

2017년에 출판된 "Attention Is All You Need" 논문 이후 Transformer 아키텍처는 자연어 처리(NLP) 분야의 초석이 되었습니다. 디자인은 수년 동안 크게 변하지 않았으며, 2022년에는 RoPE(로터리 위치 인코딩)가 도입되면서 이 분야에서 큰 발전이 이루어졌습니다.
회전 위치 임베딩은 가장 발전된 NLP 위치 임베딩 기술입니다. Llama, Llama2, PaLM 및 CodeGen과 같은 가장 널리 사용되는 대규모 언어 모델에서는 이미 이를 사용하고 있습니다. 이 글에서는 회전 위치 인코딩이 무엇인지, 절대 위치 임베딩과 상대 위치 임베딩의 장점을 어떻게 깔끔하게 혼합하는지 자세히 살펴보겠습니다.
RoPE의 중요성을 이해하기 위해 먼저 위치 인코딩이 왜 중요한지 검토해 보겠습니다. Transformer 모델은 고유 설계에 따라 입력 토큰의 순서를 고려하지 않습니다.
예를 들어, "개가 돼지를 쫓는다", "돼지가 개를 쫓는다"와 같은 문구는 의미는 다르지만 순서가 지정되지 않은 토큰 세트로 간주되므로 구별할 수 없는 것으로 간주됩니다.시퀀스 정보와 그 의미를 유지하려면 위치 정보를 모델에 통합하는 표현이 필요합니다.
문장의 위치를 인코딩하려면 각 벡터가 문장의 위치를 나타내는 동일한 차원의 벡터를 사용하는 또 다른 도구가 필요합니다. 예를 들어 문장의 두 번째 단어에 대한 특정 벡터를 지정합니다. 따라서 각 문장 위치에는 고유한 벡터가 있습니다. 그런 다음 Transformer 계층에 대한 입력은 단어 임베딩과 해당 위치의 임베딩을 결합하여 형성됩니다.
이러한 임베딩을 생성하는 두 가지 주요 방법이 있습니다.
널리 사용되지만 절대 위치 임베딩에는 단점이 없는 것은 아닙니다.
상대 위치는 문장 내 음표의 절대 위치가 아니라 음표 쌍 사이의 거리에 초점을 맞춥니다. 이 방법은 위치 벡터를 단어 벡터에 직접 추가하지 않습니다. 대신, 상대 위치 정보를 통합하도록 주의 메커니즘이 변경됩니다.
T5(Text-to-Text Transfer Transformer)는 상대 위치 임베딩을 활용하는 유명한 모델입니다. T5는 위치 정보를 처리하는 미묘한 방법을 도입합니다.
이론적으로는 매력적이지만 상대 위치 인코딩은 매우 문제가 많습니다.
이러한 엔지니어링 복잡성으로 인해 위치 인코딩은 특히 대규모 언어 모델에서 널리 채택되지 않았습니다.
RoPE는 위치 정보를 인코딩하는 새로운 방식을 나타냅니다. 전통적인 방법의 절대법과 상대법 모두에는 한계가 있습니다. 절대 위치 인코딩은 각 위치에 고유한 벡터를 할당합니다. 이는 간단하지만 확장이 잘 되지 않으며 상대 위치를 효과적으로 캡처할 수 없습니다. 상대 위치 인코딩은 마커 간의 거리에 초점을 맞추고 마커 관계에 대한 모델의 이해를 향상시키지만 모델 아키텍처를 복잡하게 만듭니다. .
RoPE는 두 가지 장점을 교묘하게 결합합니다. 모델이 마커의 절대 위치와 상대 거리를 이해할 수 있도록 위치 정보를 인코딩합니다. 이는 시퀀스의 각 위치가 임베딩 공간의 회전으로 표시되는 회전 메커니즘을 통해 달성됩니다. RoPE의 우아함은 모델이 언어 구문과 의미의 뉘앙스를 더 잘 이해할 수 있도록 하는 단순성과 효율성에 있습니다.
회전행렬은 우리가 고등학교 때 배운 사인과 코사인의 삼각법적 성질에서 파생된 것인데, 2차원 행렬을 이용하면 아래와 같은 회전행렬의 이론을 얻기에 충분할 것입니다!
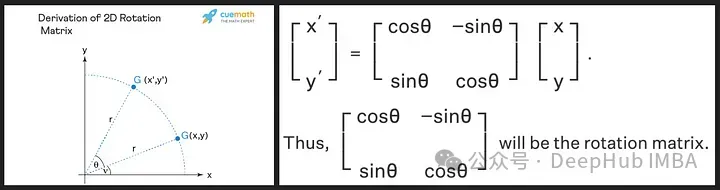
위 이미지에서 "r"로 표시된 것처럼 회전 행렬이 원래 벡터의 크기(또는 길이)를 유지하는 것을 볼 수 있습니다. 변경되는 유일한 것은 x축과의 각도입니다.
RoPE는 새로운 컨셉을 선보입니다. 위치 벡터를 추가하는 대신 단어 벡터에 회전을 적용합니다. 회전 각도(θ)는 문장에서 단어의 위치에 비례합니다. 첫 번째 위치의 벡터는 θ만큼 회전되고, 두 번째 위치의 벡터는 2θ만큼 회전되는 식입니다. 이 접근 방식에는 여러 가지 이점이 있습니다.
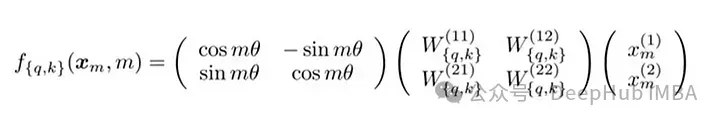
RoPE의 기술 구현에는 회전 행렬이 포함됩니다. 2D의 경우, 논문의 방정식에는 벡터를 Mθ만큼 회전시키는 회전 행렬이 포함되어 있습니다. 여기서 M은 문장의 절대 위치입니다. 이 회전은 Transformer의 self-attention 메커니즘에서 쿼리 벡터와 키 벡터에 적용됩니다.
더 높은 차원의 경우 벡터는 2D 블록으로 분할되고 각 쌍은 독립적으로 회전됩니다. 이는 n차원이 공간에서 회전하는 것으로 생각할 수 있습니다. 이 방법은 구현하기가 복잡해 보이지만 그렇지 않습니다. PyTorch와 같은 라이브러리에서는 약 10줄의 코드만으로 효율적으로 구현할 수 있습니다.
import torch import torch.nn as nn class RotaryPositionalEmbedding(nn.Module): def __init__(self, d_model, max_seq_len): super(RotaryPositionalEmbedding, self).__init__() # Create a rotation matrix. self.rotation_matrix = torch.zeros(d_model, d_model, device=torch.device("cuda")) for i in range(d_model): for j in range(d_model): self.rotation_matrix[i, j] = torch.cos(i * j * 0.01) # Create a positional embedding matrix. self.positional_embedding = torch.zeros(max_seq_len, d_model, device=torch.device("cuda")) for i in range(max_seq_len): for j in range(d_model): self.positional_embedding[i, j] = torch.cos(i * j * 0.01) def forward(self, x): """Args:x: A tensor of shape (batch_size, seq_len, d_model). Returns:A tensor of shape (batch_size, seq_len, d_model).""" # Add the positional embedding to the input tensor. x += self.positional_embedding # Apply the rotation matrix to the input tensor. x = torch.matmul(x, self.rotation_matrix) return x
为了旋转是通过简单的向量运算而不是矩阵乘法来执行。距离较近的单词更有可能具有较高的点积,而距离较远的单词则具有较低的点积,这反映了它们在给定上下文中的相对相关性。
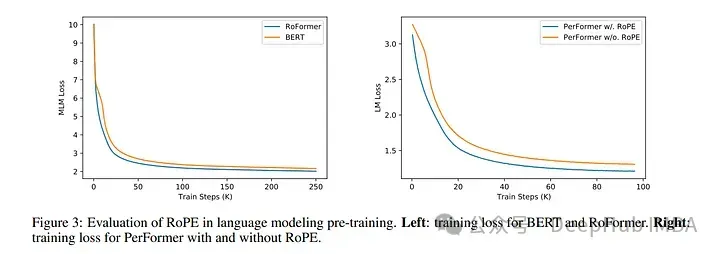
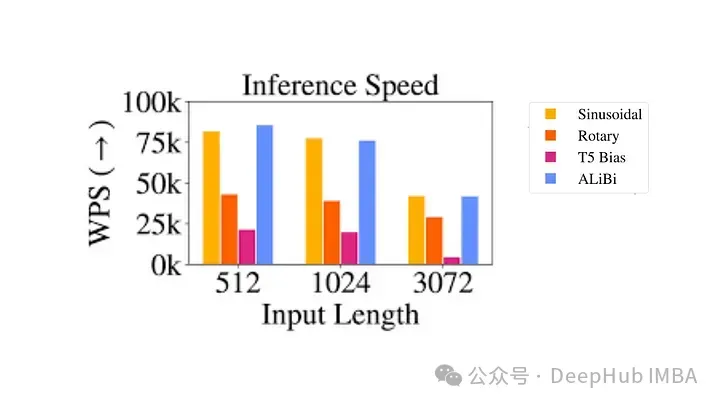
使用 RoPE 对 RoBERTa 和 Performer 等模型进行的实验表明,与正弦嵌入相比,它的训练时间更快。并且该方法在各种架构和训练设置中都很稳健。
最主要的是RoPE是可以外推的,也就是说可以直接处理任意长的问题。在最早的llamacpp项目中就有人通过线性插值RoPE扩张,在推理的时候直接通过线性插值将LLAMA的context由2k拓展到4k,并且性能没有下降,所以这也可以证明RoPE的有效性。
代码如下:
import transformers old_init = transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ def ntk_scaled_init(self, dim, max_position_embeddings=2048, base=10000, device=None): #The method is just these three linesmax_position_embeddings = 16384a = 8 #Alpha valuebase = base * a ** (dim / (dim-2)) #Base change formula old_init(self, dim, max_position_embeddings, base, device) transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ = ntk_scaled_init
旋转位置嵌入代表了 Transformer 架构的范式转变,提供了一种更稳健、直观和可扩展的位置信息编码方式。
RoPE不仅解决了LLM context过长之后引起的上下文无法关联问题,并且还提高了训练和推理的速度。这一进步不仅增强了当前的语言模型,还为 NLP 的未来创新奠定了基础。随着我们不断解开语言和人工智能的复杂性,像 RoPE 这样的方法将有助于构建更先进、更准确、更类人的语言处理系统。
위 내용은 대규모 언어 모델에서 흔히 사용되는 RoPE를 인코딩하는 회전 위치 인코딩에 대한 자세한 설명: 왜 절대 위치 인코딩이나 상대 위치 인코딩보다 나은가요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



