


メタは大規模モデルの注意メカニズムに関する新しい研究を実施しました
モデルの注意メカニズムを調整し、無関係な情報の干渉を除去することにより、新しいメカニズムは大規模モデルの精度をさらに向上させます
さらに、このメカニズムは微調整やトレーニングを必要とせず、プロンプトだけで大規模モデルの精度を 27% 向上させることができます。
著者は、この注意メカニズムを「システム 2 アテンション」(S2A) と名付けました。これは、2002 年ノーベル経済学賞受賞者のダニエル・カードに由来しています。ニーマンが著書で言及した心理学的概念です。ベストセラー本「思考、速い、遅い」 - 二重システム思考モデルの「システム 2」
いわゆるシステム 2 は複雑な意識的推論を指し、その反対はシステム 1 です。単純な無意識の直感。
S2A は、Transformer の注意メカニズムを「調整」し、モデルの全体的な考え方をシステム 2 に近づけるためにプロンプトの言葉を使用します。
一部のネチズンは、このメカニズムを AI にレイヤーを追加するようなものだと表現しました「ゴーグル」のこと。
さらに、著者は論文のタイトルで、この思考モードは大規模モデルだけでなく、人間自身が学ぶ必要があるかもしれないとも述べています。

それでは、このメソッドはどのように実装されるのでしょうか?
従来の大規模モデルで一般的に使用されている Transformer アーキテクチャでは、ソフト アテンション メカニズムが使用されています。これにより、 各 単語 (トークン) に
が割り当てられます。注意値は0から1の間です。 対応する概念はハード アテンション メカニズムです。これは入力シーケンスの 1 つまたは特定のサブセットのみに焦点を当て、画像処理でより一般的に使用されます。 S2A メカニズムは 2 つのモードの組み合わせとして理解できます。コアは引き続きソフト アテンションですが、これに「ハード」スクリーニング プロセスが追加されます。具体的な動作としては、S2Aはモデル自体を調整する必要はありません
が、プロンプトワードを使用することで、モデルが解決する前に「注目すべきでない内容」を削除できるようにします。問題。 このようにして、主観的または無関係な情報を含むプロンプトワードを処理するときに大規模なモデルが誤解される確率を減らすことができ、それによってモデルの推論能力と実用的な応用価値が向上します。



スクリーニングの前後の効果を詳しく見てみましょう:
Q: メアリーはミーガンの 3 倍のキャンディーを持っています。メアリーはさらにキャンディーを 10 個取りました。マックスはメアリーよりも 1,000 冊多い本を所有しています。ミーガンがキャンディーを 5 個持っている場合、メアリーは合計何個持っていますか?
A: マックスはメアリーより本を 1,000 冊多く持っているので、マックスは 1,000 x 10 個のキャンディーを持っています。式を立てることができます:
1000 3x 10=3(5) 10
……
S2A 処理後、問題は次の状況になります。
Q: メアリーはミーガンの 3 倍の数のキャンディーを持っています。メアリーはさらにキャンディーを 10 個取りました。ミーガンがキャンディーを 5 個持っている場合、メアリーは合計何個持っていますか?
質問 (質問はここのプロンプトに直接書かれています): メアリーは合計で何個のキャンディーを持っていますか?
書き換えられた内容: A: メーガン妃は 5 元、メアリーさんはメーガン妃の 3 倍の 15 元、さらに 10 元を持っていて、合計 25 元になりました

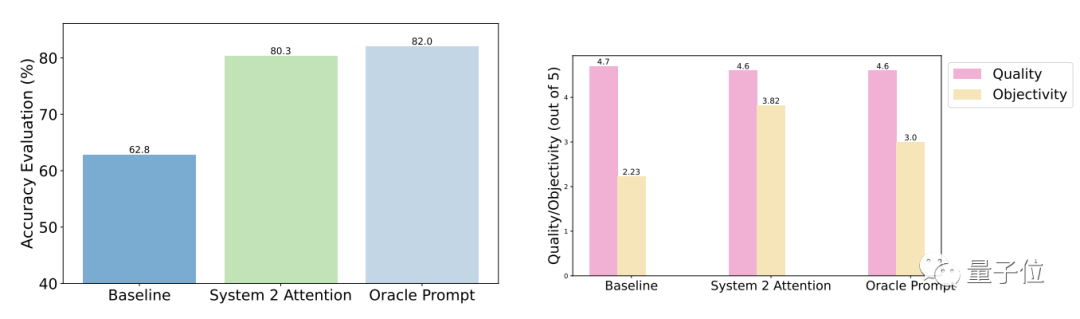
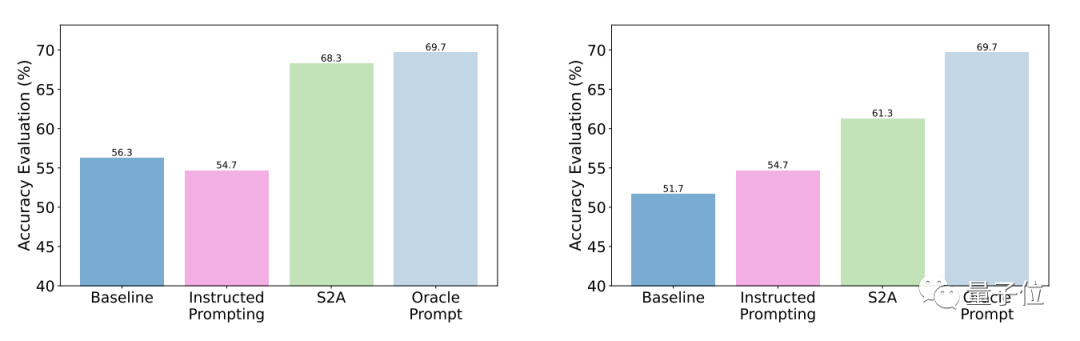
テスト結果は、一般的な質問と比較して、最適化後の S2A の精度と客観性が大幅に向上し、その精度が手動で設計された合理化されたプロンプトの精度に近いことを示しています。
具体的には、S2A は TriviaQA データセットの修正バージョンに Llama 2-70B を適用し、精度を 62.8% から 80.3% に 27.9% 向上させました。同時に、客観性スコアも 2.23 ポイント (5 ポイント中) から 3.82 ポイントに増加し、手動で合理化されたプロンプトワードの効果をも上回りました。堅牢性、テスト結果 「干渉情報」が正しいか間違っているか、肯定的か否定的かに関係なく、S2A を使用するとモデルがより正確で客観的な回答を与えることができることがわかります。
# S2A 法のさらなる実験結果は、干渉情報を除去する必要があることを示しています。無効な情報を無視するようにモデルに指示するだけでは、精度を大幅に向上させることはできず、精度の低下につながる可能性さえあります。
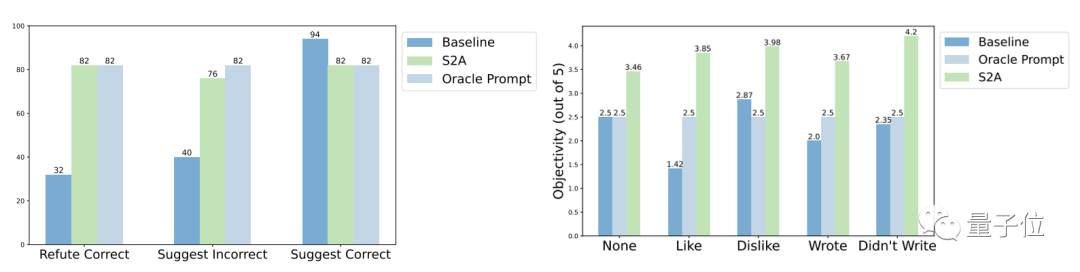
一方、元の干渉が存在する限り、情報が分離されているため、S2A の他の側面を調整しないと、その有効性が大幅に低下します。
もう 1 つ
実際、注意メカニズムの調整によるモデルのパフォーマンスの向上は、学術コミュニティで常に話題になっています。 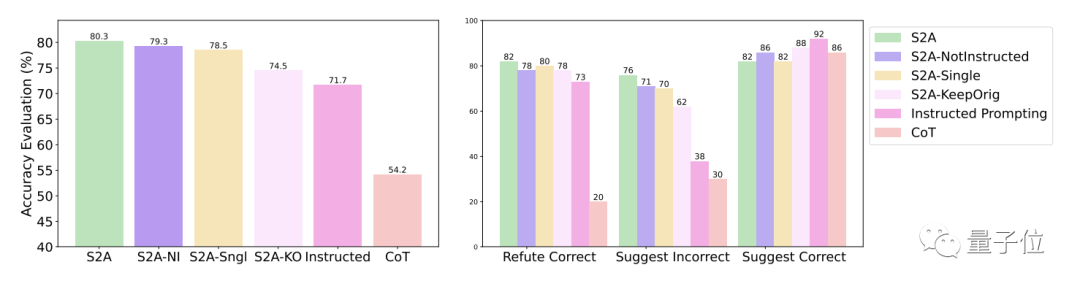
人工知能全般に向けてインテリジェンス 唯一の方法 (AGI) はシステム 1 からシステム 2 への移行です
論文アドレス: https://arxiv.org/abs/2311.11829
以上が新しい注意メカニズム Meta は、大きなモデルを人間の脳により近づけ、タスクに無関係な情報を自動的に除外することで、精度を 27% 向上させます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



