


少し前まで、OpenAI Sora はその驚くべきビデオ生成効果で急速に人気を博し、数ある Wensheng ビデオ モデルの中でも際立って世界的な注目を集めました。 2 週間前にコストを 46% 削減した Sora トレーニング推論再現プロセスの開始に続き、Colossal-AI チームは、トレーニング プロセス全体をカバーする世界初の Sora のようなアーキテクチャのビデオ生成モデル「Open-Sora 1.0」を完全にオープンソース化しました。 、データ処理、すべてのトレーニングの詳細、モデルの重みを含む、世界中の AI 愛好家と協力して、ビデオ作成の新時代を促進します。
まずは、Colossal-AI チームがリリースした「Open-Sora 1.0」モデルによって生成されたにぎやかな都市のビデオを見てみましょう。

Open-Sora 1.0 によって生成された賑やかな都市のスナップショット
これは Sora の再現の氷山の一角にすぎません上記の記事について ビデオ モデル アーキテクチャ、トレーニングされたモデルの重み、すべての繰り返しトレーニングの詳細、データの前処理プロセス、デモの表示と詳細な入門チュートリアル、Colossal-AI チームは GitHub で無料で完全にオープンソース化されており、著者できるだけ早く会社に連絡しました。チームは、今後も Open-Sora 関連のソリューションと最新の開発情報を更新し続けることを理解しています。興味のある友人は、引き続き Open-Sora のオープン ソース コミュニティにご注目ください。
Open-Sora オープンソース アドレス: https://github.com/hpcaitech/Open-Sora
次に、モデル アーキテクチャ設計、トレーニング方法、データ前処理、モデル効果の表示、最適化されたトレーニング戦略など、Sora のレプリケーション ソリューションのいくつかの重要な側面を詳しく掘り下げていきます。
モデルは、現在一般的な拡散トランス (DiT) [1] アーキテクチャを採用しています。著者チームは、やはりDiTアーキテクチャをベースとした高品質なオープンソースのヴィンセントグラフモデルPixArt-α[2]を使用し、これをベースに時間的注意層を導入し、ビデオデータまで拡張しています。具体的には、アーキテクチャ全体には、事前トレーニングされた VAE、テキスト エンコーダー、および時空間アテンション メカニズムを利用する STDiT (空間時間拡散変換器) モデルが含まれています。このうち、STDiTの各層の構造を下図に示します。シリアル手法を使用して、1 次元の時間的注意モジュールを 2 次元の空間的注意モジュールに重ねて、時間関係をモデル化します。時間的注意モジュールの後に、クロス注意モジュールを使用してテキストの意味を調整します。フル アテンション メカニズムと比較して、このような構造はトレーニングと推論のオーバーヘッドを大幅に削減します。同様に時空間注意メカニズムを使用する Latte [3] モデルと比較して、STDiT は、事前トレーニングされた画像 DiT の重みをより適切に利用して、ビデオ データのトレーニングを継続できます。
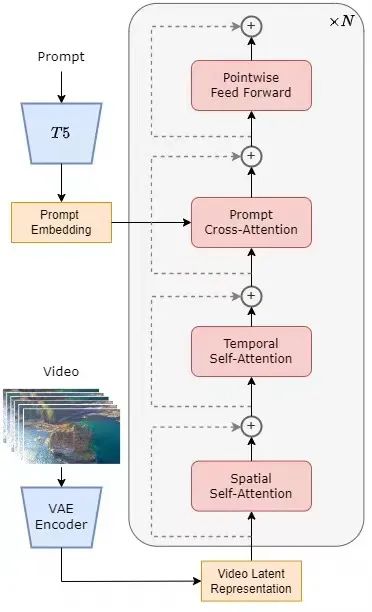
#STDiT 構造図
モデル全体のトレーニングと推論のプロセスは次のとおりです。トレーニング段階では、まず事前トレーニングされた変分オートエンコーダー (VAE) エンコーダーを使用してビデオ データを圧縮し、次に STDiT 拡散モデルが圧縮された潜在空間に埋め込まれたテキストとともにトレーニングされることが理解されています。推論段階では、VAE の潜在空間からガウス ノイズがランダムにサンプリングされ、プロンプト埋め込みとともに STDiT に入力されてノイズ除去された特徴が取得され、最後に VAE のデコーダに入力されてデコードされてビデオが取得されます。

モデルのトレーニング プロセス
チームは、Open-Sora の再発計画が Stable Video Diffusion (SVD)[3] 作業に言及しており、次の 3 つの段階を含んでいることを知りました。トレーニング。
#トレーニング計画の 3 つのフェーズ

最初のステージでは、大規模な画像の事前トレーニングと成熟したヴィンセント グラフ モデルを使用して、ビデオの事前トレーニングのコストを効果的に削減します。
#第 2 段階: 大規模なビデオ事前トレーニング
第 2 段階では、大規模なビデオ事前トレーニングを実行してモデルを増やします一般化能力、ビデオの時系列相関を効果的にマスターします。
#第 3 段階: 高品質ビデオ データの微調整
第 3 段階では、高品質ビデオ データを微調整して大幅に改善します。ビデオ生成の品質。
著者チームは、Open-Sora の再現プロセスで、トレーニングに 64 個の H800 ブロックを使用したと述べています。第 2 段階の合計トレーニング量は 2808 GPU 時間で、約 7000 ドル、第 3 段階のトレーニング量は 1920 GPU 時間で、約 4500 ドルです。予備的な見積もりの後、トレーニング プログラム全体で Open-Sora の再生プロセスを約 10,000 米ドルに抑えることに成功しました。
Sora 再現のしきい値と複雑さをさらに軽減するために、Colossal-AI チームは便利なビデオ データも提供します。前処理スクリプトを使用すると、公開ビデオ データ セットのダウンロード、ショットの連続性に基づいて長いビデオを短いビデオ クリップに分割すること、オープン ソースの大規模言語モデル LLaVA [7] を使用して詳細なプロンプト ワードを生成することなど、Sora 再帰事前トレーニングを簡単に開始できます。著者チームは、提供したバッチビデオタイトル生成コードは 2 枚のカードと 3 秒のビデオに注釈を付けることができ、品質は GPT-4V に近いと述べました。結果として得られるビデオとテキストのペアは、トレーニングに直接使用できます。 GitHub で提供されるオープン ソース コードを使用すると、独自のデータ セットでのトレーニングに必要なビデオとテキストのペアを簡単かつ迅速に生成できるため、Sora レプリケーション プロジェクトを開始するための技術的なしきい値と事前準備が大幅に軽減されます。

#データ前処理スクリプトに基づいて自動生成されたビデオ/テキストのペア
Open-Sora による実際のビデオ生成効果を見てみましょう。たとえば、Open-Sora で、崖の海岸の岩に打ち寄せる海水の空撮ショットを生成してみましょう。

Open-Sora で、崖から勢いよく流れ落ち、最後には湖に流れ込む山や滝の雄大な空撮を撮影しましょう。

# 空に行くだけでなく、海にも入ることができます。プロンプトを入力して Open-Sora にショットを生成させます。アンダーウォーターワールド。ショットでは、サンゴ礁にカメがいます。ゆっくりとクルーズします。

Open-Sora では、タイムラプス撮影を通じて星がきらめく天の川も見せてくれます。

ビデオ生成に関するさらに興味深いアイデアがある場合は、Open-Sora オープン ソース コミュニティにアクセスして、無料体験としてモデルの重みを取得できます。リンク: https://github.com/hpcaitech/Open-Sora
作者チームが Github で、現在のバージョンでは 400K のトレーニング データのみを使用していると述べたことは注目に値します。モデル 生成品質とテキストを追跡する能力の両方を改善する必要があります。たとえば、上のカメのビデオでは、結果のカメに余分な足が付いています。 Open-Sora 1.0 は、ポートレートや複雑な画像の生成も苦手です。著者チームは、既存の欠陥を継続的に解決し、制作の品質を向上させることを目的として、Github 上で実行される一連の計画をリストしました。
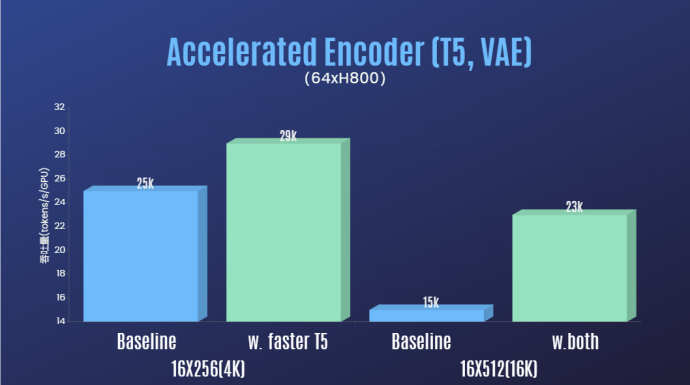
Sora 再現の技術的閾値を大幅に下げ、再生時間、解像度、コンテンツなどの多面的なビデオ生成の品質を向上させることに加えて、著者は、チームはまた、Colossal-AI 加速システムを提供し、Sora 再発の効率的なトレーニング サポートを提供します。オペレーターの最適化やハイブリッド並列処理などの効率的なトレーニング戦略により、64 フレーム、解像度 512x512 のビデオを処理するトレーニングで 1.55 倍の高速化効果が達成されました。同時に、Colossal-AI の異種メモリ管理システムのおかげで、1 分間の 1080p 高解像度ビデオ トレーニング タスクを単一のサーバー (8*H800) で支障なく実行できます。
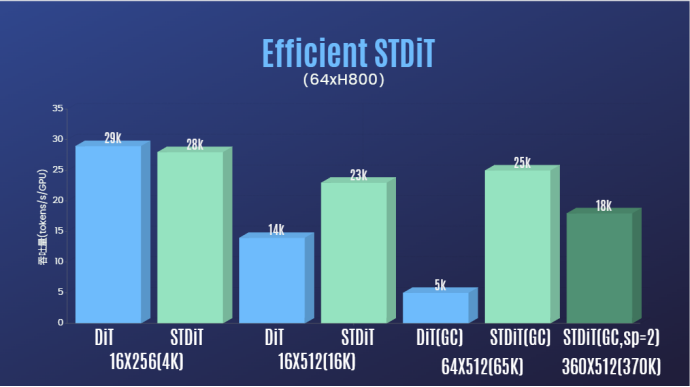
さらに、著者チームのレポートでは、STDiT モデル アーキテクチャがトレーニング中に優れた効率を示していることもわかりました。フル アテンション メカニズムを使用する DiT と比較して、STDiT はフレーム数の増加に応じて最大 5 倍の高速化を実現します。これは、長いビデオ シーケンスの処理などの現実のタスクでは特に重要です。
#Open-Sora オープン ソース プロジェクトにご注目ください: https://github.com/hpcaitech/Open-Sora
著者チームは、Open-Sora プロジェクトの維持と最適化を継続し、より多くのビデオ トレーニング データを使用して、より高品質で長いビデオ コンテンツを生成し、マルチ解像度機能をサポートすることが期待されていると述べています。映画、ゲーム、広告などの分野へのAI技術の導入を効果的に推進します。
参考リンク:
[1] https://arxiv.org/abs/2212.09748 変圧器を使用したスケーラブルな拡散モデル。
[2] https://arxiv.org/abs/2310.00426 PixArt-α: フォトリアリスティックなテキストから画像への合成のための拡散トランスフォーマーの高速トレーニング。
[3] https://arxiv.org/abs/2311.15127 安定したビデオ拡散: 潜在ビデオ拡散モデルを大規模なデータセットに拡張します。
[4] https://arxiv.org/abs/2401.03048 Latte: ビデオ生成用の潜在拡散トランスフォーマー。
[5] https://huggingface.co/stabilityai/sd-vae-ft-mse-original。
[6] https://github.com/google-research/text-to-text-transfer-transformer。
[7] https://github.com/haotian-liu/LLaVA。
[8] https://hpc-ai.com/blog/open-sora-v1.0。
以上がOpenAI を待つのではなく、Open-Sora が完全にオープンソースになるのを待ちましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



