


Optimization methods of paging queries: 1. Subquery optimization, performance improvement can be achieved by rewriting paging SQL statements into subqueries. 2. ID limitation optimization, you can calculate the range of queried IDs based on the number of queried pages and the number of queried records, and then query based on the "id between and" statement. 3. Optimize based on index reordering, find relevant data addresses through the index, and avoid full table scans. 4. For delayed association optimization, you can use JOIN to first complete the paging operation on the index column, and then return to the table to obtain the required columns.

The operating environment of this tutorial: windows7 system, mysql8 version, Dell G3 computer.
The efficiency of paging query is particularly important when the amount of data is large, affecting front-end response and user experience.
Optimization method of paging query
1. Use subquery optimization
This method first locates the id at the offset position and then queries later. This method is suitable for the case where the id is increasing.
Subquery optimization principle: https://www.jianshu.com/p/0768ebc4e28d
select * from sbtest1 where k=504878 limit 100000,5;Query process:
First, the index leaf node data will be queried, and then all required field values will be queried on the clustered index according to the primary key value on the leaf node. As shown on the left side of the figure below, you need to query the index node 100005 times, query the clustered index data 100005 times, and finally filter the results out of the first 100000 items and remove the last 5 items. MySQL spends a lot of random I/O querying data in the clustered index, and the data queried by 100,000 random I/O will not appear in the result set.
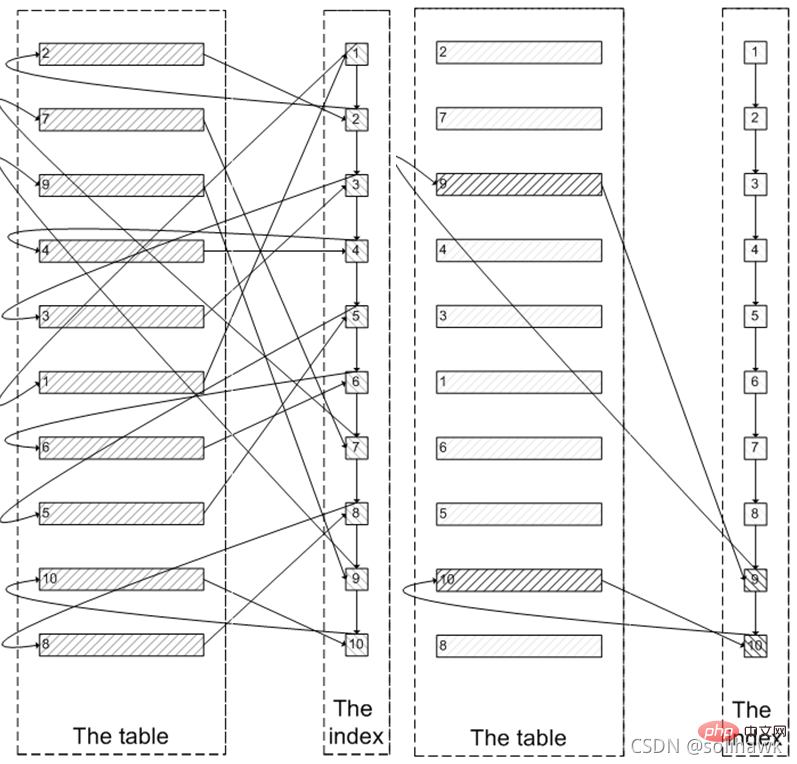
Since the index is used at the beginning, why not first query along the index leaf nodes to the last 5 nodes needed, and then query the actual data in the clustered index . This only requires 5 random I/Os, similar to the process on the right side of the picture above. This is subquery optimization. This method first locates the id at the offset position, and then queries later. This method is suitable for the case where the id is increasing. As shown below:
mysql> select * from sbtest1 where k=5020952 limit 50,1; mysql> select id from sbtest1 where k=5020952 limit 50,1; mysql> select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10; mysql> select * from sbtest1 where k=5020952 limit 50,10;
In subquery optimization, whether k in the predicate has an index has a great impact on query efficiency. The above statement does not use the index and a full table scan takes 24.2s. After removing the index, it only takes 24.2s. It takes 0.67s.
mysql> explain select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10; +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ | 1 | PRIMARY | sbtest1 | NULL | index_merge | PRIMARY,c1 | c1,PRIMARY | 8,4 | NULL | 19 | 100.00 | Using intersect(c1,PRIMARY); Using where | | 2 | SUBQUERY | sbtest1 | NULL | ref | c1 | c1 | 4 | const | 88 | 100.00 | Using index | +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ 2 rows in set, 1 warning (0.11 sec)
But this optimization method also has limitations:
This way of writing requires that the primary key ID must be consecutive
Where clause is not allowed to add other conditions
2. Use id limit optimization
This method assumes that the ids of the data table are continuous Incrementally, we can calculate the range of the queried ID based on the number of pages queried and the number of records queried, and can be queried using id between and.
Assuming that the id of the table in the database is continuously increasing, the range of the queried id can be calculated based on the number of pages queried and the number of records queried, and then queried based on the id between and statement. The range of id can be calculated through the paging formula. For example, if the current page size is m and the current page number is no1, then the maximum value of the page is max=(no1 1)m-1, and the minimum value is min=no1m, the SQL statement can be expressed as id between min and max.
select * from sbtest1 where id between 1000000 and 1000100 limit 100;
This query method can greatly optimize the query speed and can basically be completed within tens of milliseconds. The limitation is that you need to know the id clearly, but generally in the business table of paging query, the basic id field will be added, which brings a lot of convenience to paging query. There is another way to write the above SQL:
select * from sbtest1 where id >= 1000001 limit 100;
You can see the difference in execution time:
mysql> show profiles; +----------+------------+--------------------------------------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------------------------------------------------------------------+ | 6 | 0.00085500 | select * from sbtest1 where id between 1000000 and 1000100 limit 100 | | 7 | 0.12927975 | select * from sbtest1 where id >= 1000001 limit 100 | +----------+------------+--------------------------------------------------------------------------------------------------------------+
You can also use the in method to query, which is often used in multiple tables When querying, use the id set of other table queries to query:
select * from sbtest1 where id in (select id from sbtest2 where k=504878) limit 100;
When using in query, please note that some mysql versions do not support the use of limit in the in clause.
3. Optimization based on index reordering
Reordering based on index uses the optimization algorithm in the index query to find the relevant data address through the index to avoid Full table scan, which saves a lot of time. In addition, Mysql also has related index cache, and it will be better to use the cache when concurrency is high. You can use the following statement in MySQL:
SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M
This method is suitable for situations where the amount of data is large (tens of thousands of tuples). It is best that the column object after ORDER BY is the primary key or unique index, so that ORDER BY Operations can be eliminated using indexes but the result set is stable. For example, the following two statements:
mysql> show profiles; +----------+------------+--------------------------------------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------------------------------------------------------------------+ | 8 | 3.30585150 | select * from sbtest1 limit 1000000,10 | | 9 | 1.03224725 | select * from sbtest1 order by id limit 1000000,10 | +----------+------------+--------------------------------------------------------------------------------------------------------------+
After using the order by statement for the index field id, the performance has been significantly improved.
4. Use delayed association to optimize
Similar to the above subquery, we can use JOIN to complete the paging operation on the index column first, and then return Get the required columns from the table.
select a.* from t5 a inner join (select id from t5 order by text limit 1000000, 10) b on a.id=b.id;

从实验中可以得出,在采用JOIN改写后,上面的两个局限性都已经解除了,而且SQL的执行效率也没有损失。
5、记录上次查询结束的位置
和上面使用的方法都不同,记录上次结束位置优化思路是使用某种变量记录上一次数据的位置,下次分页时直接从这个变量的位置开始扫描,从而避免MySQL扫描大量的数据再抛弃的操作。
select * from t5 where id>=1000000 limit 10;

6、使用临时表优化
使用临时存储的表来记录分页的id然后进行in查询
这种方式已经不属于查询优化,这儿附带提一下。
对于使用 id 限定优化中的问题,需要 id 是连续递增的,但是在一些场景下,比如使用历史表的时候,或者出现过数据缺失问题时,可以考虑使用临时存储的表来记录分页的id,使用分页的id来进行 in 查询。这样能够极大的提高传统的分页查询速度,尤其是数据量上千万的时候。
【相关推荐:mysql视频教程】
The above is the detailed content of How to optimize mysql paging query. For more information, please follow other related articles on the PHP Chinese website!































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



