


Memory-based Redis should be the most commonly used key-value database in various web development businesses. We often use it to store user login status (Session storage) in our business. Accelerate some hot data queries (compared to mysql, the speed is improved by orders of magnitude), build simple message queues (LPUSH and BRPOP), subscription publishing (PUB/SUB) systems, etc. Larger Internet companies generally have dedicated teams to provide Redis storage as a basic service to various business calls.
However, any provider of basic services will be asked by the caller: Is your service highly available? It's best not to cause my business to suffer because of frequent problems with your service. Recently, I also built a small "highly available" Redis service in my project. Here is my summary and reflection.
First of all, we need to define what constitutes high availability for the Redis service, that is, it can still provide services normally under various abnormal circumstances. Or be more relaxed. In the event of an abnormality, normal services can be restored after only a short period of time. The so-called exception should include at least the following possibilities:
[Exception 1] A process of a certain node server suddenly went down (for example, a developer was handicapped and the redis-server process of a server was down. Killed)
[Exception 2] A certain node server is down, which is equivalent to all processes on this node being stopped (for example, an operation and maintenance handicap unplugs the power of a server; for example, some old The machine has a hardware failure)
[Exception 3] The communication between any two node servers is interrupted (for example, a temporary worker with a handicapped hand dug out the optical cable used for communication between two computer rooms)
In fact, any of the above exceptions are small probability events, and the basic guiding idea for achieving high availability is: the probability of multiple small probability events occurring at the same time is negligible. High availability can be achieved as long as we design the system to tolerate a single point of failure for a short period of time.
There are many solutions on the Internet for building high-availability Redis services, such as Keepalived, Codis, Twemproxy, and Redis Sentinel. Among them, Codis and Twemproxy are mainly used in large-scale Redis clusters. They were also open source solutions provided by twitter and Wandoujia before Redis officially released Redis Sentinel. The amount of data in my business is not large, so cluster services are a waste of machines. Finally, I made a choice between Keepalived and Redis Sentinel, and chose the official solution Redis Sentinel.
Redis Sentinel can be understood as a process that monitors whether the Redis Server service is normal, and once an abnormality is detected, the backup (slave) Redis Server can be automatically enabled, allowing external users to detect abnormalities that occur within the Redis service. No perception. We follow the steps from simple to complex to build a minimal and highly available Redis service.
Option 1: Stand-alone version of Redis Server, without Sentinel
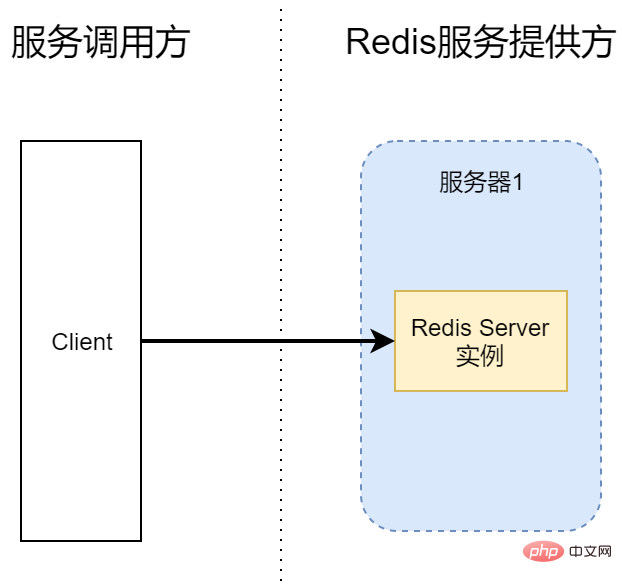
Under normal circumstances, we use For personal websites, or during daily development, a single instance of Redis Server will be set up. The caller can directly connect to the Redis service, and even the Client and Redis themselves are on the same server. This combination is only suitable for personal study and entertainment. After all, there will always be a single point of failure in this configuration that cannot be solved. Once the Redis service process hangs, or server 1 is shut down, the service will be unavailable. And if Redis data persistence is not configured, the data already stored in Redis will also be lost.
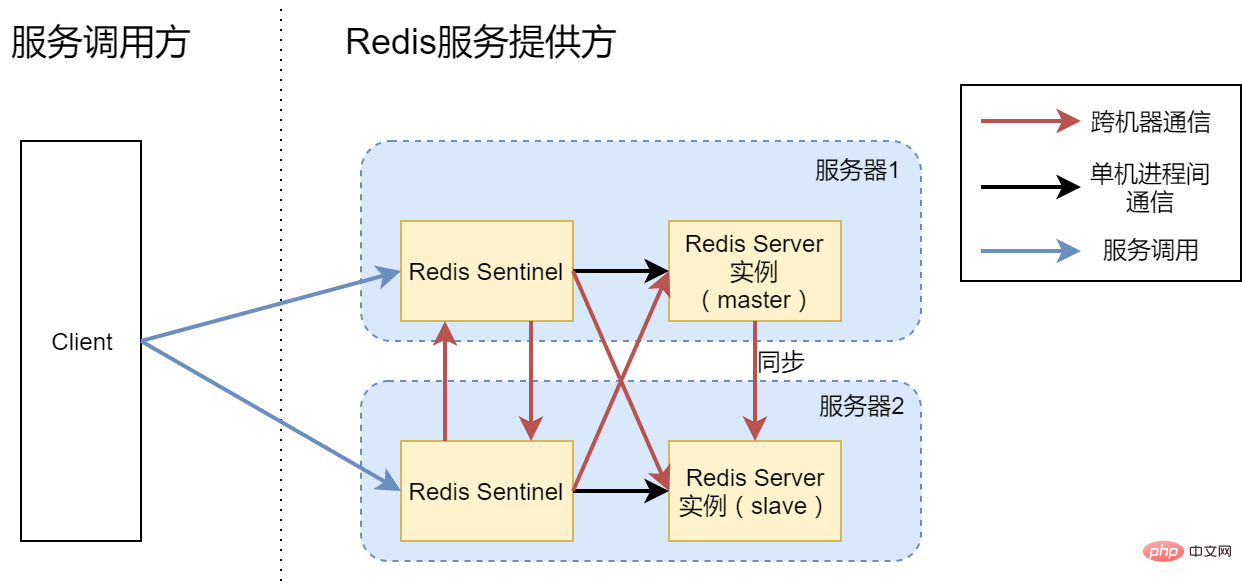
Option 2: Master-slave synchronization Redis Server, single instance Sentinel

In order to achieve high availability, For the single point of failure problem described in Solution 1, we must add a backup service, that is, start a Redis Server process on each of the two servers. Generally, the master provides services, and the slave is only responsible for synchronization and backup. At the same time, an additional Sentinel process is started to monitor the availability of two Redis Server instances so that when the master hangs up, the slave can be promoted to the role of the master in time to continue providing services. This achieves the high availability of Redis Server. This is based on a high-availability service design basis, that is, a single point of failure itself is a small probability event, and multiple single point failures at the same time (that is, the master and the slave hang up at the same time) can be considered a (basically) impossible event.
For the caller of the Redis service, it is the Redis Sentinel service that needs to be connected now, not the Redis Server. The common calling process is that the client first connects to Redis Sentinel and asks which service in the current Redis Server is the master and which is the slave, and then connects to the corresponding Redis Server for operation. Of course, current third-party libraries have generally implemented this calling process, and we no longer need to implement it manually (such as Nodejs' ioredis, PHP's predis, Golang's go-redis/redis, JAVA's jedis, etc.).
However, after we implemented the master-slave switching of the Redis Server service, a new problem was introduced, that is, Redis Sentinel itself is also a single-point service. Once the Sentinel process hangs, the client has nothing to do. Linked to Sentinel. Therefore, the configuration of option 2 cannot achieve high availability.
Solution 3: Master-slave synchronization Redis Server, dual instance Sentinel
For solution 2 Question, we also start an additional Redis Sentinel process. The two Sentinel processes provide service discovery functions for the client at the same time. For the client, it can connect to any Redis Sentinel service to obtain basic information about the current Redis Server instance. Normally, we configure multiple Redis Sentinel link addresses on the client side. Once the client finds that a certain address cannot be connected, it will try to connect to other Sentinel instances. Of course, this does not require us to implement it manually. In various development languages The more popular redis connection libraries have helped us realize this function. Our expectation is that even if one of the Redis Sentinels hangs up, there will be another Sentinel that can provide services.
However, the vision is beautiful, but the reality is very cruel. Under such an architecture, it is still impossible to achieve high availability of the Redis service. In the schematic diagram of Option 3, the red line is the communication between the two servers, and the abnormal scenario we envisage ([Exception 2]) is that a certain server is down as a whole. We might as well assume that Server 1 is down. At this time, only Redis Sentinel and slave Redis Server processes on server 2. At this time, Sentinel will not actually switch the remaining slave to the master to continue the service, which will cause the Redis service to be unavailable, because the setting of Redis is that only when more than 50% of the Sentinel processes can connect and vote for the new master , master-slave switching will actually occur. In this example, only one of the two Sentinels can be connected, which is equal to 50% and is not in a scenario where master-slave switching is possible.
You may ask, why does Redis have this 50% setting? Assuming that we allow less than or equal to 50% of Sentinel connectivity, master-slave switching can also be performed. Just imagine [Exception 3], that is, the network between server 1 and server 2 is interrupted, but the server itself is operational. As shown in the figure below:
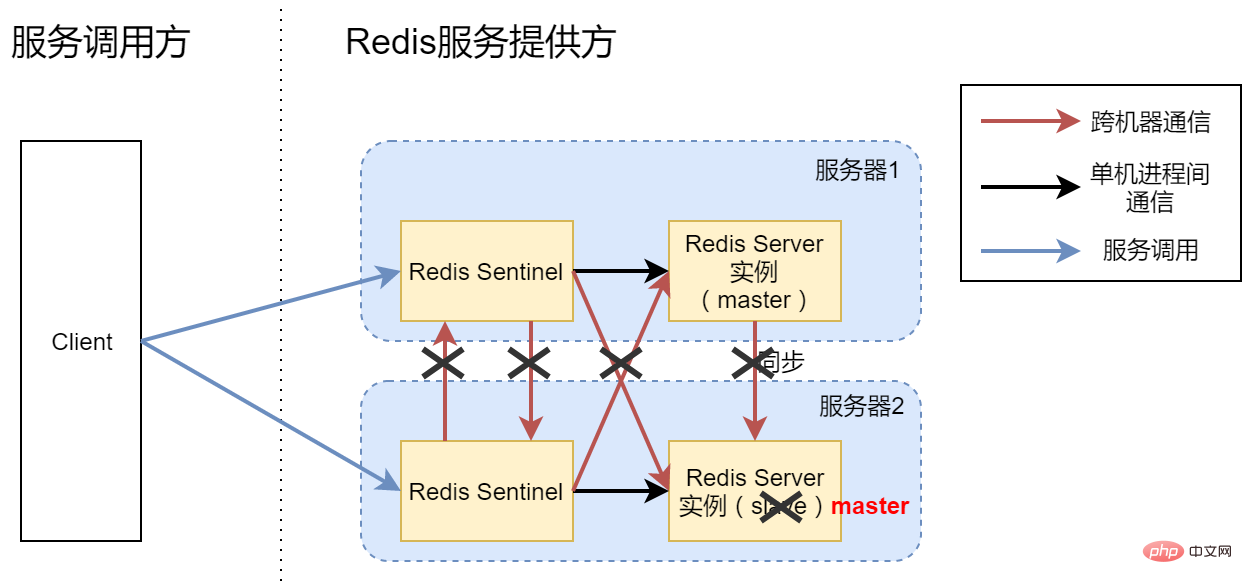
In fact, for server 2, if server 1 is directly down, it has the same effect as if server 1 is unable to connect to the network. Anyway, it will suddenly become unavailable. Any communication was carried out. Assume that when the network is interrupted, we allow Sentinel of server 2 to switch slave to master. The result is that you now have two Redis Servers that can provide services to the outside world. Any addition, deletion, and modification operations performed by the Client may fall on the Redis of Server 1 or the Redis of Server 2 (depending on which Sentinel the Client is connected to), causing data confusion. Even if the network between Server 1 and Server 2 is restored later, we will not be able to unify the data (two different data, who should we trust?), and the data consistency is completely destroyed.
Option 4: Master-slave synchronization Redis Server, three instances of Sentinel
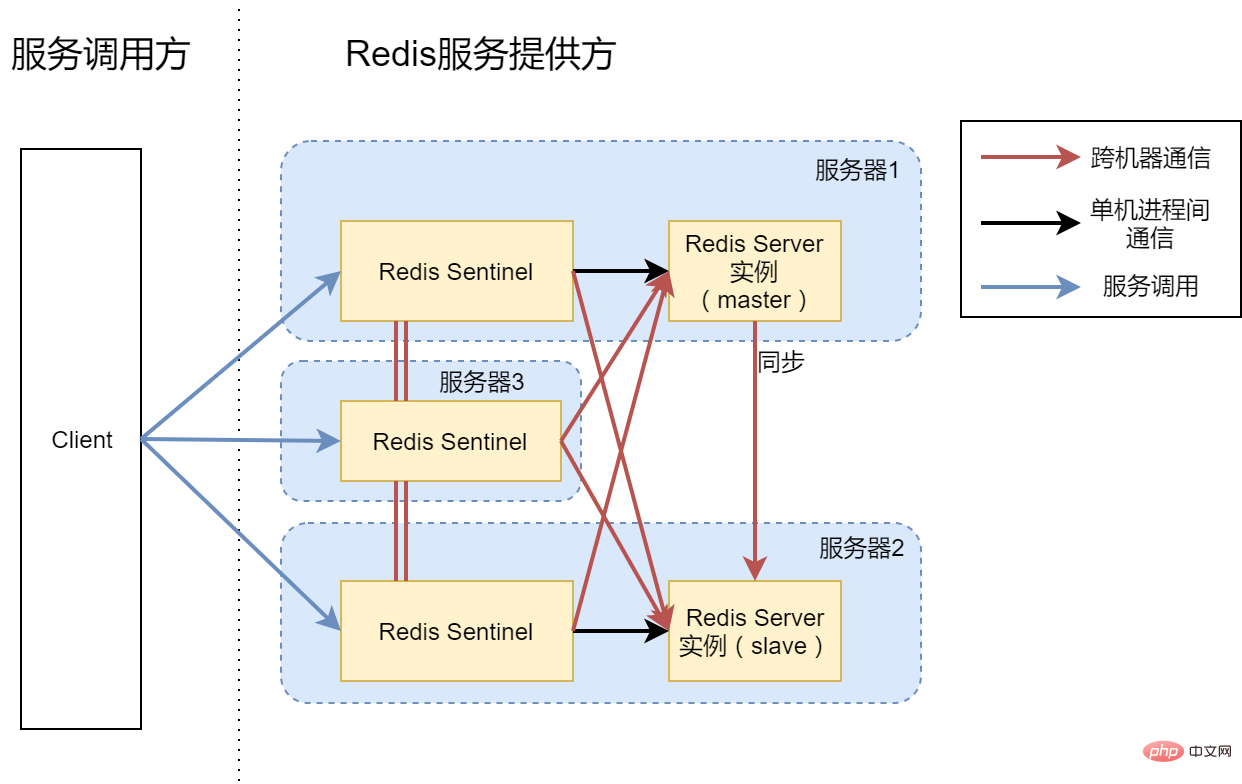
In view of the fact that option 3 does not To achieve high availability, our final version is Solution 4 shown in the figure above. In fact, this is the architecture we ended up building. We introduced server 3 and built a Redis Sentinel process on top of 3. Now three Sentinel processes manage two Redis Server instances. In this scenario, regardless of whether it is a single process failure, a single machine failure, or a network communication failure between two machines, Redis services can continue to be provided to the outside world.
In fact, if your machine is relatively idle, of course you can also open a Redis Server on server 3 to form a 1 master 2 slave architecture. Each data has two backups, and the availability will be improved. . Of course, the more slaves, the better. After all, master-slave synchronization also requires time.
In scenario 4, once the communication between server 1 and other servers is completely interrupted, servers 2 and 3 will switch slave to master. For the client, there are 2 masters providing services at this moment, and once the network is restored, all new data that fell on server 1 during the outage will be lost. If you want to partially solve this problem, you can configure the Redis Server process so that when it detects a problem with its own network, it will stop the service immediately to avoid new data coming in during the network failure (refer to Redis's min-slaves-to -write and min-slaves-max-lag two configuration items).
So far, we have built a highly available Redis service using 3 machines. In fact, there is a more machine-saving way on the Internet, which is to place a Sentinel process on the Client machine instead of the service provider's machine. It's just that in the company, the providers and callers of general services do not come from the same team. When two teams operate the same machine together, it is easy for misoperations to occur due to communication problems. Therefore, out of human factors considerations, we still adopted the architecture of Option 4. And since there is only one Sentinel process running on Server 3, it does not consume much server resources. Server 3 can also be used to run some other services.
Ease of use: Use Redis Sentinel like a stand-alone version of Redis
As a service provider, we always talk about users Experience issues. Among the above solutions, there is always something that makes it not so comfortable for the client to use. For the stand-alone version of Redis, the client directly connects to the Redis Server. We only need to give an IP and port, and the client can use our service. After transforming into Sentinel mode, the Client has to use some external dependency packages that support Sentinel mode, and also has to modify its own Redis connection configuration, which is obviously unacceptable to "pretentious" users. Is there any way to provide services by only giving the Client a fixed IP and port like using the stand-alone version of Redis?
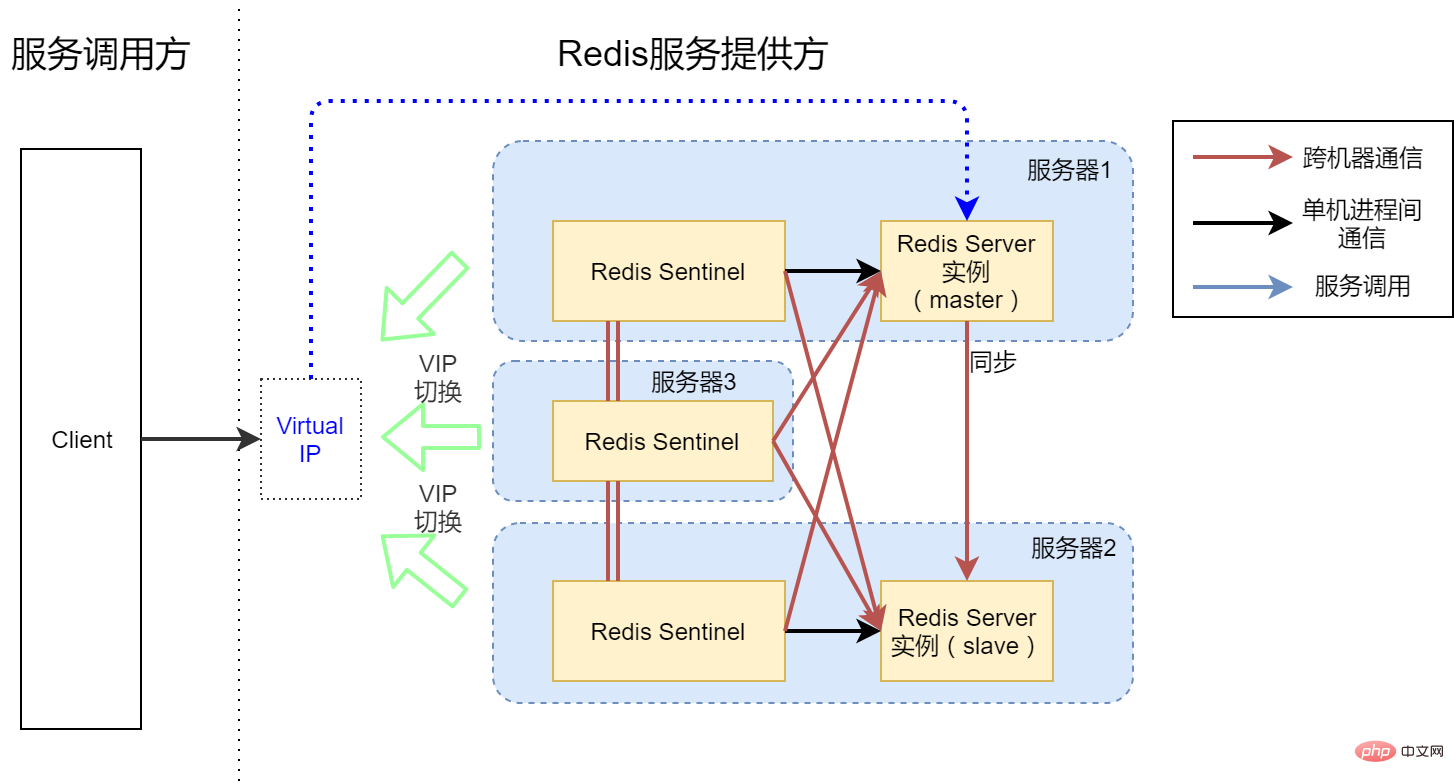
The answer is of course yes. This may require the introduction of virtual IP (Virtual IP, VIP), as shown in the figure above. We can point the virtual IP to the server where the Redis Server master is located. When a Redis master-slave switch occurs, a callback script will be triggered. The callback script switches the VIP to the server where the slave is located. In this way, for the client, it seems that he is still using a stand-alone version of the highly available Redis service.
Conclusion
It is actually very simple to build any service and make it “usable”, just like we run a stand-alone version Redis. But once you want to achieve "high availability", things become complicated. Two additional servers are used in the business, three Sentinel processes and one Slave process, just to ensure that the service is still available in the unlikely event of an accident. In actual business, we also enable supervisor for process monitoring. Once the process exits unexpectedly, it will automatically try to restart.
Recommended learning: Redis video tutorial
The above is the detailed content of Highly available Redis service architecture analysis and construction. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



