


php editor Banana comprehensively analyzes the underlying implementation logic of PHP arrays. The array in PHP is a flexible and powerful data structure, but the implementation logic behind it is quite complex. In this article, we will delve into the underlying principles of PHP arrays, including the internal structure of the array, the relationship between indexes and hash tables, and how to implement the add, delete, modify, and query operations of the array. By understanding the underlying implementation logic of PHP arrays, developers can better understand and utilize arrays, an important data structure.
What does an array look like in the PHP kernel? We can see the structure from PHP's source code as follows: The difference between
<code>// 定义结构体别名为 HashTable
typedef struct _zend_array HashTable;
struct _zend_array {
// <strong class="keylink">GC</strong> 保存引用计数,内存管理相关;本文不涉及
zend_refcounted_h gc;
// u 储存辅助信息;本文不涉及
u<strong class="keylink">NIO</strong>n {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar consistency)
} v;
uint32_t flags;
} u;
// 用于散列函数
uint32_t nTableMask;
// arData 指向储存元素的数组第一个 Bucket,Bucket 为统一的数组元素类型
Bucket *arData;
// 已使用 Bucket 数
uint32_t nNumUsed;
// 数组内有效元素个数
uint32_t nNumOfElements;
// 数组总容量
uint32_t nTableSize;
// 内部指针,用于遍历
uint32_t nInternalPointer;
// 下一个可用数字<strong class="keylink">索引</strong>
zend_long nNextFreeElement;
// 析构函数
dtor_func_t pDestructor;
};</code>##nNumUsed and nNumOfElements: nNumUsed refers to the Bucket number that has been used in the arData array, because the array only replaces the Bucket corresponding value of the element after deleting the element. The type is set to IS_UNDEF (because it would be a waste of time to move and re-index the array every time an element is deleted), and nNumOfElements corresponds to the actual number of elements in the array.
nTableSize The capacity of the array, this value is the power of 2. PHP's arrays are of variable length, but C language arrays are of fixed length. In order to realize the function of PHP's variable-length arrays, the "expansion" mechanism is adopted, which is to determine whether nTableSize is determined every time an element is inserted. Enough to store. If it is insufficient, re-apply for a new array 2 times the size of nTableSize, and copy the original array (this is the time to clear the elements of type IS_UNDEF in the original array) and re-index. .
nNextFreeElement Saves the next available numeric index, for example in PHP $a[] = 1; This usage will insert an index is the element of nNextFreeElement, and then nNextFreeElement is incremented by 1.
_zend_array This structure will be discussed here first. The functions of some structure members will be explained below, so don’t be nervous O(∩_∩)O haha~. Let’s take a look at the Bucket structure as an array member:
<code>typedef struct _Bucket {
// 数组元素的值
zval val;
// key 通过 Time 33 <strong class="keylink">算法</strong>计算得到的哈希值或数字索引
zend_ulong h;
// 字符键名,数字索引则为 NULL
zend_string *key;
} Bucket;</code>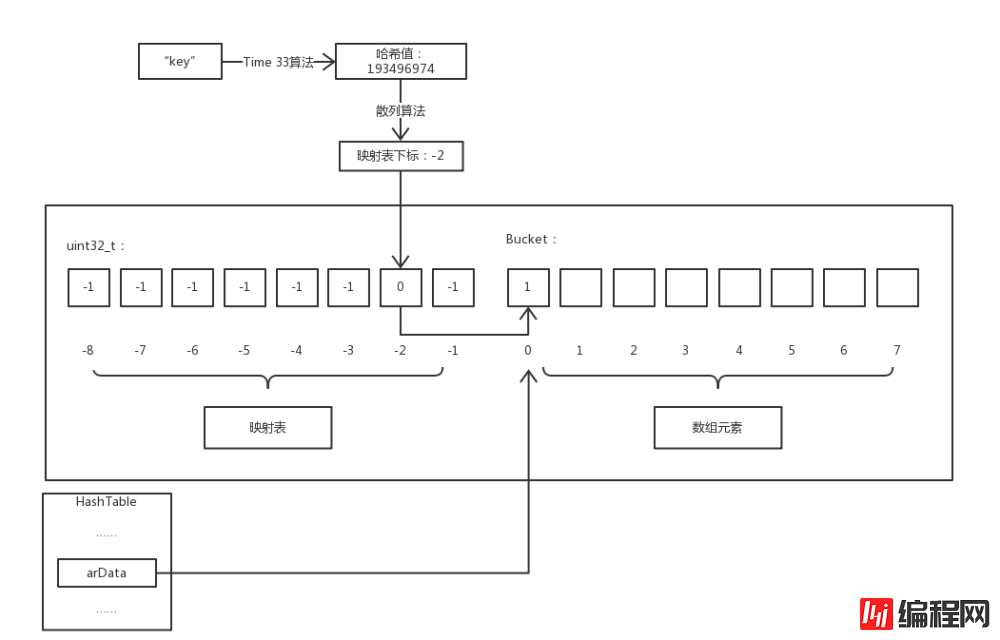
Note: Because the key name to the mapping table subscript has been hashed twice, in order to distinguish it, this article uses hash to refer to the first hash. The hash is the second hash.
As can be seen from the figure, the mapping table and array elements are in the same continuous memory. The mapping table is an integer array with the same length as the storage elements. Its default value is -1 and the valid value isBucket The subscript of the array. And HashTable->arData points to the first element of the Bucket array in this memory.
$a['key'] Access the member whose key is key in the array$a. The process is introduced: first pass Time 33 algorithm calculates the hash value of key, and then uses the hash algorithm to calculate the mapping table subscript corresponding to the hash value, because the value saved in the mapping table is Bucket The subscript value in the array, so the corresponding element in the Bucket array can be obtained.
<code>nIndex = h | ht->nTableMask;</code>
nTableMask to get the subscript of the mapping table, where the value of nTableMask is # Negative number of ##nTableSize. And since the value of nTableSize is a power of 2, the value range of h | ht->nTableMask is in [-nTableSize, -1] between, exactly within the subscript range of the mapping table. As for why not use a simple "remainder" operation but go to all the trouble of using a "bitwise OR" operation? Because the "bitwise OR" operation is much faster than the "remainder" operation, I think that for this frequently used operation, the time optimization brought about by a more complex implementation is worth it. Hash conflict
这看似与第一张图差不多,但我们同样访问 $a['key'] 的过程多了一些步骤。首先通过散列运算得出映射表下标为 -2 ,然后访问映射表发现其内容指向 arData 数组下标为 1 的元素。此时我们将该元素的 key 和要访问的键名相比较,发现两者并不相等,则该元素并非我们所想访问的元素,而元素的 val.u2.next 保存的值正是下一个具有相同散列值的元素对应 arData 数组的下标,所以我们可以不断通过 next 的值遍历直到找到键名相同的元素或查找失败。
插入元素的函数 _zend_hash_add_or_update_i ,基于 PHP 7.2.9 的代码如下:
<code>static zend_always_inline zval *_zend_hash_add_or_update_i(HashTable *ht, zend_string *key, zval *pData, uint32_t flag ZEND_FILE_LINE_DC)
{
zend_ulong h;
uint32_t nIndex;
uint32_t idx;
Bucket *p;
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) { // 数组未初始化
// 初始化数组
CHECK_INIT(ht, 0);
// 跳转至插入元素段
goto add_to_hash;
} else if (ht->u.flags & HASH_FLAG_PACKED) { // 数组为连续数字索引数组
// 转换为关联数组
zend_hash_packed_to_hash(ht);
} else if ((flag & HASH_ADD_NEW) == 0) { // 添加新元素
// 查找键名对应的元素
p = zend_hash_find_bucket(ht, key);
if (p) { // 若相同键名元素存在
zval *data;
if (flag & HASH_ADD) { // 指定 add 操作
if (!(flag & HASH_UPDATE_INDIRECT)) { // 若不允许更新间接类型变量则直接返回
return NULL;
}
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组成员值
data = &p->val;
if (Z_TYPE_P(data) == IS_INDIRECT) { // 原数组元素变量类型为间接类型
// 取间接变量对应的变量
data = Z_INDIRECT_P(data);
if (Z_TYPE_P(data) != IS_UNDEF) { // 该对应变量存在则直接返回
return NULL;
}
} else { // 非间接类型直接返回
return NULL;
}
} else { // 没有指定 add 操作
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组元素值
data = &p->val;
// 允许更新间接类型变量则 data 指向对应的变量
if ((flag & HASH_UPDATE_INDIRECT) && Z_TYPE_P(data) == IS_INDIRECT) {
data = Z_INDIRECT_P(data);
}
}
if (ht->pDestructor) { // 析构函数存在
// 执行析构函数
ht->pDestructor(data);
}
// 将 pData 的值复制给 data
ZVAL_COPY_VALUE(data, pData);
return data;
}
}
// 如果哈希表已满,则进行扩容
ZEND_HASH_IF_FULL_DO_RESIZE(ht);
add_to_hash:
// 数组已使用 Bucket 数 +1
idx = ht->nNumUsed++;
// 数组有效元素数目 +1
ht->nNumOfElements++;
// 若内部指针无效则指向当前下标
if (ht->nInternalPointer == HT_INVALID_IDX) {
ht->nInternalPointer = idx;
}
zend_hash_iterators_update(ht, HT_INVALID_IDX, idx);
// p 为新元素对应的 Bucket
p = ht->arData + idx;
// 设置键名
p->key = key;
if (!ZSTR_IS_INTERNED(key)) {
zend_string_addref(key);
ht->u.flags &= ~HASH_FLAG_STATIC_KEYS;
zend_string_hash_val(key);
}
// 计算键名的哈希值并赋值给 p
p->h = h = ZSTR_H(key);
// 将 pData 赋值该 Bucket 的 val
ZVAL_COPY_VALUE(&p->val, pData);
// 计算映射表下标
nIndex = h | ht->nTableMask;
// 解决冲突,将原映射表中的内容赋值给新元素变量值的 u2.next 成员
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
// 将映射表中的值设为 idx
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
return &p->val;
}</code>前面将数组结构的时候我们有提到扩容,而在插入元素的代码里有这样一个宏 ZEND_HASH_IF_FULL_DO_RESIZE,这个宏其实就是调用了 zend_hash_do_resize 函数,对数组进行扩容并重新索引。注意:并非每次 Bucket 数组满了都需要扩容,如果 Bucket 数组中 IS_UNDEF 元素的数量占较大比例,就直接将 IS_UNDEF 元素删除并重新索引,以此节省内存。下面我们看看 zend_hash_do_resize 函数:
重新索引的逻辑在 zend_hash_rehash 函数中,代码如下:
嗯哼,本文就到此结束了,因为自身水平原因不能解释的十分详尽清楚。这算是我写过最难写的内容了,写完之后似乎觉得这篇文章就我自己能看明白/(ㄒoㄒ)/~~因为文笔太辣鸡。想起一句话「如果你不能简单地解释一样东西,说明你没真正理解它。」PHP 的源码里有很多细节和实现我都不算熟悉,这篇文章只是一个我的 PHP 底层学习的开篇,希望以后能够写出真正深入浅出的好文章。
The above is the detailed content of Comprehensive analysis of the underlying implementation logic of PHP arrays. For more information, please follow other related articles on the PHP Chinese website!










![Getting Started with PHP Practical Development: PHP Quick Creation [Small Business Forum]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)





![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



