


2D 拡散モデルの導入により、画像コンテンツの作成プロセスが大幅に簡素化され、2D デザイン業界に革新がもたらされます。近年、この普及モデルは 3D 制作にも拡大し、VR、AR、ロボット工学、ゲームなどのアプリケーションの人件費を削減しています。多くの研究では、事前トレーニングされた 2D 拡散モデルの使用や、スコア化蒸留サンプリング (SDS) 損失を使用する NeRF メソッドの使用が検討され始めています。ただし、SDS ベースの手法では、通常、リソースの最適化に何時間もかかり、多面的なヤヌス問題などのグラフィックスでの幾何学的な問題を引き起こすことがよくあります。
一方、研究者は、何時間も費やす必要はありません。各リソースを最適化し、多様な 3D 拡散モデルの生成を実現するために、さまざまな試みが行われてきました。これらの方法では通常、トレーニング用の実データを含む 3D モデル/点群を取得する必要があります。しかし、実際の画像の場合、そのようなトレーニング データを取得することは困難です。現在の 3D 拡散手法は通常 2 段階のトレーニングに基づいているため、分類されていない非常に多様な 3D データセット上に不鮮明でノイズ除去が困難な潜在空間が生じ、高品質のレンダリングが緊急の課題となっています。
#この問題を解決するために、一部の研究者は単一段階モデルを提案しましたが、これらのモデルのほとんどは特定の単純なカテゴリのみを対象としており、一般化が不十分です
# したがって、この記事の研究者の目標は、高速でリアルで多用途な 3D 生成を実現することです。この目的のために、彼らは DMV3D を提案しました。 DMV3D は、モデル テキストまたは単一画像の入力に基づいて 3D NeRF を直接生成できる、新しい単一ステージの全カテゴリ拡散モデルです。 DMV3D は、単一の A100 GPU でわずか 30 秒でさまざまな高忠実度 3D 画像を生成できます。

メソッドで発生する可能性のある問題を回避できます。この記事の本質的には、2D マルチビュー拡散のフレームワークに基づいた 3D 再構成です。このアプローチは、シングルビュー拡散による 3D 生成方法である RenderDiffusion メソッドからインスピレーションを得ています。ただし、RenderDiffusion メソッドの制限は、トレーニング データには特定のカテゴリに関する事前知識が必要であり、データ内のオブジェクトには特定の角度またはポーズが必要であるため、汎用性が低く、あらゆる種類のオブジェクトに対して 3D を生成できないことです
研究者によると、これに比べて、遮蔽されていない 3D オブジェクトを記述するには、オブジェクトを含む 4 つのマルチビュー スパース投影のセットだけが必要です。このトレーニング データは人間の空間想像力に由来しており、これにより人々は複数のオブジェクトの周囲の平面図から完全な 3D オブジェクトを構築できます。この想像力は通常、非常に正確かつ具体的です。
ただし、この入力を適用する場合、まばらなビューの下で 3D 再構成を行うタスクはまだ解決する必要があります。これは長年の課題であり、入力にノイズが多い場合でも非常に困難ですが、私たちの手法では単一の画像/テキストに基づいた 3D 生成を実現できます。画像入力の場合、1 つのまばらなビューをノイズのない入力として修正し、2D 画像の修復と同様に他のビューでノイズ除去を実行します。テキストベースの 3D 生成を実現するために、研究者らは、2D 拡散モデルで一般的に使用される注意ベースのテキスト条件とタイプに依存しない分類器を使用しました。
彼らはトレーニング中に画像空間監視のみを使用し、Objaverse 合成画像と MVImgNet で実際にキャプチャされた画像で構成される大規模なデータセットを使用しました。結果によると、DMV3D は単一画像 3D 再構成において SOTA レベルに達し、これまでの SDS ベースの手法や 3D 拡散モデルを上回りました。さらに、テキストベースの 3D モデル生成方法も以前の方法より優れています。
紙のアドレス: https://arxiv.org/pdf/2311.09217.pdf


トレーニング方法単一段階の 3D 拡散モデルについての推論は?
研究者らは、最初に、再構成ベースのデノイザーを使用して 3D 生成用のノイズの多いマルチビュー画像のノイズを除去する新しい拡散フレームワークを導入しました。次に、LRM に基づく新しいマルチビュー デノイザーを導入しました。拡散時間ステップに条件付けされた、3D NeRF 再構築とレンダリングを通じてマルチビュー画像を段階的にノイズ除去することが提案されています。最後に、モデルはさらに拡散されて、制御可能な生成のためのテキストと画像の調整をサポートします。
書き直す必要がある内容は、マルチビュー拡散とノイズ除去です。 書き換えられた内容: マルチアングルビューの拡散とノイズリダクション
マルチビューの拡散。 2D 拡散モデルで処理された元の x_0 分布は、データセット内の単一の画像分布です。代わりに、各グループ 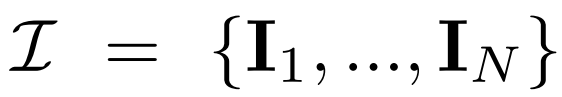 が視点 C = {c_1, .. ., c_N} から表示される、多視点画像
が視点 C = {c_1, .. ., c_N} から表示される、多視点画像 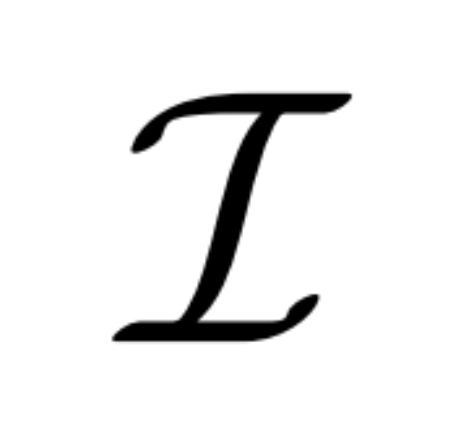 の結合分布を考慮します。の同じ 3D シーン (アセット) の観察。拡散プロセスは、以下の式 (1) に示すように、同じノイズ スケジュールを使用して各画像に対して独立して拡散操作を実行することと同等です。
の結合分布を考慮します。の同じ 3D シーン (アセット) の観察。拡散プロセスは、以下の式 (1) に示すように、同じノイズ スケジュールを使用して各画像に対して独立して拡散操作を実行することと同等です。
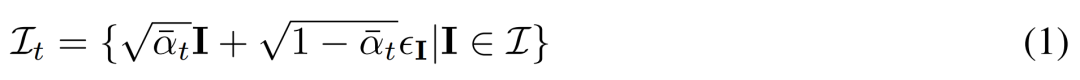
再構築ベースのノイズ除去。 2D 拡散プロセスの逆は、基本的にノイズ除去です。この論文では、研究者らは、3D 再構築とレンダリングを使用して、2D マルチビュー画像のノイズ除去を実現しながら、3D 生成用にクリーンな 3D モデルを出力することを提案しています。具体的には、3D 再構成モジュール E (・) を使用してノイズのある多視点画像 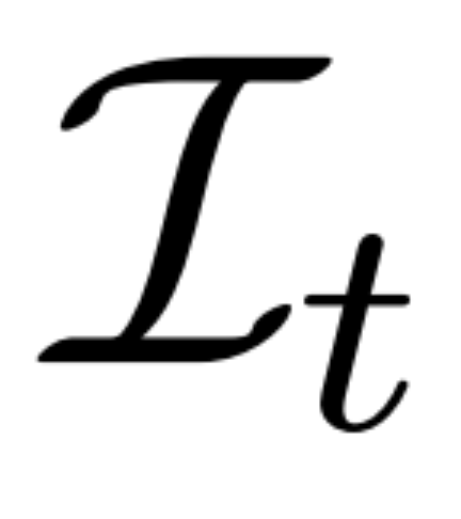 から 3D 表現 S を再構成し、微分可能レンダリング モジュール R (・) を使用してノイズ除去された画像を再構成します。レンダリングは以下の式(2)のように行われます。
から 3D 表現 S を再構成し、微分可能レンダリング モジュール R (・) を使用してノイズ除去された画像を再構成します。レンダリングは以下の式(2)のように行われます。
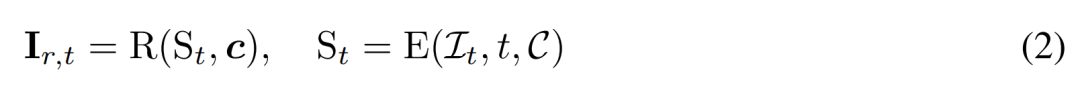
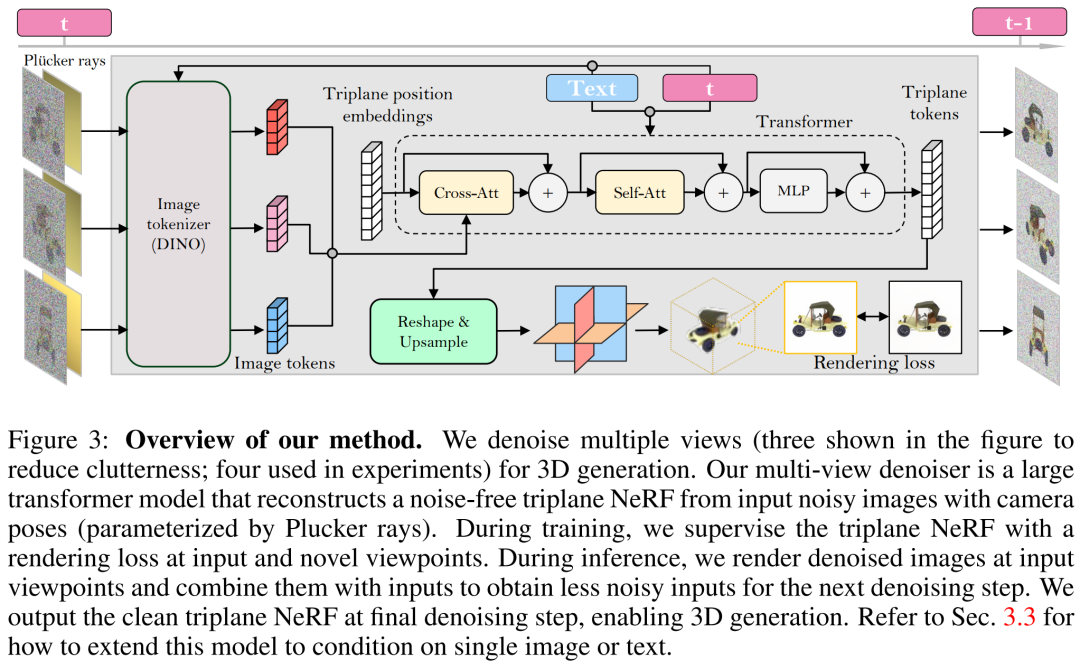
#再構築ベースのマルチビュー デノイザー
研究者らは、LRM に基づいてマルチビュー デノイザーを構築し、大規模なトランスフォーマー モデルを使用して、ノイズの多いスパース ビューのポーズ イメージからクリーンな 3 プレーン NeRF を再構築し、再構築された 3 プレーン NeRF のレンダリングをノイズ除去出力として使用しました。 。リビルドしてレンダリングします。以下の図 3 に示すように、研究者はビジョン トランスフォーマー (DINO) を使用して入力画像
を 2D トークンに変換し、そのトランスフォーマーを使用して学習した 3 平面位置の埋め込みを最後の 3 つの平面は、アセットの 3D 形状と外観を表します。次に、予測された 3 つのプレーンを使用して、微分可能なボリューム レンダリングのために MLP を介してボリューム密度とカラーをデコードします。 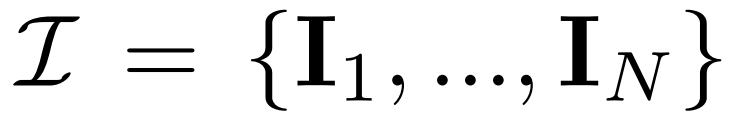
 #時間調整。 CNN ベースの DDPM (ノイズ除去拡散確率モデル) と比較して、トランスフォーマーベースのモデルでは異なる時間調整設計が必要です。
#時間調整。 CNN ベースの DDPM (ノイズ除去拡散確率モデル) と比較して、トランスフォーマーベースのモデルでは異なる時間調整設計が必要です。
この記事でモデルをトレーニングする際、研究者らは、非常に多様なカメラの固有および外部パラメーター データ セット (MVImgNet など) では、入力カメラの調整を効果的に設計する必要があると指摘しました。モデルはカメラを理解し、3D 推論を実行します。
内容を書き換えるときは、元のテキストの意味を変えずに、元のテキストの言語を中国語に変換する必要があります。文章###### ###
上記の方法により、研究者が提案したモデルを無条件生成モデルとして機能させることができます。条件付きデノイザー 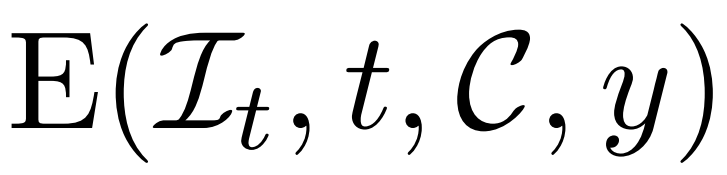 を使用して条件付き確率分布 (y はテキストまたはイメージを表します) をモデル化し、制御された 3D 生成を実現する方法について説明します。
を使用して条件付き確率分布 (y はテキストまたはイメージを表します) をモデル化し、制御された 3D 生成を実現する方法について説明します。
画像コンディショニングに関して、研究者らは、モデルのアーキテクチャを変更する必要のないシンプルで効果的な戦略を提案しました。
テキスト コンディショニング。モデルにテキスト条件付けを追加するために、研究者らは安定拡散と同様の戦略を採用しました。 CLIP テキスト エンコーダを使用してテキスト エンベディングを生成し、クロス アテンションを使用してデノイザーに挿入します。
#書き直す必要がある内容は、トレーニングと推論です。
トレーニング。トレーニング段階では、[1, T] の範囲内でタイム ステップ t を均一にサンプリングし、コサイン スケジューリングに従ってノイズを追加します。ランダムなカメラポーズを使用して入力画像をサンプリングし、さらに品質を高めるためにレンダリングを監視するために追加の新しい視点もランダムにサンプリングします。
#研究者は条件信号 y を使用してトレーニング目標を最小化します
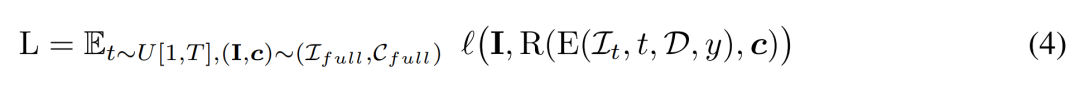
実験結果
##データセットに関する内容は、次のように書き直す必要があります。研究者のモデルは、トレーニングに多視点ポーズ画像を使用するだけで済みます。したがって、Objaverse データセットからの約 730,000 個のオブジェクトのレンダリングされたマルチビュー イメージを使用しました。各オブジェクトについて、LRM 設定に従って 50 度の固定 FOV でランダムな視点で 32 の画像レンダリングを実行し、均一な照明を実行しました。
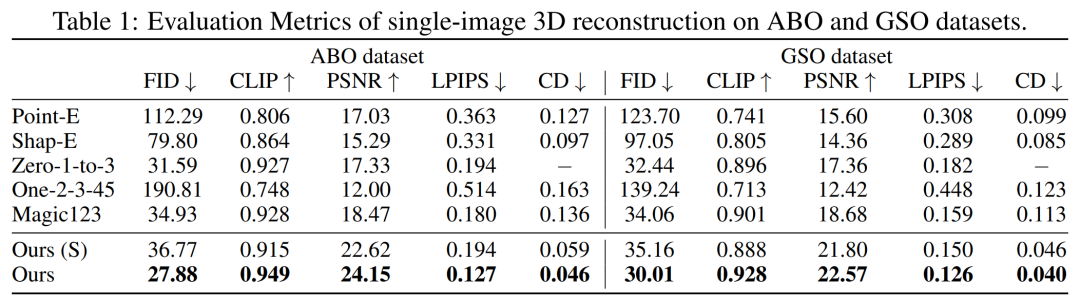
最初に、単一の画像再構成を実行しました。研究者らは、単一の画像再構成タスクに関して、画像コンディショニング モデルを、Point-E、Shap-E、Zero-1-to-3、Magic123 などの以前の手法と比較しました。彼らは、PSNR、LPIPS、CLIP 類似性スコア、FID などのメトリクスを使用して、すべての方法の新しいビューのレンダリング品質を評価しました。
GSO および ABO テスト セットの定量的結果を以下の表 1 に示します。私たちのモデルはすべてのベースライン手法を上回っており、両方のデータセットのすべてのメトリクスで新しい SOTA を達成しています。
 #のモデルによって生成された結果この記事は、ジオメトリと外観の詳細に関してベースラインよりも高い品質を持っています。この結果は、図 4
#のモデルによって生成された結果この記事は、ジオメトリと外観の詳細に関してベースラインよりも高い品質を持っています。この結果は、図 4
DMV3D は 2D 画像ベースであるのに対し、マルチビュー拡散ノイズを排除し、3D NeRF モデルを直接生成しながら、各アセットを個別に最適化する必要があります。全体として、DMV3D は 3D 画像を迅速に生成し、最高の単一画像 3D 再構成結果を達成できます。
 # 次のように書き換えられます。 : 研究者らは、テキストベースの 3D 生成結果についても DMV3D を評価しました。研究者らは、DMV3D を、同様にすべてのカテゴリにわたる高速推論をサポートする Shap-E および Point-E と比較しました。研究者らは、表 2
# 次のように書き換えられます。 : 研究者らは、テキストベースの 3D 生成結果についても DMV3D を評価しました。研究者らは、DMV3D を、同様にすべてのカテゴリにわたる高速推論をサポートする Shap-E および Point-E と比較しました。研究者らは、表 2
に示すように、Shap-E からの 50 のテキスト プロンプトに基づいてこれら 3 つのモデルを生成させ、2 つの異なる ViT モデルの CLIP 精度と平均精度を使用して生成結果を評価しました。
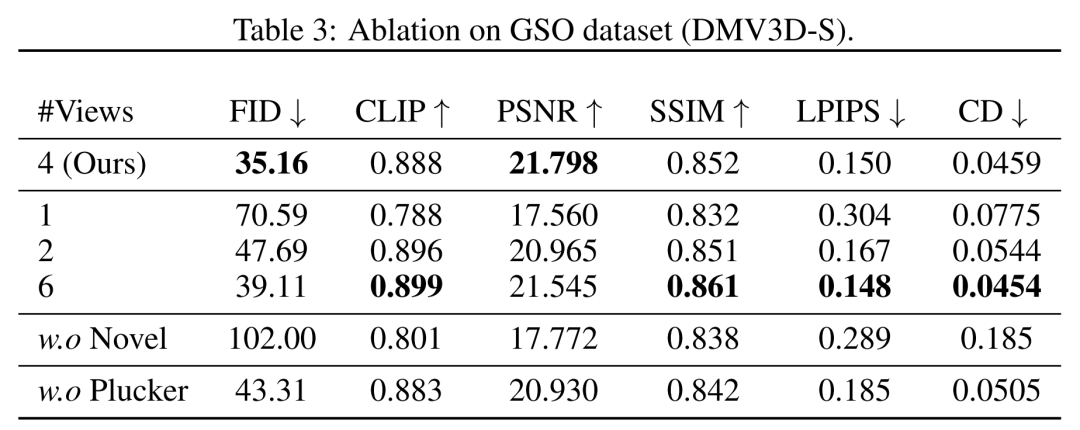
根據表中的數據顯示,DMV3D展現了最佳的精確度。從圖5的定性結果可以看出,與其他模型產生的結果相比,DMV3D產生的圖形明顯包含更豐富的幾何和外觀細節,結果也更逼真 需要重新改寫的是:其他成果 #在視角方面,研究者在表3 和圖8 中顯示了以不同數量(1、2、4、6)的輸入視圖訓練的模型的定量和定性比較。
在多實例生成方面,與其他擴散模型類似,本文提出的模型可以根據隨機輸入產生多種範例,如圖1 所示,展示了此模型產生結果的泛化性。
DMV3D在應用方面具有廣泛的靈活性和通用性,在3D生成應用領域具有強大的發展潛力。如圖1和圖2所示,本文的方法可以透過分割(例如SAM)等方法,在影像編輯應用程式中將2D照片中的任意物件提升到3D維度 請閱讀原始論文以了解更多技術細節和實驗結果



以上がAdobe の新技術: A100 で 3D 画像を生成するのにわずか 30 秒かかり、文字や画像が動きますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



