

這篇文章給大家分享的內容是3利用python如何爬取js裡面的內容,有著一定的參考價值,有需要的朋友可以參考一下
一、在寫爬蟲軟體獲取所需內容時可能會碰到所需要的內容是由javascript添加上去的在獲取的時候為空比如我們在獲取新浪新聞的評論數時使用普通的方法就無法取得
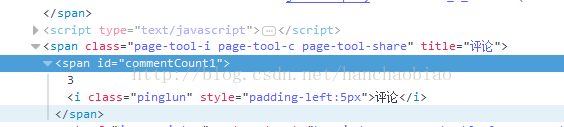
import requests from bs4 import BeautifulSoup res = requests.get('http://news.sina.com.cn/c/nd/2017-06-12/doc-ifyfzhac1650783.shtml') res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') #取评论数 commentCount = soup.select_one('#commentCount1') print(commentCount.text)
此時所取得的結果為空這是由於內容是儲存在js檔案中
#因此我們需要取尋找儲存評論內容的js 經過查找我們發現其儲存在改js裡
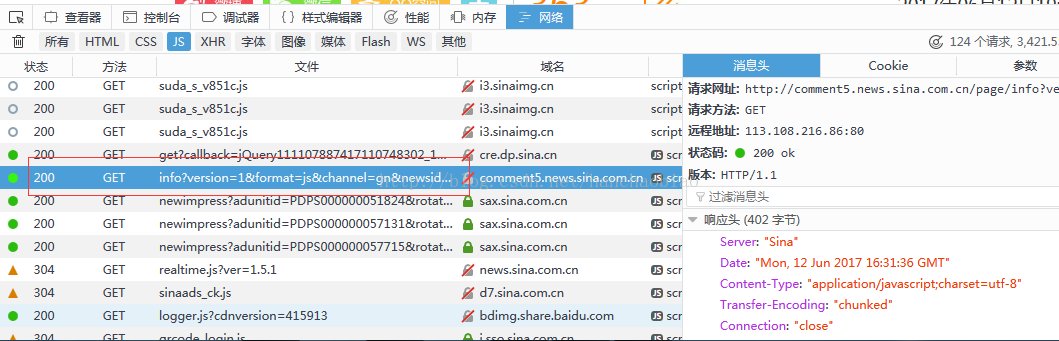
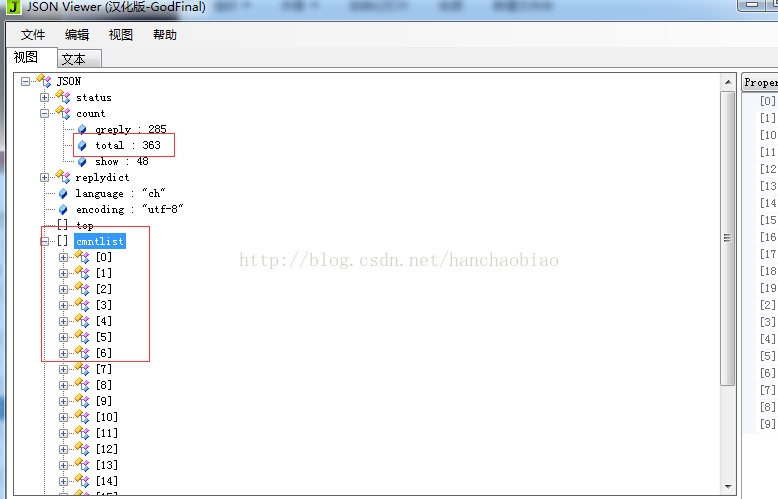
將對應內容放入json資料檢視器中我們發現評論總數和評論內容都在該js檔案中一json格式存放
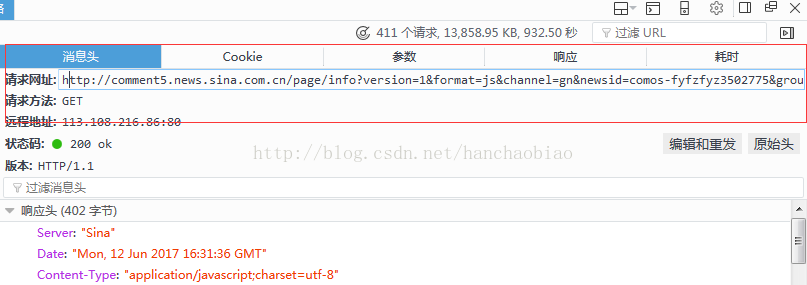
#在訊息頭中我們可以看的該js檔案的存取路徑及請求方式
程式碼範例
import json comments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fyfzhac1650783') comments.encoding = 'utf-8' print(comments) jd = json.loads(comments.text.strip('var data=')) #移除改var data=将其变为json数据 print(jd['result']['count']['total'])
程式碼範例
rrreee
註解:這裡解釋下為何需要移除var data= 因為在取得時字串前綴是包含var data=的其不符合json資料格式因此轉換時需將其從請求內容中移除
取評論總數時為何使用jd['result'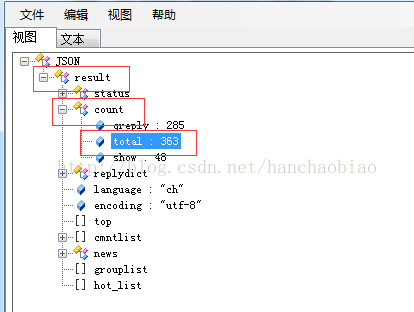 ][
][
'count'
'total'
]
以上是利用python如何爬取js裡面的內容的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















