


Apple のこの新しい取り組みは、将来の iPhone に大型モデルを追加する能力に無限の想像力をもたらすでしょう。
近年、GPT-3、OPT、PaLM などの大規模言語モデル (LLM) は、幅広い自然言語処理 (NLP) タスクで優れたパフォーマンスを実証しています。ただし、これらの大規模な言語モデルには数千億、さらには数兆のパラメーターが含まれる可能性があり、リソースに制約のあるデバイス上で効率的にロードして実行することが困難になるため、これらのパフォーマンスを達成するには大規模な計算およびメモリ推論が必要になります。
現在の標準ソリューション推論のためにモデル全体を DRAM にロードすることですが、このアプローチでは実行できる最大モデル サイズが大幅に制限されます。たとえば、70 億のパラメータ モデルでは、パラメータを半精度浮動小数点形式でロードするために 14 GB 以上のメモリが必要ですが、これはほとんどのエッジ デバイスの能力を超えています。
この制限を解決するために、Apple の研究者は、DRAM より少なくとも 1 桁大きいフラッシュ メモリにモデル パラメータを保存することを提案しました。その後、推論中に必要なパラメータを直接かつ巧みにフラッシュロードすることで、モデル全体を DRAM に収める必要がなくなりました。
このアプローチは、LLM がフィードフォワード ネットワーク (FFN) 層で高度なスパース性を示し、OPT や Falcon などのモデルが 90% を超えるスパース性を達成していることを示す最近の研究に基づいています。したがって、このスパース性を利用して、ゼロ以外の入力を持つパラメータ、またはゼロ以外の出力を持つと予測されるパラメータのみをフラッシュ メモリから選択的にロードします。

論文アドレス: https://arxiv.org/pdf/2312.11514.pdf
具体的には、研究者らは、次のようなハードウェアに着想を得たコスト モデルについて議論しました。フラッシュ メモリ、DRAM、およびコンピューティング コア (CPU または GPU)。次に、データ転送を最小限に抑え、フラッシュ スループットを最大化するための 2 つの補完的な手法が導入されています。
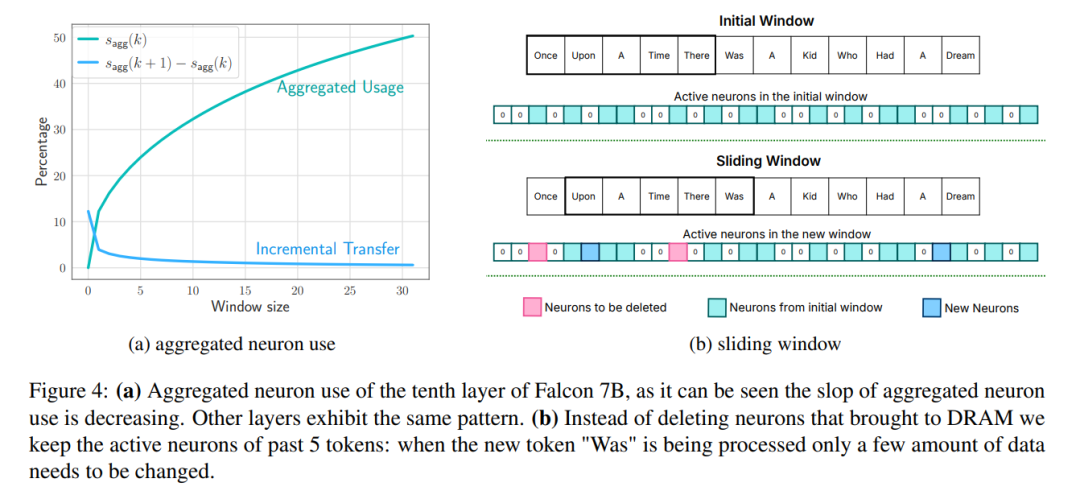
ウィンドウ: 最初のいくつかのタグのパラメータのみをロードし、最後に計算されたタグのアクティブ化を再利用します。このスライディング ウィンドウ アプローチにより、重みをロードするための IO リクエストの数が削減されます。
行と行のバンドル: 上向き投影レイヤーと下向き投影レイヤーの連結された行と列を保存し、より大きな連続部分を読み取ります。フラッシュメモリの部分。これにより、より大きなブロックを読み取ることでスループットが向上します。
フラッシュから DRAM に転送される重みの数をさらに減らすために、研究者らは FFN のスパース性を予測し、ゼロ化パラメータのロードを回避しようとしました。ウィンドウ処理とスパース予測を組み合わせて使用することにより、推論クエリごとにフラッシュ FFN レイヤーの 2% のみがロードされます。また、DRAM 内転送を最小限に抑え、推論レイテンシを削減するために、静的メモリの事前割り当ても提案しています。
この論文のフラッシュ ロード コスト モデルは、より優れたデータのロードとより大きなブロックの読み取りとの間でバランスを取ります。このコスト モデルを最適化し、オンデマンドでパラメーターを選択的にロードするフラッシュ戦略は、CPU と GPU での単純な実装と比較して、2 倍の DRAM 容量でモデルを実行し、推論速度をそれぞれ 4 ~ 5 倍および 20 ~ 25 倍向上させることができます。
この取り組みにより、iOS 開発がより面白くなるとコメントする人もいます。
フラッシュ メモリと LLM の推論
帯域幅とエネルギーの制限
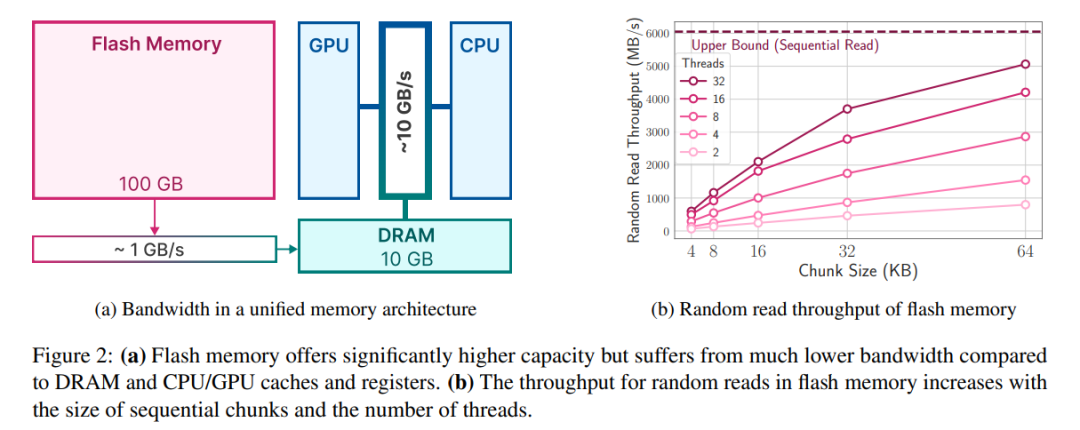
最新の NAND フラッシュ メモリは高帯域幅と低遅延を提供しますが、 , しかし、特にメモリに制約のあるシステムでは、DRAM のパフォーマンス レベルにはまだ達していません。以下の図 2a は、これらの違いを示しています。
NAND フラッシュに依存する単純な推論の実装では、順方向パスごとにモデル全体をリロードする必要がある場合があります。このプロセスには時間がかかり、モデルの圧縮にも数秒かかります。さらに、DRAM から CPU または GPU メモリへのデータ転送には、より多くのエネルギーが必要です。
DRAM で十分なシナリオでは、データの読み込みコストが削減され、モデルを DRAM に常駐させることができます。ただし、特に最初のトークンに高速な応答時間が必要な場合は、モデルの初期読み込みでもエネルギーを消費します。私たちのアプローチは、LLM の活性化スパース性を利用して、モデルの重みを選択的に読み取ることでこれらの課題に対処し、それによって時間とエネルギーのコストを削減します。
次のように再表現します: データ転送速度の取得
フラッシュ システムは、大量のシーケンシャル読み取りで最高のパフォーマンスを発揮します。たとえば、Apple MacBook Pro M2 には 2TB のフラッシュ メモリが搭載されており、ベンチマーク テストでは、キャッシュされていないファイルの 1 GiB の線形読み取り速度が 6 GiB/s を超えました。ただし、小規模なランダム読み取りでは、オペレーティング システム、ドライバー、ミッドレンジ プロセッサ、フラッシュ コントローラーなどの読み取りが多段構成であるため、このような高帯域幅を実現することはできません。各段階で遅延が発生し、読み取り速度の低下により大きな影響が生じます。
これらの制限を回避するために、研究者は同時に使用できる 2 つの主要な戦略を提唱しています。
最初の戦略は、より大きなデータ ブロックを読み取ることです。スループットの増加は線形的ではありません (データ ブロックが大きいほど、より長い転送時間が必要になります) が、最初のバイトの遅延が総リクエスト時間に占める割合は小さくなり、データの読み取りがより効率的になります。図 2b はこの原理を示しています。直観に反しますが、興味深い観察は、場合によっては、必要以上のデータを (ただし大きなチャンクで) 読み取って破棄する方が、必要なデータだけを小さなチャンクで読み取るよりも高速であるということです。
2 番目の戦略は、ストレージ スタックとフラッシュ コントローラーの固有の並列性を利用して、並列読み取りを実現することです。結果は、標準ハードウェアで 32KiB 以上のマルチスレッド ランダム読み取りを使用して、スパース LLM 推論に適したスループットを達成できることを示しています。
平均ブロック長を長くするレイアウトでは帯域幅が大幅に増加する可能性があるため、スループットを最大化する鍵は重みの格納方法にあります。場合によっては、データをより小さく効率の悪いチャンクに分割するよりも、余分なデータを読み取ってその後破棄する方が有益な場合があります。
フラッシュ ローディング
研究者らは、上記の課題に着想を得て、データ転送量を最適化し、データ転送速度を向上させる方法を提案しました。これは次のように表現できます。推論速度を向上させるため。このセクションでは、利用可能な計算メモリがモデル サイズよりはるかに小さいデバイスで推論を実行する際の課題について説明します。
この課題を分析するには、完全なモデルの重みをフラッシュ メモリに保存する必要があります。研究者がさまざまなフラッシュ ロード戦略を評価するために使用する主な指標はレイテンシです。レイテンシは、フラッシュ ロードを実行する I/O コスト、新しくロードされたデータを管理するメモリ オーバーヘッド、および推論操作。
Apple は、メモリ制約下でレイテンシーを削減するためのソリューションを 3 つの戦略的領域に分割し、それぞれがレイテンシーの特定の側面を対象としています:
1. データ負荷の削減: データのロードを減らして、メモリに関連するレイテンシーを削減することを目指しています。フラッシュ I/O 操作。
2. データ ブロック サイズの最適化: ロードされるデータ ブロックのサイズを増やすことでフラッシュのスループットを向上させ、レイテンシを短縮します。
次は、フラッシュ読み取り効率を向上させるためにデータ ブロック サイズを増やすために研究者が使用する戦略です:
列と行をバンドルする
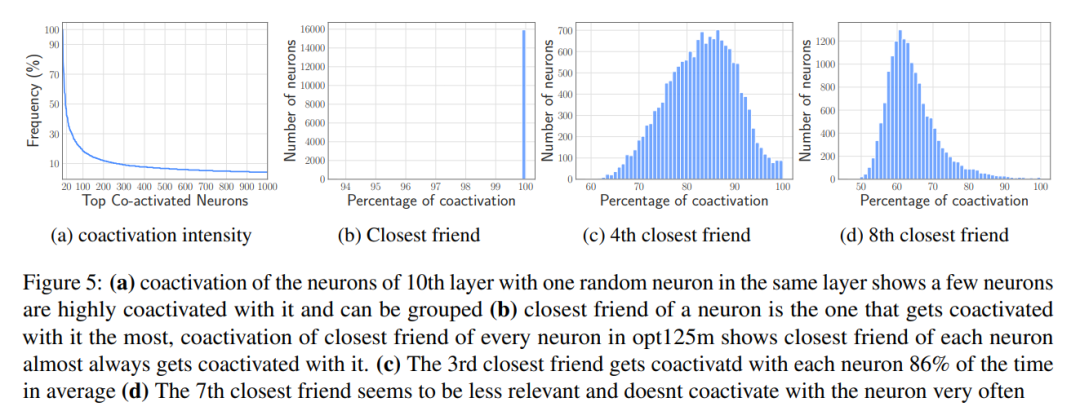
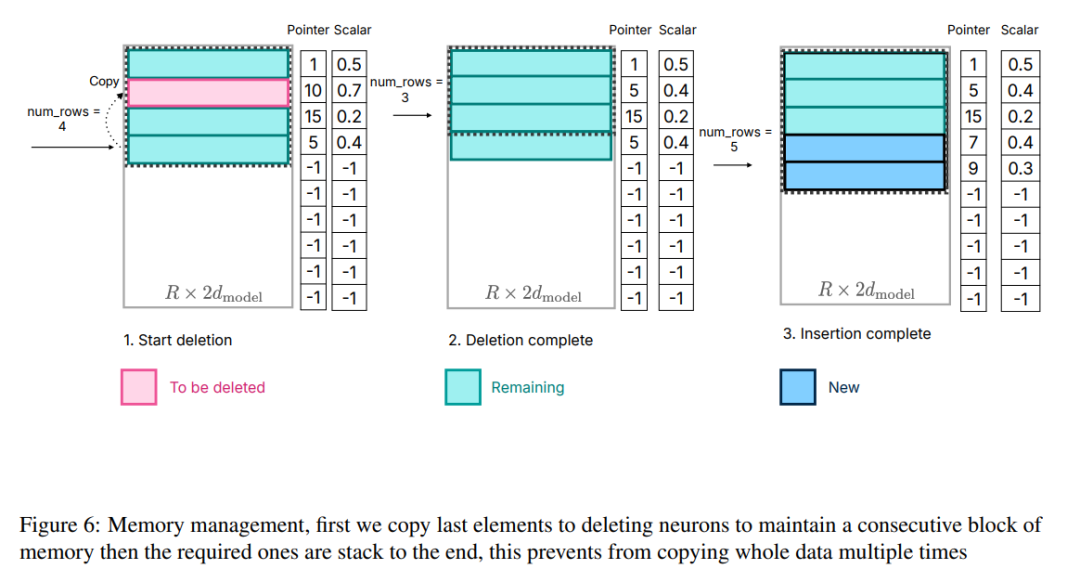
#図 6: メモリ管理などの要素が含まれます。 、最初に最後の要素を削除ニューロンにコピーしてメモリ ブロックの連続性を維持し、次に必要な要素を最後までスタックします。これにより、データ全体を複数回コピーすることが回避されます。 計算プロセスには焦点が当てられていないことに注意してください。これは、この記事の中心的な作業とは何の関係もありません。このパーティショニングにより、研究者はフラッシュ インタラクションとメモリ管理の最適化に集中して、メモリが制限されたデバイスで効率的な推論を実現できます
#実験結果の書き換えが必要
##OPT 6.7 B モデルの結果
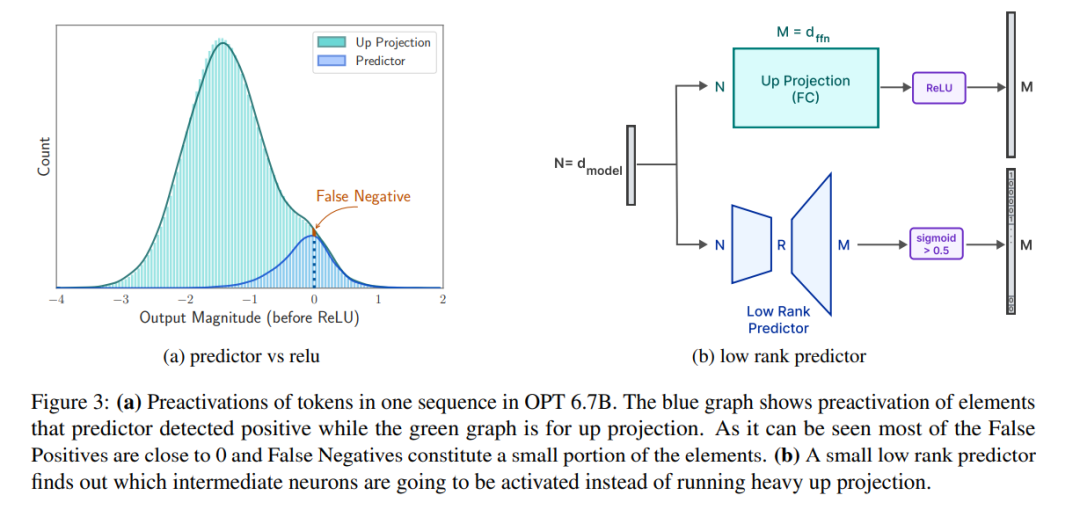
予測子。図 3a に示すように、私たちの予測器はほとんどの活性化ニューロンを正確に識別できますが、ゼロに近い値を持つ非活性化ニューロンを誤って識別することがあります。ゼロに近い値を持つこれらの偽陰性ニューロンが除去された後は、最終的な出力結果は大幅に変更されないことは注目に値します。さらに、表 1 に示すように、このレベルの予測精度は、ゼロショット タスクにおけるモデルのパフォーマンスに悪影響を及ぼしません。
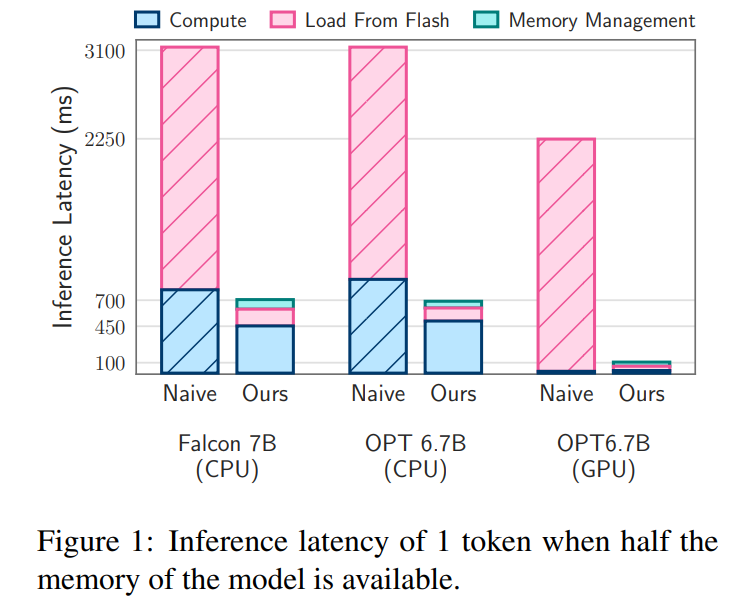
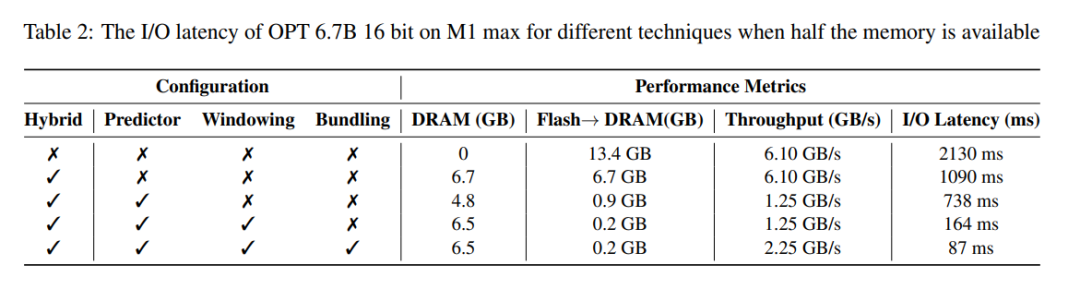
遅延解析。ウィンドウ サイズが 5 の場合、各トークンはフィードフォワード ネットワーク (FFN) ニューロンの 2.4% にアクセスする必要があります。 32 ビット モデルの場合、行と列の連結が含まれるため、読み取りあたりのデータ ブロック サイズは 2dmodel × 4 バイト = 32 KiB になります。 M1 Max では、トークンあたりのフラッシュ ロードのレイテンシは 125 ミリ秒、メモリ管理 (ニューロンの削除と追加を含む) のレイテンシは 65 ミリ秒です。したがって、メモリ関連の合計遅延はトークンあたり 190 ミリ秒未満になります (図 1 を参照)。これに対し、ベースライン アプローチでは 6.1 GB/秒で 13.4 GB のデータをロードする必要があり、トークンごとに約 2,330 ミリ秒の遅延が発生します。したがって、私たちの方法はベースライン方法と比較して大幅に改善されています。
GPU マシンの 16 ビット モデルの場合、フラッシュのロード時間は 40.5 ミリ秒に短縮され、メモリ管理時間は 40 ミリ秒になります。ただし、CPU からのデータ転送の追加オーバーヘッドにより時間はわずかに増加します。 GPUに。それにもかかわらず、ベースライン方法の I/O 時間は依然として 2000 ミリ秒を超えています。
表 2 は、各方法のパフォーマンスへの影響を詳細に比較したものです。
Falcon 7B モデルの結果
遅延解析。モデルでウィンドウ サイズ 4 を使用すると、各トークンはフィードフォワード ネットワーク (FFN) ニューロンの 3.1% にアクセスする必要があります。 32 ビット モデルでは、これは読み取りあたり 35.5 KiB のブロック サイズに相当します (2dmodel × 4 バイトとして計算)。 M1 Max デバイスでは、このデータのフラッシュ ロードに約 161 ミリ秒かかり、メモリ管理プロセスによりさらに 90 ミリ秒が追加されるため、トークンごとの合計レイテンシは 250 ミリ秒になります。比較すると、ベースライン遅延が約 2330 ミリ秒であるため、私たちの方法は約 9 ~ 10 倍高速です。
以上がモデル推論の高速化: CPU パフォーマンスが 5 倍に向上 Apple は大規模な推論の高速化にフラッシュ メモリを使用 Siri 2.0 は間もなくデビューしますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



