

This article will take you to learn more about Redis, analyze persistence in detail, introduce its working principle, persistence process, etc. I hope it will be helpful to you!
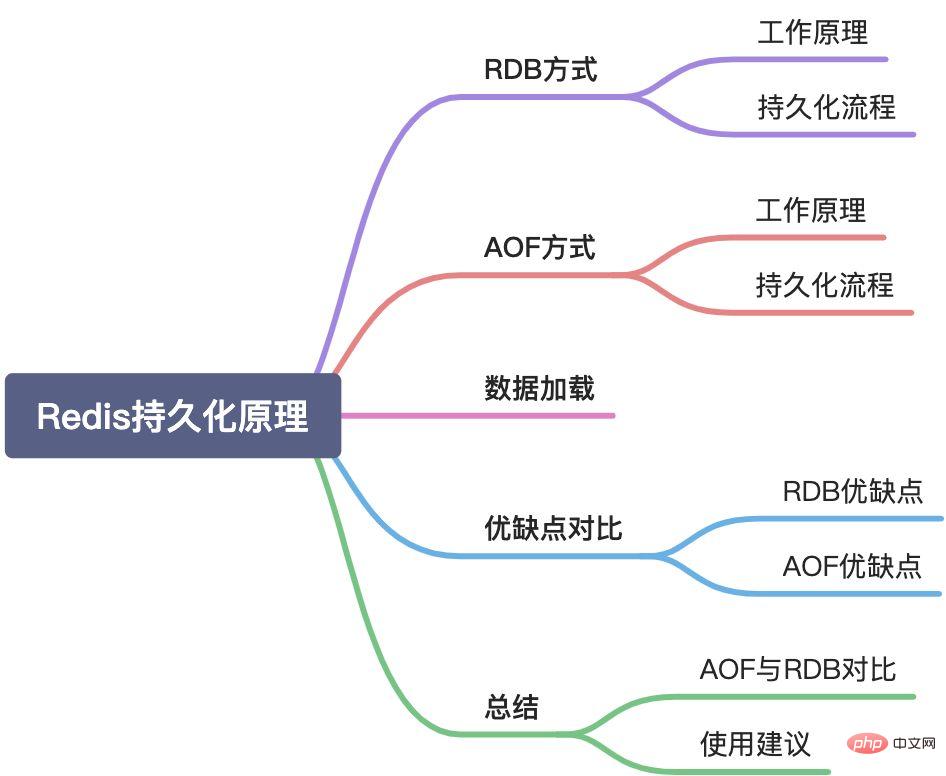
This article will introduce the Redis persistence mechanism from the following aspects:
 ## Written in front
## Written in front
This article is detailed overall Introducing the two persistence methods of Redis, including working principles, persistence process and practical strategies, as well as some theoretical knowledge behind them. The previous article only introduced RDB persistence, but Redis persistence is a whole and cannot be introduced separately, so it has been reorganized. [Related recommendations: Redis Video Tutorial]
Redis is an in-memory database. All data will be stored in memory. This is directly different from traditional relational databases such as MySQL, Oracle, and SqlServer. Compared with saving data to the hard disk, Redis's reading and writing efficiency is very high. However, saving in memory also has a big flaw. Once the power is cut off or the computer is down, all the contents in the memory database will be lost. In order to make up for this shortcoming, Redis provides the function of persisting memory data to hard disk files and restoring data through backup files, which is the Redis persistence mechanism.
Redis supports two methods of persistence: RDB snapshot and AOF.
RDB snapshot In official words: RDB persistence solution is a point-to-time snapshot generated for your data set at a specified time interval. . It saves the memory snapshot of all data objects in the Redis database at a certain time in a compressed binary file, which can be used for Redis data backup, transfer and recovery. So far, it is still the official default support solution.
Since RDB is a point-in-time snapshot of the data set in Redis, let’s first briefly understand how the data objects in Redis are stored and organized in memory.
By default, there are 16 databases in Redis, numbered from 0-15. Each Redis database is represented by a redisDb object, redisDb uses hashtable storage K-V object. To facilitate understanding, I took one of the dbs as an example to draw a schematic diagram of the storage structure of Redis's internal data.

The point-in-time snapshot is the status of each data object in each DB in Redis at a certain moment. First assume that all If the data objects no longer change, we can read these data objects one by one and write them to files according to the data structure relationship in the above figure to achieve Redis persistence. Then, when Redis restarts, the contents of this file are read according to the rules, and then written to the Redis memory to restore to the state of persistence.
Of course, this premise is true when our above assumption is true, otherwise we would have no way to start in the face of a data set that changes all the time. We know that client command processing in Redis is a single-threaded model. If persistence is processed as a command, the data set will definitely be in a static state. In addition, the child process created by the fork() function provided by the operating system can obtain the same memory data as the parent process, which is equivalent to obtaining a copy of the memory data; after the fork is completed, what should the parent process do, and the work of persisting the state is handed over. Just give it to the child process.
Obviously, the first situation is not advisable. Persistent backup will cause the Redis service to be unavailable for a short period of time, which is intolerable for high HA systems. Therefore, the second method is the main practical method of RDB persistence. Since the data of the parent process keeps changing after forking the child process, and the child process is not synchronized with the parent process, RDB persistence cannot guarantee real-time performance; a power outage or downtime after the RDB persistence is completed will result in partial data loss; backup The frequency determines the amount of lost data. Increasing the backup frequency means that the fork process consumes more CPU resources and will also lead to larger disk I/O.
There are two methods to complete RDB persistence in Redis: rdbSave and rdbSaveBackground (in the source code file rdb.c). Let’s briefly talk about the difference between the two:
The triggering of RDB persistence must be inseparable from the above two methods, and the triggering methods are divided into manual and automatic. Manual triggering is easy to understand. It means that we manually initiate persistence backup instructions to the Redis server through the Redis client, and then the Redis server starts to execute the persistence process. The instructions here include save and bgsave. Automatic triggering is a persistence process that Redis automatically triggers when preset conditions are met based on its own operating requirements. The automatically triggered scenarios are as follows (extracted from this article):
save m nThe configuration rules are automatically triggered;debug reloadWhen the command reloads redis;Combined with the source code and reference articles, I have organized the RDB persistence process to help you have an overall understanding, and then explain it in some details. 
As you can see from the above figure:
rdbSave method in the Redis command processing thread in a blocking manner. The automatic triggering process is a complete link, covering rdbSaveBackground, rdbSave, etc. Next, I will use serverCron as an example to analyze the entire process.
serverCron is a periodic function in Redis, executed every 100 milliseconds. One of its jobs is to determine the current situation based on the save rules in the configuration file. An automatic persistence process is required, and if the conditions are met, an attempt will be made to start persistence. Learn about the implementation of this part.
There are several fields related to RDB persistence in redisServer. I extracted them from the code and looked at them in Chinese and English:
struct redisServer {
/* 省略其他字段 */
/* RDB persistence */
long long dirty; /* Changes to DB from the last save
* 上次持久化后修改key的次数 */
struct saveparam *saveparams; /* Save points array for RDB,
* 对应配置文件多个save参数 */
int saveparamslen; /* Number of saving points,
* save参数的数量 */
time_t lastsave; /* Unix time of last successful save
* 上次持久化时间*/
/* 省略其他字段 */
}
/* 对应redis.conf中的save参数 */
struct saveparam {
time_t seconds; /* 统计时间范围 */
int changes; /* 数据修改次数 */
}; saveparams corresponds to the save rule under redis.conf. The save parameter is the triggering strategy for Redis to trigger automatic backup, seconds is the statistical time (unit: seconds), changes is the number of writes that occurred within the statistical time. save m n means: if there are n writes within m seconds, a snapshot will be triggered, that is, a backup. Multiple groups of save parameters can be configured to meet backup requirements under different conditions. If you need to turn off the automatic backup policy of RDB, you can use save "". The following are descriptions of several configurations:
# 表示900秒(15分钟)内至少有1个key的值发生变化,则执行 save 900 1 # 表示300秒(5分钟)内至少有1个key的值发生变化,则执行 save 300 10 # 表示60秒(1分钟)内至少有10000个key的值发生变化,则执行 save 60 10000 # 该配置将会关闭RDB方式的持久化 save ""
serverCronThe detection code for the RDB save rule is as follows:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* 省略其他逻辑 */
/* 如果用户请求进行AOF文件重写时,Redis正在执行RDB持久化,Redis会安排在RDB持久化完成后执行AOF文件重写,
* 如果aof_rewrite_scheduled为true,说明需要执行用户的请求 */
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 后台无 saving/rewrite 子进程才会进行,逐个检查每个save规则*/
for (j = 0; j = sp->changes
&& server.unixtime-server.lastsave > sp->seconds
&&(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
/* 执行bgsave过程 */
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
/* 省略:Trigger an AOF rewrite if needed. */
}
/* 省略其他逻辑 */
}If there is no background RDB persistence or AOF replication When writing a process, serverCron will judge whether persistence operations need to be performed based on the above configuration and status. The basis for judgment is whether lastsave and dirty satisfy one of the conditions in the saveparams array. If a condition is matched, the rdbSaveBackground method is called to execute the asynchronous persistence process.
rdbSaveBackground is an auxiliary method for RDB persistence. Its main job is to fork the child process, and then there are two different execution logics depending on the caller (parent process or child process). .
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
if (hasActiveChildProcess()) return C_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
// fork子进程
if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) {
int retval;
/* Child 子进程:修改进程标题 */
redisSetProcTitle("redis-rdb-bgsave");
redisSetCpuAffinity(server.bgsave_cpulist);
// 执行rdb持久化
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
sendChildCOWInfo(CHILD_TYPE_RDB, 1, "RDB");
}
// 持久化完成后,退出子进程
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent 父进程:记录fork子进程的时间等信息*/
if (childpid == -1) {
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %ld",(long) childpid);
// 记录子进程开始的时间、类型等。
server.rdb_save_time_start = time(NULL);
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
return C_OK;
}
return C_OK; /* unreached */
}rdbSave is a method that truly performs persistence. It involves a large number of I/O and calculation operations during execution, which is time-consuming and takes up a lot of CPU. It is persisted in the single-threaded model of Redis. The process will continue to occupy thread resources, causing Redis to be unable to provide other services. In order to solve this problem, Redis forks out the child process in rdbSaveBackground, and the child process completes the persistence work, avoiding occupying too many resources of the parent process.
It should be noted that if the memory usage of the parent process is too large, the fork process will be more time-consuming. During this process, the parent process cannot provide external services; in addition, the computer memory usage needs to be comprehensively considered before forking the child process. It will occupy double the memory resources, so you need to ensure that the memory is sufficient. Check the latest_fork_usec option through the info stats command to get the time taken for the latest fork operation.
Redis的rdbSave函数是真正进行RDB持久化的函数,流程、细节贼多,整体流程可以总结为:创建并打开临时文件、Redis内存数据写入临时文件、临时文件写入磁盘、临时文件重命名为正式RDB文件、更新持久化状态信息(dirty、lastsave)。其中“Redis内存数据写入临时文件”最为核心和复杂,写入过程直接体现了RDB文件的文件格式,本着一图胜千言的理念,我按照源码流程绘制了下图。
补充说明一下,上图右下角“遍历当前数据库的键值对并写入”这个环节会根据不同类型的Redis数据类型及底层数据结构采用不同的格式写入到RDB文件中,不再展开了。我觉得大家对整个过程有个直观的理解就好,这对于我们理解Redis内部的运作机制大有裨益。
上一节我们知道RDB是一种时间点(point-to-time)快照,适合数据备份及灾难恢复,由于工作原理的“先天性缺陷”无法保证实时性持久化,这对于缓存丢失零容忍的系统来说是个硬伤,于是就有了AOF。
AOF是Append Only File的缩写,它是Redis的完全持久化策略,从1.1版本开始支持;这里的file存储的是引起Redis数据修改的命令集合(比如:set/hset/del等),这些集合按照Redis Server的处理顺序追加到文件中。当重启Redis时,Redis就可以从头读取AOF中的指令并重放,进而恢复关闭前的数据状态。
AOF持久化默认是关闭的,修改redis.conf以下信息并重启,即可开启AOF持久化功能。
# no-关闭,yes-开启,默认no appendonly yes appendfilename appendonly.aof
AOF本质是为了持久化,持久化对象是Redis内每一个key的状态,持久化的目的是为了在Reids发生故障重启后能够恢复至重启前或故障前的状态。相比于RDB,AOF采取的策略是按照执行顺序持久化每一条能够引起Redis中对象状态变更的命令,命令是有序的、有选择的。把aof文件转移至任何一台Redis Server,从头到尾按序重放这些命令即可恢复如初。举个例子:
首先执行指令set number 0,然后随机调用incr number、get number 各5次,最后再执行一次get number ,我们得到的结果肯定是5。
因为在这个过程中,能够引起number状态变更的只有set/incr类型的指令,并且它们执行的先后顺序是已知的,无论执行多少次get都不会影响number的状态。所以,保留所有set/incr命令并持久化至aof文件即可。按照aof的设计原理,aof文件中的内容应该是这样的(这里是假设,实际为RESP协议):
set number 0 incr number incr number incr number incr number incr number
最本质的原理用“命令重放”四个字就可以概括。但是,考虑实际生产环境的复杂性及操作系统等方面的限制,Redis所要考虑的工作要比这个例子复杂的多:
set命令,存在很大的压缩空间。从流程上来看,AOF的工作原理可以概括为几个步骤:命令追加(append)、文件写入与同步(fsync)、文件重写(rewrite)、重启加载(load),接下来依次了解每个步骤的细节及背后的设计哲学。
When the AOF persistence function is turned on, after Redis executes a write command, it will use the protocol format (that is, RESP, the communication protocol for the interaction between the Redis client and the server) Append the executed write command to the end of the AOF buffer maintained by the Redis server. There is only a single-threaded append operation for AOF files, and there are no complex operations such as seek. There is no risk of file damage even if there is a power outage or downtime. In addition, there are many benefits to using the text protocol:
The AOF buffer type is a data structure designed independently by Redis sds. Redis will use different methods according to the type of command (catAppendOnlyGenericCommand, catAppendOnlyExpireAtCommand, etc.) processes the command content and finally writes it to the buffer.
It should be noted that if AOF rewriting is in progress when commands are appended, these commands will also be appended to the rewrite buffer (aof_rewrite_buffer).
The writing and synchronization of AOF files cannot be separated from the support of the operating system. Before starting to introduce, we need to add some knowledge about Linux I/O buffers. The I/O performance of the hard disk is poor, and the file reading and writing speed is far inferior to the processing speed of the CPU. If you wait for data to be written to the hard disk every time you write a file, it will lower the overall performance of the operating system. In order to solve this problem, the operating system provides a delayed write mechanism to improve the I/O performance of the hard disk. 
Traditional UNIX implementations have a buffer cache or page cache in the kernel, and most disk I/O occurs through buffering. When writing data to a file, the kernel usually copies the data to one of the buffers first. If the buffer is not full yet, it does not queue it into the output queue, but waits for it to fill up or when the kernel needs to When the buffer is reused to store other disk block data, the buffer is queued into the output queue, and then the actual I/O operation is performed only when it reaches the head of the queue. This output method is called delayed writing.
Delayed writing reduces the number of disk reads and writes, but it also reduces the update speed of file content, so that the data to be written to the file is not written to the disk for a period of time. When a system failure occurs, this delay can cause file updates to be lost. In order to ensure the consistency of the actual file system on the disk and the content in the buffer cache, the UNIX system provides three functions: sync, fsync and fdatasync to provide support for forced writing to the hard disk.
Redis will call the function flushAppendOnlyFile before each event rotation ends (beforeSleep), flushAppendOnlyFile will flush the AOF buffer (aof_buf ) is written to the kernel buffer, and the strategy used to write the data in the kernel buffer to disk is determined based on the appendfsync configuration, that is, calling fsync(). This configuration has three optional options always, no, everysec, the details are as follows:
fsync() is the strategy with the highest security and the worst performance. fsync() will not be called. Best performance, worst security. fsync() only when synchronization conditions are met. This is the officially recommended synchronization strategy and is also the default configuration. It takes into account both performance and data security. In theory, only 1 second of data will be lost in the event of a sudden system shutdown. Note: The strategy introduced above is affected by the configuration item no-appendfsync-on-rewrite. Its function is to inform Redis: whether during AOF file rewriting Disable calling fsync(), the default is no.
If appendfsync is set to always or everysec, BGSAVE or is ongoing in the background BGREWRITEAOF consumes too much disk I/O. Under certain Linux system configurations, Redis's call to fsync() may block for a long time. However, this problem has not been fixed yet, because the synchronous write operation will be blocked even if fsync() is executed in a different thread.
To mitigate this problem, this option can be used to prevent fsync() from being called in the main process while doing BGSAVE or BGREWRITEAOF.
yes意味着,如果子进程正在进行BGSAVE或BGREWRITEAOF,AOF的持久化能力就与appendfsync设置为no有着相同的效果。最糟糕的情况下,这可能会导致30秒的缓存数据丢失。yes,否则保持为no。如前面提到的,Redis长时间运行,命令不断写入AOF,文件会越来越大,不加控制可能影响宿主机的安全。
为了解决AOF文件体积问题,Redis引入了AOF文件重写功能,它会根据Redis内数据对象的最新状态生成新的AOF文件,新旧文件对应的数据状态一致,但是新文件会具有较小的体积。重写既减少了AOF文件对磁盘空间的占用,又可以提高Redis重启时数据恢复的速度。还是下面这个例子,旧文件中的6条命令等同于新文件中的1条命令,压缩效果显而易见。
我们说,AOF文件太大时会触发AOF文件重写,那到底是多大呢?有哪些情况会触发重写操作呢?
**
与RDB方式一样,AOF文件重写既可以手动触发,也会自动触发。手动触发直接调用bgrewriteaof命令,如果当时无子进程执行会立刻执行,否则安排在子进程结束后执行。自动触发由Redis的周期性方法serverCron检查在满足一定条件时触发。先了解两个配置项:
BGREWRITEAOF时AOF文件占用空间最小值,默认为64MB;Redis启动时把aof_base_size初始化为当时aof文件的大小,Redis运行过程中,当AOF文件重写操作完成时,会对其进行更新;aof_current_size为serverCron执行时AOF文件的实时大小。当满足以下两个条件时,AOF文件重写就会触发:
增长比例:(aof_current_size - aof_base_size) / aof_base_size > auto-aof-rewrite-percentage 文件大小:aof_current_size > auto-aof-rewrite-min-size
手动触发与自动触发的代码如下,同样在周期性方法serverCron中:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* 省略其他逻辑 */
/* 如果用户请求进行AOF文件重写时,Redis正在执行RDB持久化,Redis会安排在RDB持久化完成后执行AOF文件重写,
* 如果aof_rewrite_scheduled为true,说明需要执行用户的请求 */
if (!hasActiveChildProcess() &&
server.aof_rewrite_scheduled)
{
rewriteAppendOnlyFileBackground();
}
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 省略rdb持久化条件检查 */
/* AOF重写条件检查:aof开启、无子进程运行、增长百分比已设置、当前文件大小超过阈值 */
if (server.aof_state == AOF_ON &&
!hasActiveChildProcess() &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
/* 计算增长百分比 */
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
/**/
}AOF文件重写的流程是什么?听说Redis支持混合持久化,对AOF文件重写有什么影响?
从4.0版本开始,Redis在AOF模式中引入了混合持久化方案,即:纯AOF方式、RDB+AOF方式,这一策略由配置参数aof-use-rdb-preamble(使用RDB作为AOF文件的前半段)控制,默认关闭(no),设置为yes可开启。所以,在AOF重写过程中文件的写入会有两种不同的方式。当aof-use-rdb-preamble的值是:
结合源码(6.0版本,源码太多这里不贴出,可参考aof.c)及参考资料,绘制AOF重写(BGREWRITEAOF)流程图:
结合上图,总结一下AOF文件重写的流程:
父进程:
子进程:
aof-use-rdb-preamble configuration, use RDB or AOF Write the first half in AOF mode and synchronize it to the hard disk; After Redis is started, the data loading work is performed through the loadDataFromDisk function. It should be noted here that although the persistence method can be AOF, RDB, or both, a choice must be made when loading data. Loading the two methods separately will cause chaos.
Theoretically, AOF persistence has better real-time performance than RDB. When AOF persistence is enabled, Redis gives priority to AOF when loading data. Moreover, after Redis 4.0 version, AOF supports hybrid persistence, and version compatibility needs to be considered when loading AOF files. The Redis data loading process is shown in the figure below: 
In AOF mode, the file generated by turning on the hybrid persistence mechanism is "RDB head AOF tail", which is generated when it is not turned on. All files are in AOF format. Considering the compatibility of the two file formats, if Redis finds that the AOF file is an RDB header, it will use the RDB data loading method to read and restore the first half; and then use the AOF method to read and restore the second half. Since the data stored in the AOF format are RESP protocol commands, Redis uses a pseudo client to execute commands to recover the data.
If a downtime occurs during the appending process of the AOF command, the RESP command of the AOF may be incomplete (truncated) due to the technical characteristics of delayed writing. When encountering this situation, Redis will execute different processing strategies according to the configuration item aof-load-truncated. This configuration tells Redis to read the aof file when starting, and what to do if the file is found to be truncated (incomplete):
Redis provides two persistence options: RDB supports generating point-in-time snapshots for data sets at specific practical intervals; AOF stores each piece of data received by the Redis Server. The write command is persisted to the log, and the data can be restored by replaying the command when Redis is restarted. The log format is RESP protocol, and only the append operation is performed on the log file, so there is no risk of damage. And when the AOF file is too large, the compressed file can be automatically rewritten.
Of course, if you don't need to persist data, you can also disable Redis's persistence function, but this is not the case in most cases. In fact, we may sometimes use RDB and AOF at the same time. The most important thing is that we understand the difference between the two in order to use them reasonably.
redis-check-aof tool; After understanding the working principles, execution processes, advantages and disadvantages of the two persistence methods of RDB and AOF, let’s think about how to weigh the pros and cons in actual scenarios. , use two persistence methods reasonably. If you only use Redis as a caching tool, all data can be reconstructed based on the persistent database. You can turn off the persistence function and do protection work such as preheating, cache penetration, breakdown, and avalanche.
Generally, Redis will take on more work, such as distributed locks, rankings, registration centers, etc. The persistence function will play a greater role in disaster recovery and data migration. It is recommended to follow several principles:
Through the above analysis, we all know that RDB snapshots and AOF rewriting require fork. This is a heavyweight operation that will cause damage to Redis. block. Therefore, in order not to affect the response of the Redis main process, we need to reduce blocking as much as possible.
For more programming-related knowledge, please visit: Introduction to Programming! !
The above is the detailed content of Detailed explanation of the persistence principle of Redis in-depth learning. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis
























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



