Found a total of 77 related content

Getting started with Python crawler: crawling web images
Article Introduction:This article brings you relevant knowledge about Python. It mainly organizes the related issues of crawling web images. If you want to obtain data efficiently, crawlers are very easy to use, and using python to do crawlers is also very simple and convenient. Let’s take a look at the basic process of writing a crawler through a simple small crawler program. Let’s take a look at it together. I hope it will be helpful to everyone.
2022-07-11comment 02391

python爬虫怎么爬取图片
Article Introduction:通过 Python 中的 BeautifulSoup、Requests、Pillow 库,可以爬取图片:导入库获取网页内容找到包含图片 URL 的元素下载图片保存图片
2024-06-04comment 0997

Introduction to python crawling web pages
Article Introduction:I have written a lot of codes for crawling web pages on the Internet before. Recently, I still want to record the crawlers I wrote so that everyone can use them! The code is divided into 4 parts: Part 1: Find a website. Part 2: Crawl the web. Part 3: Get a specified url information. Part 4: Saving data.
2021-03-09comment 03226
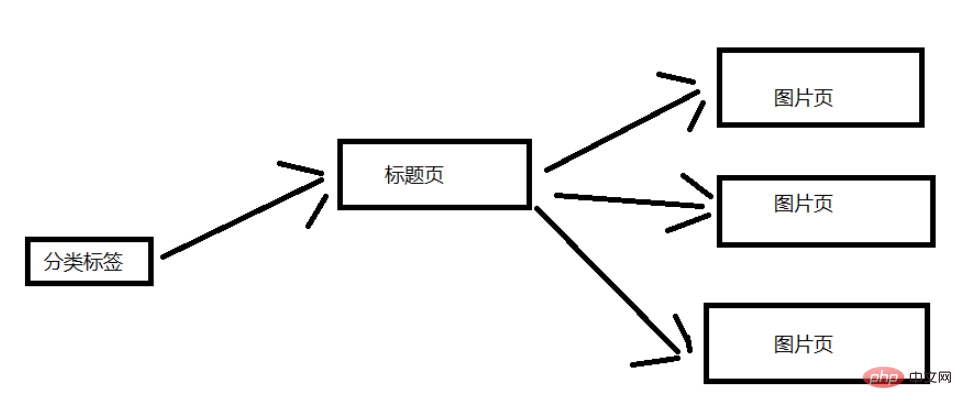
How to use Java crawler to crawl images in batches
Article Introduction:The crawling idea for obtaining this kind of pictures is essentially downloading files (HttpClient). But because it is not just about getting a picture, there is also a page parsing process (Jsoup). Jsoup: parse the html page and get the link to the image. HttpClient: Request the link of the image and save the image locally. The specific steps are to first enter the home page for analysis. There are mainly the following categories (not all categories here, but these are enough. This is just a learning technique.). Our goal is to obtain pictures under each category. Let’s analyze the structure of the website here. I’ll keep it simple here. The picture below shows the general structure. Here we select a classification label to describe.
2023-05-03comment 01388

Use the Scrapy framework to crawl the Flickr image library
Article Introduction:In today's information technology era, crawling massive amounts of data has become an important skill. With the rapid development of big data technology, data crawling technology is constantly being updated and improved. Among them, the Scrapy framework is undoubtedly the most commonly used and popular framework. It has unique advantages and flexibility in data crawling and processing. This article will introduce how to use the Scrapy framework to crawl the Flickr image library. Flickr is a picture sharing website with hundreds of millions of pictures in its inventory and a very large amount of data resources. by Sc
2023-06-22comment 0377

How does PHP perform web scraping and data scraping?
Article Introduction:PHP is a server-side scripting language that is widely used in fields such as website development and data processing. Among them, web crawling and data crawling are one of the important application scenarios of PHP. This article will introduce the basic principles and common methods of how to crawl web pages and data with PHP. 1. The principles of web crawling and data crawling Web crawling and data crawling refer to automatically accessing web pages through programs and obtaining the required information. The basic principle is to obtain the HTML source code of the target web page through the HTTP protocol, and then parse the HTML source code
2023-06-29comment 01241

Python crawler crawls web page data and parses the data
Article Introduction:This article brings you relevant knowledge about Python. It mainly introduces how python crawlers crawl web page data and parse the data to help you better use crawlers to analyze web pages. Let's take a look at it together. I hope it will be helpful to you.
2022-08-15comment 06897

How to use PHP and phpSpider to crawl and download images?
Article Introduction:How to use PHP and phpSpider to crawl and download images? With the development of the Internet, we have a large number of pictures circulating on the Internet every day. Sometimes we may need to save some pictures locally so that we can view them at any time. Manually downloading one by one may be very tedious and time-consuming. At this time, crawler technology is needed. This article will introduce how to use PHP language and phpSpider framework to crawl and download images. As a powerful server-side scripting language, PHP is known for its simplicity
2023-07-21comment 0602

How to use PHP Goutte class library for web crawling and data extraction?
Article Introduction:How to use the PHPGoutte class library for web crawling and data extraction? Overview: In the daily development process, we often need to obtain various data from the Internet, such as movie rankings, weather forecasts, etc. Web crawling is one of the common methods to obtain this data. In PHP development, we can use the Goutte class library to implement web crawling and data extraction functions. This article will introduce how to use the PHPGoutte class library to crawl web pages and extract data, and attach code examples. What is Gout
2023-08-09comment 0706


PHP crawler practice: how to crawl web table data
Article Introduction:With the advent of the Internet and big data era, more and more data can be collected and utilized. Among the many methods of obtaining data from web pages, crawler technology can be said to be the most powerful and efficient one. In actual application scenarios, we often need to grab specific data from web pages, especially table data in web pages. Therefore, this article will introduce how to use PHP crawler technology to obtain and parse tabular data in web pages. Install and configure the PHP crawler library. Before starting to write crawler code, we need to install and configure a PHP crawler library.
2023-06-13comment 0910

How to use PHPQuery to crawl web pages in PHP
Article Introduction:In today's era of information explosion, web crawlers have become a very common technical method in the Internet field. As one of the widely used languages in Internet development, PHP has many ways to implement web crawling. Among them, PHPQuery is a very practical PHP library that can quickly and easily implement web crawling, data extraction and other tasks. This article will introduce the use of PHPQuery and application cases to help readers better master this technology. 1. Introduction to PHPQuery PHPQu
2023-06-27comment 0931

Master the main methods of crawling web pages with PHP
Article Introduction:This article mainly introduces the main methods of crawling web pages with PHP. The main method is to obtain the entire web page and then match it with regular rules. Friends in need can refer to it.
2020-08-01comment 03547

Crawl images from the website and automatically download them locally
Article Introduction:In the Internet age, people have become accustomed to downloading pictures from various websites such as galleries and social platforms. If you only need to download a small number of images, manual operation is not cumbersome. However, if a large number of pictures need to be downloaded, manual operation will become very time-consuming and laborious. At this time, automation technology needs to be used to automatically download the pictures. This article will introduce how to use Python crawler technology to automatically download images from the website to the local computer. This process is divided into two steps: the first step is to use Python's requests library or s
2023-06-13comment 02066

Web crawler implementation based on PHP: extract key information from web pages
Article Introduction:With the rapid development of the Internet, a large amount of information is generated on different websites every day. This information includes various forms of data, such as text, pictures, videos, etc. For those who need a comprehensive understanding and analysis of the data, manually collecting data from the Internet is impractical. In order to solve this problem, web crawlers came into being. A web crawler is an automated program that crawls and extracts specific information from the Internet. In this article, we will introduce how to implement a web crawler using PHP. 1. Working principle of web crawler
2023-06-13comment 0823

Getting started with phpSpider: How to crawl web content easily?
Article Introduction:Getting started with phpSpider: How to crawl web content easily? Introduction: In today's Internet era, a large amount of information is scattered on various web pages. If we can automatically extract the required information from these web pages, our work efficiency will be greatly improved. So how to achieve this goal? The answer is to use crawler technology. This article will introduce how to use phpSpider to crawl simple web content, let’s take a deeper look! 1. What is phpSpider? phpSpider is
2023-07-21comment 0732

Java web crawler development: teach you how to automatically crawl web page data
Article Introduction:Java web crawler development: teach you how to automatically crawl web page data In the Internet era, data is a very precious resource. How to efficiently obtain and process this data has become the focus of many developers. As a tool for automatically crawling web page data, web crawlers are favored by developers because of their efficiency and flexibility. This article will introduce how to use Java language to develop web crawlers and provide specific code examples to help readers understand and master the basic principles and implementation methods of web crawlers. 1. Understand web crawlers
2023-09-22comment 01125

Java crawler skills: Coping with data crawling from different web pages
Article Introduction:Improving crawler skills: How Java crawlers cope with data crawling from different web pages requires specific code examples. Summary: With the rapid development of the Internet and the advent of the big data era, data crawling has become more and more important. As a powerful programming language, Java's crawler technology has also attracted much attention. This article will introduce the techniques of Java crawler in handling different web page data crawling, and provide specific code examples to help readers improve their crawler skills. Introduction With the popularity of the Internet, we can easily obtain massive amounts of data. However, these numbers
2024-01-09comment 0521

PHP crawler practice: obtaining web page source code and content analysis
Article Introduction:PHP crawler is a program that automatically obtains web page information. It can obtain web page code, crawl data and store it locally or in a database. Using crawlers can quickly obtain large amounts of data, providing great help for subsequent data analysis and processing. This article will introduce how to use PHP to implement a simple crawler to obtain web page source code and content analysis. 1. Obtain the source code of the web page. Before starting, we should first understand the basic structure of the HTTP protocol and HTML. HTTP is HyperText
2023-06-13comment 01302

