


事前トレーニング時代に入ってから、視覚認識モデルの性能は急速に発展しましたが、敵対的生成ネットワーク (GAN) などの画像生成モデルは遅れを取っているようです。
通常、GAN トレーニングは教師なしでゼロから行われるため、時間と労力がかかり、大規模な事前トレーニングでビッグデータから学習した「知識」は活用されません。それは大きな損失ですか?
さらに、画像生成自体が、現実世界の視覚現象における複雑な統計データをキャプチャしてシミュレートできる必要があります。そうでない場合、生成された画像は物理世界の法則に準拠せず、直接識別されてしまいます。一目見て「偽物」とわかります。

事前トレーニング済みモデルは知識を提供し、GAN モデルは生成機能を提供します。この 2 つの組み合わせはおそらく素晴らしいものです。
問題は、どの事前トレーニング済みモデルとそれらをどのように組み合わせることで GAN モデルの生成能力を向上できるのかということです。
最近、CMU と Adobe の研究者は、事前トレーニング モデルと「選択」による GAN モデルのトレーニングを組み合わせた記事を CVPR 2022 に発表しました。

論文リンク: https://arxiv.org/abs/2112.09130
プロジェクトリンク: https://github.com/nupurkmr9/vision- aided-gan
ビデオリンク: https://www.youtube.com/watch?v=oHdyJNdQ9E4
GAN モデルのトレーニング プロセスは、弁別器と生成器で構成されます。 discriminator ジェネレーターは、実際のサンプルと生成されたサンプルを区別する関連統計を学習するために使用されますが、ジェネレーターの目的は、生成された画像を実際の分布と可能な限り一致させることです。
理想的には、識別器は、生成された画像と実際の画像の間の分布ギャップを測定できる必要があります。
しかし、データ量が非常に限られている場合、大規模な事前トレーニング済みモデルを識別子として直接使用すると、ジェネレーターが「容赦なく潰され」、その後「過剰適合」してしまう可能性が簡単にあります。
FFHQ 1k データセットでの実験によると、最新の微分可能データ拡張手法を使用した場合でも、識別器は依然として過学習状態になります。トレーニング セットのパフォーマンスは非常に強力ですが、検証セットではパフォーマンスが非常に低くなります。 。 違い。
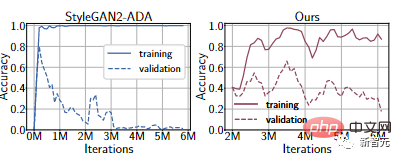
# さらに、識別子は、人間には識別できないが機械には明らかな変装に焦点を当てる場合があります。
ディスクリミネーターとジェネレーターの機能のバランスをとるために、研究者は、事前トレーニングされたモデルの異なるセットの表現をディスクリミネーターとして組み立てることを提案しました。
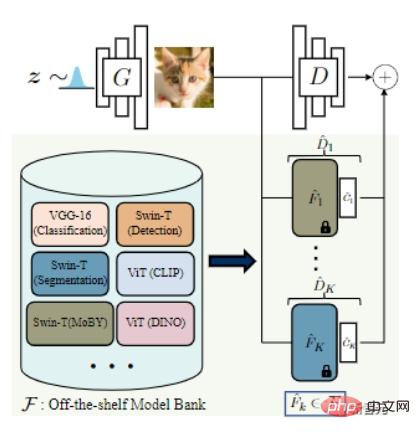
この方法には 2 つの利点があります:
1. 事前にトレーニングされた特徴に基づいて浅い分類器をトレーニングすることで、深いネットワークを小規模なスケールに適応させることができます。過学習を抑えながらデータセットの最適化を実現します。
つまり、事前学習モデルのパラメータを固定し、最上位層に軽量な分類ネットワークを追加する限り、安定した学習プロセスを提供できます。
たとえば、上記の実験の Ours 曲線から、検証セットの精度が StyleGAN2-ADA と比較して大幅に向上していることがわかります。
2. いくつかの最近の研究では、ディープ ネットワークが、低レベルの視覚的手がかり (エッジやテクスチャ) から高レベルの概念 (オブジェクトやオブジェクトのパーツ) に至るまで、意味のある視覚概念をキャプチャできることが証明されています。
これらの特徴に基づく識別子は、人間の知覚により一致する可能性があります。
そして、複数の事前トレーニング済みモデルを組み合わせることで、ジェネレーターが異なる相補的な特徴空間における実際の分布と一致するように促進できます。
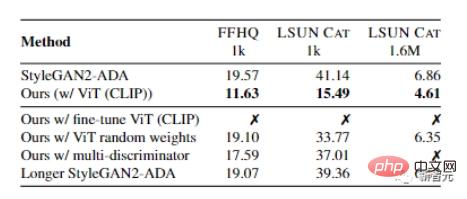
最適な事前トレーニング ネットワークを選択するために、研究者らはまず、分類用の VGG-16 と検出とセグメンテーション用の Swin-T を含む、複数の sota モデルを収集して「モデル バンク」を形成しました。
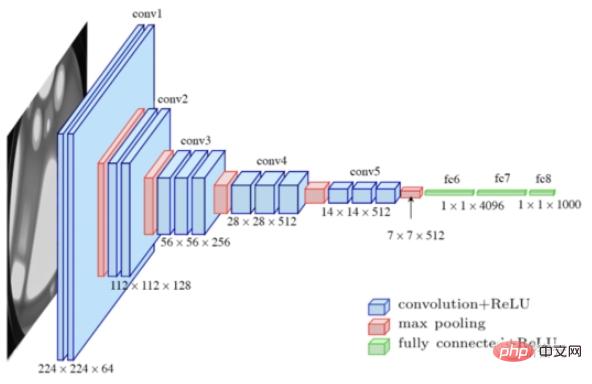
次に、特徴空間内の本物の画像と偽の画像の線形セグメンテーションに基づいて、自動モデル検索戦略が提案され、ラベルの平滑化と微分可能な強化技術が使用されて、さらにモデルのトレーニングを安定させて過学習を軽減します。
具体的には、実際のトレーニング サンプルと生成された画像の結合は、トレーニング セットと検証セットに分割されます。
事前トレーニングされたモデルごとに、論理線形弁別器をトレーニングして、サンプルが実際のサンプルからのものであるか、生成されたサンプルからのものであるかを分類し、検証分割で「負のバイナリ クロスエントロピー損失」を使用して、分布ギャップを計算し、誤差が最小のモデルを返します。
検証誤差が低いほど、線形検出精度が高くなります。これは、これらの機能が実際のサンプルと生成されたサンプルを区別するのに役立つことを示しており、これらの機能を使用すると、ジェネレーターにより有用なフィードバックを提供できます。
研究者 私たちは、FFHQ および LSUN CAT データセットからの 1000 個のトレーニング サンプルを使用して、GAN トレーニングを経験的に検証しました。
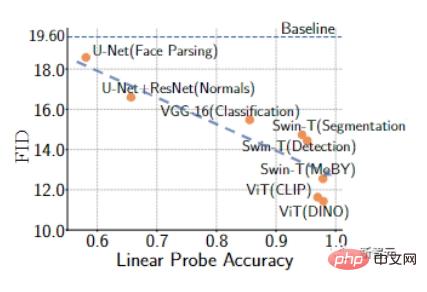
 結果は、事前トレーニング済みモデルでトレーニングされた GAN の線形検出精度が高く、一般的に言えば、より優れた FID 指標を達成できることを示しています。
結果は、事前トレーニング済みモデルでトレーニングされた GAN の線形検出精度が高く、一般的に言えば、より優れた FID 指標を達成できることを示しています。
複数の既製モデルからのフィードバックを組み込むために、この記事では 2 つのモデル選択および統合戦略についても検討します。
1) K 固定モデル選択戦略。K 個の最適なモデルを選択します。トレーニングの開始 既製のモデルと収束までトレーニング;
2) K-プログレッシブ モデル選択戦略、固定回数の反復後に最もパフォーマンスの高い未使用のモデルを繰り返し選択して追加します。
実験結果は、K 固定戦略と比較して、プログレッシブ アプローチは計算の複雑さが低く、データ分布の違いを捉える事前トレーニング済みモデルの選択にも役立つことを示しています。たとえば、プログレッシブ戦略によって選択される最初の 2 つのモデルは、通常、自己教師ありモデルと教師ありモデルのペアです。
この記事の実験は主に進歩的なものです。
最終トレーニング アルゴリズムでは、最初に標準的な敵対的損失で GAN をトレーニングします。

 ベースライン ジェネレーターが与えられた場合、線形プローブを使用して、最適な事前トレーニング済みモデルを検索し、トレーニング中に損失目的関数を導入できます。
ベースライン ジェネレーターが与えられた場合、線形プローブを使用して、最適な事前トレーニング済みモデルを検索し、トレーニング中に損失目的関数を導入できます。
K プログレッシブ戦略では、利用可能な実際のトレーニング サンプルの数に比例する固定回数の反復でトレーニングした後、スナップショット内の最適なトレーニング セットを使用して、新しい視覚的補助識別器が前のステージに追加されます。 FIDの。
トレーニング プロセス中、データ拡張は水平反転によって実行され、微分可能拡張手法と片側ラベル平滑化が正則化用語として使用されます。
また、既製のモデルのみを識別子として使用すると発散が生じる一方、オリジナルの識別子と事前トレーニングされたモデルを組み合わせることでこの状況を改善できることも観察できます。
最後の実験は、FFHQ、LSUN CAT、および LSUN CHURCH データセットのトレーニング サンプルが 1k から 10k まで変化した場合の結果を示しています。
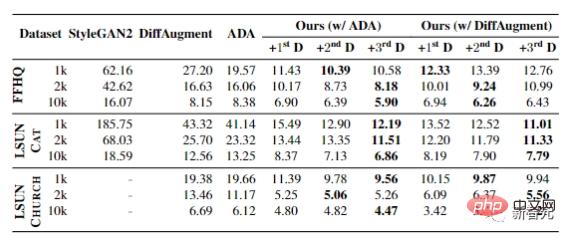
 すべての設定において、FID は大幅な改善を達成でき、限られたデータ シナリオにおけるこの方法の有効性を証明します。
すべての設定において、FID は大幅な改善を達成でき、限られたデータ シナリオにおけるこの方法の有効性を証明します。
この方法と StyleGAN2-ADA の違いを定性的に分析するために、2 つの方法で生成されたサンプルの品質に従って、記事で提案されている新しい方法は、特に最悪のサンプルの品質を改善できます。 FFHQ および LSUN CAT の場合

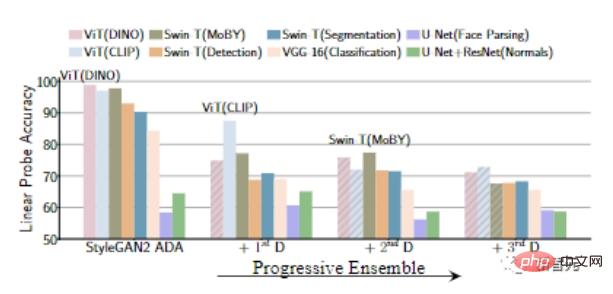
 次の識別子を徐々に追加すると、事前トレーニングされたモデルの特徴に対する線形検出の精度が徐々に減少、つまりジェネレーターが強くなります。
次の識別子を徐々に追加すると、事前トレーニングされたモデルの特徴に対する線形検出の精度が徐々に減少、つまりジェネレーターが強くなります。
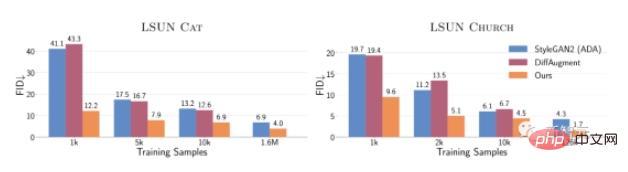
 全体として、わずか 10,000 個のトレーニング サンプルを使用したこの方法は、160 万枚の画像でトレーニングするよりも、LSUN CAT の FID でのパフォーマンスが優れています。StyleGAN2 のパフォーマンスも同様です。
全体として、わずか 10,000 個のトレーニング サンプルを使用したこの方法は、160 万枚の画像でトレーニングするよりも、LSUN CAT の FID でのパフォーマンスが優れています。StyleGAN2 のパフォーマンスも同様です。
 完全なデータセットでは、この方法により、LSUN の猫、教会、馬のカテゴリで FID が 1.5 ~ 2 倍向上します。
完全なデータセットでは、この方法により、LSUN の猫、教会、馬のカテゴリで FID が 1.5 ~ 2 倍向上します。

著者のリチャード・チャンは、カリフォルニア大学バークレー校で博士号を取得し、コーネル大学で学士号と修士号を取得しました。主な研究対象には、コンピュータ ビジョン、機械学習、ディープ ラーニング、グラフィックス、画像処理などがあり、インターンシップや大学を通じて学術研究者と協力することもよくあります。

 著者の Jun-Yan Zhu は、カーネギー メロン大学コンピューター サイエンス学部ロボット工学部の助教授であり、コンピューター サイエンスと機械学習部門。主な研究分野には、コンピューター ビジョン、コンピューター グラフィックス、機械学習、コンピュテーショナル フォトグラフィーが含まれます。
著者の Jun-Yan Zhu は、カーネギー メロン大学コンピューター サイエンス学部ロボット工学部の助教授であり、コンピューター サイエンスと機械学習部門。主な研究分野には、コンピューター ビジョン、コンピューター グラフィックス、機械学習、コンピュテーショナル フォトグラフィーが含まれます。
CMU に入社する前は、Adobe Research の研究員でした。彼は清華大学を卒業して学士号を取得し、カリフォルニア大学バークレー校で博士号を取得し、その後、MIT CSAIL で博士研究員として働いていました。

 #
#
以上がCMU が Adobe と提携: GAN モデルは事前トレーニングの時代を到来させ、トレーニング サンプルのわずか 1% しか必要としませんの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



