


This article brings you relevant knowledge about Python. It mainly introduces how python crawlers crawl web page data and parse the data to help you better use crawlers to analyze web pages. Let’s do it together. Take a look, hope it helps everyone.

[Related recommendations: Python3 video tutorial ]
Web crawlers (also known as web spiders and robots) simulate a client sending network requests and receiving request responses. It is a program that automatically captures Internet information according to certain rules.
As long as the browser can do anything, in principle, the crawler can do it.
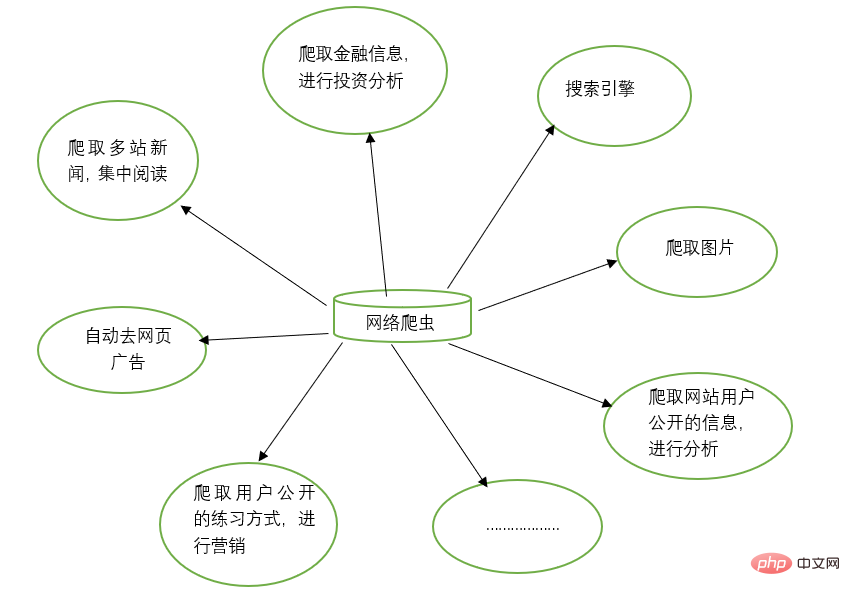
Web crawlers can replace many things manually, such as search engines, You can also crawl pictures on websites. For example, some friends crawl all the pictures on certain websites and browse them together. At the same time, web crawlers can also be used in the field of financial investment. For example, they can automatically crawl some financial information and Conduct investment analysis, etc.
Sometimes, we may have several favorite news websites, and it is troublesome to open these news websites separately every time to browse. At this time, you can use a web crawler to crawl the news information from these multiple news websites and read them together.
Sometimes, when we browse information on the web, we will find a lot of advertisements. At this time, you can also use a crawler to crawl the information on the corresponding web page, so that these advertisements can be automatically filtered out to facilitate the reading and use of the information.
Sometimes, we need to conduct marketing, so how to find target customers and their contact information is a key issue. We can manually search on the Internet, but this will be very inefficient. At this time, we can use crawlers to set corresponding rules and automatically collect target users' contact information and other data from the Internet for our marketing use.
Sometimes, we want to analyze the user information of a certain website, such as analyzing the user activity, number of comments, popular articles and other information of the website. If we are not the website administrator, manual statistics will be a very difficult task. Huge project. At this time, crawlers can be used to easily collect these data for further analysis. All crawling operations are performed automatically. We only need to write the corresponding crawler and design the corresponding rules.
In addition, crawlers can also achieve many powerful functions. In short, the emergence of crawlers can replace manual access to web pages to a certain extent. Therefore, operations that previously required manual access to Internet information can now be automated using crawlers, so that effective information in the Internet can be used more efficiently. .
Before crawling data and parsing data, you need to download and install the third-party library requests in the Python running environment.
In Windows system, open the cmd (command prompt) interface, enter pip install requests in the interface, and press Enter to install. (Pay attention to the network connection) As shown below
The installation is completed, as shown in the picture
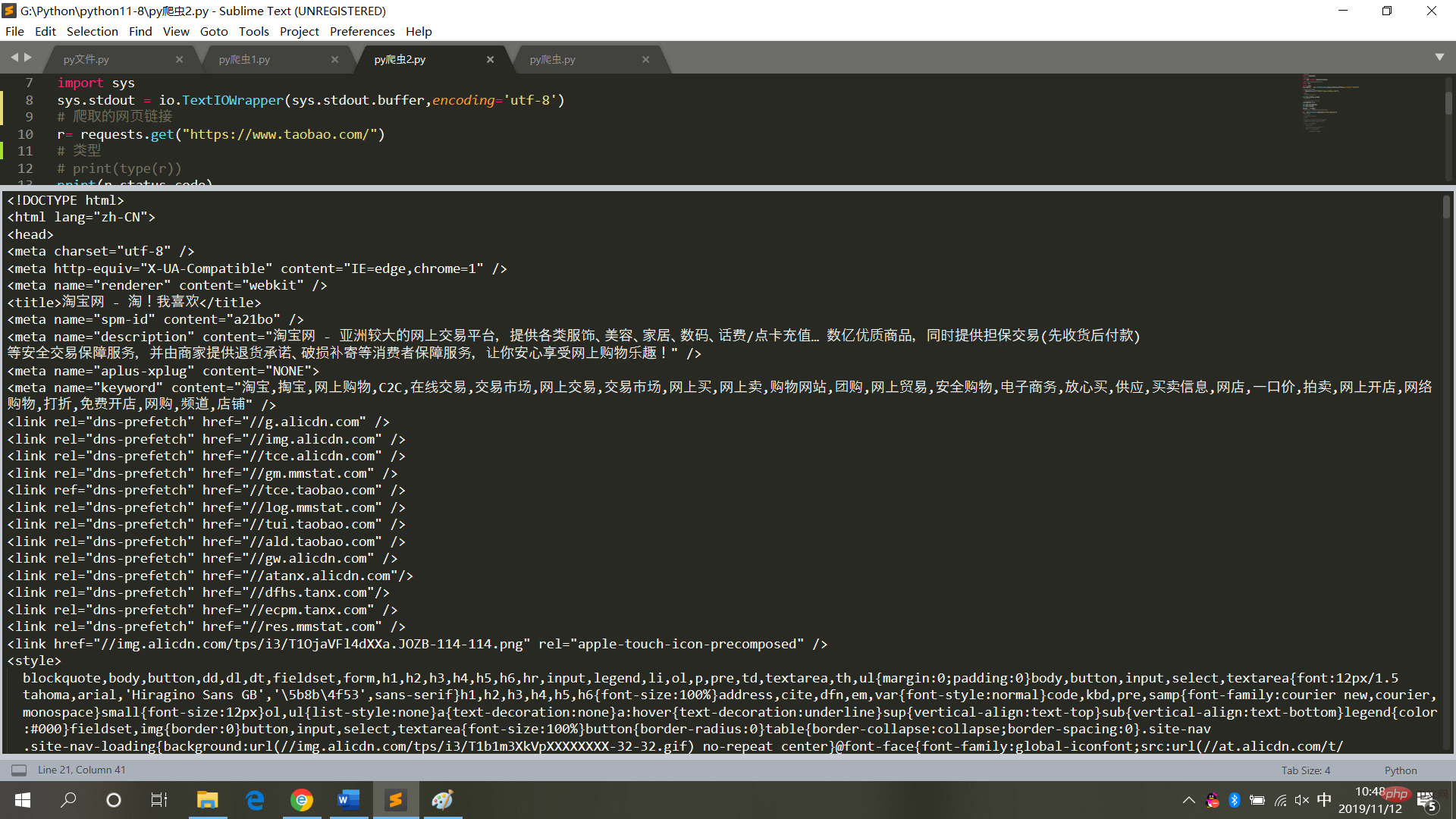
# 请求库
import requests
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.textThe running result is as shown in the figure
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
print("解析后的数据")
print(bs.span)
a={}
# 获取已爬取内容中的script标签内容
data=bs.find_all('script')
# 获取已爬取内容中的td标签内容
data1=bs.find_all('td')
# 循环打印输出
for i in data:
a=i.text
print(i.text,end='')
for j in data1:
print(j.text)Running results, as shown in the figure
When crawling web page code, do not do it frequently operation, and do not set it into an infinite loop mode (each crawl is an access to a web page, frequent operations will cause the system to crash, and legal liability will be pursued).
So after obtaining the web page data, save it in local text mode and then parse it (no need to access the web page anymore).
【Related recommendations: Python3 video tutorial】
The above is the detailed content of Python crawler crawls web page data and parses the data. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



