

Redis is currently one of the most popular in-memory databases. By reading and writing data in memory, it greatly improves the reading and writing speed. It can be said that Redis is an indispensable part of achieving high concurrency on the website. [Recommended learning:Redis video tutorial]

When we use Redis, we will come into contact with the five object types of Redis (string, hash, list , collections, ordered collections), rich types are a major advantage of Redis over Memcached, etc. On the basis of understanding the usage and characteristics of the five object types of Redis, further understanding of the memory model of Redis will be of great help to the use of Redis, for example:
1. Estimating the memory usage of Redis. So far, the cost of using memory is still relatively high, and memory cannot be used without scruples. Reasonably evaluating the memory usage of Redis based on the needs and choosing the appropriate machine configuration can save costs while meeting the needs.
2. Optimize memory usage. Understanding the Redis memory model allows you to choose more appropriate data types and encodings and make better use of Redis memory.
3. Analyze and solve problems. When problems such as blocking and memory usage occur in Redis, the cause of the problem should be discovered as soon as possible to facilitate analysis and solution.
This article mainly introduces the memory model of Redis (taking 3.0 as an example), including the memory occupied by Redis and how to query it, the encoding methods of different object types in memory, the memory allocator (jemalloc), Simple dynamic string (SDS), RedisObject, etc.; and then introduce the applications of several Redis memory models on this basis.
If you want to do your job well, you must first sharpen your tools. Before explaining Redis memory, first explain how to count the memory usage of Redis.
After the client connects to the server through redis-cli (if there is no special instructions later, the client will always use redis-cli), you can check the memory usage through the info command:
info memory
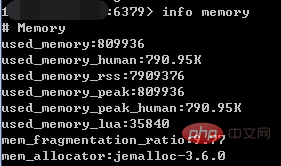
Among them, the info command can display a lot of information about the redis server, including basic server information, CPU, memory, persistence, client connection information, etc.; memory is a parameter, indicating that only memory-related information will be displayed.
Some of the more important instructions in the returned results are as follows:
(1)used_memory:The total amount of memory allocated by the Redis allocator (unit is bytes), including the virtual memory used (i.e. swap); the Redis allocator will be introduced later. used_memory_human just appears more friendly.
(2)used_memory_rss:The Redis process occupies the memory of the operating system (unit is bytes), which is consistent with the value seen by the top and ps commands; In addition to the memory allocated by the allocator, used_memory_rss also includes the memory required for the process to run itself, memory fragments, etc., but does not include virtual memory.
Therefore, used_memory and used_memory_rss, the former is the amount obtained from the perspective of Redis, and the latter is the amount obtained from the perspective of the operating system. The reason why the two are different is that on the one hand, memory fragmentation and the memory required to run the Redis process make the former may be smaller than the latter. On the other hand, the existence of virtual memory makes the former may be larger than the latter.
Since in actual applications, the amount of data in Redis will be relatively large, the memory occupied by the process running at this time will be much smaller than the amount of Redis data and memory fragments; therefore, the ratio of used_memory_rss and used_memory is It has become a parameter to measure the Redis memory fragmentation rate; this parameter is mem_fragmentation_ratio.
(3)mem_fragmentation_ratio:Memory fragmentation ratio, this value is the ratio of used_memory_rss/used_memory.
mem_fragmentation_ratio is generally greater than 1, and the greater the value, the greater the memory fragmentation ratio. mem_fragmentation_ratio<1, indicating that Redis uses virtual memory. Since the medium of virtual memory is disk, it is much slower than memory. When this situation occurs, it should be checked in time. If the memory is insufficient, it should be dealt with in time, such as adding Redis nodes, adding Redis server memory, optimized applications, etc.
Generally speaking, mem_fragmentation_ratio is in a relatively healthy state around 1.03 (for jemalloc); the mem_fragmentation_ratio value in the screenshot above is very large because the data has not been stored in Redis and the Redis process itself is running The memory makes used_memory_rss much larger than used_memory.
(4)mem_allocator:The memory allocator used by Redis is specified at compile time; it can be libc, jemalloc or tcmalloc, and the default is jemalloc; used in the screenshot The default is jemalloc.
Redis is an in-memory database, and the content stored in the memory is mainly data (key-value pairs); from the previous description, we can know that in addition to data, Redis Other parts also take up memory.
The memory usage of Redis can be mainly divided into the following parts:
As a database, data is the most important part; the memory occupied by this part will Statistics are in used_memory.
Redis uses key-value pairs to store data, and the values (objects) include 5 types, namely strings, hashes, lists, sets, and ordered sets. These 5 types are provided by Redis to the outside world. In fact, within Redis, each type may have 2 or more internal encoding implementations; in addition, when Redis stores objects, it does not directly throw the data into the memory, but Objects will be packaged in various ways: such as redisObject, SDS, etc.; this article will focus on the details of data storage in Redis later.
The Redis main process itself definitely requires memory to run, such as code, constant pool, etc.; this part of memory is about a few megabytes, and in most production environments Compared with the memory occupied by Redis data, it can be ignored. This part of memory is not allocated by jemalloc, so it will not be counted in used_memory.
Supplementary Note: In addition to the main process, the running of sub-processes created by Redis will also occupy memory, such as the sub-processes created when Redis performs AOF and RDB rewriting. Of course, this part of memory does not belong to the Redis process and will not be counted in used_memory and used_memory_rss.
Buffer memory includes client buffer, copy backlog buffer, AOF buffer, etc.; among them, the client buffer stores the input and output buffer of the client connection; the copy backlog The buffer is used for part of the copy function; the AOF buffer is used to save the latest write command during AOF rewriting. Before understanding the corresponding functions, you do not need to know the details of these buffers; this part of memory is allocated by jemalloc, so it will be counted in used_memory.
Memory fragmentation is generated by Redis during the process of allocating and recycling physical memory. For example, if the data is changed frequently and the size of the data is very different, the space released by redis may not be released in the physical memory, but redis cannot effectively use it, resulting in memory fragmentation. Memory fragmentation will not be counted in used_memory.
The generation of memory fragmentation is related to the operation of data, the characteristics of the data, etc.; in addition, it is also related to the memory allocator used: if the memory allocator is reasonably designed, the occurrence of memory fragmentation can be reduced as much as possible produce. jemalloc, which will be discussed later, does a good job of controlling memory fragmentation.
If the memory fragmentation in the Redis server is already large, you can reduce the memory fragmentation by safely restarting: because after restarting, Redis re-reads the data from the backup file and rearranges it in the memory. Re-select the appropriate memory unit for each data to reduce memory fragmentation.
The details of Redis data storage involve memory allocators (such as jemalloc), simple dynamic strings ( SDS), 5 object types and internal encoding, redisObject. Before describing the specific content, let me first explain the relationship between these concepts.
The following figure is the data model involved when executing set hello world.
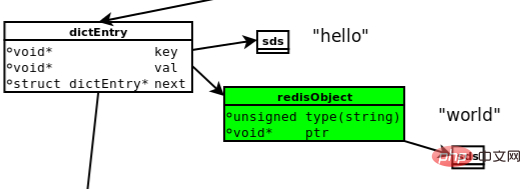
Image source: https://searchdatabase.techtarget.com.cn/7-20218/
(1) dictEntry: Redis is Key-Value Database, so there will be a dictEntry for each key-value pair, which stores pointers to Key and Value; next points to the next dictEntry, which has nothing to do with this Key-Value.
(2) Key: As can be seen in the upper right corner of the figure, Key ("hello") is not stored directly as a string, but is stored in the SDS structure.
(3) redisObject: Value("world") is neither stored directly as a string nor directly stored in SDS like Key, but is stored in redisObject. In fact, no matter which of the five types of Value it is, it is stored through redisObject; the type field in redisObject indicates the type of the Value object, and the ptr field points to the address of the object. However, it can be seen that although the string object is packaged by redisObject, it still needs to be stored through SDS.
In fact, in addition to the type and ptr fields, redisObject also has other fields not shown in the diagram, such as fields used to specify the internal encoding of the object; these will be introduced in detail later.
(4) jemalloc: Whether it is a DictEntry object, redisObject, or SDS object, a memory allocator (such as jemalloc) is required to allocate memory for storage. Taking the DictEntry object as an example, it consists of 3 pointers and occupies 24 bytes on a 64-bit machine. jemalloc will allocate a 32-byte memory unit for it.
The following introduces jemalloc, redisObject, SDS, object types and internal encoding respectively.
Redis will specify a memory allocator when compiling; the memory allocator can be libc, jemalloc or tcmalloc, and the default is jemalloc.
jemalloc, as the default memory allocator of Redis, does a relatively good job of reducing memory fragmentation. In 64-bit systems, jemalloc divides the memory space into three ranges: small, large, and huge; each range is divided into many small memory block units; when Redis stores data, it will select the memory block with the most appropriate size. storage.
The memory units divided by jemalloc are as shown below:
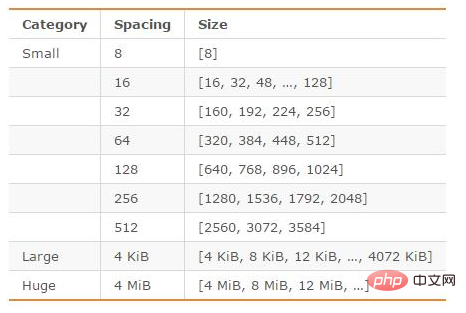
图片来源:http://blog.csdn.net/zhengpeitao/article/details/76573053
例如,如果需要存储大小为130字节的对象,jemalloc会将其放入160字节的内存单元中。
前面说到,Redis对象有5种类型;无论是哪种类型,Redis都不会直接存储,而是通过redisObject对象进行存储。
redisObject对象非常重要,Redis对象的类型、内部编码、内存回收、共享对象等功能,都需要redisObject支持,下面将通过redisObject的结构来说明它是如何起作用的。
redisObject的定义如下(不同版本的Redis可能稍稍有所不同):
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr; } robj;
redisObject的每个字段的含义和作用如下:
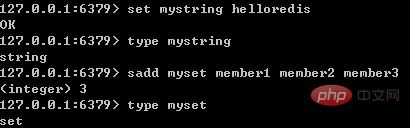
type字段表示对象的类型,占4个比特;目前包括REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
当我们执行type命令时,便是通过读取RedisObject的type字段获得对象的类型;如下图所示:
encoding表示对象的内部编码,占4个比特。
对于Redis支持的每种类型,都有至少两种内部编码,例如对于字符串,有int、embstr、raw三种编码。通过encoding属性,Redis可以根据不同的使用场景来为对象设置不同的编码,大大提高了Redis的灵活性和效率。以列表对象为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少,Redis倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。
通过object encoding命令,可以查看对象采用的编码方式,如下图所示:
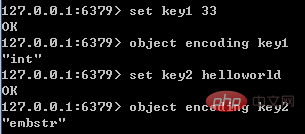
5种对象类型对应的编码方式以及使用条件,将在后面介绍。
lru记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如4.0版本占24比特,2.6版本占22比特)。
通过对比lru时间与当前时间,可以计算某个对象的空转时间;object idletime命令可以显示该空转时间(单位是秒)。object idletime命令的一个特殊之处在于它不改变对象的lru值。
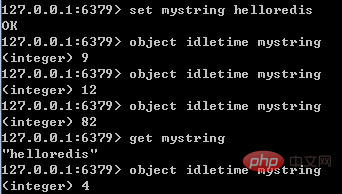
lru值除了通过object idletime命令打印之外,还与Redis的内存回收有关系:如果Redis打开了maxmemory选项,且内存回收算法选择的是volatile-lru或allkeys—lru,那么当Redis内存占用超过maxmemory指定的值时,Redis会优先选择空转时间最长的对象进行释放。
refcount与共享对象
refcount记录的是该对象被引用的次数,类型为整型。refcount的作用,主要在于对象的引用计数和内存回收。当创建新对象时,refcount初始化为1;当有新程序使用该对象时,refcount加1;当对象不再被一个新程序使用时,refcount减1;当refcount变为0时,对象占用的内存会被释放。
Redis中被多次使用的对象(refcount>1),称为共享对象。Redis为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。这个被重复使用的对象,就是共享对象。目前共享对象仅支持整数值的字符串对象。
共享对象的具体实现
Redis的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。对于整数值,判断操作复杂度为O(1);对于普通字符串,判断复杂度为O(n);而对于哈希、列表、集合和有序集合,判断的复杂度为O(n^2)。
虽然共享对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象(如哈希、列表等的元素可以使用)。
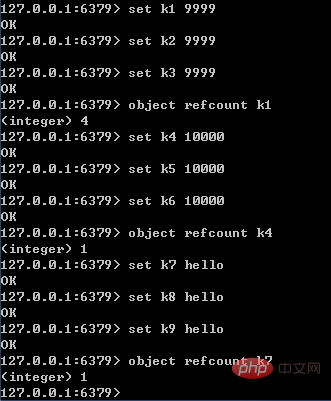
就目前的实现来说,Redis服务器在初始化时,会创建10000个字符串对象,值分别是0~9999的整数值;当Redis需要使用值为0~9999的字符串对象时,可以直接使用这些共享对象。10000这个数字可以通过调整参数REDIS_SHARED_INTEGERS(4.0中是OBJ_SHARED_INTEGERS)的值进行改变。
共享对象的引用次数可以通过object refcount命令查看,如下图所示。命令执行的结果页佐证了只有0~9999之间的整数会作为共享对象。
ptr指针指向具体的数据,如前面的例子中,set hello world,ptr指向包含字符串world的SDS。
综上所述,redisObject的结构与对象类型、编码、内存回收、共享对象都有关系;一个redisObject对象的大小为16字节:
4bit+4bit+24bit+4Byte+8Byte=16Byte。
Redis没有直接使用C字符串(即以空字符’\0’结尾的字符数组)作为默认的字符串表示,而是使用了SDS。SDS是简单动态字符串(Simple Dynamic String)的缩写。
sds的结构如下:
struct sdshdr { int len; int free; char buf[]; };
其中,buf表示字节数组,用来存储字符串;len表示buf已使用的长度,free表示buf未使用的长度。下面是两个例子。
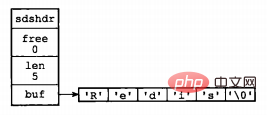
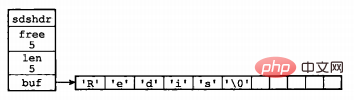
图片来源:《Redis设计与实现》
通过SDS的结构可以看出,buf数组的长度=free+len+1(其中1表示字符串结尾的空字符);所以,一个SDS结构占据的空间为:free所占长度+len所占长度+ buf数组的长度=4+4+free+len+1=free+len+9。
SDS在C字符串的基础上加入了free和len字段,带来了很多好处:
此外,由于SDS中的buf仍然使用了C字符串(即以’\0’结尾),因此SDS可以使用C字符串库中的部分函数;但是需要注意的是,只有当SDS用来存储文本数据时才可以这样使用,在存储二进制数据时则不行(’\0’不一定是结尾)。
Redis在存储对象时,一律使用SDS代替C字符串。例如set hello world命令,hello和world都是以SDS的形式存储的。而sadd myset member1 member2 member3命令,不论是键(”myset”),还是集合中的元素(”member1”、 ”member2”和”member3”),都是以SDS的形式存储。除了存储对象,SDS还用于存储各种缓冲区。
只有在字符串不会改变的情况下,如打印日志时,才会使用C字符串。
前面已经说过,Redis支持5种对象类型,而每种结构都有至少两种编码;这样做的好处在于:一方面接口与实现分离,当需要增加或改变内部编码时,用户使用不受影响,另一方面可以根据不同的应用场景切换内部编码,提高效率。
Redis各种对象类型支持的内部编码如下图所示(图中版本是Redis3.0,Redis后面版本中又增加了内部编码,略过不提;本章所介绍的内部编码都是基于3.0的):
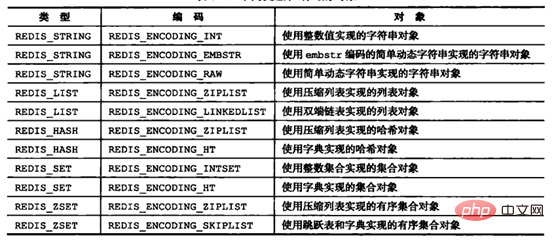
Picture source: "Redis Design and Implementation"
Regarding the conversion of Redis internal encoding, it is in line with the following rules:Encoding conversion is inRedisIt is completed when writing data, and the conversion process is irreversible. It can only be converted from small memory encoding to large memory encoding.
String is the most basic type, because all keys are string type, and string Several other complex types of elements are also strings.
The string length cannot exceed 512MB.
There are three types of internal encoding for string types. Their application scenarios are as follows:
The example is as shown below:
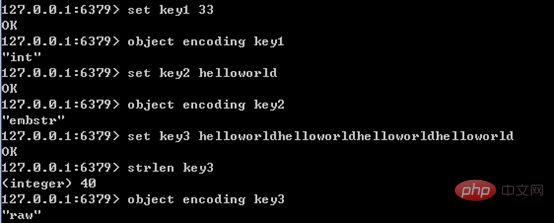
embstr and raw The length of the distinction is 39; this is because the length of redisObject is 16 bytes and the length of sds is 9 string length; therefore when the string length is 39, the length of embstr is exactly 16 9 39=64, which jemalloc can just allocate 64-byte memory unit.
When the int data is no longer an integer, or the size exceeds the range of long, it is automatically converted to raw.
As for embstr, since its implementation is read-only, when the embstr object is modified, it will be converted to raw first and then modified. Therefore, as long as the embstr object is modified, the modified object must be raw, regardless of whether it reaches 39 bytes. An example is shown in the figure below:
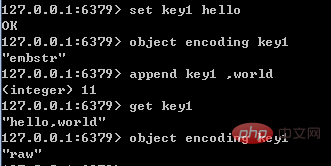
List (list) is used to store multiple An ordered string, each string is called an element; a list can store 2^32-1 elements. The list in Redis supports insertion and popping at both ends, and can obtain elements at a specified position (or range), and can function as an array, queue, stack, etc.
The internal encoding of the list can be a compressed list (ziplist) or a double-ended linked list (linkedlist).
Double-ended linked list: It consists of a list structure and multiple listNode structures; the typical structure is as shown below:
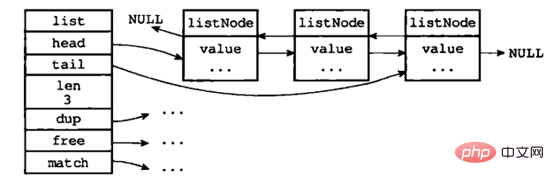
Picture source: "Redis Design and Implementation》
As can be seen from the figure, the double-ended linked list saves both the head pointer and the tail pointer, and each node has pointers pointing forward and pointing back; the length of the list is saved in the linked list ; dup, free, and match set type-specific functions for node values, so linked lists can be used to store values of various different types. Each node in the linked list points to a redisObject whose type is a string.
Compressed list: Compressed list was developed by Redis to save memory. It is composed of a series of specially encodedcontinuous memory blocks(rather than like a double-ended linked list Each node is a sequential data structure composed of pointers); the specific structure is relatively complicated and will be omitted. Compared with double-ended linked lists, compressed lists can save memory space, but the complexity is higher when modifying or adding or deleting operations; therefore, when the number of nodes is small, compressed lists can be used; but when the number of nodes is large, double-ended linked lists are still used Good deal.
Compressed lists are not only used to implement lists, but also to implement hashes and ordered lists; they are very widely used.
Compressed list will be used only when the following two conditions are met at the same time: the number of elements in the list is less than 512; all string objects in the list are less than 64 characters Festival. If one condition is not met, a double-ended list is used; and the encoding can only be converted from a compressed list to a double-ended linked list, and the reverse direction is not possible.
The following figure shows the characteristics of list encoding conversion:
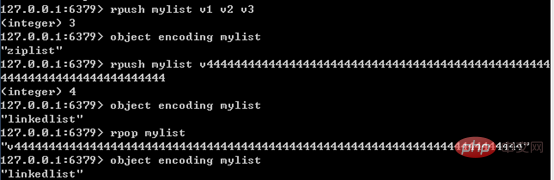
其中,单个字符串不能超过64字节,是为了便于统一分配每个节点的长度;这里的64字节是指字符串的长度,不包括SDS结构,因为压缩列表使用连续、定长内存块存储字符串,不需要SDS结构指明长度。后面提到压缩列表,也会强调长度不超过64字节,原理与这里类似。
哈希(作为一种数据结构),不仅是redis对外提供的5种对象类型的一种(与字符串、列表、集合、有序结合并列),也是Redis作为Key-Value数据库所使用的数据结构。为了说明的方便,在本文后面当使用“内层的哈希”时,代表的是redis对外提供的5种对象类型的一种;使用“外层的哈希”代指Redis作为Key-Value数据库所使用的数据结构。
内层的哈希使用的内部编码可以是压缩列表(ziplist)和哈希表(hashtable)两种;Redis的外层的哈希则只使用了hashtable。
压缩列表前面已介绍。与哈希表相比,压缩列表用于元素个数少、元素长度小的场景;其优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于哈希中元素数量较少,因此操作的时间并没有明显劣势。
hashtable:一个hashtable由1个dict结构、2个dictht结构、1个dictEntry指针数组(称为bucket)和多个dictEntry结构组成。
正常情况下(即hashtable没有进行rehash时)各部分关系如下图所示:
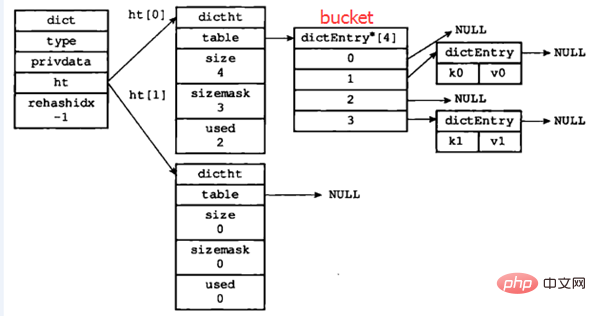
图片改编自:《Redis设计与实现》
下面从底层向上依次介绍各个部分:
dictEntry
dictEntry结构用于保存键值对,结构定义如下:
typedef struct dictEntry{ void *key; union{ void *val; uint64_tu64; int64_ts64; }v; struct dictEntry *next; }dictEntry;
其中,各个属性的功能如下:
在64位系统中,一个dictEntry对象占24字节(key/val/next各占8字节)。
bucket
bucket是一个数组,数组的每个元素都是指向dictEntry结构的指针。redis中bucket数组的大小计算规则如下:大于dictEntry的、最小的2^n;例如,如果有1000个dictEntry,那么bucket大小为1024;如果有1500个dictEntry,则bucket大小为2048。
dictht
dictht结构如下:
typedef struct dictht{ dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; }dictht;
其中,各个属性的功能说明如下:
dict
一般来说,通过使用dictht和dictEntry结构,便可以实现普通哈希表的功能;但是Redis的实现中,在dictht结构的上层,还有一个dict结构。下面说明dict结构的定义及作用。
dict结构如下:
typedef struct dict{ dictType *type; void *privdata; dictht ht[2]; int trehashidx; } dict;
其中,type属性和privdata属性是为了适应不同类型的键值对,用于创建多态字典。
ht属性和trehashidx属性则用于rehash,即当哈希表需要扩展或收缩时使用。ht是一个包含两个项的数组,每项都指向一个dictht结构,这也是Redis的哈希会有1个dict、2个dictht结构的原因。通常情况下,所有的数据都是存在放dict的ht[0]中,ht[1]只在rehash的时候使用。dict进行rehash操作的时候,将ht[0]中的所有数据rehash到ht[1]中。然后将ht[1]赋值给ht[0],并清空ht[1]。
因此,Redis中的哈希之所以在dictht和dictEntry结构之外还有一个dict结构,一方面是为了适应不同类型的键值对,另一方面是为了rehash。
如前所述,Redis中内层的哈希既可能使用哈希表,也可能使用压缩列表。
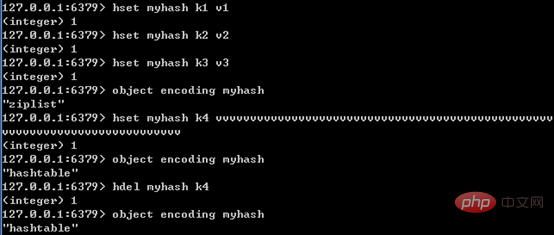
只有同时满足下面两个条件时,才会使用压缩列表:哈希中元素数量小于512个;哈希中所有键值对的键和值字符串长度都小于64字节。如果有一个条件不满足,则使用哈希表;且编码只可能由压缩列表转化为哈希表,反方向则不可能。
下图展示了Redis内层的哈希编码转换的特点:
集合(set)与列表类似,都是用来保存多个字符串,但集合与列表有两点不同:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
一个集合中最多可以存储2^32-1个元素;除了支持常规的增删改查,Redis还支持多个集合取交集、并集、差集。
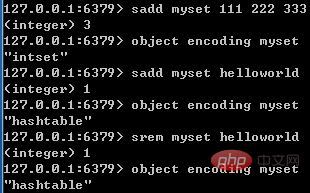
集合的内部编码可以是整数集合(intset)或哈希表(hashtable)。
哈希表前面已经讲过,这里略过不提;需要注意的是,集合在使用哈希表时,值全部被置为null。
整数集合的结构定义如下:
typedef struct intset{ uint32_t encoding; uint32_t length; int8_t contents[]; } intset;
其中,encoding代表contents中存储内容的类型,虽然contents(存储集合中的元素)是int8_t类型,但实际上其存储的值是int16_t、int32_t或int64_t,具体的类型便是由encoding决定的;length表示元素个数。
整数集合适用于集合所有元素都是整数且集合元素数量较小的时候,与哈希表相比,整数集合的优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于集合数量较少,因此操作的时间并没有明显劣势。
只有同时满足下面两个条件时,集合才会使用整数集合:集合中元素数量小于512个;集合中所有元素都是整数值。如果有一个条件不满足,则使用哈希表;且编码只可能由整数集合转化为哈希表,反方向则不可能。
下图展示了集合编码转换的特点:
有序集合与集合一样,元素都不能重复;但与集合不同的是,有序集合中的元素是有顺序的。与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数(score)作为排序依据。
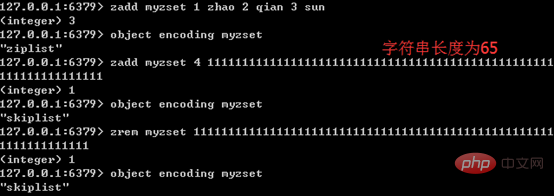
有序集合的内部编码可以是压缩列表(ziplist)或跳跃表(skiplist)。ziplist在列表和哈希中都有使用,前面已经讲过,这里略过不提。
跳跃表是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。除了跳跃表,实现有序数据结构的另一种典型实现是平衡树;大多数情况下,跳跃表的效率可以和平衡树媲美,且跳跃表实现比平衡树简单很多,因此redis中选用跳跃表代替平衡树。跳跃表支持平均O(logN)、最坏O(N)的复杂点进行节点查找,并支持顺序操作。Redis的跳跃表实现由zskiplist和zskiplistNode两个结构组成:前者用于保存跳跃表信息(如头结点、尾节点、长度等),后者用于表示跳跃表节点。具体结构相对比较复杂,略。
只有同时满足下面两个条件时,才会使用压缩列表:有序集合中元素数量小于128个;有序集合中所有成员长度都不足64字节。如果有一个条件不满足,则使用跳跃表;且编码只可能由压缩列表转化为跳跃表,反方向则不可能。
下图展示了有序集合编码转换的特点:
了解Redis的内存模型之后,下面通过几个例子说明其应用。
要估算redis中的数据占据的内存大小,需要对redis的内存模型有比较全面的了解,包括前面介绍的hashtable、sds、redisobject、各种对象类型的编码方式等。
下面以最简单的字符串类型来进行说明。
假设有90000个键值对,每个key的长度是7个字节,每个value的长度也是7个字节(且key和value都不是整数);下面来估算这90000个键值对所占用的空间。在估算占据空间之前,首先可以判定字符串类型使用的编码方式:embstr。
90000个键值对占据的内存空间主要可以分为两部分:一部分是90000个dictEntry占据的空间;一部分是键值对所需要的bucket空间。
每个dictEntry占据的空间包括:
1)一个dictEntry,24字节,jemalloc会分配32字节的内存块
2)一个key,7字节,所以SDS(key)需要7+9=16个字节,jemalloc会分配16字节的内存块
3)一个redisObject,16字节,jemalloc会分配16字节的内存块
4)一个value,7字节,所以SDS(value)需要7+9=16个字节,jemalloc会分配16字节的内存块
5)综上,一个dictEntry需要32+16+16+16=80个字节。
bucket空间:bucket数组的大小为大于90000的最小的2^n,是131072;每个bucket元素为8字节(因为64位系统中指针大小为8字节)。
因此,可以估算出这90000个键值对占据的内存大小为:90000*80 + 131072*8 = 8248576。
下面写个程序在redis中验证一下:
public class RedisTest { public static Jedis jedis = new Jedis("localhost", 6379); public static void main(String[] args) throws Exception{ Long m1 = Long.valueOf(getMemory()); insertData(); Long m2 = Long.valueOf(getMemory()); System.out.println(m2 - m1); } public static void insertData(){ for(int i = 10000; i < 100000; i++){ jedis.set("aa" + i, "aa" + i); //key和value长度都是7字节,且不是整数 } } public static String getMemory(){ String memoryAllLine = jedis.info("memory"); String usedMemoryLine = memoryAllLine.split("\r\n")[1]; String memory = usedMemoryLine.substring(usedMemoryLine.indexOf(':') + 1); return memory; } }
运行结果:8247552
理论值与结果值误差在万分之1.2,对于计算需要多少内存来说,这个精度已经足够了。之所以会存在误差,是因为在我们插入90000条数据之前redis已分配了一定的bucket空间,而这些bucket空间尚未使用。
作为对比将key和value的长度由7字节增加到8字节,则对应的SDS变为17个字节,jemalloc会分配32个字节,因此每个dictEntry占用的字节数也由80字节变为112字节。此时估算这90000个键值对占据内存大小为:90000*112 + 131072*8 = 11128576。
在redis中验证代码如下(只修改插入数据的代码):
public static void insertData(){ for(int i = 10000; i < 100000; i++){ jedis.set("aaa" + i, "aaa" + i); //key和value长度都是8字节,且不是整数 } }
运行结果:11128576;估算准确。
对于字符串类型之外的其他类型,对内存占用的估算方法是类似的,需要结合具体类型的编码方式来确定。
了解redis的内存模型,对优化redis内存占用有很大帮助。下面介绍几种优化场景。
(1)利用jemalloc特性进行优化
上一小节所讲述的90000个键值便是一个例子。由于jemalloc分配内存时数值是不连续的,因此key/value字符串变化一个字节,可能会引起占用内存很大的变动;在设计时可以利用这一点。
例如,如果key的长度如果是8个字节,则SDS为17字节,jemalloc分配32字节;此时将key长度缩减为7个字节,则SDS为16字节,jemalloc分配16字节;则每个key所占用的空间都可以缩小一半。
(2)使用整型/长整型
如果是整型/长整型,Redis会使用int类型(8字节)存储来代替字符串,可以节省更多空间。因此在可以使用长整型/整型代替字符串的场景下,尽量使用长整型/整型。
(3)共享对象
利用共享对象,可以减少对象的创建(同时减少了redisObject的创建),节省内存空间。目前redis中的共享对象只包括10000个整数(0-9999);可以通过调整REDIS_SHARED_INTEGERS参数提高共享对象的个数;例如将REDIS_SHARED_INTEGERS调整到20000,则0-19999之间的对象都可以共享。
考虑这样一种场景:论坛网站在redis中存储了每个帖子的浏览数,而这些浏览数绝大多数分布在0-20000之间,这时候通过适当增大REDIS_SHARED_INTEGERS参数,便可以利用共享对象节省内存空间。
(4)避免过度设计
然而需要注意的是,不论是哪种优化场景,都要考虑内存空间与设计复杂度的权衡;而设计复杂度会影响到代码的复杂度、可维护性。
如果数据量较小,那么为了节省内存而使得代码的开发、维护变得更加困难并不划算;还是以前面讲到的90000个键值对为例,实际上节省的内存空间只有几MB。但是如果数据量有几千万甚至上亿,考虑内存的优化就比较必要了。
内存碎片率是一个重要的参数,对redis 内存的优化有重要意义。
如果内存碎片率过高(jemalloc在1.03左右比较正常),说明内存碎片多,内存浪费严重;这时便可以考虑重启redis服务,在内存中对数据进行重排,减少内存碎片。
如果内存碎片率小于1,说明redis内存不足,部分数据使用了虚拟内存(即swap);由于虚拟内存的存取速度比物理内存差很多(2-3个数量级),此时redis的访问速度可能会变得很慢。因此必须设法增大物理内存(可以增加服务器节点数量,或提高单机内存),或减少redis中的数据。
要减少redis中的数据,除了选用合适的数据类型、利用共享对象等,还有一点是要设置合理的数据回收策略(maxmemory-policy),当内存达到一定量后,根据不同的优先级对内存进行回收。
The above is the detailed content of Redis memory model (detailed explanation). For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software What are the in-memory databases?
What are the in-memory databases? Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis? How to use redis as a cache server
How to use redis as a cache server How redis solves data consistency
How redis solves data consistency How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency? What data does redis cache generally store?
What data does redis cache generally store? What are the 8 data types of redis
What are the 8 data types of redis





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



