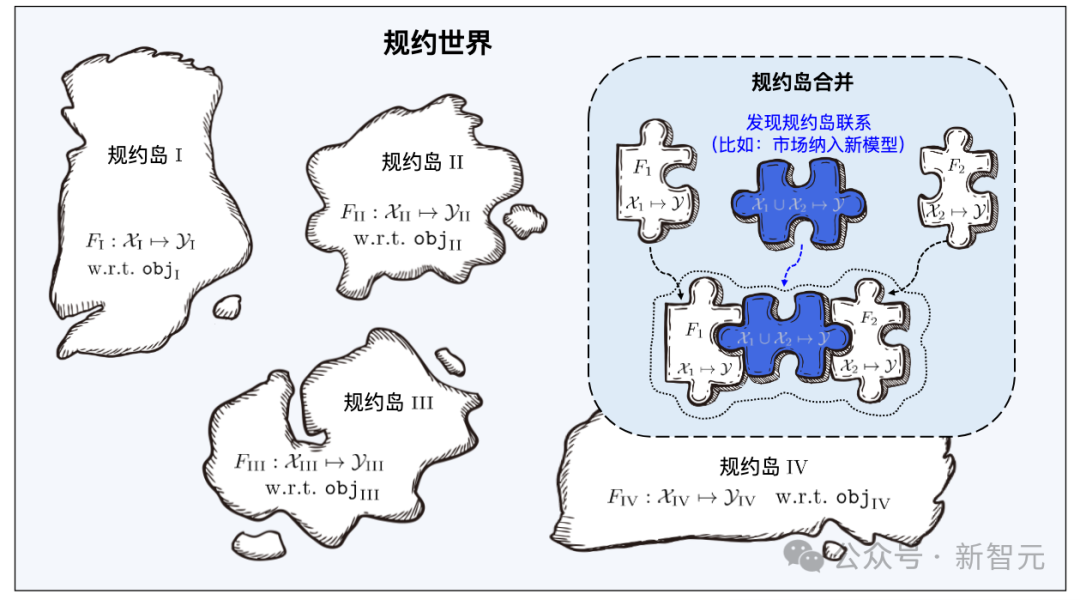
Learnware from different feature/marker spaces constitutes numerous protocol islands, and all protocol islands together constitute the protocol in the learnware base system world. In the protocol world, if the connections between different islands can be discovered and established, then the corresponding protocol islands will be able to be merged.
Under the learningware paradigm, developers around the world can share models to the learningware base system. The system helps users efficiently solve machine learning tasks by effectively searching and reusing learningware. No need to build a machine learning model from scratch.
Beimingwu is the first systematic open source implementation of academicware, providing a preliminary scientific research platform for academicware-related research.
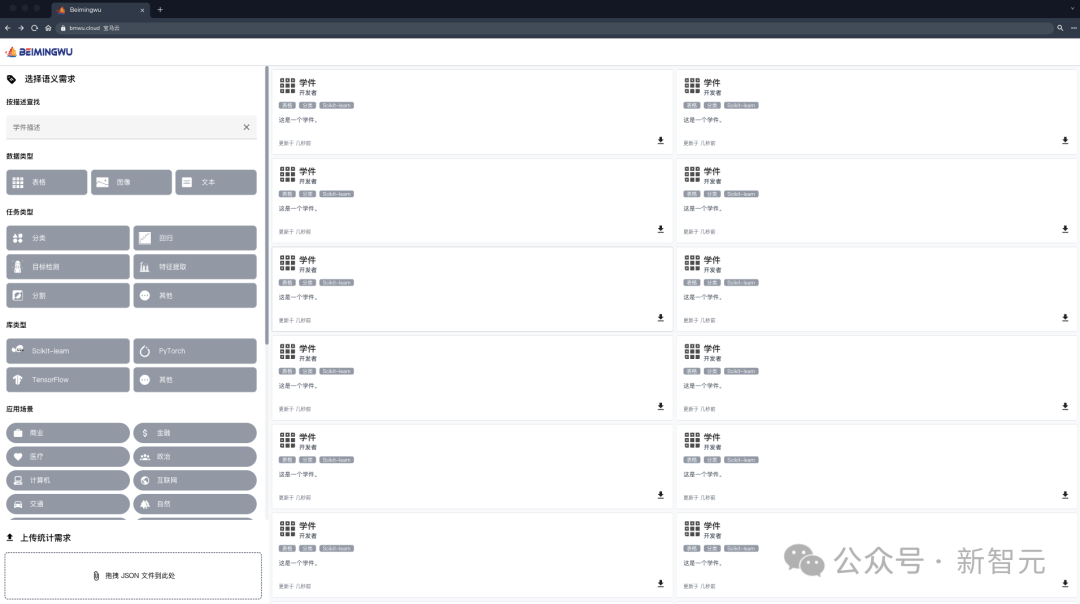
Developers who are willing to share can freely submit models, and the Learning Warehouse assists in generating specifications to form learning software and store them in the Learning Warehouse. In this process, there is no need to disclose your training data to the learning dock.
Future users can submit their requirements to the Learning Warehouse, and with the assistance of the Learning Warehouse, they can search and reuse learning materials to complete their own machine learning tasks, and users do not need to submit to the Learning Warehouse. The dock leaked its own data.
And in the future, after there are millions of learning software in the learning dock, "emergence" behavior may occur: machine learning tasks for which no model has been specially developed in the past may be solved through Solved by reusing several existing learning software.
Machine learning has achieved great success in many fields, but it still faces many problems, such as the need for a large amount of training data and Superior training techniques, difficulties with continuous learning, risk of catastrophic forgetting, and leakage of data privacy/ownership, etc.
Although each of the above problems has corresponding research, because the problems are coupled to each other, solving one of the problems may cause other problems to become more serious.
The learning base system hopes to solve many of the above problems at the same time through an overall framework:
As shown in the figure below, the system workflow is divided into the following two stages:
Protocol is the core component of the learning base system, connecting the system in series Regarding the entire process of learning software, including learning software uploading, organization, search, deployment and reuse.
Learning materials from different feature/marker spaces constitute numerous protocol islands, and all protocol islands together constitute the protocol world in the learning component base system. In the protocol world, if the connections between different islands can be discovered and established, then the corresponding protocol islands will be able to be merged.
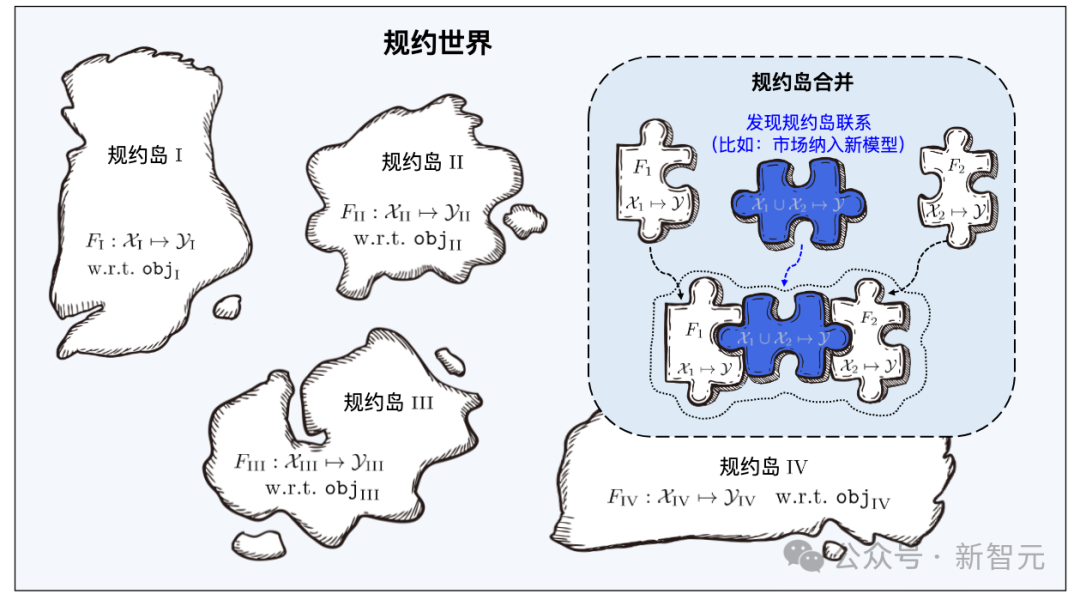
When the learning base system searches, it first locates the specific protocol island through the semantic specifications in the user requirements, and then uses the user requirements to The statistical protocol in the protocol accurately identifies the learning artifacts on the protocol island. The merging of different protocol islands means that the corresponding learning software can be used for tasks in different feature/marker spaces, that is, it can be reused for tasks beyond its original purpose.
Learningware Paradigm builds a unified specification space by making full use of the capabilities of machine learning models shared by the community, and efficiently solves machine learning tasks for new users in a unified manner. As the number of learning pieces increases, by effectively organizing the learning piece structure, the overall ability of the learning piece base system to solve tasks will be significantly enhanced.
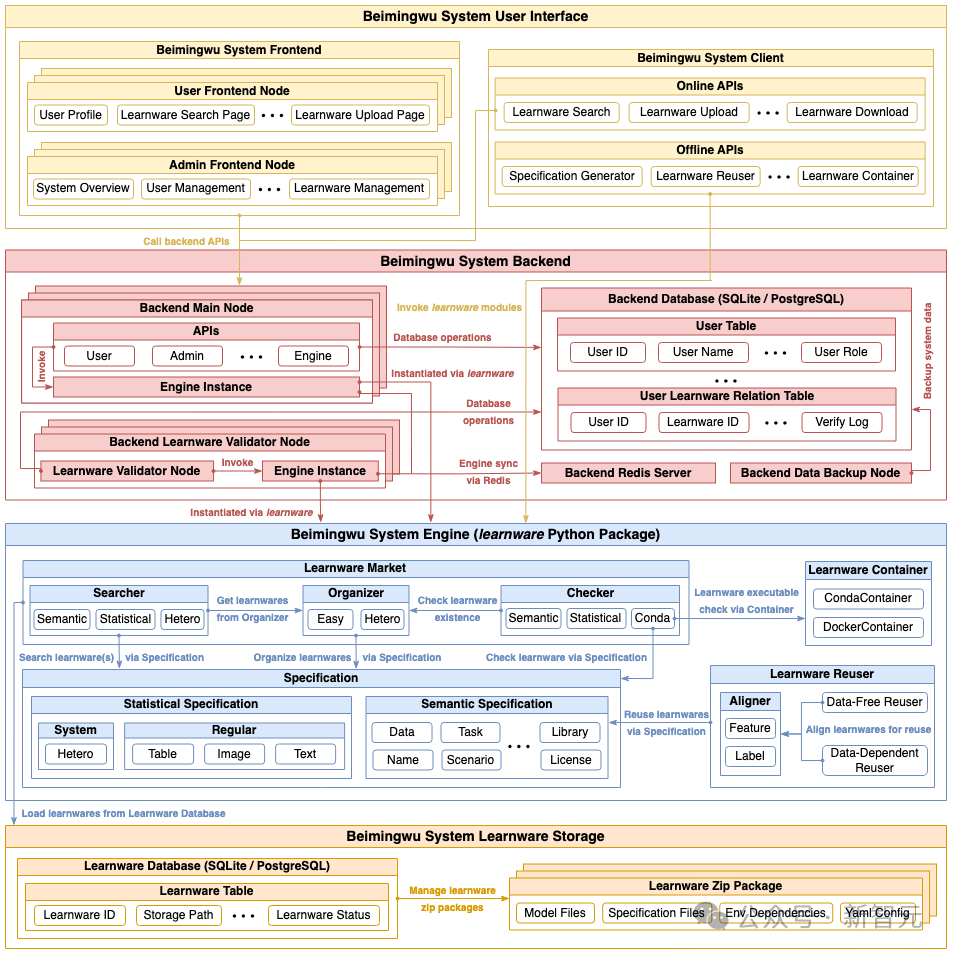
As shown in the figure below, the system architecture of Beimingwu contains four levels, from the learning software storage layer As for the user interaction layer, the learningware paradigm is systematically implemented from the bottom up for the first time. The specific functions of the four levels are as follows:
In the paper, the research team also constructed various types of basic experimental scenarios to evaluate tables, images and text data A benchmark algorithm for specification generation, learning artifact identification and reuse.
Tabular Data Experiment
On various tabular data sets, the team first evaluated the learning software system Performance in identifying and reusing learning artifacts that share the same feature space as user tasks.
Furthermore, since form tasks usually come from different feature spaces, the research team also evaluated the recognition and reuse of learning pieces from different feature spaces.
Homogeneous case
In the homogeneous case, the 53 stores in the PFS dataset act as 53 independent user.
Each store utilizes its own test data as user task data and adopts a unified feature engineering approach. These users can then search the base system for homogeneous learning items that share the same feature space as their tasks.
When the user has no labeled data or the amount of labeled data is limited, the team compared different benchmark algorithms, and the average loss for all users is shown in the figure below. The left table shows that the data-free approach is much better than randomly selecting and deploying a learnware from the market; the right chart shows that when the user has limited training data, identifying and reusing single or multiple learnware is better than user-trained models. Better performance.
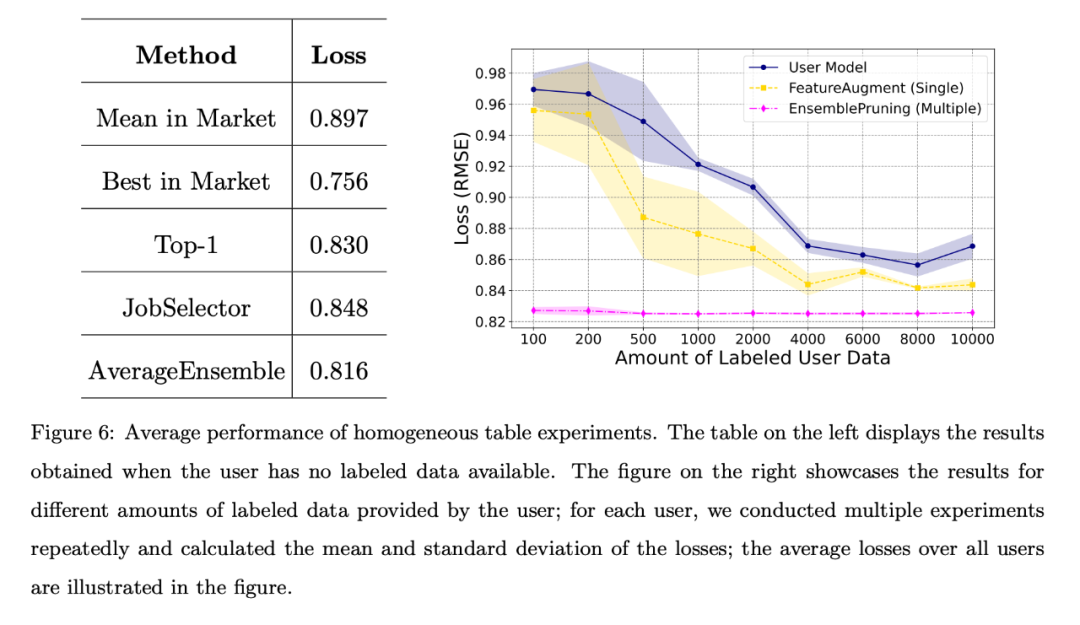
#The left table shows that the data-free approach is much better than randomly selecting and deploying a piece of learning from the market; the right table shows that when the user When training data is limited, identifying and reusing single or multiple learning pieces has better performance than user-trained models.
Heterogeneous cases
Heterogeneous cases can be further divided into for different feature engineering and different task scenarios.
Different feature engineering scenarios:
The results shown on the left in the figure below show that even if the user lacks annotation data, the learning software in the system It can show strong performance, especially the AverageEnsemble method that reuses multiple learning pieces.
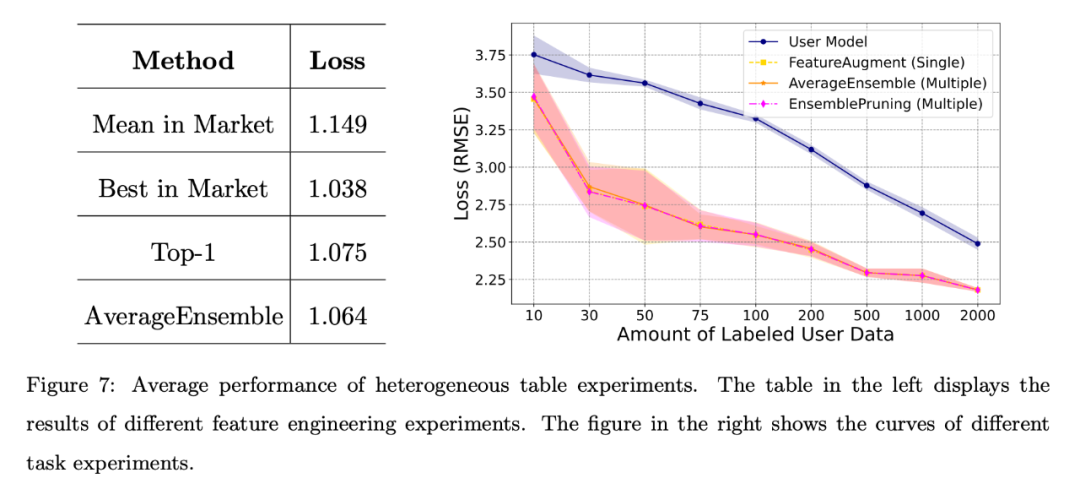
Different task scenarios:
The right picture above shows the user self-training model and several Loss curves for learningware reuse methods.
Obviously, experimental verification of heterogeneous learning pieces is beneficial when the amount of user annotated data is limited, and helps to better align with the user's feature space.
Image and text data experiments
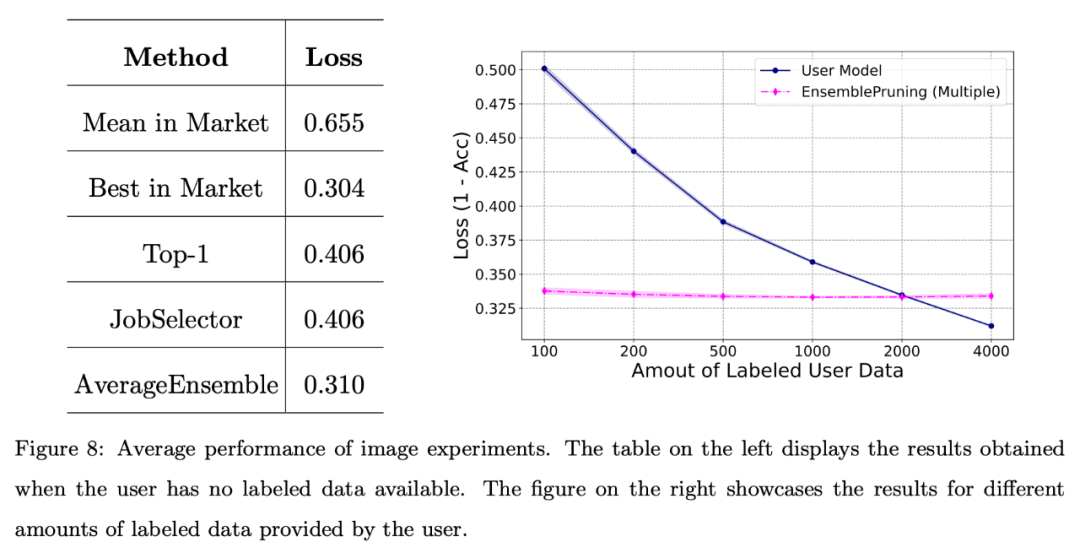
In addition, the research team conducted basic testing of the system on image data sets Evaluate.
The figure below shows that leveraging a learning base system can yield good performance when users face scarcity of annotated data or only have a limited amount of data (fewer than 2000 instances).
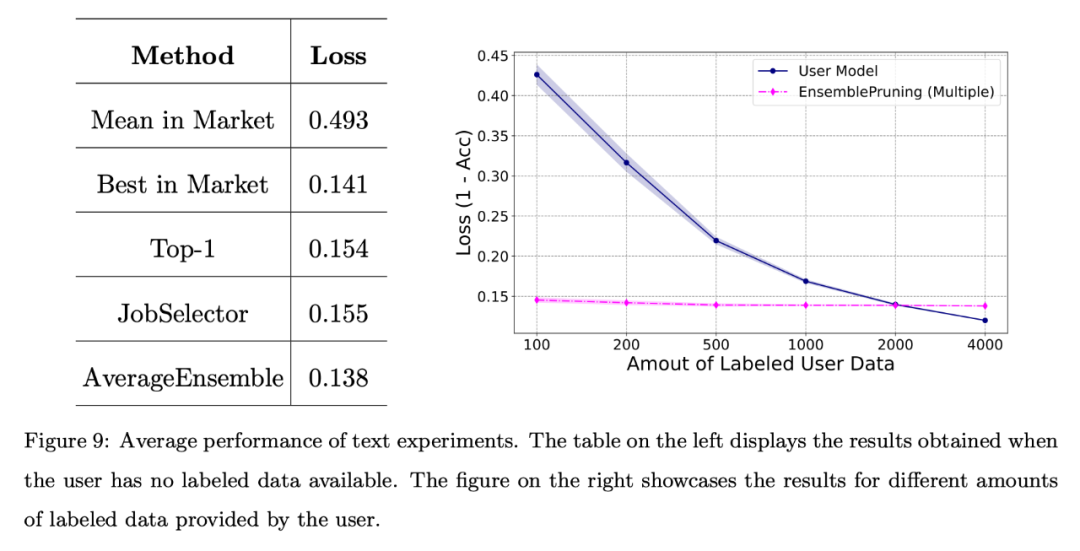
The team also conducted a basic evaluation of the system on a benchmark text dataset. Feature space alignment via a unified feature extractor.
As shown in the figure below, even when no annotation data is provided, the performance obtained through learningware identification and reuse is comparable to the best learningware in the system.
In addition, using the learning base system can reduce approximately 2,000 samples compared to training the model from scratch.
The above is the detailed content of An 8-year masterpiece of NTU Zhou Zhihua's team! The 'learningware' system solves the problem of machine learning reuse, and 'model fusion' emerges a new paradigm of scientific research. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



