


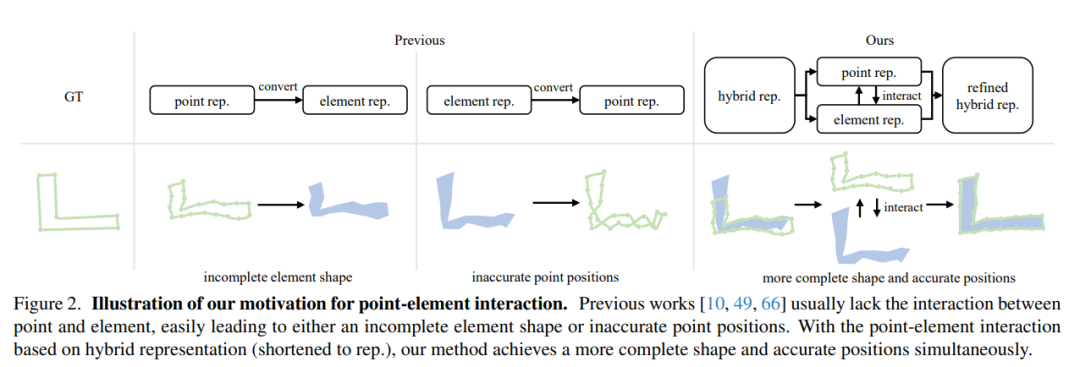
ベクトル化された高解像度 (HD) 地図の構築では、地図要素 (道路境界線、車線分離帯、横断歩道など) のカテゴリとポイント座標を予測する必要があります。最先端の方法は、主に、正確な点座標を回帰するための点レベルの表現学習に基づいています。ただし、このパイプラインには、要素レベルの情報を取得し、間違った要素の形状や要素間のもつれなどの要素レベルの障害を処理する際に制限があります。上記の問題を解決するために、この論文では、ポイントレベルおよび要素レベルの情報を完全に学習して対話するための、HIMap という名前のシンプルで効果的な HybrId フレームワークを提案します。
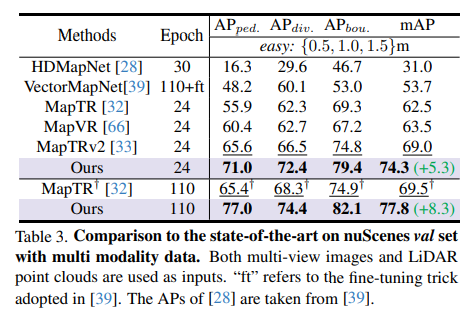
具体的には、すべての地図要素を表すために HIQuery と呼ばれるハイブリッド表現が導入され、点の位置や要素の形状などの要素のハイブリッド情報を対話的に抽出して HIQuery にエンコードする点要素インタラクターが提案されています。さらに、点レベルの情報と要素レベルの情報の間の一貫性を強化するために、点要素の一貫性制約も提案されています。最後に、統合された HIQuery の出力ポイント要素は、マップ要素のクラス、ポイント座標、およびマスクに直接変換できます。 nuScenes と Argoverse2 データセットに対して広範な実験が行われ、以前の方法よりも一貫して優れた結果が示されています。この方法は nuScenes データセットで 77.8mAP を達成しており、これは以前の SOTA よりも少なくとも 8.3mAP 大幅に優れていることは注目に値します。
論文名: HIMap: エンドツーエンドのベクトル化 HD マップ構築のための HybrId 表現学習
論文リンク: https://arxiv.org/pdf/2403.08639.pdf
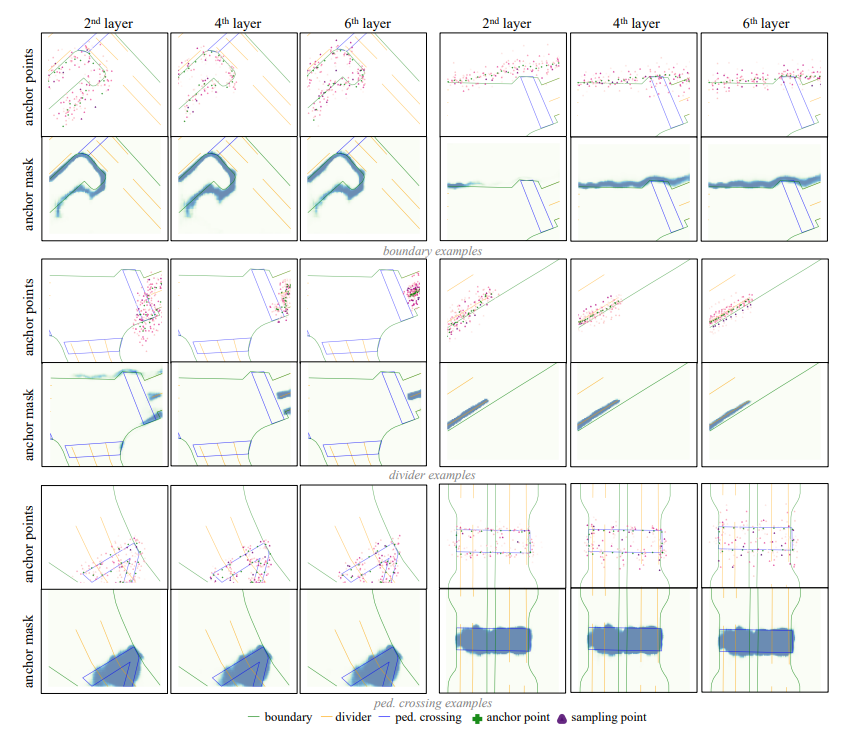
HIMap では、まず、マップ内のすべてのマップ要素を表す HIQuery と呼ばれるハイブリッド表現が導入されます。これは、BEV 機能と対話することで繰り返し更新および調整できる学習可能なパラメーターのセットです。次に、マップ要素のハイブリッド情報 (ポイントの位置、要素の形状など) を HIQuery にエンコードし、ポイント要素の相互作用を実行するように、マルチレイヤー ハイブリッド デコーダーが設計されています (図 2 を参照)。ハイブリッド デコーダの各層には、ポイント要素インタラクター、セルフ アテンション、FFN が含まれます。点要素インタラクターの内部には、点レベルと要素レベルの情報の交換を実現し、単一レベル情報の学習バイアスを回避するための相互作用メカニズムが実装されています。最後に、統合された HIQuery の出力ポイント要素は、要素のポイント座標、クラス、マスクに直接変換できます。さらに、点レベルの情報と要素レベルの情報の間の一貫性を強化するために、点要素の一貫性制約も提案されています。
HIMap の全体的なプロセスを図 3(a) に示します。 HIMap は、マルチビュー カメラからの RGB 画像、LIDAR からの点群、マルチモーダル データなど、さまざまな航空センサー データと互換性があります。ここでは、HIMap がどのように機能するかを説明するために、マルチビュー RGB 画像を例に挙げます。
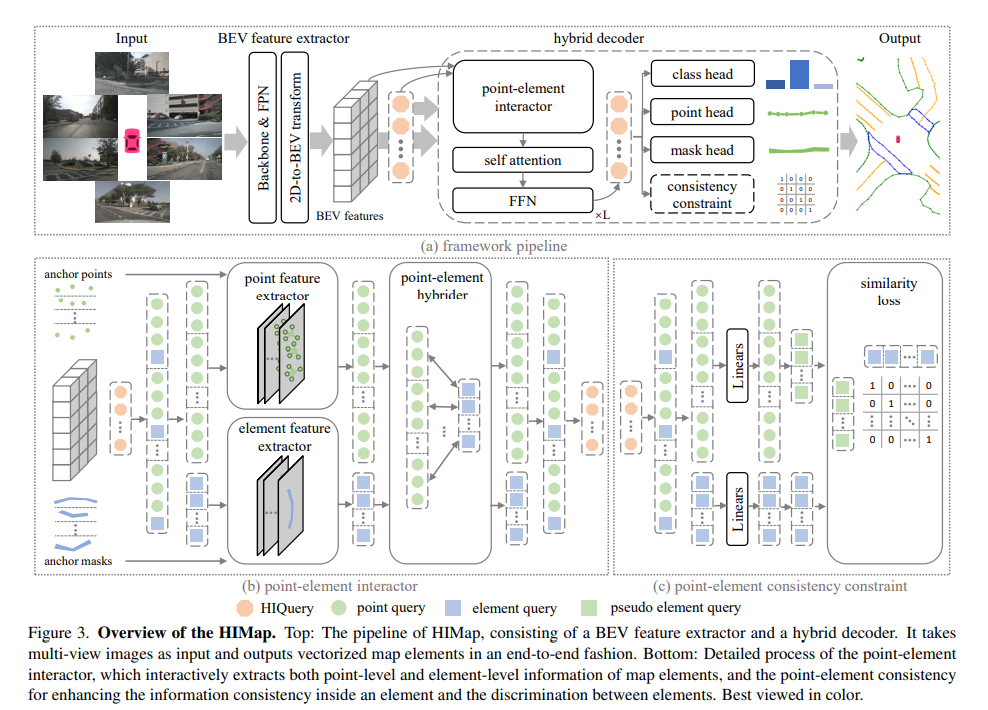
BEV 特徴抽出ツールは、マルチビュー RGB 画像から BEV 特徴を抽出するツールです。そのコアには、各視点からマルチスケール 2D フィーチャのバックボーン部分を抽出すること、マルチスケール フィーチャを融合および洗練することによって単一スケール フィーチャの FPN 部分を取得すること、および 2D から BEV フィーチャへの変換モジュールを利用して 2D フィーチャを BEV にマッピングすることが含まれます。特徴。 。このプロセスは、画像情報を処理と分析により適した BEV 特徴に変換するのに役立ち、特徴の使いやすさと精度が向上します。この手法により、多視点画像の情報をより深く理解して活用することができ、その後のデータ処理や意思決定をより強力にサポートします。
HIQuery: 地図要素のポイントレベルおよび要素レベルの情報を完全に学習するために、地図内のすべての要素を表す HIQuery が導入されました。
ハイブリッド デコーダ: ハイブリッド デコーダは、HIQuery Qh と BEV 機能 X を反復的に対話させることによって、統合された HIQuery を生成します。
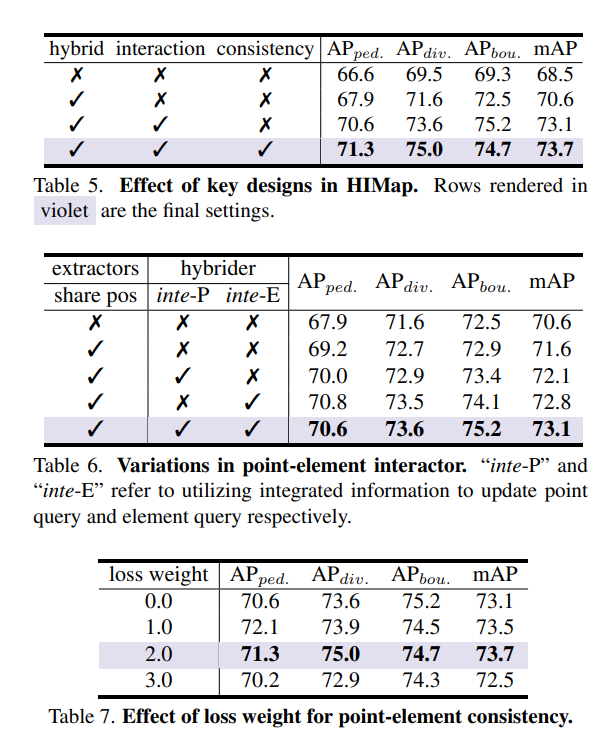
ポイント要素インタラクターの目標は、マップ要素のポイントレベルおよび要素レベルの情報を対話的に抽出し、それを HIQuery にエンコードすることです。 2 つのレベルの情報の相互作用の動機は、それらの相補性から生じます。ポイントレベルの情報にはローカルな位置の知識が含まれ、要素レベルの情報にはグローバルな形状と意味論的な知識が含まれます。したがって、この相互作用により、マップ要素のローカルおよびグローバル情報の相互改良が可能になります。
それぞれ局所的な情報と全体的な情報に焦点を当てた点レベルの表現と要素レベルの表現の間の元々の違いを考慮すると、2 つのレベルの表現の学習は相互に干渉する可能性もあります。これにより、情報のやり取りが難しくなり、情報のやり取りの有効性が低下します。そこで、点要素整合性制約を導入することで、各点レベルと要素レベル情報との整合性を高め、要素の識別性も高めることができます!
この論文では、NuScenes データセットと Argoverse2 データセットで実験を行いました。
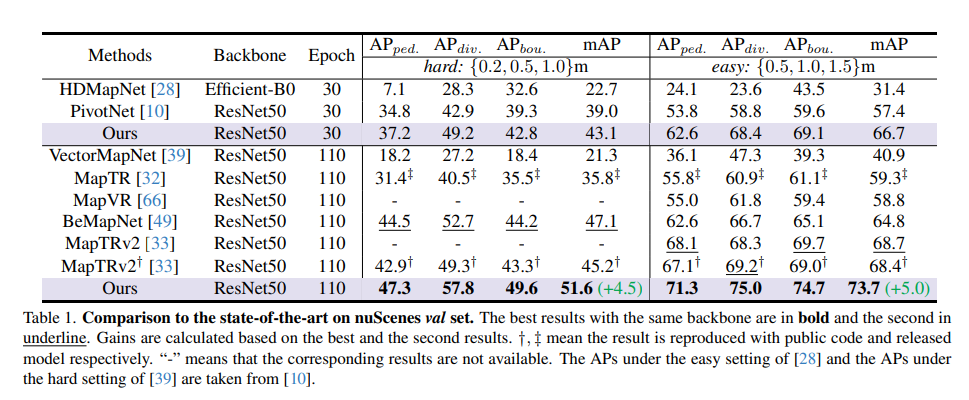
nuScenes val-set での SOTA モデルの比較:
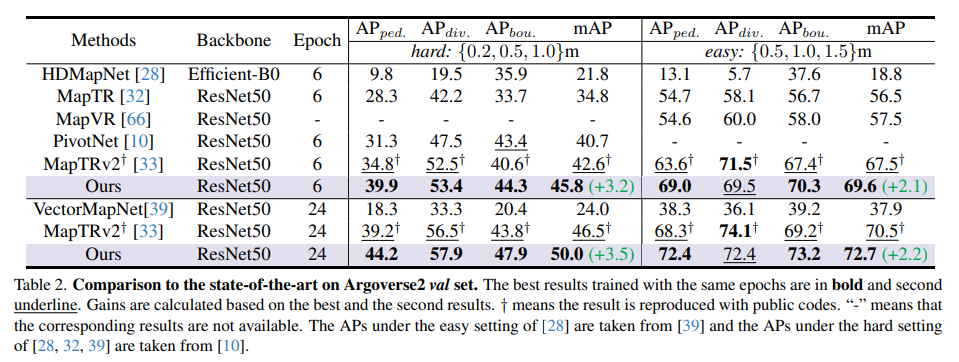
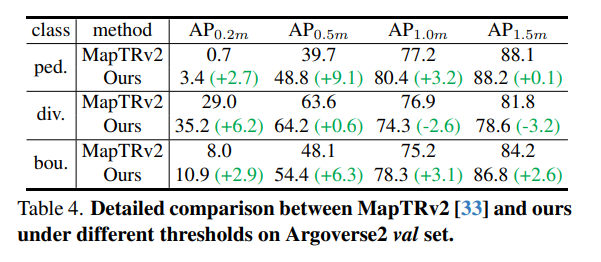
Argoverse2 val-set での SOTA モデルの比較:
nuScenes 検証セットのマルチモーダル データでの SOTA モデルとの比較:

以上がすべての方法よりも優れています! HIMap: エンドツーエンドのベクトル化された HD マップ構築の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



