The implementation of virtual memory needs to be based on the discretely allocated memory management method. There are three implementation methods: 1. Request paging storage management method; 2. Request segmented storage management method; 3. Segment page storage management method. No matter which method is used, certain hardware support is required: 1. A certain capacity of memory and external memory; 2. Page table mechanism (or segment table mechanism), as the main data structure; 3. Interrupt mechanism, when the user program needs If the accessed part has not yet been transferred into the memory, an interrupt will occur; 4. Address conversion mechanism, conversion from logical address to physical address.
#The operating environment of this tutorial: linux7.3 system, Dell G3 computer.
1. Overview of virtual memory
Traditional storage management keeps multiple processes in memory at the same time to allow multi-programming. They all have the following two common characteristics:
One-time:The job must be done onceAfter all is loaded into the memory, to start running. This will lead to two situations: 1) When the job is large and cannot be loaded into the memory, the job will be unable to run; 2) When a large number of jobs are required to be run, due to insufficient memory, For all jobs, only a few jobs can be run first, resulting in a decrease in multiprogramming.
Residency:After the job is loaded into the memory, it will alwaysresident in the memory, and no part of it will be swapped out,Until the job runs to the end. A running process will be blocked waiting for I/O and may be in a long-term waiting state.
Therefore, many programs (data) that are not used during program operation or are not used temporarily occupy a large amount of memory space, and some jobs that need to be run cannot be loaded and run, which obviously wastes precious memory. resource.
1.1 Definition and characteristics of virtual memory
Based on thelocalityprinciple, when the program is loaded , you can loadpart of the program into the memory, and leave the rest in external memory, and you can start the program execution. During the execution of the program, when the accessed information is not in the memory, the operating systemwill transfer the required part into the memory, and then continue to execute the program. On the other hand, the operating system swaps out the temporarily unused content in the memory to external storage, thereby freeing up space to store the information that will be transferred into the memory.In this way, since the system provides
partial loading, request transfer and replacement functions(completely transparent to the user), the user feels as if there is a Memory that is much larger than actual physical memory is calledvirtual memory.The
size of virtual memory is determined by the address structure of the computer
, and is not a simple sum of memory and external memory.
Virtual storage has the following three main characteristics:
Multiple times: No need to install it all at once when the job is running into memory, but allows it to be divided into multiple times and loaded into memory for execution.
Swapability
: There is no need to stay in memory while the job is running, but allows swapping in and out during the running process of the job.
Virtuality
: Logically expand the memory capacity so that the memory capacity seen by the user is much larger than the actual memory capacity.
1.2 Implementation of virtual memory technology
Virtual memory allowsa job to be transferred into the memory multiple times
.
When the continuous allocation method is used, a considerable part of the memory space will be in a temporary or "permanent" idle state, resulting in a serious waste of memory resources, and it is impossible to logically expand the memory capacity.
Therefore, the implementation of virtual memory needs to be based on the
discrete allocation
memory management method. There are three ways to implement virtual memory:
Request paging
Storage management
Request segmentation
Storage management
Segment page type
Storage management
No matter which method is used, certain
hardware support
is required. The support generally required includes the following aspects:
A certain amount of memory and external storage.
Page table mechanism (or segment table mechanism), as the main data structure.
Interrupt mechanism, when the part to be accessed by the user program has not been transferred into the memory, an interrupt is generated.
Address conversion mechanism, conversion of logical address to physical address.
Continuous allocation method
:refers to allocating acontinuous memory spacefor a user program.
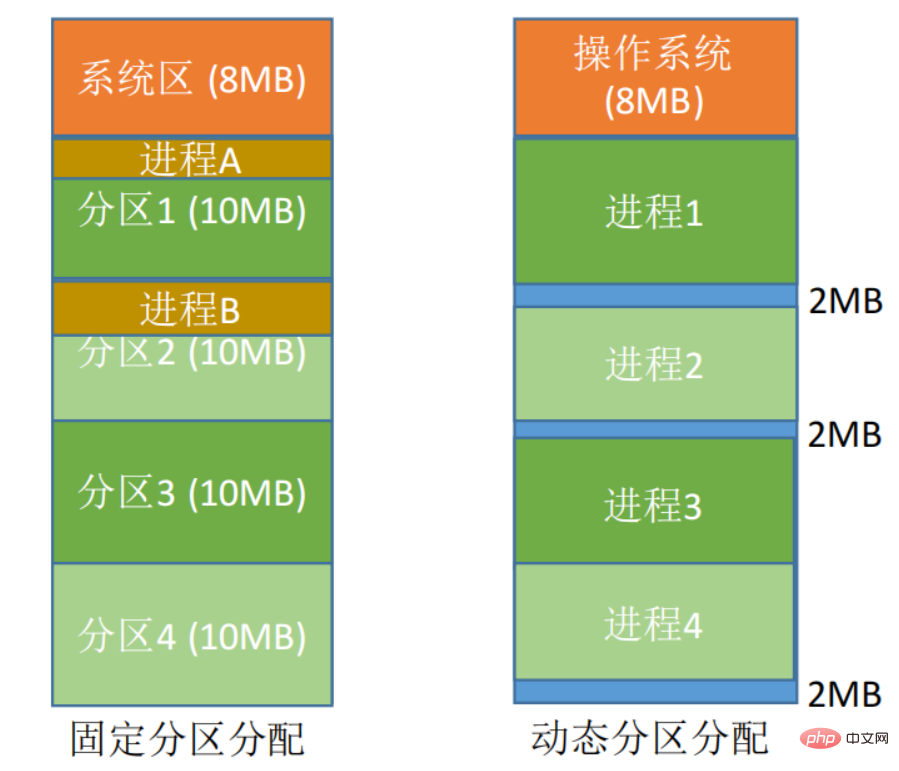
Fixed partition allocation:Divide the memory space into several fixed-size areas. Only one job is loaded into each partition, and multiple jobs can be executed concurrently. Lack of flexibility will produce a large amount ofinternal fragmentation, andmemory utilization is very low.
Dynamic partition allocation:Dynamicly allocate memory space to the process according to its actual needs. When a job is loaded into memory, the available memory is divided into a continuous area for the job, and the size of the partition is exactly suitable for the size of the job. A lot ofexternal debris will be generated.
##Discrete allocation method:Load a processinto discrete distributionTo manynon-adjacent partitions, you can make full use of memory.
The concept of paging storage:
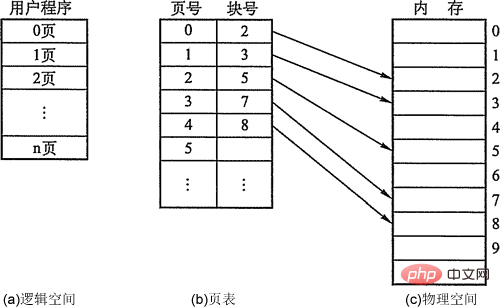
Pages, page frames and blocks.
The block in the processis calledpage or page (Page), with a page number;The block in the memoryis calledPage Frame(Page Frame, page frame = memory block = physical block = physical page), has a page frame number.External storageis also divided in the same unit, directly calledBlock. When a process is executed, it needs to apply for main memory space, which means that each page must be allocated an available page frame in the main memory, which creates a one-to-one correspondence between pages and page frames. Each page does not have to be stored consecutively and can be placed in non-adjacent page frames.
Address structure: The first part is thepage number P, and the latter part is thepage offset W. The address length is 32 bits, of which bits 0~11 are the intra-page address, that is, the size of each page is 4KB; bits 12~31 are the page number, and the address space allows up to 2^20 pages.
Page table. In order to facilitatefinding the physical blockcorresponding to each page of the process in the memory, the system establishes a page table for each process to record the physical block number corresponding to the page in the memory,Page table Generally stored in memory. After the page table is configured, when the process is executed, the physical block number of each page in the memory can be found by looking up the table. It can be seen that the role of the page table is toimplement the address mappingfrom the page number to the physical block number.
2. Request paging management to implement virtual memory
Request pagingIt is currently the most commonly used method to implement virtual memory.
The request paging system is based on the
basic paging system. In order to support the virtual memory function, therequest pagingfunction andpage replacement## are added. #Function.In the request paging system, only a part of the currently required pages are required to be loaded into the memory before the job can be started.
During the execution of the job, when the page to be accessed is not in the memory, it can be brought in through the paging function. At the same time, the temporarily unused pages can also be swapped out to external memory through the replacement function to free up memory. space.
In order to implement request paging, the system must provide certain hardware support. In addition to a computer system that requires a
certain capacity of memory and external storage, it also needs apage table mechanism, page fault interrupt mechanism, and address conversion mechanism.
2.1 Page table mechanism#The page table mechanism of the request paging system is different from the basic paging system. The request paging system does not start before a job is run. All are required to be loaded into memory at once.
Therefore, during the running process of the job, there will inevitably be a situation where the page to be accessed is not in the memory. How to detect and deal with this situation are two basic problems that the request paging system must solve. To this end, four fields are added to the request page table entry, which are:
Page table entry in the request paging system
Status bit P: Used to indicate whether the page has been transferred into memory for reference when the program accesses it.
Access field A: Used to record the number of times this page has been accessed within a period of time, or record how long this page has not been accessed recently for the replacement algorithm to swap out the page. refer to.
Modification bit M: Indicates whether the page has been modified after being transferred into memory.
External memory address: Used to indicate the address of the page on the external memory, usually the physical block number, for reference when loading the page.
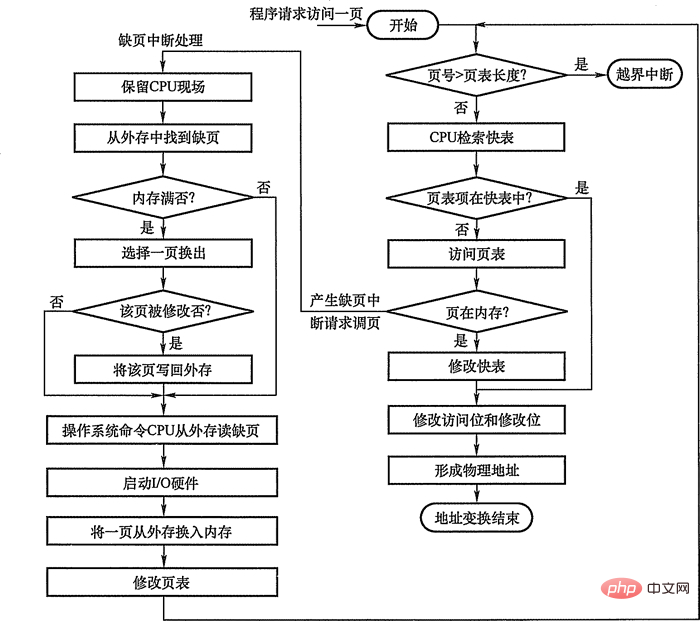
2.2 Page fault interrupt mechanism
In the request paging system, whenever the page to beaccessed is not in the memory, apage missing interruptis generated, requesting the operating system to transfer the missing page into the memory.
At this time, the process with page fault should be blocked (wake up after paging is completed). If there is a free block in the memory, allocate a block, load the page to be loaded into the block, and modify the corresponding page table Page table entry; if there is no free block in the memory at this time, a certain page must be eliminated (if the eliminated page has been modified during the memory period, it must be written back to external memory).
Page fault interrupts also need to be experienced as interrupts, such as protecting the CPU environment, analyzing the cause of the interrupt, transferring to the page fault interrupt handler, and restoring the CPU environment. But compared with general interrupts, it has the following two obvious differences:
The interrupt signal is generated and processed during the execution of the instruction, rather than after an instruction is executed, it is an internal interrupt.
During the execution of an instruction, multiple page fault interrupts may occur.
2.3 Address conversion mechanism
The address conversion mechanism in the request paging system is based on the address conversion mechanism of the paging system , formed by adding certain functions to implement virtual memory.
Address transformation process in request paging
When performing address translation, first search thefast table:
If the page to be accessed is found, the access bit in the page table entry is modified (the write instruction is also The modification bit must be reset), and then the physical block number and intra-page address given in the page table entry are used to form the physical address.
If the page table entry of the page is not found, the page table should be searched in the memory, and then compared with the status bit P in the page table entry to see whether the page has been transferred into the memory. If not, an error message will appear. Page fault interrupt, requesting that the page be transferred from external memory into memory.
Page tableIndicates the correspondence between the page number in the logical address and the physical block number of the occupied main memory. Page storage management uses page tables to perform address translation when loading operations using dynamic relocation.
Fast table (TLB, Translation Lookaside Buffer)is a partial page table stored in the cache memory. As the Cache of the current process page table, its function is similar to the page table, butspeeds up the address mapping speedand increases the access rate.
Because the page table is used for address translation, the CPU has to access the main memory twice (querying the page table and accessing the destination address) when reading and writing memory data.
With the fast table, sometimes the cache memory and the main memory only need to be accessed once, which can speed up the search and increase the instruction execution speed.
3. Page replacement algorithm
When the process is running, if the page it accesses is not in the memory, it needs to be brought in, butthe memory has been When there is no free space, it is necessary to load a page of program or data from the memory and send it to the swap area of the disk.
The algorithm for selecting the page to call out is called the page replacement algorithm. A good page replacement algorithm shouldlower page replacement frequency, that is, pages that will not be accessed again in the future or will not be accessed for a long time in the future should be called out first.
3.1 Optimal replacement algorithm (OPT)
##The best (Optimal, OPT) replacement algorithmselected The eliminated pages will never be used in the future, or will not be accessed for the longest period of time. This can ensure the lowest page fault rate.
cannot predictwhich of the thousands of pages in the memory of the process will no longer be accessed in the longest time in the future, sothis algorithm cannot be implemented, but the optimal replacement algorithm can be used toevaluate other algorithms.
When the process is running, the three pages 7, 0, and 1 are first loaded into the memory in sequence. When the process wants to access page 2, a page fault interrupt occurs. According to the optimal replacement algorithm, page 7, which needs to be transferred only after the 18th access, is selected and eliminated. Then, when page 0 is accessed, there is no need to generate a page fault interrupt because it is already in memory. When page 3 is accessed, page 1 will be eliminated based on the optimal replacement algorithm... and so on. From the figure we can see the situation when using the optimal replacement algorithm.
Page number
Physical block number
Status bit P
Access field A
Modify bit M
External storage address
But because people currentlyAssume that the system allocates three physical blocks to a process, and consider the following page number reference string:
Displacement graph when using the optimal displacement algorithm
Visit page
7
0
1
2
0
3
0
4
2
3
0
3
2
1
2
0
1
7
0
1
##Physical Block 1
7
7
7
2
##2
2
##2
##2
#7
Physical Block 2
0
0
0
0
4
0
##0
0
##Physical Block 3
##1
1
3
3
##3
1
##1
Missing Page No
√
√
√
##√
##√
##√
##√
√
##
It can be seen that the number of page fault interruptions is 9, and the number of page replacements is 6.
The page that enters the memory earliestis eliminated first, that is, The page that has resided longest in memory.
The algorithm is simple to implement. You only need to link the pages transferred into the memory into aqueueaccording to the order, and set a pointer to always point to the earliest page. However, this algorithmis not suitable for the actual running time of the process, because some pages are frequently accessed during the process.
Displacement graph when using FIFO replacement algorithm
Visit page
7
0
1
2
0
3
0
4
2
3
0
3
2
1
2
0
1
7
0
1
Physical Block 1
7
7
7
2
2
2
4
4
4
0
0
0
##7
7
7
Physical Block 2
0
0
0
##33
3
2
2
2
##1
1
##1
0
0
Physical Block 3
1
1
1
0
00
3
3
3
2
##2
2
1
Missing Page No
√
√
√
√
##√
√
##√
√
√
√
##√
√
√
√
√
When using the FIFO algorithm, 12 page replacements are performed, which is exactly twice as many as the optimal replacement algorithm.
The FIFO algorithm will also produce the abnormal phenomenon that when the number of allocatedphysical blocks increases, the number of page faults does not decrease but increases. This was discovered by Belady in 1969, so it is calledBelady exception, as shown in the table below.
Only the FIFO algorithm may have Belady anomalies, while the LRU and OPT algorithms will never experience Belady anomalies.
3.3 Least Recently Used (LRU) replacement algorithm
Least Recently Used (LRU) )The replacement algorithm selectsthe page that has not been visited for the longest time and eliminates it. It believes that the page that has not been visited in the past period of time may not be visited in the near future.
This algorithm sets avisit fieldfor each page to record the time that the pagehas elapsed since it was last visited, and selects the existing page when eliminating the page The one with the highest median value will be eliminated.
Visit page
1
2
3
4
1
2
5
1
2
3
4
5
Physical Block 1
1
1
1
4
4
4
5
##5
5
Physical Block 2
##2
2
2
1
1
1
##3
3
Physical Block 3
3
3
3
2
2
2
4
##Missing PageNo
√
√
√
√
√
##√
√
##√
√
# #Compare after increasing the number of physical blocks
Physical block 1*
1
1
1
1
##5
5
5
5
4
4
Physical Block 2*
2
2
2
##2
1
1
1
1
5
Physical Block 3*
3
3
##3
3
2
2
2
2
##Physical Block 4*
4
4
4
4
3
3
3
Missing Page No
√
√
√
√
##√
√
√
√
√
√
Displacement graph during LRU page replacement algorithm
Access page
7
0
1
2
0
3
0
4
2
3
0
3
2
1
2
0
1
7
0
1
Physical Block 1
7
7
7
2
2
4
##4
4
0
##1
##1
1
##Physical Block 2
0
0
0
0
0
0
3
3
##3
0
0
Physical Block 3
##1
1
3
3
2
2
2
2
2
7
##Missing Page No
√
√
√
√
##√
##√
√
√
√
##√
##√
##√
LRU has better performance, but requires hardware support for registers and stacks, and is more expensive.
LRU is an algorithm ofstack class. Theoretically, it can be proved that Belady exception is impossible to occur in stack algorithms. The FIFO algorithm is implemented based on a queue, not a stack algorithm.
3.4 Clock (CLOCK) replacement algorithm
The performance of the LRU algorithm is close to OPT, but it is difficult to implement and expensive; FIFO The algorithm is simple to implement, but its performance is poor. Therefore, operating system designers have tried many algorithms, trying to approach the performance of LRU with relatively small overhead. Such algorithms are all variants of the CLOCK algorithm.
The simple CLOCK algorithm associates an additional bit with each frame, called the usage bit. When a page is first loaded into main memory and subsequently accessed, the use bit is set to 1.
For the page replacement algorithm, the set ofcandidate framesused for replacement is treated as acircular buffer, and has a pointer associated with it. When a page is replaced, the pointer is set to point to the next frame in the buffer.
When it is time to replace a page, the operating system scans the buffer to find the first frame with a usage bit of 0. Whenever a frame with a usage bit of 1 is encountered, the operating system resets the bit to 0; if all frames have a usage bit of 1, the pointer completes a cycle in the buffer, clearing all usage bits. Set to 0 and stay at the original position, replacing the page in the frame. Because this algorithm checks the status of each page cyclically, it is called the CLOCK algorithm, also known as theNot Recently Used (NRU)algorithm.
The performance of the CLOCK algorithm is relatively close to LRU, and by increasing the number of bits used, the CLOCK algorithm can be made more efficient. Adding amodified bit modifiedto theused bit usedwill result in an improved CLOCK replacement algorithm.
Each frame is in one of the following four situations:
has not been accessed recently and has not been modified (u=0, m=0).
was recently accessed but not modified (u=1, m=0).
has not been accessed recently, but has been modified (u=0, m=1).
was recently accessed and modified (u=1, m=1).
The algorithm performs the following steps:
Start from the current position of the pointer and scan the frame buffer. During this scan, no modifications are made to the usage bits. The first frame encountered (u=0, m=0) is selected for replacement.
If step 1 fails, rescan and look for frames of (u=0, m=1). The first such frame encountered is selected for replacement. During this scan, for each skipped frame, its usage bit is set to 0.
If step 2 fails, the pointer will return to its original position and the used bits of all frames in the set will be 0. Repeat step 1, and if necessary, step 2. This will find frames for replacement.
The improved CLOCK algorithm is better than the simple CLOCK algorithm in thatprefers unchanged pageswhen replacing them. This saves time sincemodified pages must be written back tobefore they are replaced.
4. Page allocation strategy
4.1 Resident set size
For paging Virtual memory, in preparation for execution, does not need and cannot read all pages of a process into main memory, so the operating system must decide how many pages to read. In other words,how much main memory space is allocated to a specific process, this needs to consider the following points:
The smaller the amount of storage allocated to a process, The more processes that can reside in main memory at any one time, the more efficient use of processor time can be.
If a process has too fewpagesin main memory, thepage fault ratewill still be relatively high despite the locality principle. high.
Ifthere are too many pages, due to the principle of locality, allocating more main memory space to a specific process will not have a significant impact on the error rate of the process .
Based on these factors, modern operating systems usually adopt three strategies:
Fixed allocation local replacement: It Each process is allocated a certain number of physical blocks thatdoes not changethroughout the run. If a page fault occurs while the process is running, you can only select one page fromthe pages in the memory of the process and swap it out, and then load the required page. It is difficult to determine the number of physical blocks that should be allocated to each process when implementing this strategy: too few will cause frequent page faults, and too many will reduce CPU and other resource utilization.
Variable allocation global replacement: This is the easiest physical block allocation and replacement strategy to implement, allocating a certain number of physical blocks to each process in the system , the operating system itself also maintains a queue of free physical blocks. When a page fault occurs in a process, the system takes out a physical block from thefree physical block queue and assigns it to the process, and loads the page to be loaded into it.
Variable allocation local replacement: It allocates a certain number of physical blocks to each process. When a page fault occurs in a process, only the pages in the memory of the process are allowed to be removed. Select a page and swap it out, so that it will not affect the operation of other processes. If the processfrequently misses pageswhile the process is running, the systemwill allocatea number of physical blocks to the process until the page miss rate of the process reaches an appropriate level; conversely, if the processis runningIf the page fault rate is particularly low, you can appropriatelyreduce the number of physical blocks allocated
to the process.
4.2 Timing of loading the page
To ensure that the system transfers the page that is missing when the process is running into the memory At the right time, the following two paging strategies can be adopted:
Pre-pagingStrategy: According to the principle of locality, one paging strategy Several adjacent pages may be more efficient than loading one page at a time. But if most of the loaded pages have not been accessed, it is inefficient. Therefore, it is necessary to adopt a prediction-based pre-paging strategy to pre-load pages that are expected to be accessed in the near future into the memory. However, the current success rate of pre-adjusted pages is only about 50%. Therefore, this strategy is mainly used when the process is loaded for the first time, and the programmer indicates which pages should be loaded first.
Request pagingStrategy: Thepage that the process needs to access during operation is not in memory and a request is made, by The system loads the required pages into memory. Pages transferred by this strategy will definitely be accessed, and this strategy is relatively easy to implement, so this strategy is mostly used in current virtual memories. Its disadvantage is thatonly loads one page at a time. When there are many pages loaded in and out, it will consume too much I/O overhead.
4.3 Where to load the page
Request the
external storage in the paging systemis divided into two parts: thefile areaused to store files and theswap areaused to store swap pages .The swap area usually uses the continuous allocation method, while thefile area uses the discrete allocation method, so the disk I/O speed of theswap area is faster than that of the file area. quick. There are three situations in which pages can be transferred from:
The system has enough swap area space: You canall transfer from the swap areaRequired pages to improve paging speed. To this end, before the process runs, the files related to the process need to be copiedfrom the file areato the swap area.
The system lacks enough swap area space: Allfiles that will not be modifiedare directly copied from thefile areaTransfer in (no need to write back when swapping out). But for those parts that may be modified, they must be transferred to the swap area when swapping them out, and then transferred back from the swap area when needed later.
UNIX way: Files related to the process are placed in the file area, sopages that have not been run should be transferred from the file area. Pages that have been run before but are swapped out are placed in the swap area, soshould be transferred in from the swap area the next time they are loaded. If the shared page requested by the process is transferred into the memory by other processes, there is no need to transfer it from the swap area.
5. Page jitter (turbulence) and working set (resident set)
5.1 Page jitter (turbulence) )
One of the worst situations during the page replacement process is that the page just swapped out will be swapped out immediately, and the page just swapped in will be swapped out immediately. Main memory, this
frequent paging behavior is called thrashing, or thrashing. If a process spendspaging more time than execution time, then the process is thrashing. Frequent page fault interrupts (jitter) occur mainly because the number of pages frequently accessed by a process is higher than the number of available physical page frames. Virtual memory technology can keep more processes in memory to improve system efficiency. In the steady state, almost all of main memory is occupied by process blocks, and the processor and operating system have direct access to as many processes as possible. But if not managed properly, most of the processor's time will be spent swapping blocks, that is, requesting the operation of loading pages, rather than executing the instructions of the process, which will greatly reduce system efficiency.
5.2 Working set (resident set)
The working set (or resident set) refers to the set of pagesthat a process will access within acertain interval. Pages that are frequently used need to be in the working set, while pages that have not been used for a long time are discarded from the working set. In order to prevent system thrashing, you need to choose an appropriate working set size.
The principle of the working set model is to let the operating system track the working set of each process and allocate physical blocks to the process that are larger than its working set. If there are free physical blocks, you can transfer another process to the memory to increase the number of multi-programs. If the sum of all working sets increases to exceed the total number of available physical blocks, the operating system pauses a process, pages it out, and allocates its physical blocks to other processes to prevent thrashing.
Correctly choosing the size of the working set will have an important impact onmemory utilization and improving system throughput.
6. Summary
PagingManagement method andSegmentationmanagement method are similar in many places, such as in memory They are discontinuous and have address translation mechanisms to perform address mapping, etc. However, there are many differences between the two. Table 3-20 lists the comparison between paging management method and segmentation management method in various aspects.
##Paging
Section
Purpose
Page is the physical unit of information, and paging is a way to realizediscrete allocationto reduce the external fraction of memory and improve memory utilization. In other words, paging is only due to the needs ofsystem managementrather than the needs of users
is a logical unit of information, which contains a set of information whose meaning is relatively complete. The purpose of segmentation is to better meet the needs of
users
length
The
size of the page is fixed and determined by the system, the system divides the logical address into two parts, the page number and the page address, which is implemented by the machine hardware, so there can only be one size of page in the system
length of the segment It is not fixed, it depends on the program written by the user. Usually the compiler divides the address space## according to the nature of the information when compiling the stream program. #The job address space is one-dimensional, that is, a single linear address space. The programmer only needs to use a mnemonic to represent an address.
The job address space is two-dimensional. The programmer identifies an address. When, you need to give both the segment name and the address within the segment
Fragments
There are internal fragments, but there are no external fragments
With external fragmentation, no internal fragmentation
"Sharing" and "Dynamic Linking"Not easy to achieve
Easy to implement
Related recommendations: "
Linux Video Tutorial
"
The above is the detailed content of What does linux use to implement virtual memory?. For more information, please follow other related articles on the PHP Chinese website!
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn



































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



