

Google이 홍보하는 JAX는 최근 벤치마크 테스트에서 Pytorch와 TensorFlow를 제치고 7개 지표에서 1위를 차지했습니다.

그리고 JAX 성능이 가장 좋은 TPU에서는 테스트가 진행되지 않았습니다.

현재 개발자들 사이에서는 여전히 Pytorch가 Tensorflow보다 더 인기가 있지만.
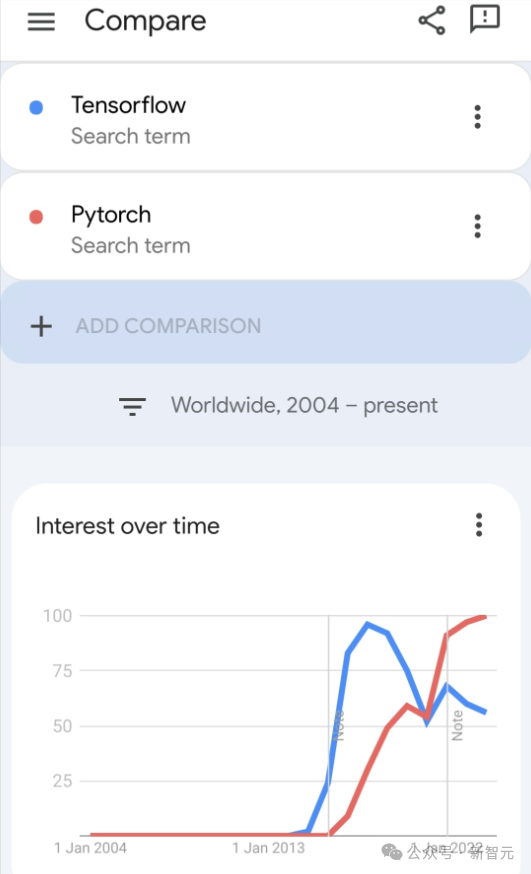
그러나 앞으로는 더 많은 대형 모델이 JAX 플랫폼을 기반으로 훈련되고 실행될 것입니다.
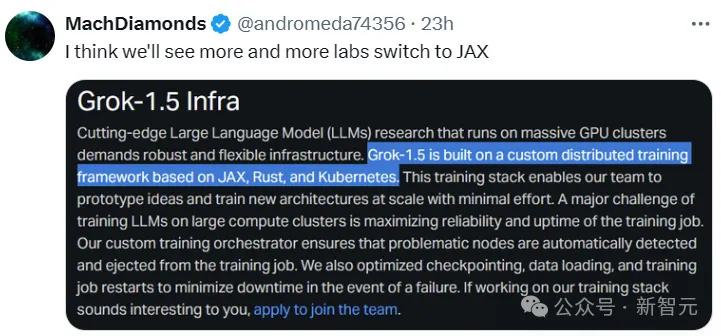
최근 Keras 팀은 기본 PyTorch 구현을 사용하는 세 가지 백엔드(TensorFlow, JAX, PyTorch)와 TensorFlow를 사용하는 Keras 2에 대한 벤치마크를 실시했습니다.
먼저 생성 및 비생성 인공 지능 작업을 위한 주류 컴퓨터 비전 및 자연어 처리 모델 세트를 선택했습니다.

모델의 Keras 버전에는 KerasCV 및 KerasNLP 빌드를 채택했습니다. 기존 구현에 대해. 기본 PyTorch 버전의 경우 인터넷에서 가장 인기 있는 옵션을 선택했습니다.
- HuggingFace Transformers의 BERT, Gemma, Mistral
- HuggingFace Diffusers의 StableDiffusion
- SegmentAnything from Meta
그들은 PyTorch 백엔드를 사용하는 Keras 3 버전과 구별하기 위해 이 모델 세트를 "Native PyTorch"라고 부릅니다.
모든 벤치마크에 합성 데이터를 사용했고 모든 LLM 교육 및 추론에 bfloat16 정밀도를 사용했으며 모든 LLM 교육에는 LoRA(미세 조정)를 사용했습니다.
PyTorch 팀의 제안에 따라 그들은 기본 PyTorch 구현에서 torch.compile(model, mode="reduce-overhead")를 사용했습니다(비호환성으로 인한 Gemma 및 Mistral 교육 제외).
기본 성능을 측정하기 위해 그들은 가능한 한 최소한의 구성으로 높은 수준의 API(예: HuggingFace의 Trainer(), 표준 PyTorch 훈련 루프 및 Keras model.fit())를 사용합니다.
모든 벤치마크 테스트는 40GB 비디오 메모리, 12개의 가상 CPU 및 85GB 호스트 메모리를 갖춘 NVIDIA A100 GPU로 구성된 Google Cloud Compute Engine을 사용하여 수행되었습니다.
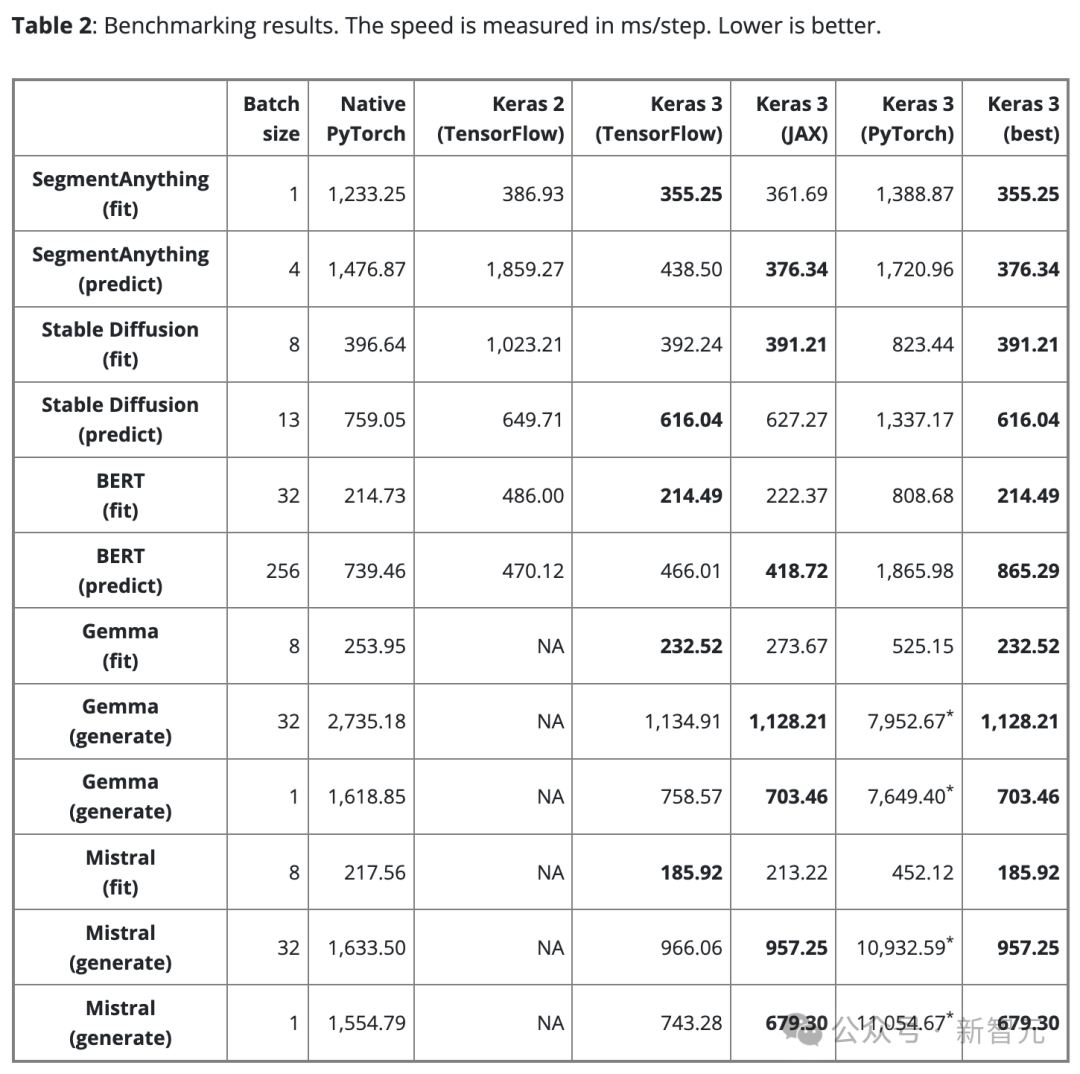
표 2는 벤치마크 결과를 steps/ms 단위로 보여줍니다. 각 단계에는 단일 데이터 배치에 대한 훈련 또는 예측이 포함됩니다.
결과는 100단계 평균이지만, 첫 번째 단계에는 모델 생성 및 컴파일이 포함되어 추가 시간이 소요되므로 첫 번째 단계는 제외됩니다.
공정한 비교를 보장하기 위해 동일한 모델 및 작업(훈련이든 추론이든)에 동일한 배치 크기가 사용됩니다.
다양한 모델과 작업의 경우 규모와 아키텍처가 다르기 때문에 필요에 따라 데이터 배치 크기를 조정하여 너무 큰 배치로 인한 메모리 오버플로 또는 너무 작은 배치 부족으로 인한 GPU 사용량을 방지할 수 있습니다.
배치 크기가 너무 작으면 Python 오버헤드가 증가하므로 PyTorch가 느리게 나타날 수도 있습니다.
대규모 언어 모델(Gemma 및 Mistral)의 경우 유사한 수의 매개변수(7B)를 가진 동일한 유형의 모델이므로 테스트 시 동일한 배치 크기도 사용되었습니다.
단일 배치 텍스트 생성에 대한 사용자 요구를 고려하여 배치 크기 1로 텍스트 생성에 대한 벤치마크 테스트도 수행했습니다.
Discovery 1
"최적" 백엔드는 없습니다.
Keras의 세 가지 백엔드는 각각 고유한 장점을 가지고 있습니다. 중요한 것은 성능 측면에서 어느 백엔드도 항상 승리할 수 없다는 것입니다.
가장 빠른 백엔드를 선택하는 것은 종종 모델의 아키텍처에 따라 달라집니다.
이 점은 최적의 성능을 추구하기 위해 다양한 프레임워크를 선택하는 것의 중요성을 강조합니다. Keras 3를 사용하면 백엔드를 쉽게 전환하여 모델에 가장 적합한 것을 찾을 수 있습니다.
Found 2
Keras 3는 일반적으로 PyTorch의 표준 구현보다 성능이 뛰어납니다.
기본 PyTorch에 비해 Keras 3는 처리량(단계/ms)이 크게 향상되었습니다.
특히 10개의 테스트 작업 중 5개에서 속도가 50% 이상 향상되었습니다. 그 중 최고치는 290%에 달했다.
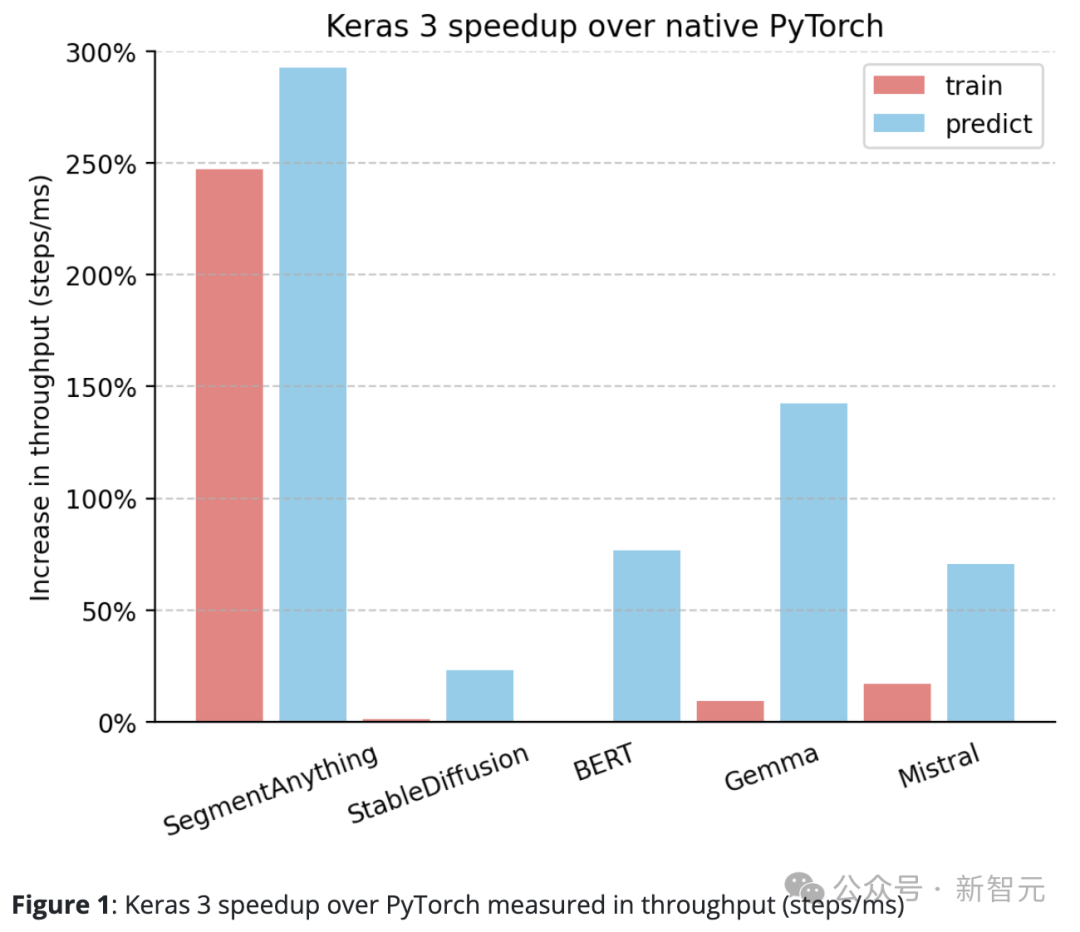
100%이면 Keras 3가 PyTorch보다 2배 빠르다는 뜻이고, 0%이면 둘의 성능이 동일하다는 뜻입니다
Discover 3
Keras 3는 동급 최고의 "즉시 사용 가능한" 성능을 제공합니다.
즉, 테스트에 참여한 모든 Keras 모델은 어떤 방식으로도 최적화되지 않았습니다. 대조적으로, 기본 PyTorch 구현을 사용할 때 사용자는 일반적으로 스스로 더 많은 성능 최적화를 수행해야 합니다.
위에 공유한 데이터 외에도 HuggingFace Diffusers의 StableDiffusion 추론 기능 성능이 버전 0.25.0에서 0.3.0으로 업그레이드할 때 100% 이상 증가한 것으로 테스트 중에 확인되었습니다.
마찬가지로 HuggingFace Transformers에서도 Gemma를 버전 4.38.1에서 4.38.2로 업그레이드하면 성능이 크게 향상되었습니다.
이러한 성능 개선은 HuggingFace의 성능 최적화에 대한 집중과 노력을 강조합니다.
SegmentAnything과 같이 수동 최적화가 덜한 일부 모델의 경우 연구 작성자가 제공한 구현이 사용됩니다. 이 경우 Keras와의 성능 격차는 대부분의 다른 모델보다 큽니다.
이는 Keras가 뛰어난 기본 성능을 제공할 수 있으며 사용자가 모든 최적화 기술을 탐구하지 않고도 빠른 모델 실행 속도를 즐길 수 있음을 보여줍니다.
Found 4
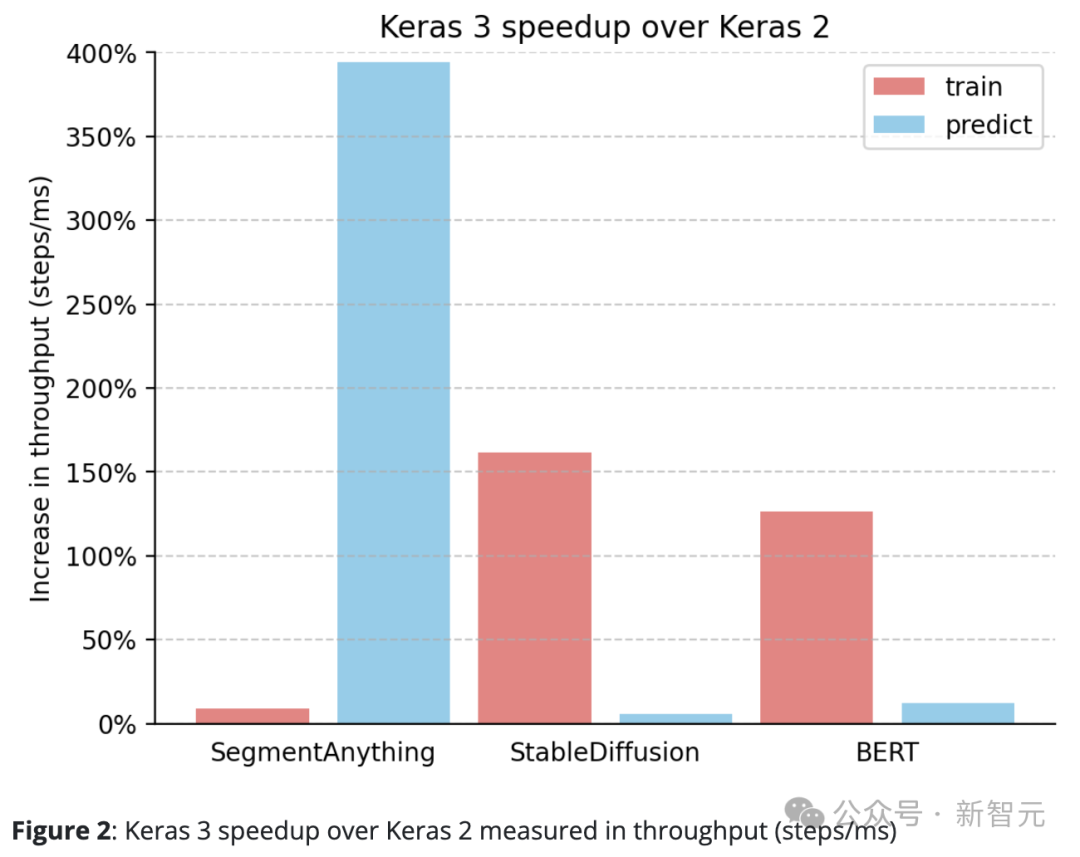
Keras 3는 지속적으로 Keras 2보다 성능이 뛰어납니다.
예를 들어 SegmentAnything의 추론 속도는 놀랍게도 380% 증가했고, StableDiffusion의 훈련 처리 속도는 150% 이상 증가했으며, BERT의 훈련 처리 속도도 100% 이상 증가했습니다.
이는 주로 Keras 2가 경우에 따라 더 많은 TensorFlow 융합 작업을 직접 사용하기 때문인데, 이는 XLA 컴파일에 최선의 선택이 아닐 수 있습니다.
Keras 3으로 업그레이드하고 TensorFlow 백엔드를 계속 사용하는 것만으로도 성능이 크게 향상되었다는 점은 주목할 가치가 있습니다.
프레임워크의 성능은 사용된 특정 모델에 따라 크게 달라집니다.
Keras 3는 작업에 가장 빠른 프레임워크를 선택하는 데 도움이 될 수 있으며, 이러한 선택은 거의 항상 Keras 2 및 PyTorch 구현보다 성능이 뛰어납니다.
더 중요한 것은 Keras 3 모델이 복잡한 기본 최적화 없이 뛰어난 기본 성능을 제공한다는 것입니다.
위 내용은 Google은 열광하고 있습니다. JAX 성능이 Pytorch와 TensorFlow를 능가합니다! GPU 추론 훈련을 위한 가장 빠른 선택이 될 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



