


Catboost を使用して、RNN、ARIMA、Prophet モデルから予測用の信号を抽出します。
さまざまな弱学習器を統合すると予測精度を向上させることができますが、モデルがすでに非常に強力である場合、アンサンブル学習がおまけになることがよくあります。人気の機械学習ライブラリ scikit-learn は、時系列タスクに使用できる StackingRegressor を提供します。ただし、StackingRegressor には制限があり、他の scikit-learn モデル クラスと API のみを受け入れます。したがって、scikit-learn で利用できない ARIMA のようなモデルやディープ ニューラル ネットワークのモデルは使用できません。この投稿では、確認できるモデルの予測を積み重ねる方法を説明します。

次のパッケージを使用します:
pip install --upgrade scalecast conda install tensorflow conda install shap conda install -c conda-forge cmdstanpy pip install prophet
データセットは 1 時間ごとに生成され、トレーニング セット (700 個の観察) とテスト セット (48 個の観察) に分割されます。次のコードはデータを読み取り、Forecaster オブジェクトに保存します。
import pandas as pd import numpy as np from scalecast.Forecaster import Forecaster from scalecast.util import metrics import matplotlib.pyplot as plt import seaborn as sns def read_data(idx = 'H1', cis = True, metrics = ['smape']): info = pd.read_csv( 'M4-info.csv', index_col=0, parse_dates=['StartingDate'], dayfirst=True, ) train = pd.read_csv( f'Hourly-train.csv', index_col=0, ).loc[idx] test = pd.read_csv( f'Hourly-test.csv', index_col=0, ).loc[idx] y = train.values sd = info.loc[idx,'StartingDate'] fcst_horizon = info.loc[idx,'Horizon'] cd = pd.date_range( start = sd, freq = 'H', periods = len(y), ) f = Forecaster( y = y, # observed values current_dates = cd, # current dates future_dates = fcst_horizon, # forecast length test_length = fcst_horizon, # test-set length cis = cis, # whether to evaluate intervals for each model metrics = metrics, # what metrics to evaluate ) return f, test.values f, test_set = read_data() f # display the Forecaster object
f.set_estimator('naive')
f.manual_forecast(seasonal=True)f.set_estimator('arima')
f.manual_forecast(
order = (5,1,4),
seasonal_order = (1,1,1,24),
call_me = 'manual_arima',
)f.set_estimator('rnn')
f.manual_forecast(
lags = 48,
layers_struct=[
('LSTM',{'units':100,'activation':'tanh'}),
('LSTM',{'units':100,'activation':'tanh'}),
('LSTM',{'units':100,'activation':'tanh'}),
],
optimizer = 'Adam',
epochs = 15,
plot_loss = True,
validation_split=0.2,
call_me = 'rnn_tanh_activation',
)
f.manual_forecast(
lags = 48,
layers_struct=[
('LSTM',{'units':100,'activation':'relu'}),
('LSTM',{'units':100,'activation':'relu'}),
('LSTM',{'units':100,'activation':'relu'}),
],
optimizer = 'Adam',
epochs = 15,
plot_loss = True,
validation_split=0.2,
call_me = 'rnn_relu_activation',
)f.set_estimator('prophet')
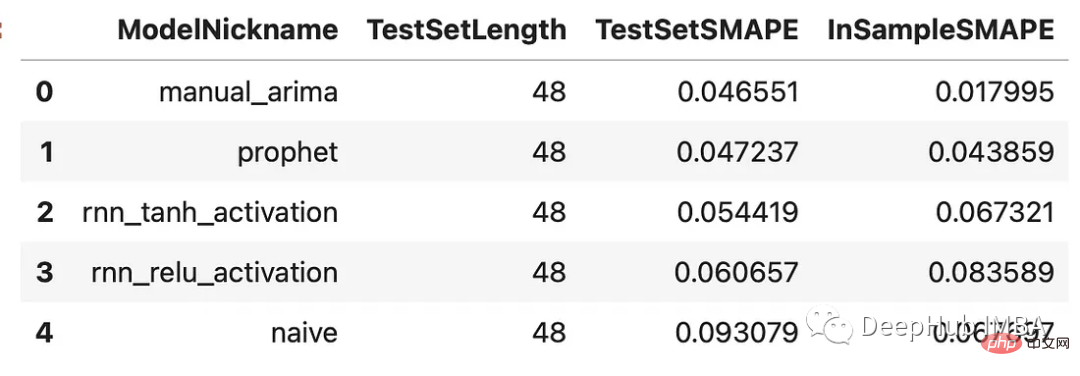
f.manual_forecast()results = f.export(determine_best_by='TestSetSMAPE') ms = results['model_summaries'] ms[ [ 'ModelNickname', 'TestSetLength', 'TestSetSMAPE', 'InSampleSMAPE', ] ]
f.plot(order_by="TestSetSMAPE",ci=True) plt.show()

f.add_signals(
f.history.keys(), # add signals from all previously evaluated models
)
f.add_ar_terms(48)
f.set_estimator('catboost')f.manual_forecast(
Xvars='all',
call_me='catboost_all_reg',
verbose = False,
)
f.manual_forecast(
Xvars=[x for x in f.get_regressor_names() if x.startswith('AR')],
call_me = 'catboost_lags_only',
verbose = False,
)
f.manual_forecast(
Xvars=[x for x in f.get_regressor_names() if not x.startswith('AR')],
call_me = 'catboost_signals_only',
verbose = False,
)test_results = pd.DataFrame(index = f.history.keys(),columns = ['smape','mase'])
for k, v in f.history.items():
test_results.loc[k,['smape','mase']] = [
metrics.smape(test_set,v['Forecast']),
metrics.mase(test_set,v['Forecast'],m=24,obs=f.y),
]
test_results.sort_values('smape')
可以看到,通过组合来自不同类型模型的信号生成了两个优于其他估计器的估计器:使用所有信号训练的Catboost模型和只使用信号的Catboost模型。这两种方法的样本误差都在2.8%左右。下面是对比图:
fig, ax = plt.subplots(figsize=(12,6)) f.plot( models = ['catboost_all_reg','catboost_signals_only'], ci=True, ax = ax ) sns.lineplot( x = f.future_dates, y = test_set, ax = ax, label = 'held out actuals', color = 'darkblue', alpha = .75, ) plt.show()

为了完善分析,我们可以使用shapley评分来确定哪些信号是最重要的。Shapley评分被认为是确定给定机器学习模型中输入的预测能力的最先进的方法之一。得分越高,意味着输入在特定模型中越重要。
f.export_feature_importance('catboost_all_reg')
上面的图只显示了前几个最重要的预测因子,但我们可以从中看出,ARIMA信号是最重要的,其次是序列的第一个滞后,然后是Prophet。RNN模型的得分也高于许多滞后模型。如果我们想在未来训练一个更轻量的模型,这可能是一个很好的起点。
在这篇文章中,我展示了在时间序列上下文中集成模型的力量,以及如何使用不同的模型在时间序列上获得更高的精度。这里我们使用scalecast包,这个包的功能还是很强大的,如果你喜欢,可以去它的主页看看:https://github.com/mikekeith52/scalecast
本文的数据集是M4的时序竞赛:https://github.com/Mcompetitions/M4-methods
使用代码在这里:https://scalecast-examples.readthedocs.io/en/latest/misc/stacking/custom_stacking.html
以上が時系列モデルを統合して予測精度を向上させるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



