


Attention-free large model Eagle7B: Based on RWKV, the inference cost is reduced by 10-100 times
In the AI track, small models have attracted much attention recently. Compared with models with hundreds of billions of parameters, Model. For example, the Mistral-7B model released by the French AI startup outperformed Llama 2 by 13B in every benchmark, and outperformed Llama 1 by 34B in code, math, and inference.
Compared with large models, small models have many advantages, such as low computing power requirements and the ability to run on the device side.
Recently, a new language model has emerged, namely the 7.52B parameter Eagle 7B, from the open source non-profit organization RWKV, which has the following characteristics:


##Eagle 7B is built based on the RWKV-v5 architecture. RWKV (Receptance Weighted Key Value) is a novel architecture that combines the advantages of RNN and Transformer and avoids their shortcomings. It is very well designed and can alleviate the memory and expansion bottlenecks of Transformer and achieve more effective linear expansion. At the same time, RWKV also retains some of the properties that have made Transformer dominant in the field.
Currently RWKV has been iterated to the sixth generation RWKV-6, with performance and size similar to Transformer. Future researchers can use this architecture to create more efficient models.
For more information about RWKV, you can refer to "Reshaping RNN in the Transformer era, RWKV expands the non-Transformer architecture to tens of billions of parameters."
It is worth mentioning that RWKV-v5 Eagle 7B can be used for personal or commercial use without restrictions.
Test results on 23 languages
The performance of different models on multiple languages is as follows, Test benchmarks include xLAMBDA, xStoryCloze, xWinograd, and xCopa.
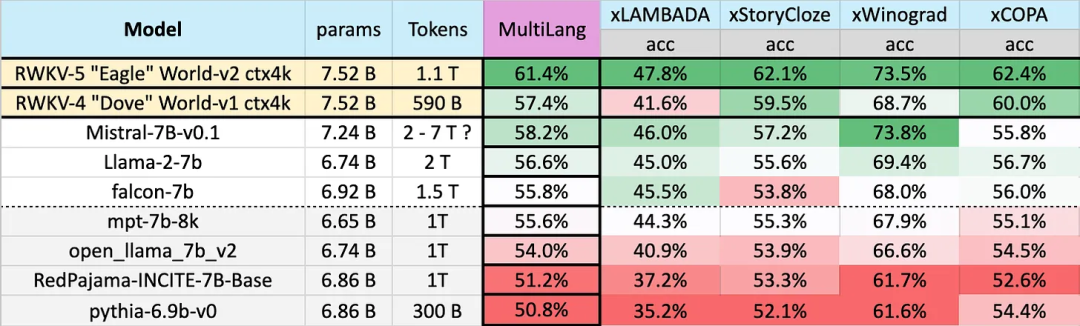
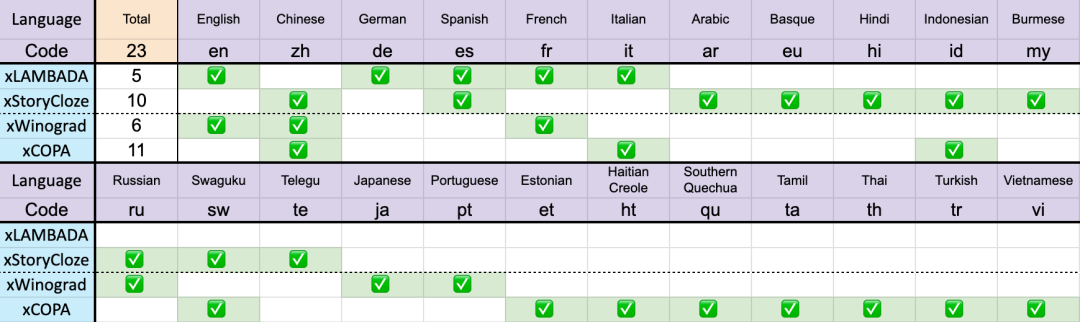
These benchmarks incorporate mostly common sense reasoning and show the huge leap in multi-language performance of the RWKV architecture from v4 to v5. However, due to the lack of multilingual benchmarks, the study can only test its ability in 23 more commonly used languages, and the ability in the remaining 75 or more languages is still unknown.
Performance in English
The performance of different models in English is judged through 12 benchmarks, including Common sense reasoning and world knowledge.

Additionally, v5 performance starts to align with expected Transformer performance levels given the approximate token training statistics.
Previously, Mistral-7B used a training method of 2-7 trillion Tokens to maintain its lead in the 7B scale model. The study hopes to close this gap so that RWKV-v5 Eagle 7B surpasses llama2 performance and reaches the level of Mistral. The following figure shows that RWKV-v5 Eagle 7B's checkpoints near 300 billion token points show similar performance to pythia-6.9b: This is consistent with previous experiments (pile-based) on the RWKV-v4 architecture, where linear transformers like RWKV are similar in performance level to transformers and have the same number of tokens. train. # Predictably, the emergence of this model marks the arrival of the strongest linear transformer (in terms of evaluation benchmarks) to date. 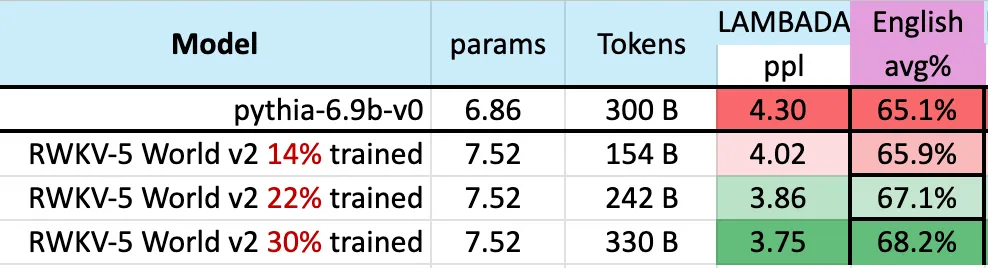
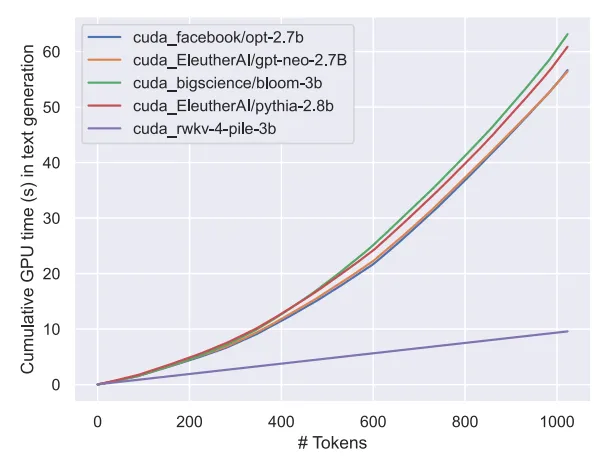
The above is the detailed content of Attention-free large model Eagle7B: Based on RWKV, inference cost is reduced by 10-100 times. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



