


世界初のオープンソースのSora風建築ビデオ生成モデルが登場!
データ処理、すべてのトレーニングの詳細、モデルの重みを含むトレーニング プロセス全体はすべてオープンです。
これは、リリースされたばかりの Open-Sora 1.0 です。
実際の効果は以下の通りで、繁華街の夜景に賑わいを生み出すことができます。

航空写真の視点を使用して、崖の海岸と岩に打ち寄せる海水のシーンを表示することもできます。

または、タイムラプス撮影による広大な星空。

Sora のリリース以来、Sora の公開と再作成は、その驚くべき効果と技術的な詳細の不足により、開発コミュニティで最も話題になるトピックの 1 つとなっています。たとえば、Colossal-AI チームは、コストを 46% 削減できる Sora のトレーニングと推論の複製プロセスを開始しました。
わずか 2 週間後、チームは再び最新の進捗状況をリリースし、Sora のようなソリューションを再現し、技術ソリューションと詳細なチュートリアルを GitHub で無料でオープンソースにしました。
そこで問題は、ソラをどのように再現するかということです。
Open-Sora オープン ソース アドレス: https://github.com/hpcaitech/Open-Sora
Sora 再発計画には以下が含まれます4 つの側面:
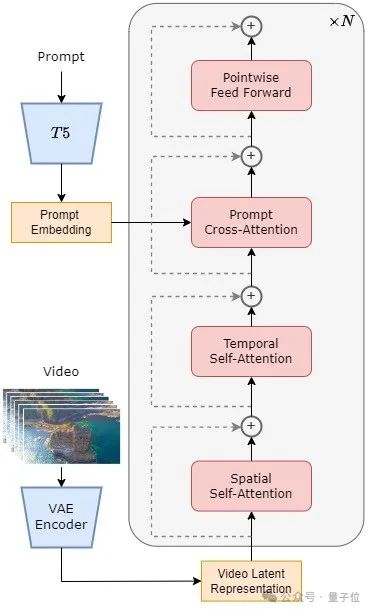 #△STDiT 構造図
#△STDiT 構造図モデル全体の学習と推論のプロセスは次のとおりです。
トレーニング段階では、まず事前トレーニングされた変分オートエンコーダー (VAE) エンコーダーを使用してビデオ データを圧縮し、次に STDiT が圧縮された潜在空間に埋め込まれたテキストとともにトレーニングされることが理解されています。モデル。
推論段階では、ガウス ノイズが VAE の潜在空間からランダムにサンプリングされ、プロンプト エンベディングとともに STDiT に入力されてノイズ除去された特徴が取得され、最後に VAE デコード プロセッサに入力されてデコードされて、ビデオ。

△モデルトレーニングプロセス
トレーニング再現部分では、Open-Sora は Stable Video Diffusion (SVD) を指します。
これは 3 つのステージに分かれています:
各ステージでは、前のステージの重みに基づいてトレーニングを継続します。
ゼロからの単一ステージのトレーニングと比較して、マルチステージ トレーニングでは、データを段階的に拡張することで、高品質のビデオ生成という目標をより効率的に達成します。


公開ビデオ データ セットのダウンロード、ショットの連続性に基づいて長いビデオを短いビデオ クリップに分割すること、オープンソースの大規模言語モデル LLaVA を使用して正確なプロンプト ワードを生成することが含まれます。
同社が提供するバッチビデオタイトル生成コードは、ビデオに 2 枚のカードと 3 秒の注釈を付けることができ、品質は GPT-4V に近くなります。
最終的なビデオとテキストのペアは、トレーニングに直接使用できます。 GitHub で提供されるオープン ソース コードを使用すると、独自のデータ セットでのトレーニングに必要なビデオとテキストのペアを簡単かつ迅速に生成できるため、Sora レプリケーション プロジェクトを開始するための技術的なしきい値と事前準備が大幅に軽減されます。

さらに、Colossal-AI チームはトレーニング高速化ソリューションも提供します。
オペレーターの最適化やハイブリッド並列処理などの効率的なトレーニング戦略により、64 フレーム、解像度 512x512 のビデオ処理のトレーニングで 1.55 倍の高速化効果が達成されました。
同時に、Colossal-AI の異種メモリ管理システムのおかげで、1 分間の 1080p 高解像度ビデオ トレーニング タスクを単一サーバー (8H800) で支障なく実行できます。

#また、チームは、STDiT モデル アーキテクチャがトレーニング中に優れた効率を示すことも発見しました。
フル アテンション メカニズムを使用する DiT と比較して、STDiT はフレーム数の増加に応じて最大 5 倍の高速化効果を実現します。これは、長いビデオ シーケンスの処理などの実際のタスクでは特に重要です。

最後に、チームはさらに Open-Sora 生成エフェクトもリリースしました。
、期間 00:25
チームと Qubits は、Open-Sora 関連のソリューションと開発を長期的に更新および最適化することを明らかにしました。将来的には、より多くのビデオ トレーニング データを使用して、より高品質で長いビデオ コンテンツを生成し、マルチ解像度機能をサポートする予定です。
実用化に関しては、映画、ゲーム、広告などの分野での導入を推進していくことを明らかにした。
興味のある開発者は、GitHub プロジェクトにアクセスして詳細をご覧ください~
Open-Sora オープン ソース アドレス: https://github.com/hpcaitech/Open-Sora
Referenceリンク:
[1]https://arxiv.org/abs/2212.09748 変圧器を備えたスケーラブルな拡散モデル。
[2]https://arxiv.org/abs/2310.00426 PixArt-α: フォトリアリスティックなテキストから画像への合成のための拡散変換器の高速トレーニング.
[3]https://arxiv.org/abs/2311.15127 安定したビデオ拡散: 潜在ビデオ拡散モデルを大規模なデータセットに拡張します。
[4]https://arxiv.org/abs/2401.03048 Latte: ビデオ生成用の潜在拡散トランスフォーマー。
[5]https://huggingface.co/stabilityai/sd-vae-ft-mse-original。
[6]https://github.com/google-research/text-to-text-transfer-transformer。
[7]https://github.com/haotian-liu/LLaVA。
[8]https://hpc-ai.com/blog/open-sora-v1.0。
以上が世界初のSora風のオープンソース複製ソリューションが登場!すべてのトレーニングの詳細とモデルの重みを完全に開示の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



