AIxivコラムは、本サイト上で学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
GPT に代表される大規模言語モデルは、デジタル認知空間における一般的な人工知能の夜明けを告げます。これらのモデルは、自然言語を処理および生成することによって強力な理解および推論能力を実証し、複数の分野での幅広い応用の見通しを示しています。コンテンツ生成、自動化された顧客サービス、生産性ツール、AI 検索、あるいは教育や医療などの分野においても、大規模な言語モデルは常にテクノロジーの進歩とアプリケーションの普及を促進しています。
しかし、物理世界の探索に向けて一般的な人工知能を促進するには、最初のステップは、視覚的な理解の問題、つまり、大きなモデルのマルチモーダルな理解を解決することです。マルチモーダル理解により、AI は人間と同じように複数の感覚を通じて情報を取得して処理することで、世界をより完全に理解し、対話できるようになります。この分野のブレークスルーにより、人工知能はロボット工学や自動運転などにおいてさらなる進歩を遂げ、デジタル世界から物理世界への飛躍を真に実現することができるでしょう。
GPT-4Vは昨年6月にリリースされましたが、大規模な言語モデルと比較して、マルチモーダル理解モデルの開発は、特に中国語分野で遅れているようです。さらに、技術的なルートと比較的確実な大規模言語モデルの選択とは異なり、マルチモーダル モデルのアーキテクチャとトレーニング方法の選択については、業界はまだ完全に合意に達していません。

” ” ” 認知空間から物理世界への大規模モデルの開発経路
最近、テンcent Hunyuan は MoE アーキテクチャに基づくマルチモード モデルを発表しました大きなモデルの技術的理解。このモデルは、アーキテクチャ、トレーニング方法、データ処理の点で革新的かつ徹底的に最適化されており、パフォーマンスが大幅に向上し、あらゆるアスペクト比と最大 7K 解像度の画像の理解をサポートします。主にオープンソースのベンチマークで調整されたほとんどのマルチモーダル モデルとは異なり、Tencent のハイブリッド マルチモーダル モデルは、モデルの汎用性、実用性、信頼性により重点を置いており、豊富なマルチモーダル シーン理解機能を備えています。最近リリースされた中国のマルチモーダル大型モデル SuperCLUE-V ベンチマーク評価 (2024 年 8 月) では、Tencent Hunyuan が複数の主流クローズドソース モデルを上回り、国内で 1 位にランクされました。
Tencentの混合言語大規模モデルは、中国で初めて混合エキスパートモデル(MoE)アーキテクチャを採用しており、モデルの全体的なパフォーマンスは、以前のモデルよりも50%高くなります。 GPT-4o と連携し、数学、推論、その他の能力だけでなく、「現在」の質問に答えるパフォーマンスも大幅に向上しました。今年の初めには、Tencent Hunyuan がこのモデルを Tencent Yuanbao に適用しました。
Tencent Hunyuan は、多数の一般的なタスクを解決できる MoE アーキテクチャは、マルチモーダルな理解シナリオにとっても最適な選択であると信じています。 MoE は、より多くのモダリティやタスクとの互換性が向上し、さまざまなモダリティやタスクが競合するのではなく相互に強化されるようになります。
Tencent Hunyuan の大規模言語モデルの機能に依存して、Tencent Hunyuan は MoE アーキテクチャに基づいた大規模なマルチモーダル理解モデルを立ち上げ、アーキテクチャ、トレーニング方法、データの面で革新と徹底的な最適化を行いました。処理が強化され、パフォーマンスが大幅に向上しました。これは、中国の教育省アーキテクチャに基づいた初のマルチモーダル大型モデルでもあります。

モ Tencent 混合要素マルチモード モデル アーキテクチャの概略図
MOE アーキテクチャの使用に加えて、Tencent 混合要素マルチモード モデルの設計もシンプルで合理的なスケーラビリティの原則に従います:
ネイティブの任意の解像度をサポート: 業界の主流の固定解像度またはカットサブグラフ方式と比較して、Tencent のハイブリッド マルチモーダル モデルは、あらゆる解像度のネイティブ画像を処理できます。 7K を超える解像度と任意のアスペクト比 (例: 16:1、以下の例を参照) で画像の理解をサポートするマルチモーダル モデル。
-
シンプルな MLP アダプターの使用: 以前の主流の Q-former アダプターと比較して、MLP アダプターは情報伝送中の損失が少なくなります。
-
このシンプルなデザインにより、モデルとデータの拡張とスケールが簡単になります。
SuperClue-Vが国内リスト1位にランクイン
2024年8月、SuperCLUEは初めてマルチモーダル理解評価リストSuperClue-Vをリリースしました。
SuperCLUE-V ベンチマークには、基本機能とアプリケーション機能という 2 つの一般的な方向性が含まれており、8 つの第 1 レベルのディメンションと 30 の第 2 レベルのディメンションを含むマルチモーダルな大規模モデルを未解決の質問の形式で評価します。
この評価では、Hunyuan マルチモーダル理解システム hunyuan-vision は、GPT-4o に次いで 2 番目のスコア 71.95 を達成しました。マルチモーダル アプリケーションの点では、hunyuan-vision は Claude3.5-Sonnet や Gemini-1.5-Pro よりも優れています。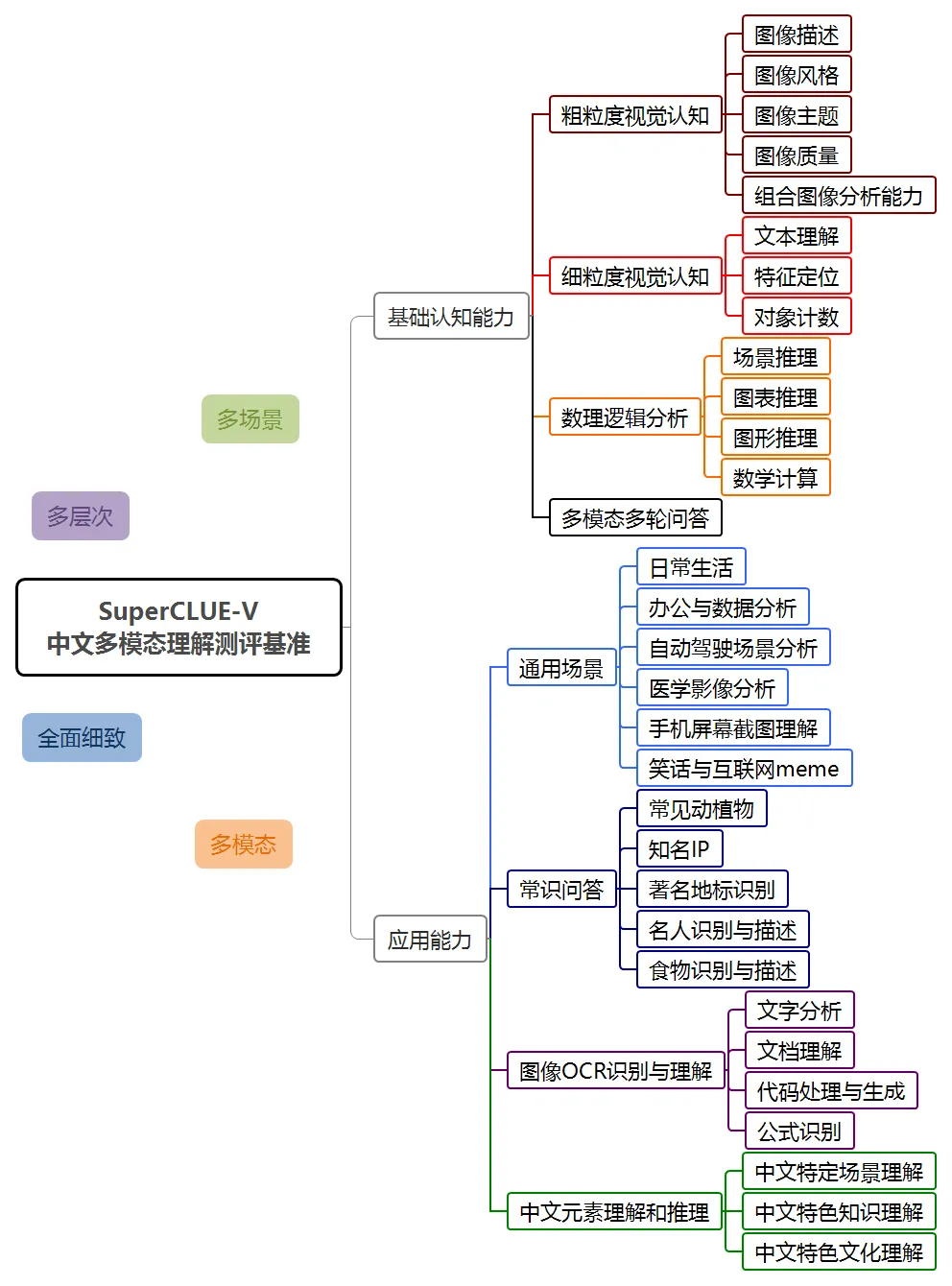
業界におけるこれまでのマルチモーダル評価は主に英語能力に焦点を当てており、評価質問のほとんどが多肢選択式または正誤問題であったことは注目に値します。 SuperCLUE-V の評価は、中国語の能力評価に重点を置き、ユーザーの実際の問題に焦点を当てています。また、これは最初のリリースであるため、オーバーフィッティングはまだ発生していません。
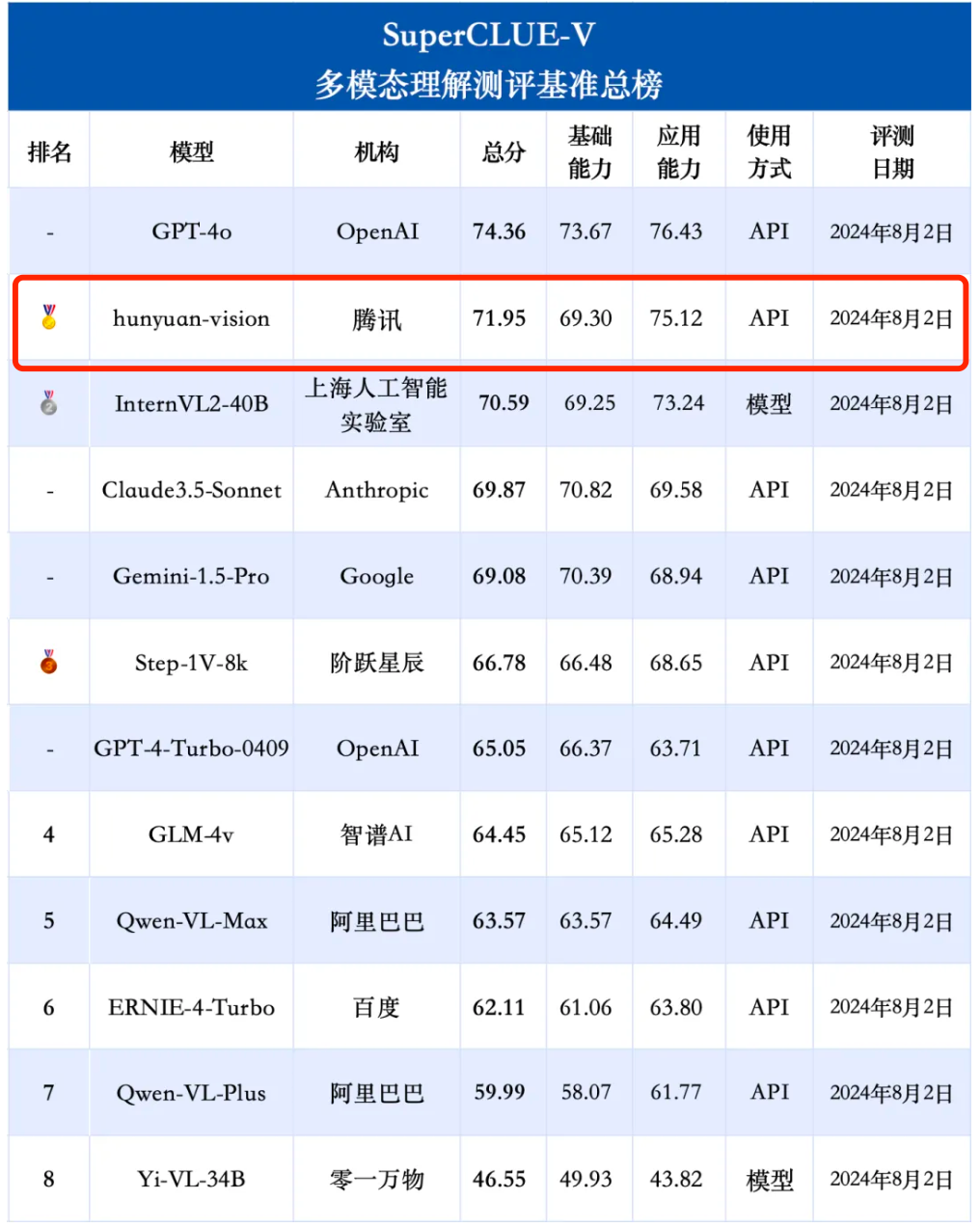
Tencent Hunyuan グラフィックスおよびテキストのラージ モデルは、一般的なシーン、画像 OCR の認識と理解、中国語要素の理解と推論などの複数の側面で優れたパフォーマンスを示し、将来のアプリケーションにおけるモデルの可能性も反映しています。 。
 一般的なアプリケーションシナリオを対象としています
一般的なアプリケーションシナリオを対象としています
混合要素マルチモーダル理解モデルは、一般的なシナリオと大規模なアプリケーション向けに最適化されており、基本的なものをカバーする数千万件の関連する質問と回答のコーパスを蓄積しています画像理解、コンテンツ作成、推論分析、知識問答、OCR文書分析、被験者回答など様々なシーンでご利用いただけます。以下に代表的なアプリケーション例をいくつか示します。
さらに典型的な例を示します:
コードの一部を説明します: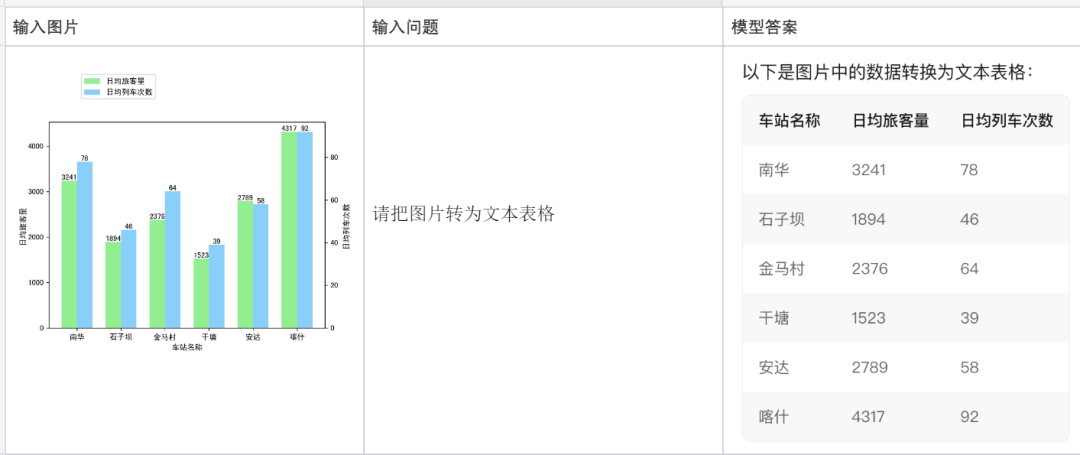
請求書を分析する: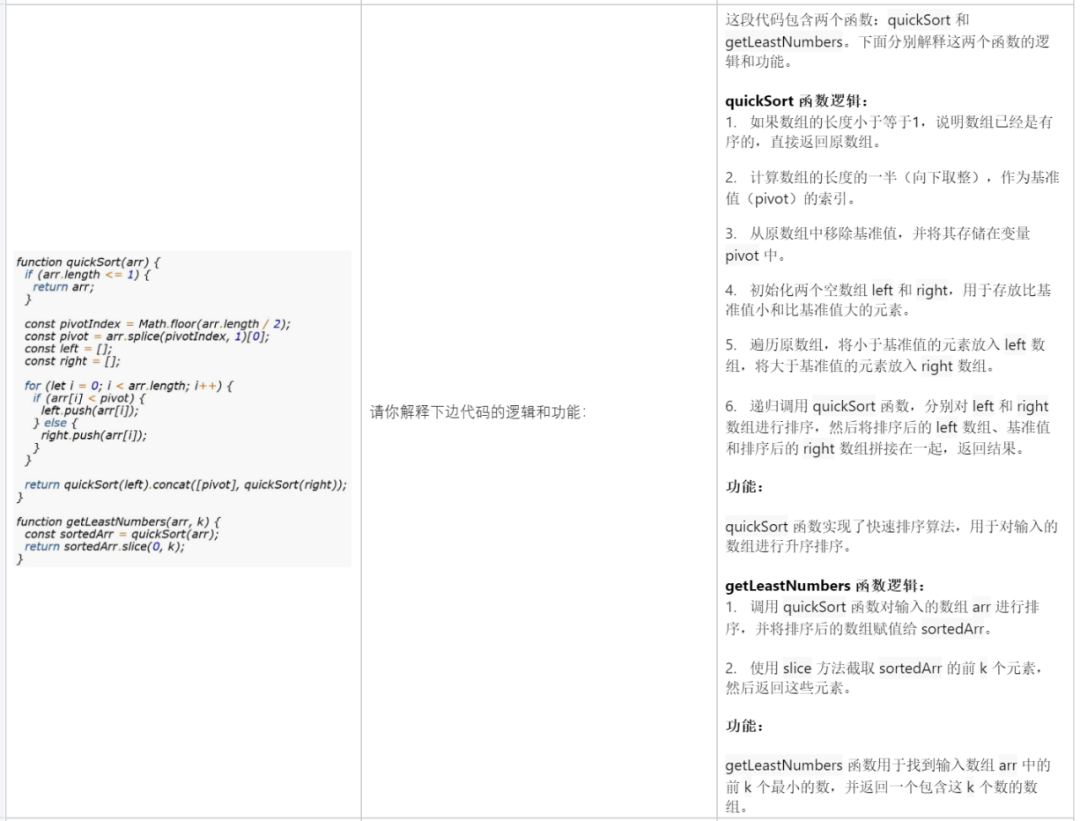
説明画像コンテンツ: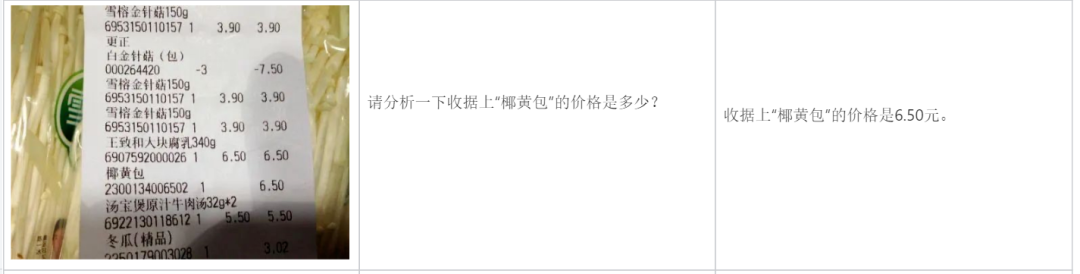
数学の問題を行う:
画像コンテンツに基づいて分析する: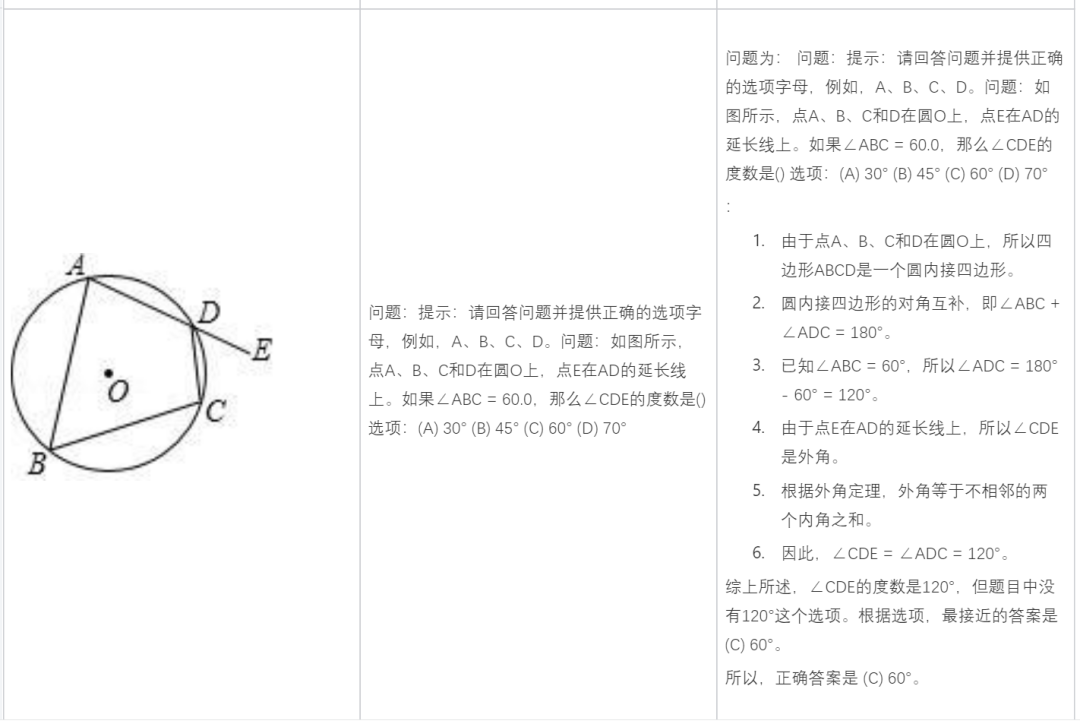
コピーを書くのを手伝う:
現在、Tencent の Hunyuan マルチモーダル理解大規模モデルは、AI アシスタント製品である Tencent Yuanbao でリリースされており、Tencent Cloud を通じて企業と個人の開発者に公開されています。
テンセント元宝アドレス: https://yuanbao.tencent.com/chat
以上が中国初の自社開発環境省マルチモーダル大規模モデルは、テンセントの混合要素マルチモーダル理解を明らかにするの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



