


Based on the basic CSS syntax knowledge learned above, now let’s implement field parsing. First, parse the title. Open the web developer tools and find the source code corresponding to the title. This article mainly introduces the relevant information about CSS selector implementation of field parsing. Friends who need it can refer to it. I hope it can help everyone
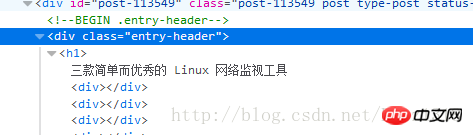
I found it in p class= "entry-header"In the h1 node below, I opened scrapy shell for debugging

But I don’t want the

Note the two colons. Using CSS selectors is really convenient. In the same way, I use CSS to implement field parsing. The code is as follows
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass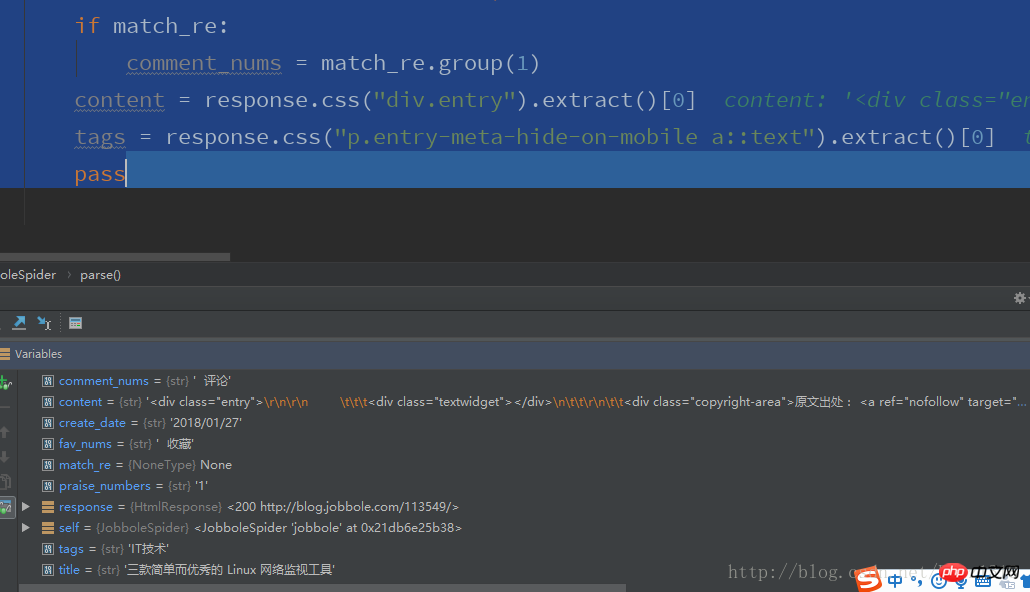
Related recommendations:
OpenERP employee (employee) table and user Table related field analysis
The above is the detailed content of How to implement CSS selector field parsing. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



