

Redis の一般的な使用方法としては、
1.Redis の単一コピー、
2.Redis の複数のコピー (マスター/スレーブ) が挙げられます。 ;
3.Redis Sentinel;
4.Redis Cluster;
5.Redis は自社開発です。
Redis シングル コピーは、単一の Redis ノード デプロイメント アーキテクチャを採用しており、バックアップ ノードはありません。データをリアルタイムで同期します。データの永続化やバックアップ戦略は提供されず、データの信頼性要件が低い純粋なキャッシュ ビジネス シナリオに適しています。
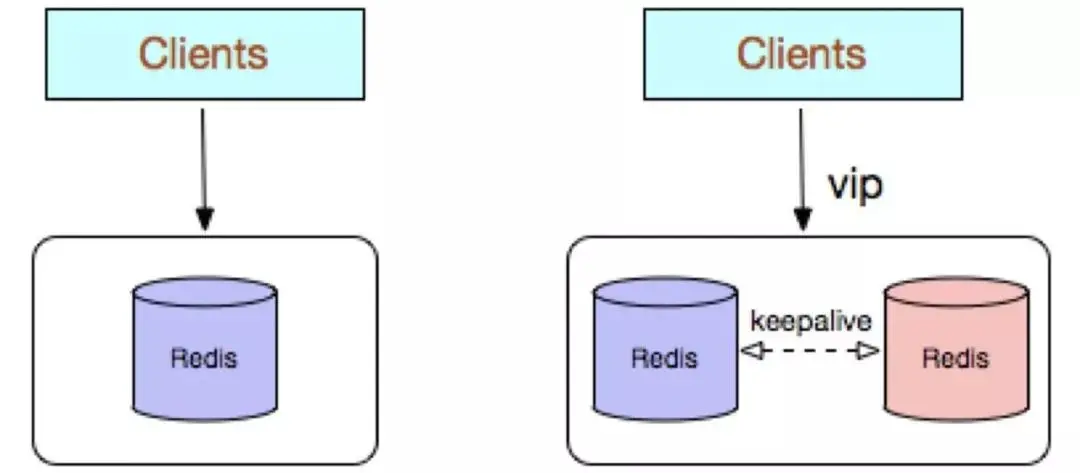
利点:
シンプルなアーキテクチャと簡単な導入;
高いコスト パフォーマンス: を使用する場合、バックアップ ノードは必要ありません。キャッシュ (単一インスタンスの可用性はスーパーバイザまたは crontab で保証できます) もちろん、ビジネスの高可用性を満たすために、バックアップ ノードも犠牲にすることもできますが、同時に外部サービスを提供できるインスタンスは 1 つだけです。 #####ハイパフォーマンス。
欠点:
データの信頼性は保証されません;
キャッシュを使用すると、プロセスの再起動後にデータが失われます。たとえ高可用性を解決するためにバックアップ ノードがあったとしても、キャッシュの予熱の問題をまだ解決できないため、高いデータ信頼性要件を必要とするビジネスには適していません;
高性能はシングルコア CPU の処理能力によって制限されます (Redis はシングルコア CPU です)。スレッド機構)、CPU が主なボトルネックとなるため、ソートや計算が少なく、操作コマンドがシンプルなシナリオに適しています。代わりに Memcached の使用を検討することもできます。
2. Redis マルチコピー (マスター-スレーブ)
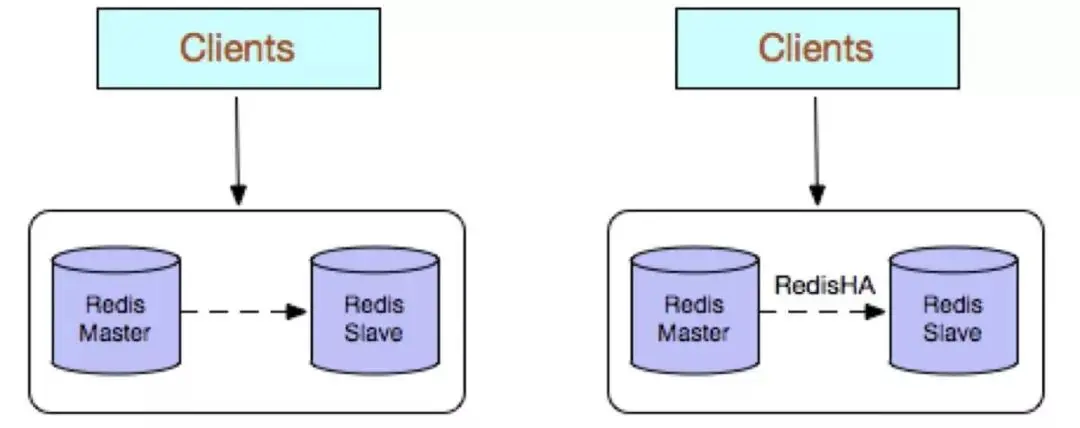
利点:
高信頼性: 一方で、デュアルマシンのアクティブおよびスタンバイ アーキテクチャを採用しており、メイン データベースに障害が発生した場合、スタンバイ スイッチングにより、スレーブ データベースがメイン データベースにサービスを提供するように昇格され、サービスのスムーズな運用が確保されます。一方、データ永続化機能をオンにして合理的なバックアップ戦略を構成すると、効果的にバックアップを実行できます。データの誤操作と異常なデータ損失の問題を解決します。
読み取りと書き込みの分離戦略: スレーブ ノードは、メイン データベース ノードの読み取り機能を拡張し、大規模な同時読み取り操作に効果的に対処できます。
欠点:
障害回復が複雑 RedisHA システムがない場合 (開発が必要)、メイン データベース ノードに障害が発生した場合、スレーブ ノードを手動でマスター ノードに昇格させる必要があります。ビジネス パーティに通知する必要があります。構成を変更し、他のスレーブ データベース ノードに新しいマスター データベース ノードをコピーさせる必要があります。プロセス全体には人間の介入が必要で、比較的面倒です。
マスターの書き込み能力データベースは単一マシンによって制限されるため、シャーディングを検討できます;
メイン ライブラリのストレージ容量は単一マシンによって制限されるため、Pika を検討できます;
ネイティブ レプリケーションの欠点Redis レプリケーションが中断された後、スレーブは pync を開始します。これは、同期が失敗した場合、完全な同期が実行されます。メイン ライブラリが完全バックアップを実行すると、ミリ秒または秒単位でバックアップが発生する可能性があります。 -レベルのラグ; COW メカニズムにより、極端な場合にはメイン ライブラリのメモリがオーバーフローし、プログラムが異常終了するかクラッシュします。マシン; メイン ライブラリ ノードはバックアップ ファイルを生成し、これによりサーバーのディスク IO と CPU (圧縮) リソースが消費されます。 ; 数 GB のバックアップ ファイルを送信すると、サーバーのエクスポート帯域幅が大幅に増加し、リクエストがブロックされるため、最新バージョンにアップグレードすることをお勧めします。
3. Redis Sentinel (センチネル)
Redis Sentinel クラスターは、複数の Sentinel ノードで構成される分散クラスターであり、障害検出、自動フェイルオーバー、構成センター、クライアント通知を実現できます。 Redis Sentinel を満たすノードの数は奇数である必要があり、その数は 2n 1 (n≥1) です。
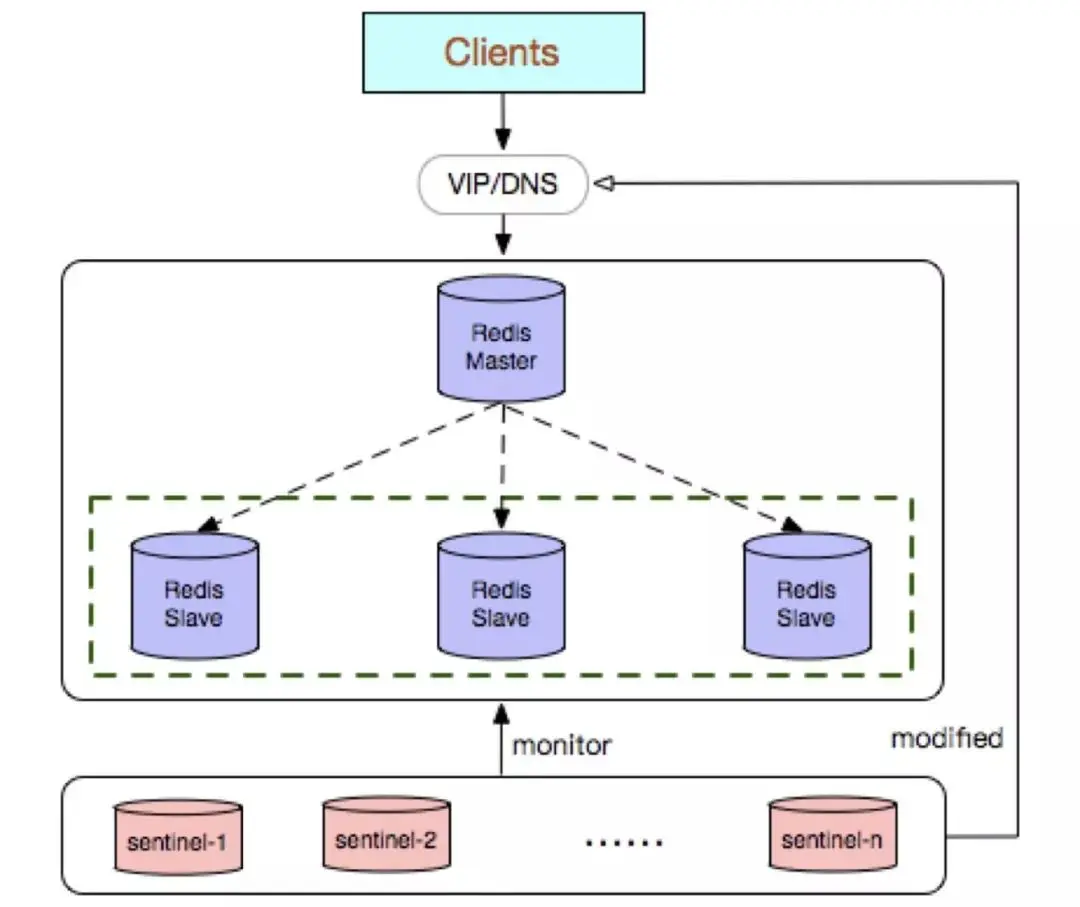
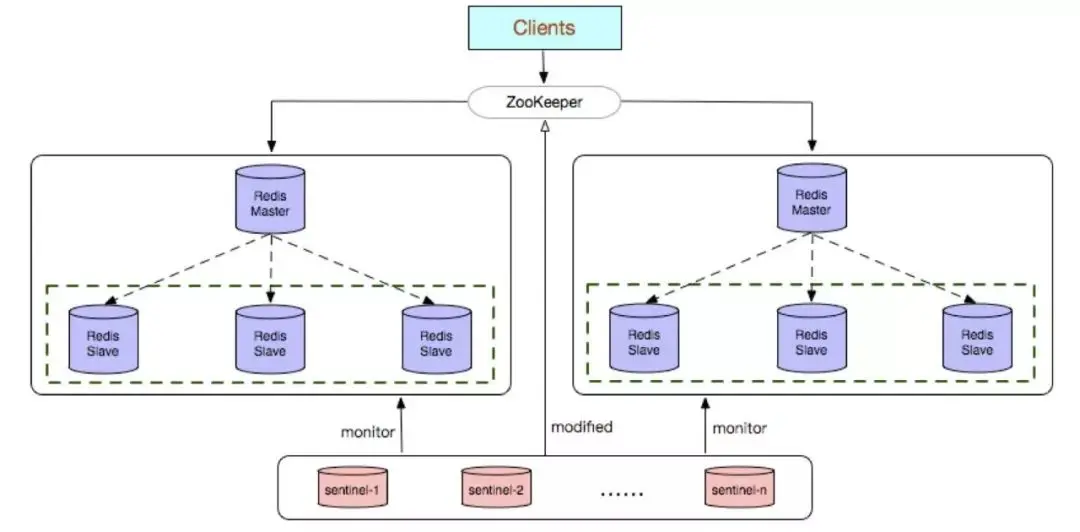 #利点:
#利点:
は読み取りと書き込みの分離の問題を解決できず、実装が比較的複雑です。
推奨事項:
同じビジネスを監視する場合は、Redis データ ノードの複数のグループを監視する Sentinel クラスターを選択できます。それ以外の場合は、Redis データ ノードのグループを監視する Sentinel クラスターを選択します。 。
センチネル モニター構成での推奨設定は、センチネル ノードの半分に 1 を加えたものです。センチネルが複数の IDC に展開されている場合、単一の IDC に展開されているセンチネルの数が (センチネル数 - クォーラム) を超えることは推奨されません。 )。
偶発的な切断を防止し、スイッチング感度制御を制御するためにパラメータを合理的に設定します:
a. クォーラム
b. ダウンアフターミリ秒 30000
c. ailover-timeout 180000
d.maxclient
e.timeout
デプロイされた各ノードのサーバー時刻は可能な限り同期する必要があります。そうしないと、ログのタイミングが同期されなくなります。混乱します。
Redis では、パイプラインとマルチキー操作を使用して RTT の数を減らし、リクエストの効率を向上させることをお勧めします。
構成センター (zookeeper) を自分で構成して、クライアントがインスタンス リンクにアクセスできるようにします。
Redis Cluster はコミュニティ バージョンによって開始された Redis 分散クラスター ソリューションであり、主に単一マシンのメモリ、同時実行性、およびボトルネックがある場合、Redis Cluster は適切な負荷分散の目的を達成できます。
Redis Cluster クラスター ノードの最小構成は 6 ノード (3 つのマスターと 3 つのスレーブ) を超えています。マスター ノードは読み取りおよび書き込み操作を提供し、スレーブ ノードはバックアップ ノードとして機能しますが、これらのノードは提供されません。リクエストを処理し、フェイルオーバーのみに使用されます。
Redis Cluster は仮想スロット パーティショニングを使用します。すべてのキーは、ハッシュ関数に従って 0 ~ 16383 の整数スロットにマッピングされます。各ノードは、スロットの一部とスロットによってマッピングされたキー値データを維持する責任があります。
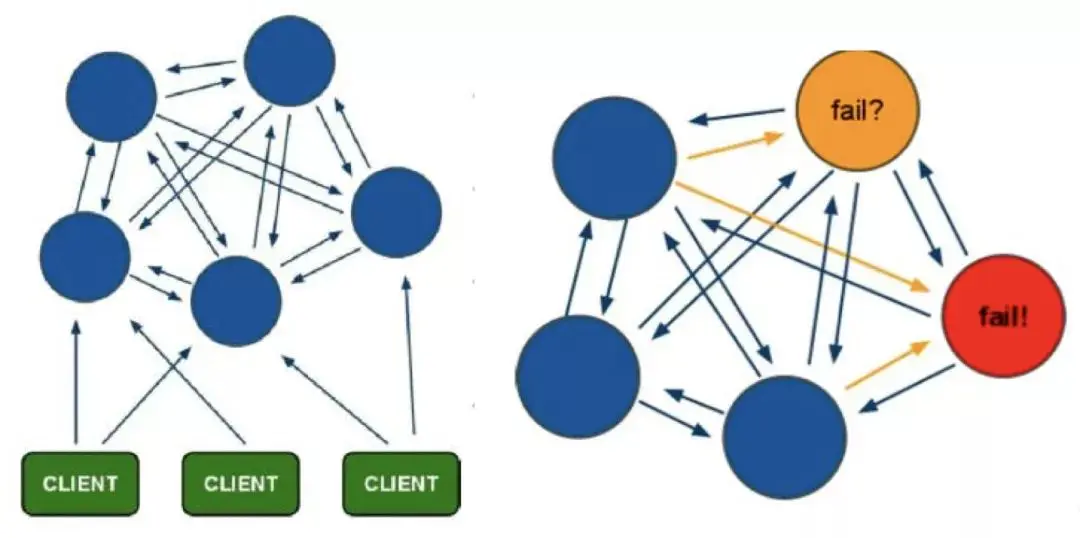
利点:
中央アーキテクチャなし;
データはスロットとデータに従って複数のノードに保存および分散されます。ノード間で共有され、データ分散を動的に調整できます。
スケーラビリティ: 1,000 を超えるノードに線形的に拡張でき、ノードを動的に追加または削除できます。
高可用性: 一部のノードがは使用できませんが、クラスターは引き続き使用できます。スレーブをスタンバイ データ コピーとして追加することで、自動フェイルオーバーを実現できます。ノードはゴシップ プロトコルを通じてステータス情報を交換し、投票メカニズムを使用してスレーブからマスターへの役割の昇格を完了します。
操作とメンテナンスコストを削減し、システム拡張のパフォーマンスと可用性を向上させます。
欠点:
クライアントの実装は複雑で、ドライバーにはスロット マッピング情報をキャッシュし、タイムリーに更新するスマート クライアントの実装が必要であるため、開発の難易度が高くなります。クライアントの状況はビジネスの安定性に影響を与えます。現時点では、JedisCluster のみが比較的成熟しており、一般的な「最大リダイレクト例外」などの例外処理部分はまだ完全ではありません。
ノードは何らかの理由によりブロックされ(ブロック時間がclutser-node-timeoutを超えている)、オフラインと判断されるため、この種のフェイルオーバーは必要ありません。
データは非同期的にレプリケートされるため、データの強い一貫性は保証されません。
複数の企業が同じクラスタを利用する場合、ホットデータとコールドデータが統計的に区別できず、リソースの分離が悪く相互影響が生じやすくなります。
スレーブはクラスター内で「コールド スタンバイ」として機能し、読み取りプレッシャーを軽減できません。もちろん、SDK の合理的な設計により、スレーブ リソースの使用率を改善できます。
mset や mget の使用などのキーのバッチ操作の制限では、現在、バッチ操作を実行するために同じスロット値を持つキーのみがサポートされています。異なるスロット値にマップされたキーの場合、キーはスロット間のクエリをサポートしていないため、mset、mget、sunion などの操作を実行するのはユーザーフレンドリーではありません。
キー トランザクション操作のサポートは制限されており、同一ノード上の複数キー トランザクション操作のみサポートされており、複数のキーが異なるノードに分散されている場合、トランザクション機能は使用できません。
データ パーティショニングではキーが最小の粒度であるため、大きなキー値オブジェクト (ハッシュ、リストなど) を含むデータを別のノードにマップすることはできません。
複数のデータベース スペースはサポートされません。スタンドアロン モードの Redis は、最大 16 のデータベースをサポートできます。クラスター モードでは、1 つのデータベース スペース (db 0) のみを使用できます。
レプリケーション構造は 1 つのレベルのみをサポートします。スレーブ ノードはマスター ノードのみをレプリケートでき、ネストされたツリー レプリケーション構造はサポートされません。
メイン データベース ノードがシステムの欠点となるホットキーの生成を避けてください。
ネットワーク カードの過負荷やクエリの遅延などを引き起こす可能性があるビッグキーの生成は避けてください。
再試行時間は、クラスターノード時間よりも長くする必要があります。
Redis クラスターでは、最大リダイレクト シナリオを減らすためにパイプライン操作と複数キー操作を使用することはお勧めしません。
「JVM、ロック、高同時実行性、リフレクション、Spring 原則、マイクロサービス、Zookeeper、データベース、データ構造などをカバーする」インタビュー ガイド「Java Core Knowledge Points Compilation.pdf」を共有します。 Java208 のインタビューの質問 (回答を含む) がある場合は、(Java Advanced Architecture) 705127209 に参加して無料で質問を入手してください。
Redis が自社開発した高可用性ソリューションは、主に構成センター、障害検出、フェイルオーバー処理メカニズムに反映されており、通常は実際のシステムに基づく必要があります。企業のオンライン ビジネス環境をカスタマイズします。
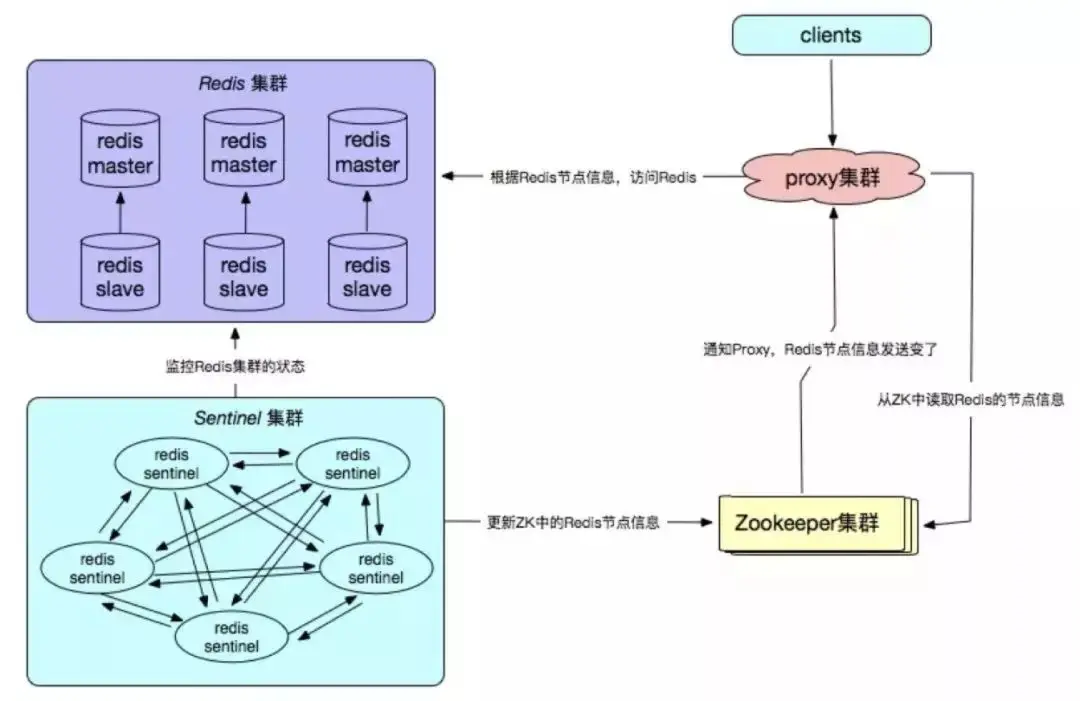
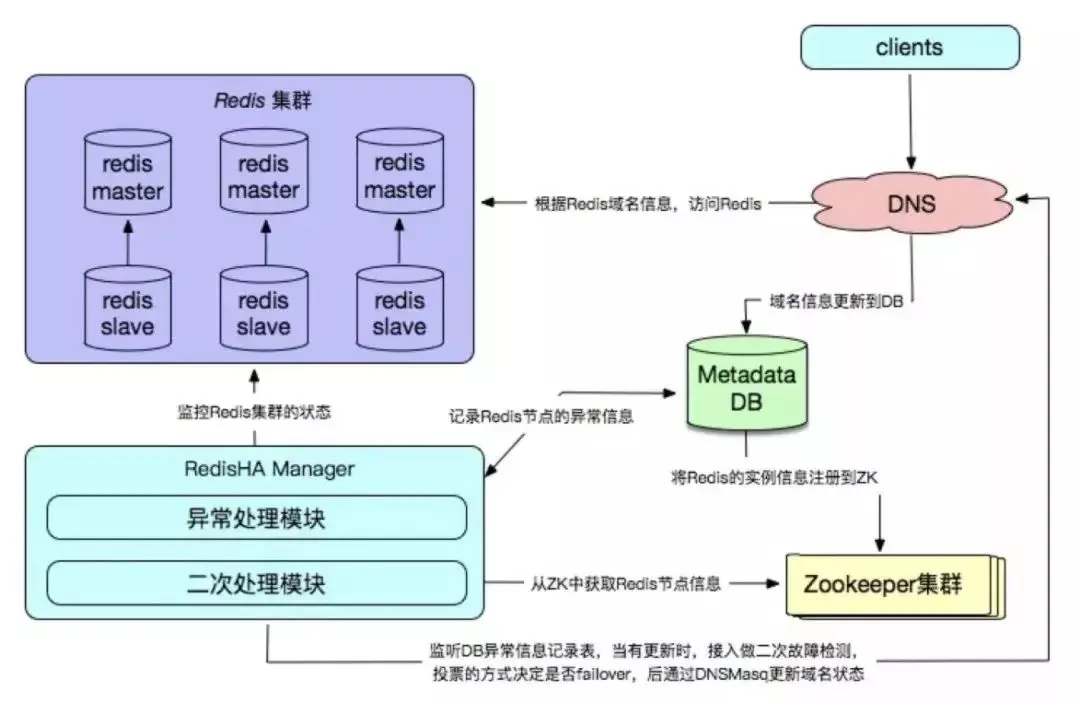
利点:
高信頼性と高可用性;
高い自律性と制御性;
適切なビジネス 実際のニーズ、優れた拡張性と優れた互換性。
欠点:
複雑な実装と高い開発コスト;
監視、ドメイン名サービス、メタデータ情報を保存するデータベースなどのサポート周辺機能の確立が必要.;
高額なメンテナンス費用。
以上がRedis の一般的な使用方法は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



