



日常生活では、スクリーンショットの抽出や写真の検索に OCR (光学式文字認識) テクノロジーが広く使用されています。 、これはテキスト認識の分野で非常に重要な技術です
#OCR (光学文字認識) は、光学技術とコンピューター技術を使用して、印刷または手書きのテキスト画像をコンピューター用に正確で読み取り可能なテキスト形式に変換するコンピューターテキスト認識方法です。 OCR 認識技術は、現代生活のさまざまな業界でますます広く使用されており、テキスト コンテンツをコンピュータにすばやく入力するための重要な技術です。
OCR テクノロジは、主に、従来の OCR とディープ ラーニング OCR の 2 つの流派に分かれています。
OCR テクノロジー開発の初期の頃、技術者は、二値化、接続ドメイン分析、射影分析などの画像処理技術を、統計的機械学習 (Adaboost や SVM など) と組み合わせて使用していました。 ) 画像を抽出する 私たちはテキスト コンテンツを従来の OCR として分類します。その主な特徴は、複雑なデータ前処理操作に依存して画像上のノイズを修正および低減することです。複雑なシーンへの適応性の重要性は無視できません。適応力は、変化する環境において重要な能力です。適応力が高い人は、新しい状況や要件に適応し、変化に素早く適応し、問題の解決策を見つけることができます。適応力は、私生活や職業生活で成功するための重要な要素の 1 つでもあります。したがって、精度や対応速度が劣りながらも、変化する世界に対応できる適応力を養い、向上させることに努めなければなりません。
AI 技術の継続的な開発により、エンドツーエンドの深層学習に基づく OCR 技術は徐々に成熟してきました。この手法の利点は、明示的に導入する必要がないことです。画像の前処理段階でのテキスト切断リンクは、テキスト認識をシーケンス学習問題に変換し、テキストのセグメンテーションを深層学習に統合します。これは、OCR 技術の向上と将来の開発の方向性にとって非常に重要です。
#2.1 従来の OCR 認識プロセス

画像の前処理: テキスト画像は、デバイスによってスキャンされた後、前処理段階に入ります。さまざまな文字メディアの存在により、紙の平滑性や印刷品質、画面の明暗などの干渉要因により文字の歪みが発生するため、明るさ調整、画像補正、補正などの前処理方法が必要となります。画像にはノイズフィルタリングが必要です。
テキスト領域の位置決め: テキスト領域の位置決めと抽出には、主に接続ドメイン検出と MSER 検出が含まれます。
文字画像修正: 文字が傾いている場合に水平になるように修正します。修正方法には主に水平補正と遠近補正があります。
行と行の単一文字セグメンテーション: 従来のテキスト認識は単一文字認識に基づいており、セグメンテーション方法では主に接続されたドメインの輪郭と、垂直投影カット。
分類子文字認識: HOG や Sift などの特徴抽出アルゴリズムを使用して文字からベクトル情報を抽出し、SVM アルゴリズムとロジスティックを使用します。回帰、サポートベクターマシンなどのトレーニング用。
後処理: 分類器の分類が完全に正しくない可能性や、文字の切り取り処理でエラーが発生する可能性があるため、統計的な言語モデル (隠れマルコフ連鎖、HMM など)、またはテキスト結果に対して意味論的なエラー修正を実行するために人間の抽出ルールによって設計された言語ルール モデルに基づく必要があります。
2.2 ディープ ラーニング OCR写真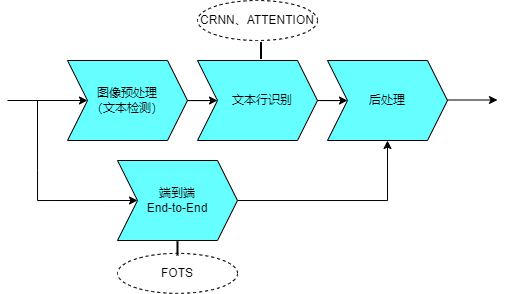
テキスト検出は、回帰ベースの方法とセグメンテーション ベースの方法に分類できます。回帰手法には、画像内の方向性のあるテキストを検出できる CTPN、Textbox、EAST などのアルゴリズムが含まれますが、テキスト領域の不規則性の影響を受けます。 PSENet アルゴリズムなどのセグメンテーション手法は、さまざまな形状やサイズのテキストを処理できますが、テキストが密集していると固着の問題が発生しやすくなります。さまざまな方法には、それぞれ長所と短所があります。
テキスト認識ステージでは、主に CRNN と ATTENTION という 2 つの主要なテクノロジを使用して、テキスト認識をシーケンス学習問題に変換します。特徴学習段階 どちらもCNN RNNのネットワーク構造を利用していますが、違いは最終出力層(翻訳層)、つまりネットワークで学習した配列特徴情報をどのように最終的な認識結果に変換するかにあります。
さらに、テキスト検出とテキスト認識を学習用の単一ネットワーク モデルに直接統合する最新のエンドツーエンド アルゴリズムがあります。たとえば、FOTS や Mask TextSpotter などのアルゴリズムです。独立したテキスト検出およびテキスト認識方法と比較して、このアルゴリズムは認識速度は速いですが、相対的な精度は劣ります
アルゴリズム
#複数ステージの全体的な安定性が低い 終了後 終了あり-ツーエンドの最適化により、システムの安定性が大幅に向上しました
精度が高くない場合でも、サンプルが小さい従来のシナリオには一定の利点があります 精度は高くなりますが、融合度が深くなるほど精度は徐々に低下します 識別 認識が遅い
# シナリオ #適応性の重要性は無視できません。適応力は、変化する環境において重要な能力です。適応力が高い人は、新しい状況や要件に適応し、変化に素早く適応し、問題の解決策を見つけることができます。適応力は、私生活や職業生活で成功するための重要な要素の 1 つでもあります。したがって、私たちは、絶え間なく変化する世界に対処するための適応力を養い、向上させるよう努める必要があります
##強い、モデルのトレーニングに依存 精度率: システムが認識した文字の総数に対する、OCR システムが正しく認識した文字の数の割合を指します。システムの認識結果が本当に正しいことを示し、値が大きいほどシステムの認識結果の信頼性が高くなります。 F1 値: 再現率と適合率の総合的な評価指標です。F1 値は 0 から 1 の間です。値が大きいほど適合率と適合率のバランスが優れています。より良いバランスが実現されました。 Average Edit Distance (平均編集距離) は、OCR 認識結果と実際のテキストとの差異の程度を評価するために使用される指標です。 Part 04 , 応用と展望2.3 スキームの比較
#従来の識別
人工知能ディープラーニング認識技術
基盤層
テキストの検出と認識は、さまざまなアルゴリズムの組み合わせを使用して、複数のステージとサブプロセスに分割されます
このモデルの目標は、検出プロセスと認識プロセスを融合してエンドツーエンドを実現することです
##安定性
#速度 #精度
認識が速い
#脆弱で適用可能な標準印刷形式 #強力で複雑なシナリオに対応、モデルのトレーニングに依存耐干渉能力
一般的な OCR 評価指標 弱い、入力画像の要件が高い
再現率: OCR システムによって正しく認識された文字数と実際の文字数の比率を指し、システムが一部の文字を認識し損ねているかどうかを測定するために使用されます。値が大きいほど、システムが文字をカバーする能力が高くなります。
OCR は、テキスト認識分野の主要分野の 1 つとして、依然として幅広い研究方向性を持っています。そして将来の開発スペース。認識精度に関しては、よりスマートな画像処理技術とより強力な深層学習モデルの研究が依然として急務であり、複数の言語やフォントをカバーするより普遍的な認識、複雑なシーンへの適応能力の強化が必要です。技術面では、AR翻訳やテキストデータの自動誤り訂正、データ修正など、仮想現実技術や拡張現実技術と組み合わせたさらなる応用ポイントを模索しています。
以上がOCR 認識の原理と応用シナリオを探るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



