

This article will share with you some Redis high-frequency interview questions. It has certain reference value. Friends in need can refer to it. I hope it will be helpful to everyone.

Redis (Remote Dictionary Server) is an open source ( BSD licensed) high-performance non-relational (NoSQL) key-value database.
Redis can store mappings between keys and five different types of values. The key type can only be string, and the value supports five data types: string, list, set, hash table, and ordered set.
Different from traditional databases, Redis data is stored in memory, so the read and write speed is very fast. Therefore, redis is widely used in the cache direction and can handle more than 100,000 read and write operations per second. The fastest Key-Value DB known to perform. In addition, Redis is often used for distributed locks. In addition, Redis supports transactions, persistence, LUA scripts, LRU driven events, and various cluster solutions.
Advantages
Excellent reading and writing performance, Redis can read The speed of writing is 110000 times/s, and the writing speed is 81000 times/s.
Supports data persistence and supports two persistence methods: AOF and RDB.
Supports transactions. All operations of Redis are atomic. At the same time, Redis also supports atomic execution after merging several operations.
Rich data structures, in addition to supporting string type value, it also supports hash, set, zset, list and other data structures.
Supports master-slave replication, the host will automatically synchronize data to the slave, and read and write can be separated.
Disadvantages
The database capacity is limited by physical memory and cannot be used for high-performance reading and writing of massive data. Therefore, the scenarios suitable for Redis are mainly limited to small amounts of data. High-performance operations and calculations.
Redis does not have automatic fault tolerance and recovery functions. The downtime of the host and slave machines will cause some front-end read and write requests to fail. You need to wait for the machine to restart or manually switch the front-end IP to recover.
The host machine is down. Some data could not be synchronized to the slave machine in time before the machine went down. After switching IP, data inconsistency will be introduced, which reduces the availability of the system.
Redis is difficult to support online expansion. When the cluster capacity reaches the upper limit, online expansion will become very complicated. In order to avoid this problem, operation and maintenance personnel must ensure that there is enough space when the system goes online, which causes a great waste of resources.
Mainly from the two points of "high performance" and "high concurrency" Let’s look at this issue.
High performance:
If the user accesses some data in the database for the first time. This process will be slower because it is read from the hard disk. Store the data accessed by the user in the cache, so that the next time the data is accessed, it can be obtained directly from the cache. Operating the cache is to directly operate the memory, so the speed is quite fast. If the corresponding data in the database changes, just change the corresponding data in the cache synchronously!
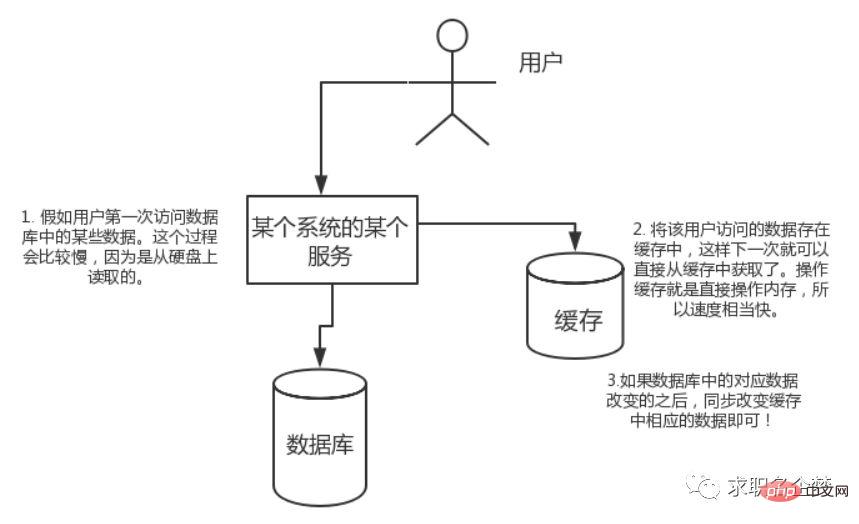
High concurrency:
The requests that the direct operation cache can withstand are far greater than the direct access to the database, so we can consider Transfer part of the data in the database to the cache, so that some of the user's requests will go directly to the cache without going through the database.
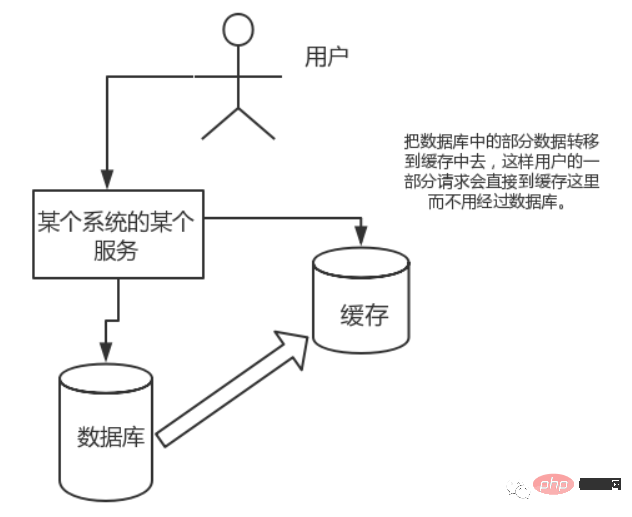
The cache is divided into local cache and distributed cache cache. Taking Java as an example, local caching is implemented using the built-in map or guava. The main feature is that it is lightweight and fast. The life cycle ends with the destruction of the jvm, and in the case of multiple instances, each instance Each cache needs to be saved, and the cache is not consistent.
Using redis or memcached is called distributed cache. In the case of multiple instances, each instance shares a cache of data, and the cache is consistent. The disadvantage is that the redis or memcached service needs to be kept highly available, and the entire program architecture is relatively complex.
1. It is completely based on memory. Most requests are pure memory operations, which are very fast. The data is stored in memory, similar to HashMap. The advantage of HashMap is that the time complexity of search and operation is O(1);
#2. The data structure is simple and the data operation is also simple. In Redis The data structure is specially designed;
3. Use single thread to avoid unnecessary context switching and competition conditions. There is no need to consider switching caused by multi-process or multi-thread to consume the CPU. For various lock issues, there is no locking and releasing operations, and there is no performance consumption caused by possible deadlocks;
4. Use multi-channel I/O multiplexing model, non-blocking IO;
5. Use different underlying models, the underlying implementation methods and the application protocols for communication with the client are different. , Redis directly built its own VM mechanism, because if the general system calls system functions, it will waste a certain amount of time to move and request;
Redis mainly has 5 data types, including String, List, Set, Zset, and Hash, which meet most usage requirements
Summary 1
1. Counter
You can perform increment and decrement operations on String to realize the counter function. Redis, an in-memory database, has very high read and write performance and is very suitable for storing counts of frequent reads and writes.
2. Cache
Put hot data into memory, set the maximum memory usage and elimination strategy to ensure the cache hit rate.
3. Session cache
You can use Redis to uniformly store session information of multiple application servers. When the application server no longer stores the user's session information, it no longer has state. A user can request any application server, making it easier to achieve high availability and scalability.
4. Full Page Cache (FPC)
In addition to the basic session token, Redis also provides a very simple FPC platform. Taking Magento as an example, Magento provides a plugin to use Redis as a full-page cache backend. In addition, for WordPress users, Pantheon has a very good plug-in wp-redis, which can help you load the pages you have browsed as quickly as possible.
5. Lookup table
For example, DNS records are very suitable for storage using Redis. The lookup table is similar to the cache and also takes advantage of the fast lookup feature of Redis. But the contents of the lookup table cannot be invalidated, while the contents of the cache can be invalidated, because the cache does not serve as a reliable source of data.
6. Message queue (publish/subscribe function)
List is a doubly linked list that can write and read messages through lpush and rpop. However, it is best to use messaging middleware such as Kafka and RabbitMQ.
7. Distributed lock implementation
In a distributed scenario, locks in a stand-alone environment cannot be used to synchronize processes on multiple nodes. You can use the SETNX command that comes with Redis to implement distributed locks. In addition, you can also use the officially provided RedLock distributed lock implementation.
8. Others
Set can implement operations such as intersection and union, thereby realizing functions such as mutual friends. ZSet can implement ordered operations to achieve functions such as rankings.
Summary 2
Compared with other caches, Redis has a very big advantage, that is, it supports multiple data types.
Data type description string string, the simplest k-v storage hashhash format, value is field and value, suitable for scenarios such as ID-Detail. list is a simple list, a sequential list, supports inserting data at the first or last position, unordered list, fast search speed, suitable for intersection, union, and difference processing sorted set ordered set
In fact, through the above data Based on the characteristics of the type, you can basically think of suitable application scenarios.
string——Suitable for the simplest k-v storage, similar to memcached storage structure, SMS verification code, configuration information, etc., use this type to store.
hash- Generally, the key is an ID or a unique identifier, and the value corresponds to the details. Such as product details, personal information details, news details, etc.
list——Because list is ordered, it is more suitable for storing some ordered and relatively fixed data. Such as province and city table, dictionary table, etc. Because the list is ordered, it is suitable to be sorted according to the writing time, such as the latest hot news, message queue, etc.
set——It can be simply understood as an ID-List model, such as which friends a person has on Weibo. The best thing about set is that it can provide intersection between two sets. , union and difference operations. For example: Find common friends between two people, etc.
Sorted Set——is an enhanced version of set, adding a score parameter, which will automatically sort according to the score value. It is more suitable for data such as top 10 that is not sorted according to the insertion time.
As mentioned above, although Redis is not as complex a data structure as a relational database, it can also be suitable for many scenarios, including more than general cache data structures. Understanding the business scenarios suitable for each data structure will not only help improve development efficiency, but also effectively utilize the performance of Redis.
Persistence is to write the memory data to the disk to prevent the memory data from being lost if the service goes down.
Redis provides two persistence mechanisms, RDB (default) and AOF mechanism;
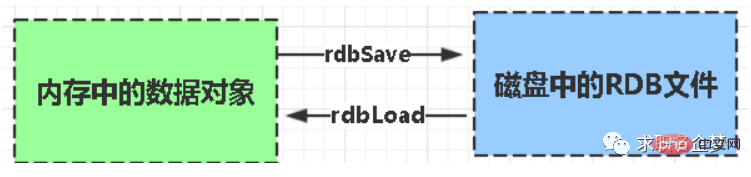
RDB: It is the abbreviation snapshot of Redis DataBase
RDB It is the default persistence method of Redis. The memory data is saved to the hard disk in the form of a snapshot according to a certain period of time, and the corresponding data file generated is dump.rdb. The snapshot period is defined through the save parameter in the configuration file.
Advantages:
1. There is only one file dump.rdb, which is convenient for persistence.
2. Good disaster tolerance, a file can be saved to a safe disk.
3. To maximize performance, fork the child process to complete the write operation and allow the main process to continue processing commands, so IO is maximized. Use a separate sub-process for persistence, and the main process will not perform any IO operations, ensuring the high performance of redis.
4. When the data set is large, the startup efficiency is higher than AOF.
Disadvantages:
1. Low data security. RDB is persisted at intervals. If redis fails between persistence, data loss will occur. Therefore, this method is more suitable when the data requirements are not strict)
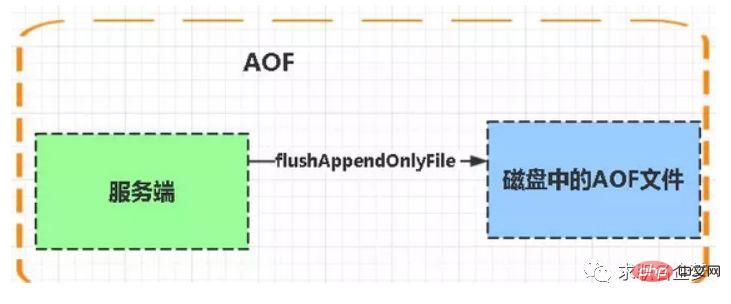
2. AOF (Append-only file) persistence method: refers to all command line records being completely persistently stored in the format of the redis command request protocol ) is saved as an aof file.
AOF persistence (i.e. Append Only File persistence) records each write command executed by Redis to a separate In the log file, when Redis is restarted, the data in the persistent log file will be restored.
When both methods are enabled at the same time, data recovery Redis will give priority to AOF recovery.
Advantages:
1. Data security, aof persistence can be configured with appendfsync attribute, always, every time a command operation is performed Just record it once in the aof file.
2. Write files through append mode. Even if the server goes down in the middle, you can use the redis-check-aof tool to solve the data consistency problem.
3. Rewrite mode of AOF mechanism. Before the AOF file is rewritten (commands will be merged and rewritten when the file is too large), you can delete some of the commands (such as flushall by mistake)
Disadvantages:
1. AOF files are larger than RDB files, and the recovery speed is slow.
2. When the data set is large, the startup efficiency is lower than rdb.
What are the advantages and disadvantages?
AOF files are updated more frequently than RDB, priority is given to using AOF to restore data
AOF is more secure and larger than RDB
RDB performance is better than AOF
If both are configured, AOF is loaded first
Generally speaking, if you want to achieve data security comparable to PostgreSQL, you should use both persistence functions at the same time. In this case, when Redis is restarted, the AOF file will be loaded first to restore the original data, because under normal circumstances, the data set saved by the AOF file is more complete than the data set saved by the RDB file.
If you care deeply about your data, but can still afford data loss within a few minutes, then you can just use RDB persistence.
Many users only use AOF persistence, but this method is not recommended because regularly generating RDB snapshots is very convenient for database backup, and RDB data set recovery is faster than AOF recovery. The speed is faster. In addition, using RDB can also avoid bugs in AOF programs.
If you only want your data to exist when the server is running, you can also not use any persistence method.
If Redis is used as a cache, use consistent hashing to achieve dynamic expansion and contraction.
If Redis is used as a persistent storage, a fixed keys-to-nodes mapping relationship must be used, and the number of nodes cannot be changed once determined. Otherwise (that is, when Redis nodes need to change dynamically), a system that can rebalance data at runtime must be used, and currently only Redis cluster can do this.
We all know that Redis is a key-value database, and we can set the expiration time of the keys cached in Redis. . The expiration policy of Redis refers to how Redis handles it when the cached key in Redis expires.
Expiration strategies usually have the following three types:
Timed expiration: Each key that sets the expiration time needs to create a timer. When the expiration time expires, will be cleared immediately. This strategy can immediately clear expired data and is very memory-friendly; however, it will occupy a large amount of CPU resources to process expired data, thus affecting the cache response time and throughput.
Lazy expiration: Only when a key is accessed, it will be judged whether the key has expired, and it will be cleared when it expires. This strategy can save CPU resources to the maximum extent, but it is very unfriendly to memory. In extreme cases, a large number of expired keys may not be accessed again, thus not being cleared and occupying a large amount of memory.
Periodic expiration: Every certain period of time, a certain number of keys in the expires dictionary of a certain number of databases will be scanned, and the expired keys will be cleared. This strategy is a compromise between the first two. By adjusting the time interval of scheduled scans and the limited time consumption of each scan, the optimal balance between CPU and memory resources can be achieved under different circumstances.
(The expires dictionary will save the expiration time data of all keys with expiration time set, where key is a pointer to a key in the key space, and value is the UNIX timestamp representation of the key with millisecond precision. The expiration time. The key space refers to all the keys saved in the Redis cluster.)
Redis uses both lazy expiration and periodic expiration strategies.
EXPIRE and PERSIST commands.
In addition to the cache invalidation policy that comes with the cache server In addition (Redis has 6 strategies to choose from by default), we can also customize cache elimination according to specific business needs. There are two common strategies:
1. Scheduled cache elimination Clean up the expired cache;
2. When a user makes a request, determine whether the cache used by the request has expired. If it expires, go to the underlying system to obtain new data and update the cache.
Both have their own advantages and disadvantages. The disadvantage of the first one is that it is more troublesome to maintain a large number of cached keys. The disadvantage of the second one is that every time a user requests it, the cache must be judged to be invalid, and the logic Relatively complicated! Which solution to use specifically can be weighed based on your own application scenarios.
When the size of the redis memory data set increases to a certain size, the data elimination strategy will be implemented.
The memory elimination strategy of Redis refers to how to solve the problem when Redis’s memory for caching is insufficient. Process data that requires new writing and requires additional space to be requested.
1. Global key space selective removal
noeviction: When the memory is not enough to accommodate newly written data, New write operations will report an error.
allkeys-lru: When the memory is insufficient to accommodate newly written data, in the key space, remove the least recently used key. (This is the most commonly used)
allkeys-random: When the memory is not enough to accommodate newly written data, a key is randomly removed from the key space.
2. Selective removal of key space with expiration time set
volatile-lru: When the memory is not enough to accommodate newly written data , in the key space with an expiration time set, remove the least recently used key.
volatile-random: When the memory is insufficient to accommodate newly written data, a key is randomly removed from the key space with an expiration time set.
volatile-ttl: When the memory is insufficient to accommodate newly written data, in the key space with an expiration time set, keys with earlier expiration times will be removed first.
Summary
The selection of Redis’s memory elimination strategy will not affect the processing of expired keys. The memory elimination policy is used to handle data that requires additional space when memory is insufficient; the expiration policy is used to handle expired cached data.
Memory.
If the set upper limit is reached, the Redis write command will return an error message (but the read command can still return normally.) Or you can configure the memory elimination mechanism when Redis reaches the upper memory limit. Old content will be flushed.
You can make good use of collection type data such as Hash, list, sorted set, set, etc., because usually many small Key-Values can be stored together in a more compact way. Use hashes as much as possible. Hash tables (meaning that the number stored in a hash table is small) use very small memory, so you should abstract your data model into a hash table as much as possible. For example, if there is a user object in your web system, do not set a separate key for the user's name, surname, email, and password. Instead, store all the user's information in a hash table.
Redis developed a network event processor based on the Reactor model. This processor is called a file event handler (file event handler) . Its structure is composed of 4 parts: multiple sockets, IO multiplexer, file event dispatcher, and event processor. Because the consumption of the file event dispatcher queue is single-threaded, Redis is called a single-threaded model.
1. The file event handler uses I/O multiplexing (multiplexing) program to monitor multiple sockets at the same time, and configure the socket according to the task currently performed by the socket. Associate different event handlers.
2. When the monitored socket is ready to perform operations such as connection response (accept), read (read), write (write), close (close), etc., the file corresponding to the operation Events will be generated, and the file event handler will call the event handler previously associated with the socket to handle these events.
Although the file event processor runs in a single-threaded manner, by using an I/O multiplexer to listen to multiple sockets, the file event processor not only implements a high-performance network communication model, It can also be well connected with other modules in the redis server that also run in a single-threaded manner, which maintains the simplicity of the single-threaded design within Redis.
A transaction is a single isolated operation: all commands in the transaction are serialized and executed in order. During the execution of the transaction, it will not be interrupted by command requests sent by other clients.
A transaction is an atomic operation: either all commands in the transaction are executed, or none of them are executed.
The concept of Redis transaction
The essence of Redis transaction is a collection of commands such as MULTI, EXEC, and WATCH. Transactions support executing multiple commands at one time, and all commands in a transaction will be serialized. During the transaction execution process, the commands in the queue will be executed serially in order, and command requests submitted by other clients will not be inserted into the transaction execution command sequence.
To summarize: a redis transaction is a one-time, sequential, and exclusive execution of a series of commands in a queue.
Three stages of Redis transaction
1. Transaction starts MULTI
2. Command enqueue
3. Transaction execution EXEC
During the transaction execution process, if the server receives a request other than EXEC, DISCARD, WATCH, and MULTI, it will put the request in the queue
Redis transaction related commands
The Redis transaction function is implemented through the four primitives MULTI, EXEC, DISCARD and WATCH
Redis will All commands in a transaction are serialized and then executed in order.
1,redis does not support rollback, "Redis does not rollback when a transaction fails, but continues to execute the remaining commands", so the internals of Redis can remain simple and fast.
2,If an error occurs in a command in a transaction, then all commands will not be executed;
3,If an error occurs in a transaction If an error occurs, the correct command will be executed.
The WATCH command is an optimistic lock that provides check-and-set (CAS) behavior for Redis transactions. One or more keys can be monitored. Once one of the keys is modified (or deleted), subsequent transactions will not be executed, and monitoring continues until the EXEC command.
The MULTI command is used to start a transaction and it always returns OK. After MULTI is executed, the client can continue to send any number of commands to the server. These commands will not be executed immediately, but will be placed in a queue. When the EXEC command is called, all commands in the queue will be executed.
EXEC: Execute commands within all transaction blocks. Returns the return values of all commands within the transaction block, arranged in the order of command execution. When the operation is interrupted, the empty value nil is returned.
By calling DISCARD, the client can clear the transaction queue and give up executing the transaction, and the client will exit from the transaction state.
The UNWATCH command can cancel watch’s monitoring of all keys.
Transaction Management (ACID) Overview
Atomicity
Atomicity means that a transaction is an indivisible unit of work, and operations in a transaction either all occur or none occur.
Consistency
The integrity of the data before and after the transaction must be consistent.
Isolation
When multiple transactions are executed concurrently, the execution of one transaction should not affect the execution of other transactions.
Durability (Durability)
Durability means that once a transaction is committed, its changes to the data in the database are permanent , then even if the database fails, it should not have any impact on it.
Redis transactions always have ACID consistency and isolation, and other features are not supported. Transactions are also durable when the server is running in AOF persistence mode and the value of the appendfsync option is always.
Redis is a single-process program, and it guarantees that the transaction will not be interrupted when executing the transaction, and the transaction can run until all transactions are executed. to the commands in the queue. Therefore, Redis transactions are always isolated.
In Redis, a single command is executed atomically, but transactions are not guaranteed. Atomic and no rollback. If any command in the transaction fails to execute, the remaining commands will still be executed.
Based on Lua script, Redis can ensure that the commands in the script are executed once and in order It does not provide rollback for transaction running errors. If some commands run incorrectly during execution, the remaining commands will continue to run.
Based on the intermediate mark variable, another mark variable is used to identify whether the transaction is completed. When reading data, the mark variable is first read to determine whether the transaction is completed. But this will require additional code to be implemented, which is more cumbersome.
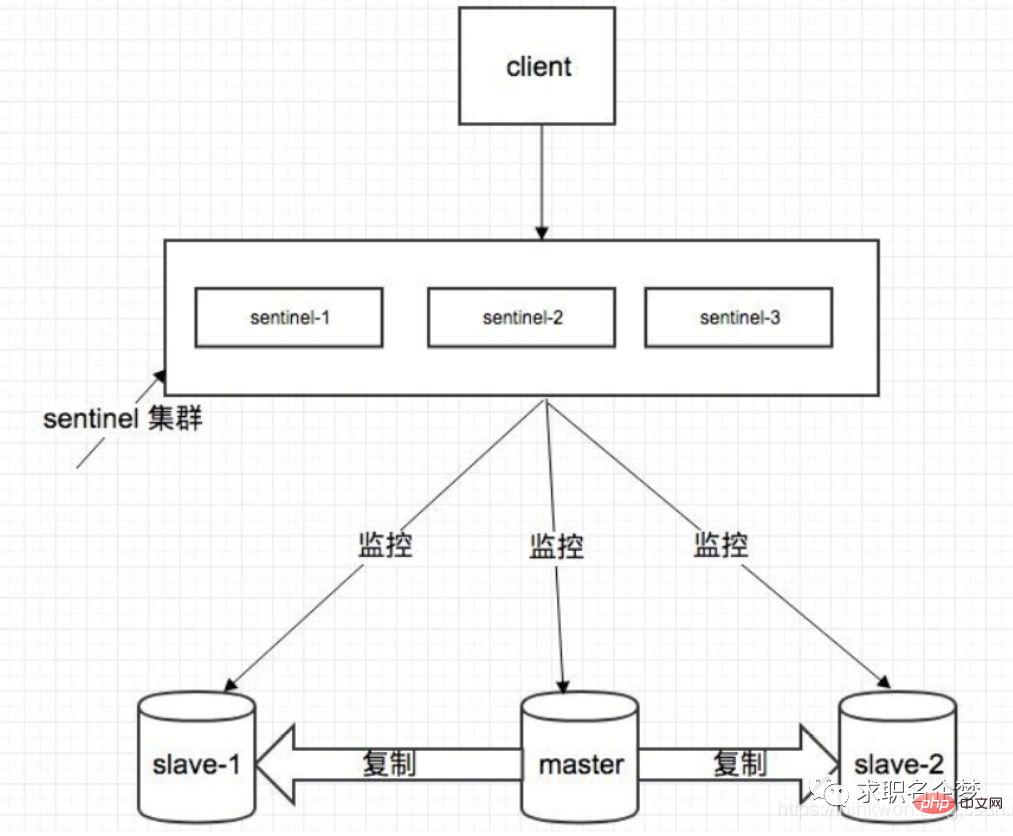
##Introduction to Sentinel
Cluster Monitoring: Responsible for monitoring whether the redis master and slave processes are working properly.
Message Notification: If a redis instance fails, Sentinel is responsible for sending messages as alarm notifications to the administrator.
Failover: If the master node hangs, it will automatically be transferred to the slave node.
Configuration Center: If failover occurs, notify the client of the new master address.
Sentinels are used to achieve high availability of redis clusters. They are also distributed and run as a sentinel cluster to work together.
Core knowledge of sentry
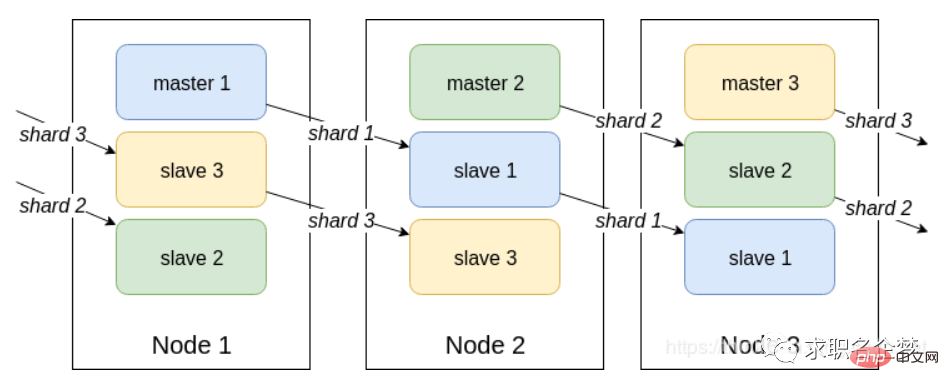
Introduction
Program description
gossipprotocol, which is used for efficient data exchange between nodes and takes up less network bandwidth and processing time.
Internal communication mechanism between nodes
Distributed addressing algorithm
Advantages
Disadvantages
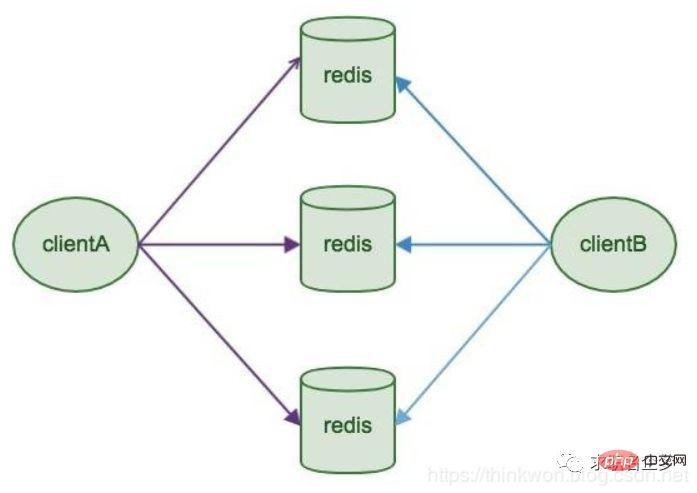
Introduction
Redis Sharding is a multi-Redis instance cluster method commonly used in the industry before Redis Cluster came out. The main idea is to use a hash algorithm to hash the key of Redis data. Through the hash function, a specific key will be mapped to a specific Redis node. Java redis client drives jedis and supports Redis Sharding function, namely ShardedJedis and ShardedJedisPool combined with cache pool
Advantages
The advantage is that it is very simple, server-side Redis The instances are independent of each other and have no correlation with each other. Each Redis instance runs like a single server, which is very easy to linearly expand. The system is highly flexible
Disadvantages
1. Since sharding processing is placed on the client, further expansion of the scale will bring challenges to operation and maintenance.
2. Client-side sharding does not support dynamic addition and deletion of nodes. When the topology of the server's Redis instance group changes, each client needs to be updated and adjusted. Connections cannot be shared. When the application scale increases, resource waste control optimization
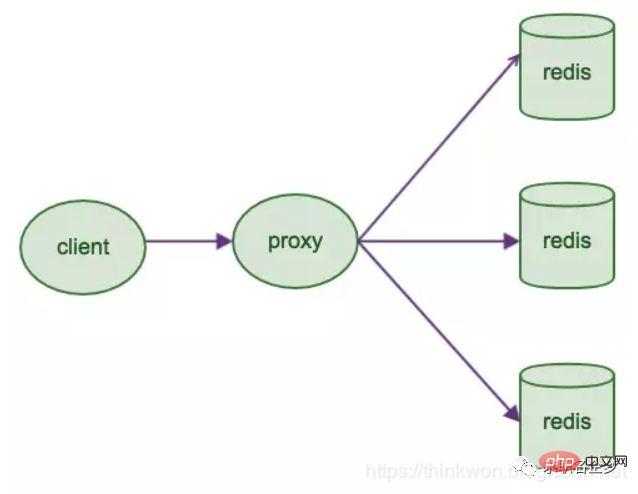
## Introduction
Features
Industry open source solution
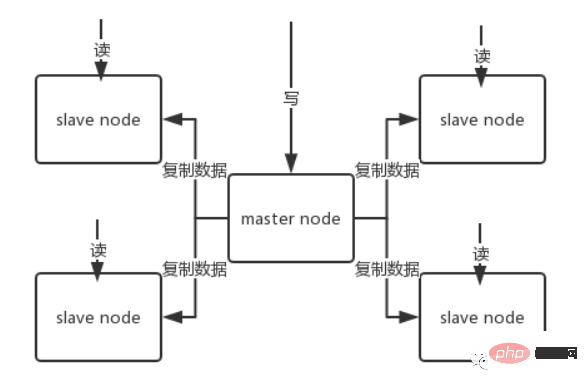 ##redis replication -> Master-slave architecture -> Read and write separation -> Horizontal expansion supports high read concurrency
##redis replication -> Master-slave architecture -> Read and write separation -> Horizontal expansion supports high read concurrency
1. Redis replicates data to the slave node asynchronously, but starting from redis2.8, the slave node will periodically confirm the amount of data it replicates each time;
2. A master node can be configured with multiple slave nodes;
3. The slave node can also connect to other slave nodes;
4. When the slave node replicates, It will not block the normal work of the master node;
5. When the slave node is replicating, it will not block its own query operations. It will use the old data set to provide services; but the replication is completed. Sometimes, you need to delete the old data set and load the new data set. At this time, external services will be suspended;
6. The slave node is mainly used for horizontal expansion and separation of reading and writing. The expanded slave node can improve Read throughput.
Note that if a master-slave architecture is adopted, it is recommended that the persistence of the master node must be turned on. It is not recommended to use the slave node as the data hot backup of the master node, because in that case, if you turn off the persistence of the master , the data may be empty when the master crashes and restarts, and then the data of the slave node may be lost as soon as it is replicated.
In addition, various backup plans for the master also need to be done. In case all the local files are lost, select an RDB from the backup to restore the master. This will ensure that there is data at startup. Even if the high availability mechanism explained later is adopted, the slave node can automatically take over the master node. But it is also possible that the master node has automatically restarted before sentinel detects the master failure, or it may cause all the slave node data above to be cleared.
When a slave node is started, it will send a PSYNC command to the master node.
If this is the first time that the slave node connects to the master node, a full resynchronization full copy will be triggered. At this time, the master will start a background thread and start generating an RDB snapshot file.
At the same time, all write commands newly received from the client will be cached in memory. After the RDB file is generated, the master will send the RDB to the slave. The slave will first write it to the local disk, and then load it from the local disk into the memory.
Then the master will send the write command cached in the memory. To the slave, the slave will also synchronize these data.
If there is a network failure between the slave node and the master node and the connection is disconnected, it will automatically reconnect. After the connection, the master node will only copy the missing data to the slave.
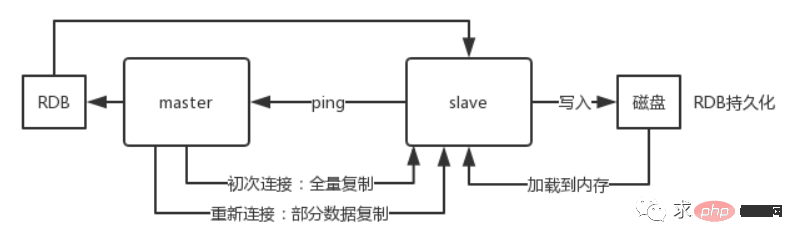
2. After the master database receives the SYNC command, it will start saving snapshots in the background (RDB persistence process) , and cache the write commands received during the period
3. When the snapshot is completed, the master Redis will send the snapshot file and all cached write commands to the slave Redis
4. The slave Redis After receiving it, the snapshot file will be loaded and the received cached command will be executed
5. Afterwards, the master Redis will send the command to the slave Redis whenever it receives a write command to ensure data consistency
Disadvantages
All replication and synchronization of slave node data are handled by the master node, which will cause too much pressure on the master node, so use the master-slave structure to solve it
What is the master-slave replication model of Redis cluster?
In order to make the cluster still available when some nodes fail or most nodes cannot communicate, the cluster uses a master-slave replication model, and each node will have N-1 replicas. Product
redis cluster, 10 machines, 5 machines are deployed with redis master instances, and the other 5 machines are deployed with redis slave instances. Each master instance has a slave instance, and 5 nodes are exposed to the outside world. Providing read and write services, the peak read and write qps of each node may reach 50,000 per second, and the maximum read and write request/s for 5 machines is 250,000.
What is the configuration of the machine? 32G memory, 8-core CPU, 1T disk, but the memory allocated to the redis process is 10g. In general online production environments, the memory of redis should not exceed 10g. If it exceeds 10g, there may be problems.
5 machines provide external reading and writing, with a total of 50g of memory.
Because each master instance has a slave instance, it is highly available. If any master instance goes down, it will automatically failover and the redis slave instance will automatically become the master instance and continue to provide read and write services. .
What data are you writing into the memory? What is the size of each piece of data? Product data, each piece of data is 10kb. 100 pieces of data is 1mb, and 100,000 pieces of data is 1g. There are 2 million pieces of product data resident in the memory, and the memory occupied is 20g, which is only less than 50% of the total memory. The current peak period is about 3,500 requests per second.
In fact, large companies will have an infrastructure team responsible for the operation and maintenance of the cache cluster.
The Redis cluster does not use consistent hashing, but introduces the concept of hash slots. The Redis cluster has 16384 hash slots. Each key passes CRC16 verification and 16384 is obtained. The module determines which slot to place, and each node in the cluster is responsible for a portion of the hash slot.
Redis does not guarantee strong consistency of data, which means that in practice, the cluster may lose write operations under certain conditions.
Asynchronous replication
16384
Redis cluster currently cannot select database, and defaults to database 0.
You can deploy multiple Redis instances on the same server and use them as different servers. At some point, one server is not enough anyway, so, If you want to use multiple CPUs, you can consider sharding.
Partitioning allows Redis to manage larger memory, and Redis will be able to use the memory of all machines. Without partitions, you can only use up to one machine's memory. Partitioning allows Redis's computing power to be doubled by simply adding computers, and Redis's network bandwidth will also increase exponentially with the addition of computers and network cards.
1. Client partitioning means that the client has decided which redis node the data will be stored in or read from. Most clients already implement client-side partitioning.
2. Agent partitioning means that the client sends the request to the agent, and then the agent decides which node to write or read data to. The agent decides which Redis instances to request based on partition rules, and then returns them to the client based on the Redis response results. A proxy implementation for redis and memcached is Twemproxy.
3. Query routing (Query routing) means that the client randomly requests any redis instance, and then Redis forwards the request to the correct Redis node. Redis Cluster implements a hybrid form of query routing, but instead of forwarding requests directly from one redis node to another redis node, it redirects directly to the correct redis node with the help of the client.
1. Operations involving multiple keys are usually not supported. For example, you cannot intersect two collections because they may be stored in different Redis instances (actually there is a way for this situation, but the intersection command cannot be used directly).
2. If multiple keys are operated at the same time, Redis transactions cannot be used.
3. The partitioning granularity is the key, so it is not possible to shard a dataset with a single huge key like a very big sorted set)
4. When using partitions, data processing will be very complicated. For example, for backup, you must collect RDB/AOF files from different Redis instances and hosts at the same time.
5. Dynamic expansion or contraction during partitioning may be very complicated. Redis cluster adds or deletes Redis nodes at runtime, which can achieve data rebalancing that is transparent to users to the greatest extent. However, some other client partitioning or proxy partitioning methods do not support this feature. However, there is a pre-sharding technology that can also solve this problem better.
Redis is a single-process single-thread mode, using queue mode to turn concurrent access into serial access, and multi-client There is no competition for connections to Redis. You can use the SETNX command in Redis to implement distributed locks.
If and only if key does not exist, set the value of key to value. If the given key already exists, SETNX does not take any action
SETNX is the abbreviation of "SET if Not eXists" (if it does not exist, then SET).
Return value: If the setting is successful, 1 is returned. Setup fails and returns 0.
The process and matters of using SETNX to complete the synchronization lock are as follows:
Use the SETNX command to obtain the lock. If 0 is returned (the key already exists, the lock already exists), the acquisition fails, otherwise the acquisition succeeds
In order to prevent exceptions in the program after acquiring the lock, causing other threads/processes to always return 0 when calling the SETNX command and enter a deadlock state, a "reasonable" expiration time needs to be set for the key
Release Lock, use the DEL command to delete the lock data
The so-called problem of concurrent competition for Key in Redis is multiple The system operates on a key at the same time, but the final execution order is different from the order we expect, which leads to different results!
Recommend a solution: distributed lock (both zookeeper and redis can implement distributed lock). (If there is no concurrent competition for Key in Redis, do not use distributed locks, which will affect performance)
Distributed locks based on zookeeper temporary ordered nodes. The general idea is: when each client locks a certain method, a unique instantaneous ordered node is generated in the directory of the specified node corresponding to the method on zookeeper. The way to determine whether to acquire a lock is very simple. You only need to determine the smallest sequence number among the ordered nodes. When the lock is released, just delete the transient node. At the same time, it can avoid deadlock problems caused by locks that cannot be released due to service downtime. After completing the business process, delete the corresponding child node to release the lock.
In practice, reliability is of course the main priority. Therefore, Zookeeper is recommended first.
Since Redis is so lightweight (a single instance only uses 1M memory), the best way to prevent future expansion is to start more instances at the beginning. Even if you only have one server, you can have Redis run in a distributed manner from the beginning, using partitions to start multiple instances on the same server.
Set up a few more Redis instances at the beginning, such as 32 or 64 instances. This may be troublesome for most users, but in the long run it is worth the sacrifice. of.
In this case, when your data continues to grow and you need more Redis servers, all you need to do is just migrate the Redis instance from one service to another server (without considering repartitioning The problem). Once you add another server, you need to migrate half of your Redis instances from the first machine to the second machine.
The Redis official website proposes an authoritative way to implement distributed locks based on Redis called Redlock. This method is better than the original The single-node approach is more secure. It can guarantee the following features:
1. Security features: mutually exclusive access, that is, only one client can always get the lock
2. Avoid deadlock: eventually all clients may get the lock When the lock is reached, there will be no deadlock, even if the client that originally locked a resource crashes or a network partition occurs
3. Fault tolerance: As long as most Redis nodes survive, services can be provided normally
Cache avalanche
Cache avalanche refers to the cache of the same A large area of time fails, so subsequent requests will fall on the database, causing the database to withstand a large number of requests in a short period of time and collapse.
Solution
1. Set the expiration time of cached data randomly to prevent a large number of data from expiring at the same time.
2. Generally, when the amount of concurrency is not particularly large, the most commonly used solution is lock queuing.
3. Add a corresponding cache tag to each cached data and record whether the cache is invalid. If the cache tag is invalid, update the data cache.
Cache penetration
Cache penetration refers to data that is neither in the cache nor in the database, causing all requests to fall on the database , causing the database to collapse due to a large number of requests in a short period of time.
Solution
1. Add verification at the interface layer, such as user authentication verification, basic verification of id, and direct interception of id<=0;
2. The data that cannot be obtained from the cache is not obtained in the database. At this time, the key-value pair can also be written as key-null. The cache validity time can be set shorter, such as 30 seconds ( Setting it too long will make it unusable under normal circumstances). This can prevent attacking users from repeatedly using the same ID to brute force attacks;
3. Use a Bloom filter to hash all possible data into a large enough bitmap. Data that must not exist will be It is intercepted by this bitmap, thereby avoiding query pressure on the underlying storage system.
Additional
The ultimate use of space is Bitmap and Bloom Filter.
Bitmap: The typical one is the hash table
The disadvantage is that Bitmap can only record 1 bit of information for each element. If you want to complete additional functions, I am afraid that only It can be accomplished by sacrificing more space and time.
Bloom filter (recommended)
introduces k(k>1)k(k>1) independent hash functions to ensure that Under a given space and misjudgment rate, the process of element weight determination is completed.
Its advantage is that space efficiency and query time are much higher than the general algorithm, but its disadvantage is that it has a certain misrecognition rate and difficulty in deletion.
The core idea of the Bloom-Filter algorithm is to use multiple different Hash functions to resolve "conflicts".
Hash has a conflict (collision) problem. The values of two URLs obtained by using the same Hash may be the same. In order to reduce conflicts, we can introduce several more Hash values. If we conclude from one of the Hash values that an element is not in the set, then the element is definitely not in the set. Only when all Hash functions tell us that the element is in the set can we be sure that the element exists in the set. This is the basic idea of Bloom-Filter.
Bloom-Filter is generally used to determine whether an element exists in a large data collection.
Cache breakdown
Cache breakdown refers to data that is not in the cache but is in the database (usually the cache time has expired), At this time, because there are so many concurrent users, the data is not read in the read cache at the same time, and the data is fetched from the database at the same time, causing the pressure on the database to increase instantly, causing excessive pressure. Different from cache avalanche, cache breakdown refers to the concurrent query of the same data. Cache avalanche means that different data have expired, and a lot of data cannot be found, so the database is searched.
Solution
1. Set the hotspot data to never expire
2. Add a mutex lock, mutex lock
Cache preheating
Cache preheating means loading relevant cache data directly into the cache system after the system goes online. In this way, you can avoid the problem of querying the database first and then caching the data when the user requests it! Users directly query cached data that has been preheated!
Solution
1. Directly write a cache refresh page, and do it manually when going online;
2. The amount of data is not large, you can Automatically load when the project starts;
3. Refresh the cache regularly;
Cache downgrade
When the number of visits increases When service problems occur (such as slow response time or no response) or non-core services affect the performance of core processes, it is still necessary to ensure that the service is still available, even if the service is compromised. The system can automatically downgrade based on some key data, or configure switches to achieve manual downgrade.
The ultimate goal of cache downgrade is to ensure that core services are available, even if they are lossy. And some services cannot be downgraded (such as adding to shopping cart, checkout).
Before downgrading, the system should be sorted out to see if the system can lose soldiers and retain commanders; thereby sorting out what must be protected to the death and what can be downgraded; for example, you can refer to the log level setting plan:
1. General: For example, some services occasionally time out due to network jitter or the service is online, and can be automatically downgraded;
2. Warning: Some services have fluctuating success rates within a period of time (such as 95~ 100%), you can automatically downgrade or manually downgrade, and send an alarm;
3. Error: For example, the availability rate is lower than 90%, or the database connection pool is exhausted, or the number of visits suddenly increases. reaches the maximum threshold that the system can withstand. At this time, it can be automatically downgraded or manually downgraded according to the situation;
4. Serious error: For example, if the data is incorrect due to special reasons, emergency manual downgrade is required.
The purpose of service downgrade is to prevent Redis service failure from causing avalanche problems in the database. Therefore, for unimportant cached data, a service downgrade strategy can be adopted. For example, a common approach is that if there is a problem with Redis, instead of querying the database, it directly returns the default value to the user.
Hot data and cold data
Hot data, cache is valuable
For cold data, most The data may have been squeezed out of the memory before it is accessed again, which not only takes up memory, but also has little value. For frequently modified data, consider using cache depending on the situation
For hot data, such as one of our IM products, birthday greeting module, and birthday list of the day, the cache may be read hundreds of thousands of times. For another example, in a navigation product, we cache navigation information and may read it millions of times in the future.
Cache is meaningful only if the data is read at least twice before updating. This is the most basic strategy. If the cache fails before it takes effect, it will not be of much value.
What about the scenario where the cache does not exist and the frequency of modification is very high, but you have to consider caching? have! For example, this reading interface puts a lot of pressure on the database, but it is also hot data. At this time, you need to consider caching methods to reduce the pressure on the database, such as the number of likes, collections, and shares of one of our assistant products. This is very typical hot data, but it keeps changing. At this time, the data needs to be saved to the Redis cache synchronously to reduce the pressure on the database.
Cache hotspot key
When a Key in the cache (such as a promotional product) expires at a certain point in time, it happens to be At this point in time, there are a large number of concurrent requests for this Key. When these requests find that the cache has expired, they usually load data from the backend DB and reset it to the cache. At this time, large concurrent requests may instantly overwhelm the backend DB.
Solution
Lock the cache query. If the KEY does not exist, lock it, then check the DB into the cache, and then unlock it; if other processes find that there is a lock Just wait, and then return the data or enter the DB query after unlocking
##What are the Java clients supported by Redis? Which one is officially recommended?
What is the relationship between Redis and Redisson?
Redisson is an advanced distributed coordination Redis client that can help users easily implement some Java objects (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map) in a distributed environment , ConcurrentMap, List, ListMultimap, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, AtomicLong, CountDownLatch, Publish / Subscribe, HyperLogLog).What are the advantages and disadvantages of Jedis and Redisson?
Jedis is a client implemented by Redis in Java. Its API provides relatively comprehensive support for Redis commands; Redisson implements a distributed and scalable Java data structure. Compared with Jedis, its functions It is relatively simple, does not support string operations, and does not support Redis features such as sorting, transactions, pipelines, and partitions. The purpose of Redisson is to promote the separation of users' concerns from Redis, so that users can focus more on processing business logic.
Both are non-relational memories For key-value databases, companies now generally use Redis to implement caching, and Redis itself is becoming more and more powerful! The main differences between Redis and Memcached are as follows:
| ##Type |
Storage value |
Operation |
Application scenario |
| Execute on the entire string or part of the string Operation; | Perform increment or decrement operations on integers and floating point numbers | Do simple key-value pair caching
||
| Push or pop elements from both ends; | Trim single or multiple elements, retaining only elements within a range | Storage some list-type data structures , data similar to fan list, article comment list and so on
||
| Check whether an element exists in the set; Calculate intersection, union, and difference set; Randomly obtain elements from the set | Intersection, union, Difference operations, such as intersection, can combine the fan lists of two people into one intersection
|||
| Get all key-value pairs; Check whether a key exists | Structured data, such as an object
|||
| Ordered set | Get elements based on score range or members; Calculate one The ranking of keys | is deduplicated but can be sorted, such as getting the top users
| Compare parameters |
redis | memcached |
| Type | 1. Supports memory 2. Non-relational database | 1. Supports memory 2. Key-value pair format 3. Cache format |
| Data storage type | 1. String 2. List 3. Set 4. Hash 5. Sort Set [commonly known as ZSet] | 1. Text type 2 . Binary type |
| Query [Operation] type | 1. Batch operation 2. Transaction support 3. Different CRUD for each type | 1. Commonly used CRUD 2. A small number of other commands |
| Additional functions | 1. Publish/subscribe mode 2. Master-slave partition 3. Serialization support 4. Script support【 Lua script】 | 1. Multi-threaded service support |
| Network IO model | Single-threaded multi-channel IO multiplexing model |
1. Multi-threaded, non-blocking IO mode |
| Event library |
AeEvent | LibEvent |
| Persistence support |
1. RDB 2. AOF | Does not support |
| Cluster mode |
Natively supports cluster mode, which can realize master-slave replication and read-write separation. |
There is no native cluster mode and you need to rely on the client to implement sharded writes to the cluster. Data |
| Memory management mechanism |
In Redis, not all data is always stored in memory, and some values that have not been used for a long time can be exchanged to Disk | Memcached data will always be in memory. Memcached divides the memory into blocks of specific lengths to store data to completely solve the problem of memory fragmentation. However, this method will cause low memory utilization. For example, if the block size is 128 bytes and only 100 bytes of data is stored, the remaining 28 bytes will be wasted. |
| Applicable scenarios |
Complex data structure, persistence, high availability requirements, large value storage content |
Pure key-value, a business with a very large amount of data and a very large amount of concurrency |
(1) All values in memcached are simple strings, and redis is its replacement. Supports richer data types
(2) redis is much faster than memcached
(3) redis can persist its data
How to ensure caching Data consistency with database double write?
As long as you use cache, it may involve dual storage and double writing of cache and database. As long as you use dual writing, there will definitely be data consistency problems. So how do you solve the consistency problem? ?
Generally speaking, if your system does not strictly require the cache database to be consistent, the cache may occasionally be slightly inconsistent with the database. It is best not to do this solution. Read request and write request strings Serialize and serialize it into a memory queue, so as to ensure that there will be no inconsistency.
After serialization, the throughput of the system will be greatly reduced, and the usage will be significantly lower than that under normal conditions. Download several times more machines to support an online request.
Another way is that temporary inconsistency may occur, but the probability of occurrence is very small, that isupdate the database first, and then delete the cache.
| Problem Scenario |
Description | Solution |
| Write to the cache first, then write to the database. If the cache is written successfully, but the database write fails | The cache is written successfully, but writing to the database fails or the response is delayed, the next time When reading (concurrent read) cache, dirty reading occurs | This way of writing cache is wrong in itself. You need to write to the database first and invalidate the old cache; when reading data, If the cache does not exist, read the database and then write to the cache |
| Write to the database first, then write to the cache. The database write is successful, but the cache write fails | The database is written successfully, but If the write cache fails, the next time the cache is read (concurrently read), the data cannot be read | When the cache is used, if the read cache fails, the database is read first, and then written back to the cache. |
| Requires cache asynchronous refresh | means that the database operation and write cache are not in the same operation step. For example, in a distributed scenario, the cache cannot be written at the same time or asynchronous refresh is required (remediation Measures) | Determine which data is suitable for such scenarios, determine a reasonable data inconsistency time based on empirical values, and the time interval for user data refresh |
Redis common performance problems and solutions?
1. Master is best not to do any persistence work, including memory snapshots and AOF log files, especially do not enable memory snapshots for persistence.
2. If the data is critical, a Slave enables AOF backup data, and the policy is to synchronize once per second.
3. For the speed of master-slave replication and the stability of the connection, it is best for Slave and Master to be in the same LAN.
4. Try to avoid adding slave libraries to the master library that is under great pressure.
5. Master calls BGREWRITEAOF to rewrite the AOF file. AOF will occupy a large amount of CPU and memory during rewriting. resources, causing the service load to be too high and temporary service suspension.
6. For the stability of the Master, do not use a graph structure for master-slave replication. It is more stable to use a one-way linked list structure, that is, the master-slave relationship is: Master<–Slave1<–Slave2<–Slave3…, like this The structure is also convenient to solve the single point of failure problem and realize the replacement of the Master by the Slave. That is, if the Master hangs up, you can immediately enable Slave1 as the Master, and other things remain unchanged.
Why doesn’t Redis officially provide a Windows version?
Because the current Linux version is quite stable and has a large number of users, there is no need to develop a windows version, which will cause compatibility and other problems.
What is the maximum capacity that a string type value can store?
512M
How does Redis insert large amounts of data?
Starting with Redis 2.6, redis-cli supports a new mode called pipe mode for performing large amounts of data insertion work.
Suppose there are 100 million keys in Redis, and 100,000 of them start with a fixed, known prefix. How to find them all?
Use the keys command to scan out the key list of the specified mode.
The other party then asked: If this redis is providing services to online businesses, what are the problems with using the keys command?
At this time you have to answer one of the key features of redis: redis's single thread. The keys instruction will cause the thread to block for a period of time and the online service will pause. The service cannot be restored until the instruction is executed. At this time, you can use the scan command. The scan command can extract the key list of the specified mode without blocking, but there will be a certain probability of duplication. Just do it once on the client, but the overall time spent will be longer than using it directly. The keys command is long.
Have you ever used Redis to create an asynchronous queue? How was it implemented?
Use the list type to save data information, rpush produces messages, and lpop consumes messages. When lpop has no messages, you can sleep for a period of time, and then check whether there is any information. If you do not want to sleep, you can use blpop , when there is no information, it will block until the information arrives. Redis can implement one producer and multiple consumers through the pub/sub topic subscription model. Of course, there are certain shortcomings. When the consumer goes offline, the produced messages will be lost.
How does Redis implement delay queue?
Use sortedset, use timestamp as score, message content as key, call zadd to produce messages, and consumers use zrangbyscore to obtain data n seconds ago for polling processing.
How does the Redis recycling process work?
1. A client ran a new command and added new data.
2. Redis checks the memory usage. If it is greater than the limit of maxmemory, it will be recycled according to the set strategy.
3. A new command is executed, etc.
4. So we constantly cross the boundary of the memory limit by constantly reaching the boundary and then continuously recycling back below the boundary.
If the result of a command causes a large amount of memory to be used (such as saving the intersection of a large set to a new key), it will not take long for the memory limit to be exceeded by this memory usage.
What algorithm is used for Redis recycling?
LRU Algorithm
For more programming-related knowledge, please visit:Programming Teaching! !
The above is the detailed content of Redis high-frequency interview questions (with answer analysis). For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software What are the in-memory databases?
What are the in-memory databases? Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis? How to use redis as a cache server
How to use redis as a cache server How redis solves data consistency
How redis solves data consistency How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency? What data does redis cache generally store?
What data does redis cache generally store? What are the 8 data types of redis
What are the 8 data types of redis























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



