Found a total of 10000 related content

数据稀缺对模型训练的影响问题
Article Introduction:数据稀缺对模型训练的影响问题,需要具体代码示例在机器学习和人工智能领域,数据是训练模型的核心要素之一。然而,现实中我们经常面临的一个问题是数据稀缺。数据稀缺指的是训练数据的量不足或标注数据的缺乏,这种情况下会对模型训练产生一定的影响。数据稀缺的问题主要体现在以下几个方面:过拟合:当训练数据量不够时,模型很容易出现过拟合的现象。过拟合是指模型过度适应训练数据,
2023-10-08
comment 0
845

数据预处理在模型训练中的重要性问题
Article Introduction:数据预处理在模型训练中的重要性及具体代码示例引言:在进行机器学习和深度学习模型的训练过程中,数据预处理是一个非常重要且必不可少的环节。数据预处理的目的是通过一系列的处理步骤,将原始数据转化为适合模型训练的形式,以提高模型的性能和准确度。本文旨在探讨数据预处理在模型训练中的重要性,并给出一些常用的数据预处理代码示例。一、数据预处理的重要性数据清洗数据清洗是数据
2023-10-08
comment 0
761
英伟达开创新纪元:机器人训练数据的“永动机”
Article Introduction:之前的合成数据大多用于AI大模型训练,这一次,英伟达为机器人训练建起了“数据粮仓”——机器人技术发展步调远远落后于其他AI领域的关键原因之一,便是缺乏数据。只需200个人类演示源数据,这一系统就能直接生成50000个训练数据。AI对数据的庞大需求之下,数据资源几近枯竭,因此各家公司已开始摸索一条获取数据的“新路”——自己“造”数据。不过之前的合成数据大多用于AI大模型训练,这一次,英伟达为机器人训练造出了“数据粮仓”。英伟达与得克萨斯大学奥斯汀分校的一项最新研究论文中,介绍了一个名为“Mimic
2023-10-30
comment 0
338

数据拆分的技术和陷阱——训练集、验证集与测试集的使用方式
Article Introduction:为了构建可靠的机器学习模型,数据集的拆分是必不可少的。拆分过程包括将数据集分为训练集、验证集和测试集。本文旨在详细介绍这三个集合的概念、数据拆分的技术以及容易出现的陷阱。训练集、验证集和测试集训练集训练集是用于训练和使模型学习数据中隐藏的特征/模式的数据集。在每个epoch中,相同的训练数据被重复输入神经网络架构,模型继续学习数据的特征。训练集应该具有多样化的输入集,以便模型在所有场景下都得到训练,并且可以预测未来可能出现的数据样本。验证集验证集是一组数据,与训练集分开,用于在训练期间验证模型性
2024-01-22
comment 0
351

使用C++训练机器学习模型:从数据预处理到模型验证
Article Introduction:在C++中训练ML模型涉及以下步骤:数据预处理:加载、转换并工程化数据。模型训练:选择算法并训练模型。模型验证:划分数据集,评估性能,并调整模型。通过遵循这些步骤,您可以成功地在C++中构建、训练和验证机器学习模型。
2024-05-11
comment
444

训练YOLOv7模型,开发AI火灾监测
Article Introduction:1.准备数据集数据集使用的是开源图片,共6k张火灾图片,分别标注出浓烟和火两类。火浓烟项目采用YOLO训练,我已经把数据转成YOLO格式,并分好了训练集和验证集,见dataset目录。2.训练训练过程参考YOLOv7官网文档即可。修改data/coco.yaml文件,配置好训练数据的路径和类别。下载预训练模型yolov7.pt,然后就可以开始训练了3.火灾监测训练完成后,在yolov7目录下的run目录中,找到生成的模型文件——best.pt。我训练
2023-05-11
comment 0
553

keep怎么自由训练
Article Introduction:Keep自由训练模式允许用户自定义训练内容,包括动作、组数、次数和休息时间。具体步骤包括:1. 选择动作;2. 设定参数;3. 编排训练计划;4. 开始训练;5. 循序渐进;6. 恢复和放松。
2024-05-04
comment 0
600
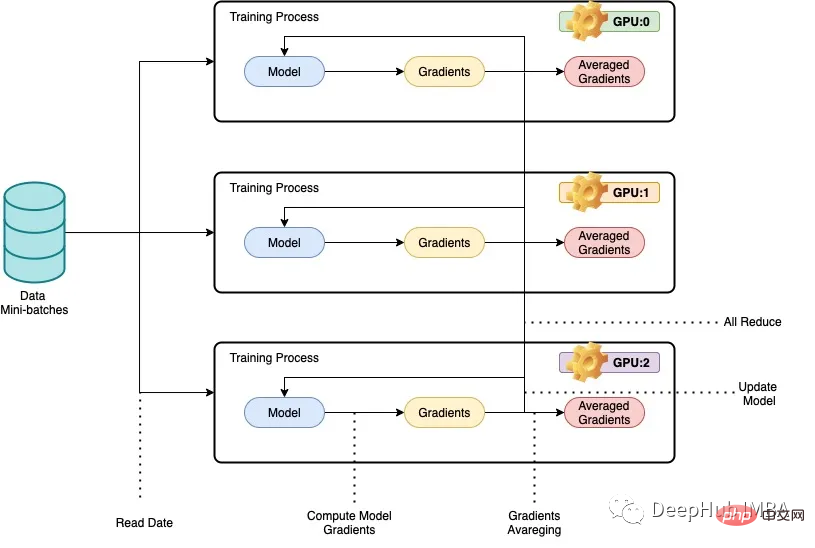
PyTorch 并行训练 DistributedDataParallel 完整代码示例
Article Introduction:使用大型数据集训练大型深度神经网络 (DNN) 的问题是深度学习领域的主要挑战。 随着 DNN 和数据集规模的增加,训练这些模型的计算和内存需求也会增加。这使得在计算资源有限的单台机器上训练这些模型变得困难甚至不可能。使用大型数据集训练大型 DNN 的一些主要挑战包括:训练时间长:训练过程可能需要数周甚至数月才能完成,具体取决于模型的复杂性和数据集的大小。内存限制:大型 DNN 可能需要大量内存来存储训练期间的所有模型参数、梯度和中间激活。 这可能会导致内存不足错误并限制可在单台机器上训练的
2023-04-10
comment 0
862

贫穷让我预训练
Article Introduction:一、要不要预训练预训练的效果是直接的,需要的资源常常令人望而却步。如果有这样一种预训练方法,它需要算力、数据、人工的资源很少,低到单人单卡原始语料就可以启动。经过无监督的数据处理,完成一次迁移到自己领域的预训练之后,就能获得零样本的NLG、NLG和向量表示推理能力,其他向量表示的召回能力超过BM25,那么你有兴趣尝试吗?预训练是大事,需要一些前置条件和资源,也要又充足的预期收益才会实行。通常所需要的条件有:充足的语料库建设,通常来说质量比数量更难得,所以语
2023-06-26
comment 0
436

CMU联手Adobe:GAN模型迎来预训练时代,仅需1%的训练样本
Article Introduction:进入预训练时代后,视觉识别模型的性能得到飞速发展,但图像生成类的模型,比如生成对抗网络GAN似乎掉队了。通常GAN的训练都是以无监督的方式从头开始训练,费时费力不说,大型预训练通过大数据学习到的「知识」都没有利用上,岂不是很亏?而且图像生成本身就需要能够捕捉和模拟真实世界视觉现象中的复杂统计数据,不然生成出来的图片不符合物理世界规律,直接一眼鉴定为「假」。预训练模型提供知识、GAN模型提供生成能力,二者强强联合,多是一件美事!问题来了,哪些预训练模型、以及如何结合起来才能改善GAN模型的生成能力
2023-05-11
comment 0
1089

使用JavaScript函数实现机器学习的模型训练
Article Introduction:使用JavaScript函数实现机器学习的模型训练随着机器学习的迅速发展,许多开发者开始关注如何使用JavaScript在前端实现机器学习的模型训练。本文将介绍如何使用JavaScript函数来实现机器学习的模型训练,并提供具体的代码示例。在开始之前,我们需要了解几个重要的概念。数据集:机器学习的模型训练需要一组有标签的数据集作为输入。数据集由特
2023-11-03
comment 0
786

数据增强技术对模型训练效果的提升问题
Article Introduction:数据增强技术对模型训练效果的提升问题,需要具体代码示例近年来,深度学习在计算机视觉、自然语言处理等领域取得了巨大的突破,但在某些场景下,由于数据集规模较小,模型的泛化能力和准确性难以达到令人满意的水平。这时,数据增强技术就能发挥其重要作用,通过扩充训练数据集,提高模型的泛化能力。数据增强(dataaugmentation)是指通过对原始数据进行一系列转换和
2023-10-10
comment 0
795

自训练的概念及其与半监督学习的联系
Article Introduction:自训练是一种半监督分类方法,包括平滑度和聚类假设。因此,它也被称为自标记或决策导向学习。通常,当标记的数据集包含大量关于数据生成过程的信息,并且未标记的样本仅用于微调算法时,自训练是一个不错的选择。然而,当这些条件不满足时,自训练的结果就不理想。因此自训练在很大程度上取决于标记样本。自训练的每一步会根据当前决策函数对未标记数据进行标记,并使用预测进行重新训练。自训练的工作原理自训练算法以拟合另一个先前学习的监督模型预测的伪标签。自训练有这几个关键点数据实例分为训练集和测试集,分类算法训练在标记训
2024-01-23
comment 0
327

谷歌 PaLM 2训练所用文本数据量是初代的近5倍
Article Introduction:公司内部文件显示,自2022年起训练新模型所使用的文本数据量几乎是前一代的5倍。据悉,谷歌最新发布的PaLM2能够执行更高级的编程、运算和创意写作任务。内部文件透露,用于训练PaLM2的token数量有3.6万亿个。所谓的token就是字符串,人们会将训练模型所用文本中的句子、段落进行切分,其中的每个字符串通常被称为token。这是训练大型语言模型的重要组成部分,能教会模型预测序列中接下来会出现哪个单词。谷歌于
2023-05-21
comment 0
736

蚂蚁开源分布式训练扩展库ATorch实现大模型训练算力有效利用率达到60%
Article Introduction:蚂蚁集团最近宣布推出了名为ATorch的大模型分布式训练加速扩展库,这是一个开源工具。ATorch的目标是通过自动资源动态优化和分布式训练稳定性提升,帮助提高深度学习的智能性。根据了解,在大模型训练中,ATorch可以将千亿模型千卡级别训练的算力利用率提高到60%,相当于为跑车添上了强劲的引擎。这对于深度学习的研究人员和开发者来说,将是一个重要的工具,可以帮助他们更高效地训练和优化大型模型。图:ATorch致力于让大模型训练更高效、可复现随着生成式大模型的爆发,模型训练的数据集和参数规模呈现指数级增长。为
2024-01-14
comment
997

java框架如何加速人工智能模型训练?
Article Introduction:Java框架可通过以下方式加速人工智能模型训练:利用TensorFlowServing部署预训练模型进行快速推理;使用H2OAIDriverlessAI自动化训练过程并利用分布式计算缩短训练时间;通过SparkMLlib在ApacheSpark架构上实现分布式训练和大规模数据集处理。
2024-06-02
comment 0
727

Batch Size的意义及对训练的影响(与机器学习模型有关)
Article Introduction:BatchSize是指机器学习模型在训练过程中每次使用的数据量大小。它将大量数据分割成小批量数据,用于模型的训练和参数更新。这种分批处理的方式有助于提高训练效率和内存利用率。训练数据通常被划分为批次进行训练,每个批次包含多个样本。而批次大小(batchsize)则指的是每个批次中包含的样本数量。在训练模型时,批次大小对训练过程有着重要的影响。1.训练速度批量大小(batchsize)对模型的训练速度有影响。较大的批量大小可以更快地处理训练数据,因为在每个epoch中,较大的批量大小可以同时处理更
2024-01-23
comment 0
522

深度学习模型的训练时间问题
Article Introduction:深度学习模型的训练时间问题引言:随着深度学习的发展,深度学习模型在各种领域取得了显著的成果。然而,深度学习模型的训练时间是一个普遍存在的问题。在大规模数据集和复杂网络结构的情况下,深度学习模型的训练时间会显著增加。本文将探讨深度学习模型的训练时间问题,并给出具体的代码示例。并行计算加速训练时间深度学习模型的训练过程通常需要大量的计算资源和时间。为了加速训练时
2023-10-09
comment 0
1008

Huggingface微调BART的代码示例:WMT16数据集训练新的标记进行翻译
Article Introduction:如果你想在翻译任务上测试一个新的体系结构,比如在自定义数据集上训练一个新的标记,那么处理起来会很麻烦,所以在本文中,我将介绍添加新标记的预处理步骤,并介绍如何进行模型微调。因为Huggingface Hub有很多预训练过的模型,可以很容易地找到预训练标记器。但是我们要添加一个标记可能就会有些棘手,下面我们来完整的介绍如何实现它,首先加载和预处理数据集。加载数据集我们使用WMT16数据集及其罗马尼亚语-英语子集。load_dataset()函数将从Huggingface下载并加载任何可用的数据集。
2023-04-10
comment 0
944

AI训练数据不用担心版权问题?日本政府表态引发热议
Article Introduction:生成式AI爆火的现在,其背后模型用以训练的信息数据的版权问题一直是人们关注的焦点——到底怎样才算合法的训练数据?是否会在无意间侵犯他人版权?对此,有外媒称,日本的政府人工智能战略委员会于5月26日提交了一份草案,表示不会强制人工智能训练中使用的数据符合版权法。而日本文部科学(相当于国内教育部)大臣永冈桂子在当地会议上证实了这一消息,称日本的法律不保护AI训练所用资料的版权。
2023-06-03
comment 0
328
