AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この論文の著者は、南方科学大学彭城研究所マルチエージェント・身体性知能研究所の教師と学生です。テクノロジー、中山大学 チームには、Lin Liang 教授 (研究所所長、国家優秀若手研究者、IEEE フェロー)、Zheng Feng 教授、Liang Xiaodan 教授、Wang Zhiqiang (南方科技大学)、Zheng Hao が含まれます。 (南方科技大学)、Nie Yunshuang (香港)、Xu Wenjun (彭城)、Ye Hua (彭城)、他Pengcheng Laboratory の Lin Liang 教授のチームは、産業用インターネット、社会ガバナンスとサービスなどの主要なアプリケーション ニーズを強化するために、マルチエージェント コラボレーションやシミュレーション トレーニング プラットフォーム、クラウドベースの協調的な具体化されたマルチモーダル大規模モデルなどの一般的な基本プラットフォームの構築に取り組んでいます。 。 今年に入ってから、身体化インテリジェンスが学界や産業界で注目の分野となり、関連する製品や成果が次々と登場しています。本日、彭城研究所のマルチエージェント・身体化知能研究所(以下、彭城身体化研究所)は、南方科技大学および中山大学と共同で、科学分野における最新の学術成果を正式に公開し、オープンソース化しました。身体化インテリジェンス - ARIO (All Robots In One) 身体化大規模データセットは、現在身体化インテリジェンスの分野で直面しているデータ取得の問題を解決することを目的としています。 

論文タイトル: All Robots in One: A New Standard and Unified Dataset for Versatile.General-Purpose Embodied Agents
論文リンク: http://arxiv.org/abs/2408.10899
プロジェクトホームページ: https://imaei.github.io/project_pages/ario/
彭城研究所体現研究所ウェブサイトリンク: https://imaei.github.io/
具現化ロボットの頭脳として、具現化された大型モデルのパフォーマンスを向上させる鍵となるのは、高品質の具現化ビッグデータを取得することです。大規模な言語モデルや大規模なビジュアル モデルで使用されるテキストや画像データとは異なり、身体化されたデータはインターネットの膨大なコンテンツから直接取得することはできず、実際のロボットの操作を通じて収集するか、高度なシミュレーション プラットフォームによって生成する必要があります。具現化されたデータの収集には時間とコストがかかり、大規模化が難しい。 同時に、上の表に示すように、JD ManiData、ManiWAV、RH20T のデータ量は大きくなく、DROID に使用されるロボット ハードウェア プラットフォームにも多くの欠点があります。データは比較的単一である Open-X の実施形態は、大量のデータに達していますが、その感覚データ モダリティは十分に豊富ではなく、サブデータ セット間のデータ形式は均一ではなく、品質も不均一です。データを使用する前にフィルタリングして処理するのに多くの時間がかかり、複雑なシナリオで具体化されたインテリジェント モデルの効率的かつ的を絞ったトレーニングのニーズを満たすのは困難です。 これに対し、今回リリースされたARIOデータセットには、操作とナビゲーションの2つの主要カテゴリをカバーする、2D、3D、テキスト、タッチ、サウンドの5つのモダリティの感覚データが含まれています。 シミュレーション データと実際のシーン データの両方が含まれており、非常に豊富なさまざまなロボット ハードウェアが含まれています。データ規模は300万に達しますが、データの統一フォーマットも確保されており、身体化インテリジェンスの分野において高品質、多様性、大規模性を同時に実現するオープンソースのデータセットとなっています。 身体化知能のデータセットについては、ロボットには単腕、双腕、人型、四足など様々な形態があり、知覚や制御方法も異なるため、関節角度によって制御され、一部はボディまたはエンドポーズの座標によって駆動されるため、具体化されたデータ自体は単純な画像やテキストデータよりもはるかに複雑で、多くの制御パラメータを記録する必要があります。また、統一された形式がないと、複数種類のロボットデータを集約する際に追加の前処理に多大なエネルギーが費やされてしまいます。
したがって、彭城研究所の体現研究所はまず、体現されたビッグデータのための一連のフォーマット標準を設計しました。この標準は、さまざまな形式のロボット制御パラメータを記録でき、データ編成形式の明確な構造を持ち、また、異なるフレームレートのセンサーと互換性があり、対応するタイムスタンプを記録して、センシングと制御タイミングのための具体化されたインテリジェント大型モデルの正確な要件を満たします。以下の図は、ARIO データセットの全体的な設計を示しています。 O 図 1. ARIO データセットの設計
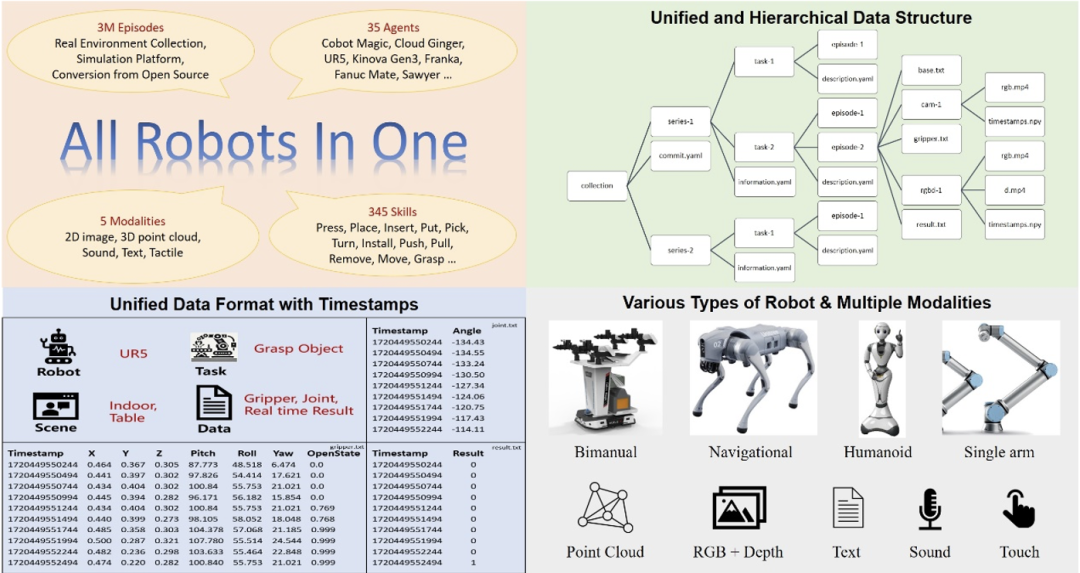
Ario データセット。合計 258 のシーン シーケンス、32,1064 のタスク、および 303 万のサンプル。 ARIO のデータは 3 つの主要なソースから得られます。1 つは、現実の環境にシーンやタスクを配置することによる現実の人物の収集、もう 1 つは、 MuJoCo や Habitat などのシミュレーション エンジンに基づいて、仮想シーンやオブジェクト モデルを設計し、 3 番目のステップは、現在オープンソースで組み込まれているデータセットを 1 つずつ分析および処理し、ARIO フォーマット標準に準拠したデータに変換することです。以下に、ARIO データセットの具体的な構成と、3 つのソースからのプロセスと例を示します。 高品質のロボット工学データは入手が困難ですが、非常に価値があります。 Pengcheng Laboratory は、マスター/スレーブ双腕ロボット Cobot Magic をベースに、単純 - 中 - 難しい 3 つの操作難易度レベルを含む 30 以上のタスクを設計し、干渉するオブジェクトを追加したり、オブジェクトとロボットの位置をランダムに変更したり、レイアウトの変更環境などを工夫してサンプルの多様性を高め、最終的にRGBDカメラ3台を含む3,000点以上の軌跡データを取得しました。さまざまなタスクの収集例と収集ビデオを以下に示します。 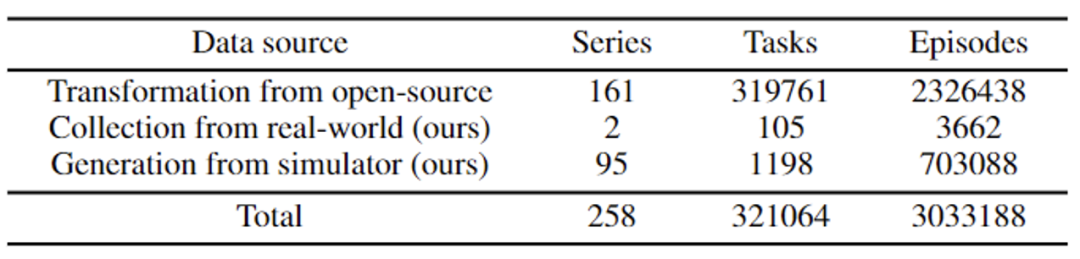 O 그림 3. Ario Real Robot 데이터 수집 예시 COBOT MAGIC Robotic Kimneys 컬렉션 데이터 예시 영상
O 그림 3. Ario Real Robot 데이터 수집 예시 COBOT MAGIC Robotic Kimneys 컬렉션 데이터 예시 영상  MUJOCO 시뮬레이션 데이터 수집 예시 영상
MUJOCO 시뮬레이션 데이터 수집 예시 영상 

 플랫폼 기반 시뮬레이션 데이터 생성 예시 영상
플랫폼 기반 시뮬레이션 데이터 생성 예시 영상  RH20T에서 변환된 데이터 예시 영상 덕분에 ARIO의 통일된 포맷 디자인 데이터를 사용하면 통계 분석을 쉽게 수행할 수 있습니다. 데이터 구성. 아래 그림은 시리즈, 태스크, 에피소드의 세 가지 수준에서 ARIO 장면(그림 a)과 스킬(그림 b)의 분포에 대한 통계를 보여줍니다. 현재 구현된 데이터의 대부분은 실내 생활 및 가정 환경의 장면과 기술에 중점을 두고 있음을 알 수 있습니다.
RH20T에서 변환된 데이터 예시 영상 덕분에 ARIO의 통일된 포맷 디자인 데이터를 사용하면 통계 분석을 쉽게 수행할 수 있습니다. 데이터 구성. 아래 그림은 시리즈, 태스크, 에피소드의 세 가지 수준에서 ARIO 장면(그림 a)과 스킬(그림 b)의 분포에 대한 통계를 보여줍니다. 현재 구현된 데이터의 대부분은 실내 생활 및 가정 환경의 장면과 기술에 중점을 두고 있음을 알 수 있습니다.
ARIO 데이터는 시나리오와 스킬 외에도 로봇 자체의 관점에서 통계 분석을 수행하고 로봇 산업의 현재 개발 동향을 배울 수 있습니다. ARIO 데이터 세트는 로봇의 형상, 움직이는 물체, 물리적 제어 변수, 센서 종류 및 설치 위치, 시각 센서 수, 제어 방식 비율, 데이터 수집 방식 비율, 개수 비율에 대한 통계 데이터를 제공합니다. 아래 그림 a-i에 해당하는 로봇 팔의 자유도. 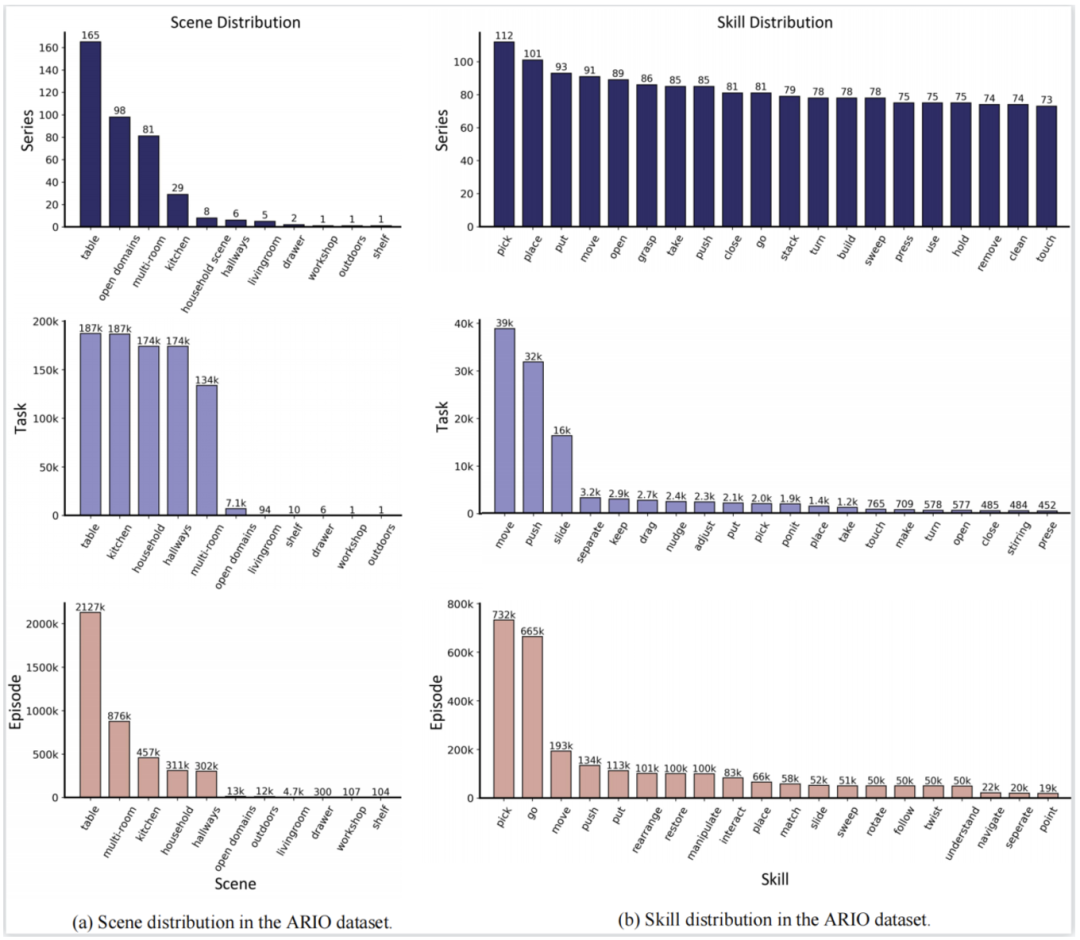
아래 그림을 예로 들면, 현재 대부분의 데이터는 단일 팔 로봇에서 나온 것임을 알 수 있습니다. 휴머노이드 로봇에 대한 오픈 소스 데이터는 거의 없으며 주로 실제 수집에서 나온 것입니다. Pengcheng 연구소의 시뮬레이션 생성. ㅋㅋㅋ >
以上が具現化されたインテリジェンスデータは高価すぎると常に言われていますが、Pengcheng Laboratoryは100万規模の標準化されたデータセットをオープンソースしましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



