


How to use Node to crawl data from web pages and write them into Excel files? The following article uses an example to explain how to use Node.js to crawl web page data and generate Excel files. I hope it will be helpful to everyone!

I believe that Pokémon is the childhood memory of many people born in the 90s. As a programmer, I have wanted to make a Pokémon game more than once, but before doing so, I should first Sort out how many Pokémon there are, their numbers, names, attributes and other information. In this issue, we will use Node.js to simply implement a crawling of Pokémon web data to convert these The data is generated into an Excel file until the interface is used to read Excel to access the data.
Since we are crawling data, let’s first find a webpage with Pokémon illustrated data, as shown below:
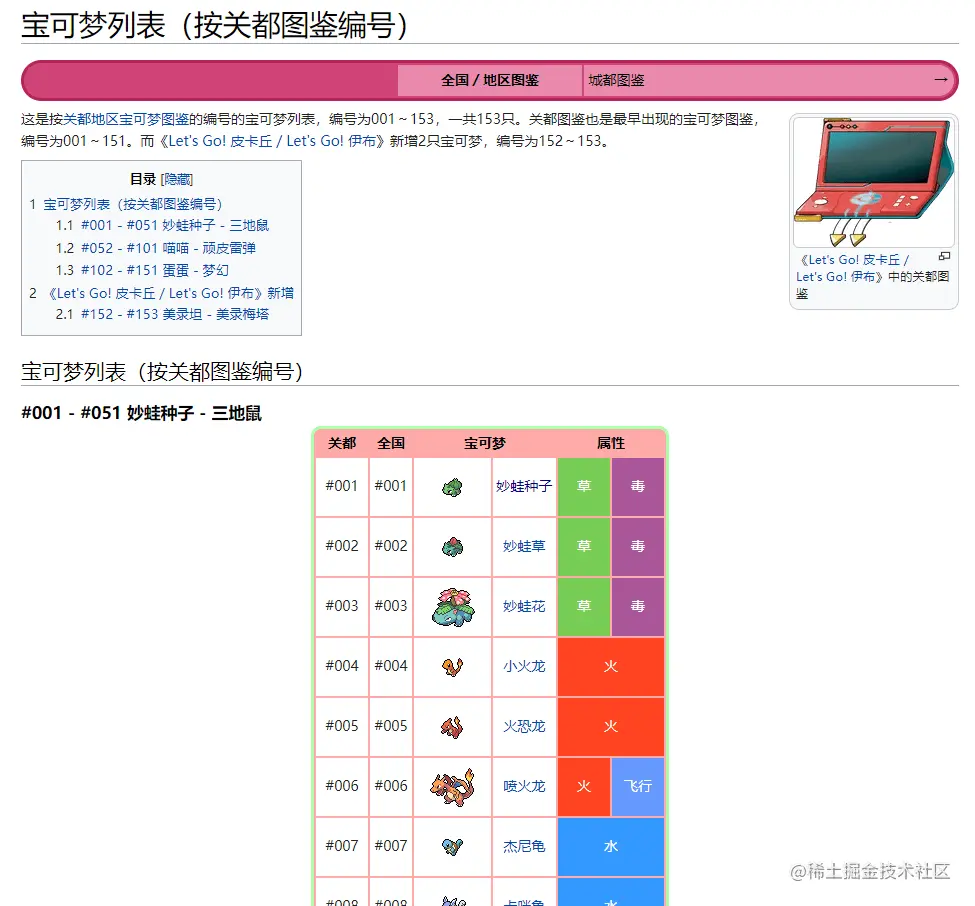
This website is written in PHP, and there is no separation between the front and back, so we will not read the interface to capture data. We use the crawler library to capture the content of the web page. elements to get the data. Let me explain in advance, the advantage of using the crawler library is that you can use jQuery to capture elements in the Node environment.
Installation:
yarn add crawler
Implementation:
const Crawler = require("crawler");
const fs = require("fs")
const { resolve } = require("path")
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
function getPokemon() {
let uri = "" // 宝可梦图鉴地址
let data = []
return new Promise((resolve, reject) => {
crawler.queue({
uri,
callback: (err, res, done) => {
if (err) reject(err);
let $ = res.$;
try {
let $tr = $(".roundy.eplist tr");
$tr.each((i, el) => {
let $td = $(el).find("td");
let _code = $td.eq(1).text().split("\n")[0]
let _name = $td.eq(3).text().split("\n")[0]
let _attr = $td.eq(4).text().split("\n")[0]
let _other = $td.eq(5).text().split("\n")[0]
_attr = _other.indexOf("属性") != -1 ? _attr : `${_attr}+${_other}`
if (_code) {
data.push([_code, _name, _attr])
}
})
done();
resolve(data)
} catch (err) {
done()
reject(err)
}
}
})
})
}When generating an instance, you also need to enable the jQuery mode, and then you can use $ matches. The business of the middle part of the above code is to capture the data required in elements and crawl web pages. It is used the same as jQuery API, so I won’t go into details here.
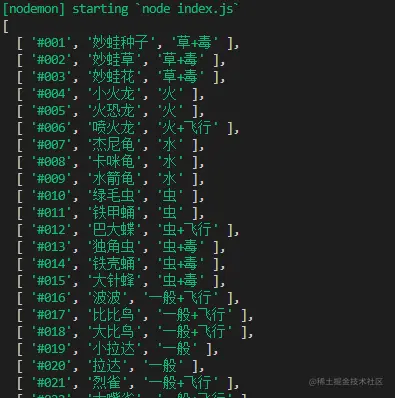
getPokemon().then(async data => {
console.log(data)
})Finally we can execute and print the passed data data to verify that the format has been crawled and there are no errors.
Now that we have crawled the data just now, next, we will use node -xlsx library to complete writing data and generating an Excel file.
First of all, let’s introduce that node-xlsx is a simple excel file parser and generator. The one built by TS relies on the SheetJS xlsx module to parse/build excel worksheets, so the two can be common in some parameter configurations.
Installation:
yarn add node-xlsx
Implementation:
const xlsx = require("node-xlsx")
getPokemon().then(async data => {
let title = ["编号", "宝可梦", "属性"]
let list = [{
name: "关都",
data: [
title,
...data
]
}];
const sheetOptions = { '!cols': [{ wch: 15 }, { wch: 20 }, { wch: 20 }] };
const buffer = await xlsx.build(list, { sheetOptions })
try {
await fs.writeFileSync(resolve(__dirname, "data/pokemon.xlsx"), buffer, "utf8")
} catch (error) { }
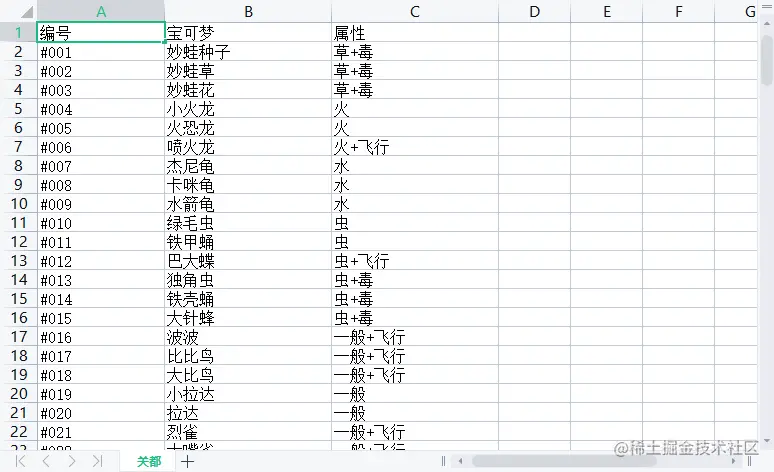
})The name is the column name in the Excel file, and the data If the type is an array, an array must also be passed in to form a two-dimensional array, which means that the incoming text is sorted starting from the ABCDE.... column. At the same time, you can set the column width through !cols. The first object wch:10 means that the width of the first column is 10 characters. There are many parameters that can be set. You can refer to xlsx library to learn these configuration items.
Finally, we generate buffer data through the xlsx.build method, and finally use fs.writeFileSync to write or create an Excel file , for the convenience of viewing, I have stored it in a folder named data. At this time, we will find an additional file called pokemon.xlsx in the data folder. Open it and the data will be the same. Write the data like this This step of entering Excel is complete.
Reading Excel is actually very easy and you don’t even need to write fs to read. Use the xlsx.parse method to pass in the file address to read it directly.
xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
Of course, in order to verify the accuracy, we directly write an interface to see if we can access the data. For convenience, I directly use the express framework to accomplish this.
Let’s install it first:
yarn add express
Then, create the express service. I use 3000 for the port number here, so just write a GET Just request to send the data read from the Excel file.
const express = require("express")
const app = express();
const listenPort = 3000;
app.get("/pokemon",(req,res)=>{
let data = xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
res.send(data)
})
app.listen(listenPort, () => {
console.log(`Server running at http://localhost:${listenPort}/`)
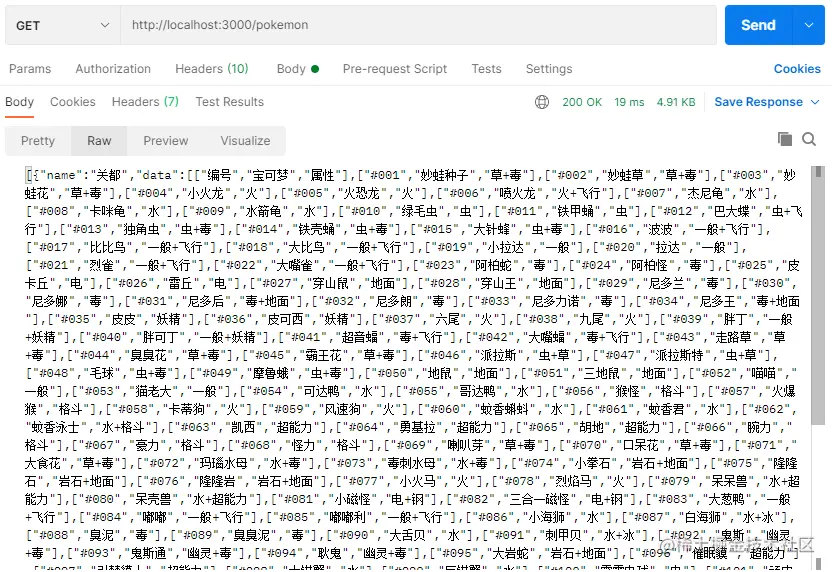
})Finally, I use the postman access interface here, and you can clearly see that all Pokémon data we have received from crawling to storing in the table.
As you can see, this article uses Pokémon as an example to learn how to use Node.js to crawl data from web pages and how to write data to Excel files. , and how to read data from Excel files. In fact, it is not difficult to implement, but sometimes it is quite practical. If you are worried about forgetting, you can save it~
More node related For knowledge, please visit: nodejs tutorial!
The above is the detailed content of Node crawl data example: grab the Pokémon illustrated book and generate an Excel file. For more information, please follow other related articles on the PHP Chinese website!
 Tutorial on buying and selling Bitcoin on Huobi.com
Tutorial on buying and selling Bitcoin on Huobi.com
 How to turn on vt
How to turn on vt
 How to convert excel to vcf
How to convert excel to vcf
 How to check dead links on your website
How to check dead links on your website
 How to change file type in win7
How to change file type in win7
 What is the difference between JD International self-operated and JD self-operated
What is the difference between JD International self-operated and JD self-operated
 The role of linux terminal commands
The role of linux terminal commands
 How to write triangle in css
How to write triangle in css




![Node.js complete introductory tutorial [es6+npm+express+webpack+promise]](https://img.php.cn/upload/course/000/000/068/6242b4c8f1a39624.png)






![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



