




The effect of pre-training is direct, and the resources required are often prohibitive. If this pre-training method exists, its startup requires very little computing power, data, and human resources, or even only the original corpus of a single person and a single card. After unsupervised data processing and a pre-training transfer to your own domain, you can obtain zero-sample NLG, NLG and vector representation reasoning capabilities. The recall capabilities of other vector representations exceed BM25. Are you interested in trying it?

# Do you want to do something? Determine by measuring input and output. Pre-training is a big deal and requires some prerequisites and resources, as well as sufficient expected benefits before it can be implemented. The usually required conditions are: sufficient corpus construction. Generally speaking, quality is more rare than quantity, so the quality of the corpus can be relaxed, but the quantity must be sufficient; secondly, there is a corresponding talent reserve and manpower budget. In comparison, , small models are easier to train and have fewer obstacles, while large models will encounter more problems; the last thing is the computing resources. According to the scenario and talent matching, it depends on the people. It is best to have a large memory graphics card. The benefits brought by pre-training are also very intuitive. Migrating the model can directly bring about effect improvement. The degree of improvement is directly related to the pre-training investment and field differences. The final benefit is gained by model improvement and business scale.
#In our scenario, the data field is very different from the general field, and even the vocabulary needs to be significantly replaced, and the business scale is sufficient. If not pre-trained, the model will also be fine-tuned specifically for each downstream task. The expected benefits of pre-training are certain. Our corpus is poor in quality, but sufficient in quantity. Computing power resources are very limited and can be compensated for by matching the corresponding talent reserves. At this time, the conditions for pre-training are already met.
The factor that directly determines how we start pre-training is that there are too many downstream models that need to be maintained, which especially takes up machine and human resources, and needs to be assigned to each task. Prepare a large amount of data to train a dedicated model, and the complexity of model management increases dramatically. So we explore pre-training, hoping to build a unified pre-training task to benefit all downstream models. When we do this, it is not accomplished overnight. The more models that need to be maintained also mean more model experience. Combined with the experience of multiple previous projects, including some self-supervised learning, contrastive learning, multi-task learning and other models, after repeated experiments and iterations Fusion formed.
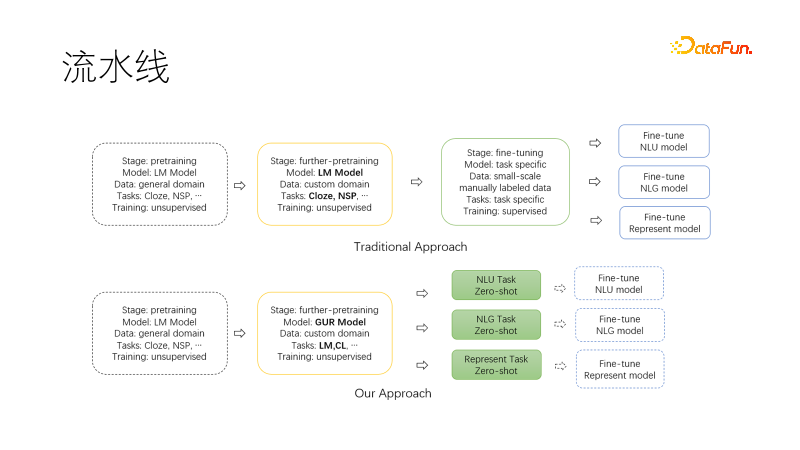
The above picture is the traditional nlp pipeline paradigm, based on the existing general pre-training model, with optional migration After pre-training is completed, collecting data sets for each downstream task, fine-tuning the training, and requiring a lot of labor and graphics cards to maintain multiple downstream models and services.
The following figure is the new paradigm we proposed. When migrating to our field to continue pre-training, we use joint language modeling tasks and contrastive learning tasks to make the product The model has zero-sample NLU, NLG, and vector representation capabilities. These capabilities are modeled and can be used on demand. In this way, there are fewer models that need to be maintained, especially when the project is started, they can be used directly for research. If further fine-tuning is necessary, the amount of data required is also greatly reduced.
2. How to pre-train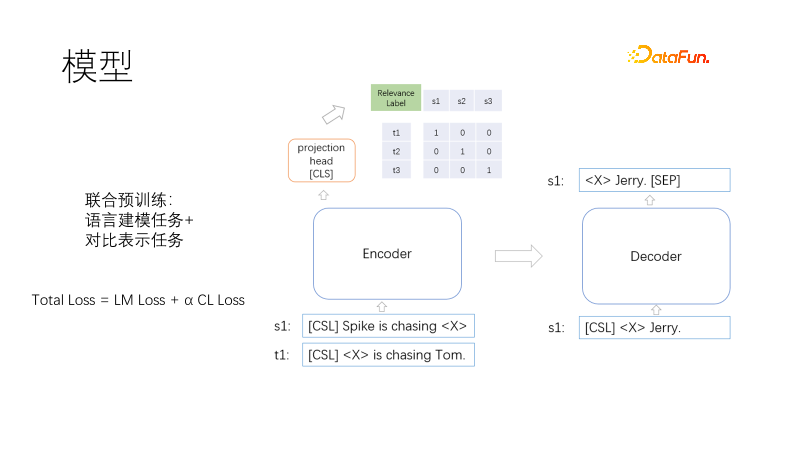
The goals of pre-training include language modeling and contrastive representation. The loss function is Total Loss = LM Loss α CL Loss. The language modeling task and the contrastive representation task are jointly trained, where α represents the weight coefficient. . Language modeling uses a mask model, similar to T5, which only decodes the mask part. The contrastive representation task is similar to CLIP. Within a batch, there is a pair of related training positive samples and other non-negative samples. For each sample pair (i, I) i, there is a positive sample I and the other samples are negative samples. , using symmetric cross-entropy loss to force the representation of positive samples to be close and the representation of negative samples to be far apart. Using T5 decoding can shorten the decoding length. A non-linear vector representation is placed above the head loading encoder. One is that the vector representation is required to be faster in the scenario, and the other is that the two shown functions act far away to prevent training target conflicts. So here comes the question. Cloze tasks are very common and do not require samples. So how do similar sample pairs come from? 
Of course, as a pre-training method, the sample pairs must be mined by an unsupervised algorithm. Usually, the basic method used to mine positive samples in the field of information retrieval is reverse cloze, which mines several fragments in a document and assumes that they are related. Here we split the document into sentences and then enumerate the sentence pairs. We use the longest common substring to determine whether two sentences are related. As shown in the figure, two positive and negative sentence pairs are taken. If the longest common substring is long enough to a certain extent, it is judged to be similar, otherwise it is not similar. The threshold is chosen by yourself. For example, a long sentence requires three Chinese characters, and more English letters are required. A short sentence can be more relaxed.
#We use correlation as the sample pair instead of semantic equivalence because the two goals are conflicting. As shown in the figure above, the meanings of cat catching mouse and mouse catching cat are opposite but related. Our scenario search is mainly focused on relevance. Moreover, correlation is broader than semantic equivalence, and semantic equivalence is more suitable for continued fine-tuning based on correlation.
#Some sentences are filtered multiple times, and some sentences are not filtered. We limit the frequency of sentences being selected. For the unsuccessful sentences, they can be copied as positive samples, spliced into the selected sentences, or reverse cloze can be used as positive samples.
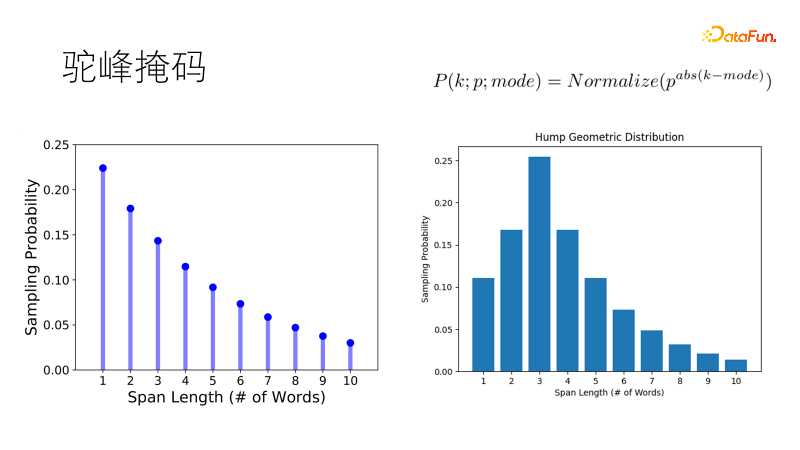
Traditional masking methods such as SpanBert use geometric distribution to sample mask lengths. Short masks have a higher probability, and longer masks have a higher probability. The masking probability is low and suitable for long sentences. But our corpus is fragmented. When faced with short sentences of one to twenty words, the traditional tendency is to mask two single words rather than one double word, which does not meet our expectations. So we improved this distribution so that it has the highest probability of sampling the optimal length, and the probability of other lengths gradually decreases, just like a camel's hump, becoming a camel-hump geometric distribution, which is more robust in our short sentence-rich scenarios.
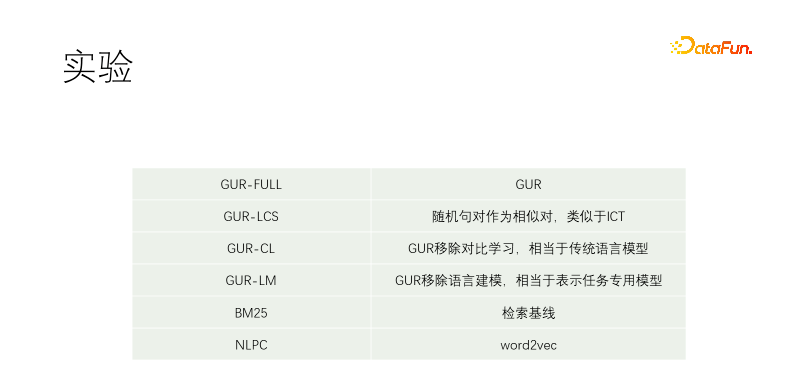
We conducted a controlled experiment. Including GUR-FULL, which uses language modeling and vector contrastive representation; UR-LCS sample pairs are not filtered by LCS; UR-CL does not have contrastive representation learning, which is equivalent to a traditional language model; GUR-LM only has vector contrastive representation learning , without language modeling learning, is equivalent to fine-tuning specifically for downstream tasks; NLPC is a word2vec operator in Baidu.
#The experiment starts from a T5-small and continues pre-training. Training corpora include Wikipedia, Wikisource, CSL and our own corpora. Our own corpus is captured from the material library, and the quality is very poor. The best quality part is the title of the material library. Therefore, when digging for positive samples in other documents, almost any text pair is screened, while in our corpus, the title is used to match every sentence of the text. GUR-LCS has not been selected by LCS. If it is not done this way, the sample pair will be too bad. If it is done this way, the difference with GUR-FULL will be much smaller.
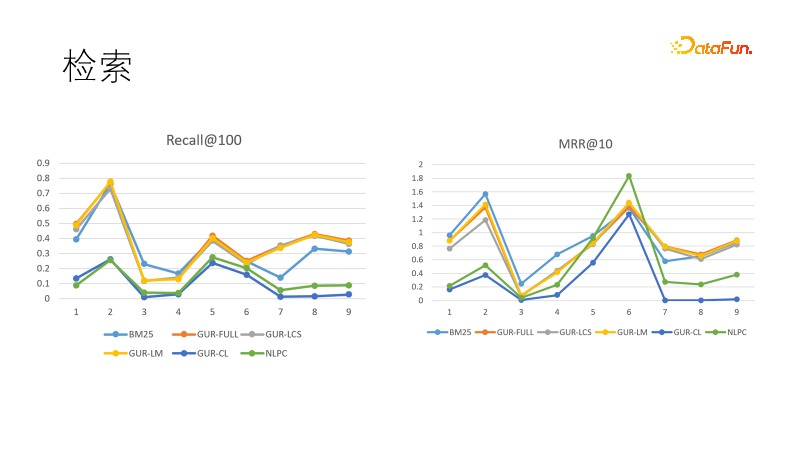
We evaluate the vector representation effect of the model on several retrieval tasks. The picture on the left shows the performance of several models in recall. We found that the models learned through vector representation performed best, outperforming BM25. We also compared ranking targets, and this time BM25 came back to win. This shows that the dense model has strong generalization ability and the sparse model has strong determinism, and the two can complement each other. In fact, in downstream tasks in the field of information retrieval, dense models and sparse models are often used together.
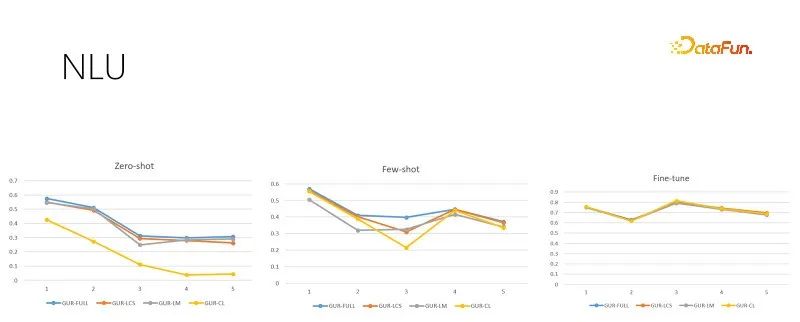
The above picture shows the NLU evaluation tasks with different training sample sizes. Each task has There are dozens to hundreds of categories, and the effect is evaluated by ACC score. The GUR model also converts the classification labels into vectors to find the nearest label for each sentence. The above figure from left to right shows zero sample, small sample and sufficient fine-tuning evaluation according to the increasing training sample size. The picture on the right is the model performance after sufficient fine-tuning, which shows the difficulty of each sub-task and is also the ceiling of zero-sample and small-sample performance. It can be seen that the GUR model can achieve zero-sample reasoning in some classification tasks by relying on vector representation. And the small sample capability of the GUR model is the most outstanding.
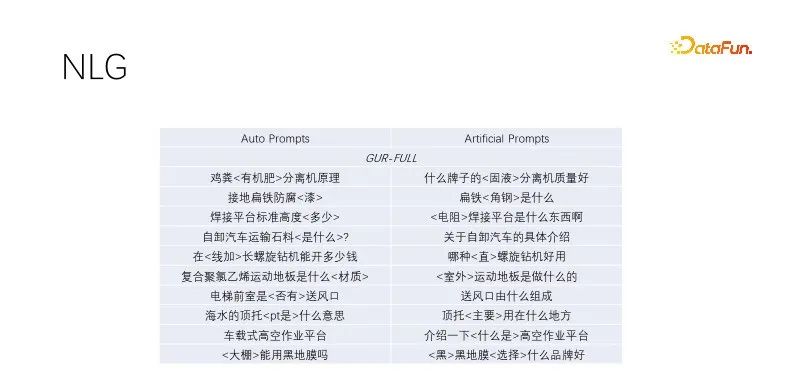
This is a zero-sample performance in NLG. When we are doing title generation and query expansion, we mine titles with high-quality traffic, retain keywords, and randomly mask non-keywords. The models trained by language modeling perform well. This automatic prompt effect is similar to the manually constructed target effect, with wider diversity and capable of meeting mass production. Several models that have undergone language modeling tasks perform similarly. The above figure uses the GUR model example.
This article proposes a new pre-training paradigm. The above control experiments show that, Joint training does not create a conflict of objectives. When the GUR model continues to be pre-trained, it can increase its vector representation capabilities while maintaining its language modeling capabilities. Pre-training once, inference with zero original samples everywhere. Suitable for low-cost pre-training for business departments.

The above link records our training details. For reference details, please see the paper citation and code The version is slightly newer than the paper. I hope to make a small contribution to the democratization of AI. Large and small models have their own application scenarios. In addition to being directly used for downstream tasks, the GUR model can also be used in combination with large models. In the pipeline, we first use the small model for recognition and then use the large model to instruct the task. The large model can also produce samples for the small model, and the GUR small model can provide vector retrieval for the large model.
The model in the paper is a small model selected to explore multiple experiments. In practice, the gain is obvious if a larger model is selected. Our exploration is not enough and further work is needed. If you are willing, you can contact laohur@gmail.com and look forward to making progress together with everyone.
The above is the detailed content of Poverty prepares me. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



