


arXiv 論文「ST-P3: 時空間特徴学習によるエンドツーエンドのビジョンベースの自動運転」、7 月 22 日、上海交通大学、上海 AI 研究所、カリフォルニア大学サンディエゴ校、JD の著者。 com 北京研究所。

ST-P3 と呼ばれる、知覚、予測、計画タスクのためのより代表的な特徴のセットを同時に提供できる時空間特徴学習スキームを提案します。具体的には、BEV 変換を感知する前に 3 次元空間に幾何学的情報を保持する自己中心的調整累積手法が提案されており、著者は、将来の予測のために過去の動きの変化が考慮されるように二重経路モデルを設計しています。計画された視覚要素の認識を補うために、洗練ユニットが導入されました。ソース コード、モデル、プロトコルの詳細はオープン ソースhttps://github.com/OpenPerceptionX/ST-P3.
先駆的な LSS 手法は、マルチビュー カメラから遠近感特徴を抽出し、深さ推定を通じてそれらを 3D に引き上げ、BEV 空間に融合します。 2 つのビュー間の特徴変換。潜在深度予測が重要です。
2 次元の平面情報を 3 次元にアップグレードするには、追加の次元、つまり 3 次元の幾何学的自動運転タスクに適した深さが必要です。ほとんどのシーンにはビデオ ソースが割り当てられているため、特徴表現をさらに改善するには、時間情報をフレームワークに組み込むのが自然です。
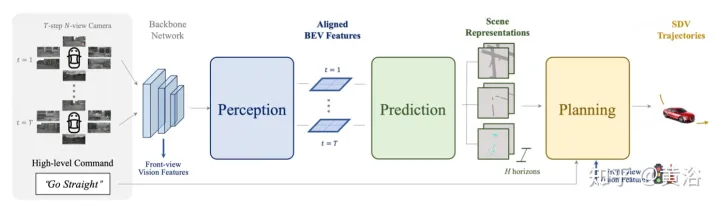
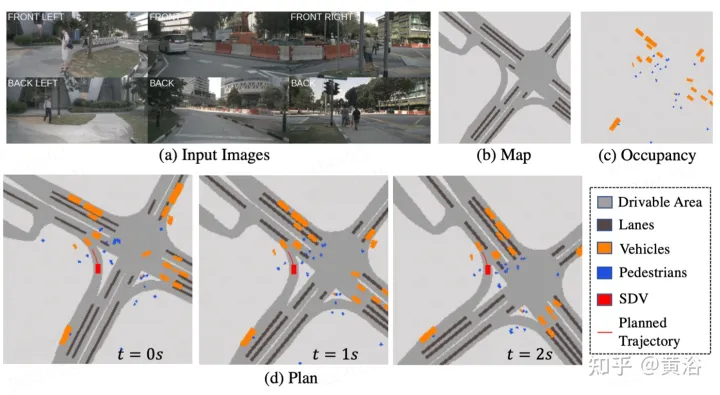
図で説明されているST- P3全体的なフレームワーク: 具体的には、周囲のカメラ ビデオのセットが与えられると、それらをバックボーンに入力して、予備的な正面図の特徴を生成します。補助的な深度推定を実行して、2D フィーチャを 3D 空間に変換します。自己中心位置合わせ累積スキームは、まず過去のフィーチャを現在のビュー座標系に位置合わせします。その後、現在および過去のフィーチャが 3 次元空間に集約され、BEV 表現に変換する前に幾何学的情報が保存されます。一般的に使用される prediction 時間領域モデルに加えて、過去の動きの変化を説明する 2 番目のパスを構築することで、パフォーマンスがさらに向上します。このデュアルパス モデリングにより、将来のセマンティックな結果を推測するためのより強力な特徴表現が保証されます。軌道 計画 という最終目標を達成するために、ネットワークの初期機能の事前知識が統合されます。改良モジュールは、HD マップがない場合でも高レベルのコマンドを使用して最終的な軌道を生成するように設計されました。
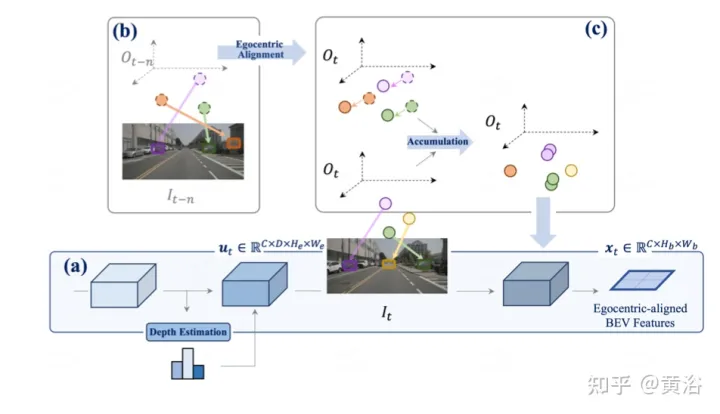
図は、知覚の自己中心的調整蓄積法を示しています。 (a) 深度推定を利用して現在のタイムスタンプの特徴を 3D に引き上げ、位置合わせ後に BEV 特徴にマージします; (b-c) 前のフレームの 3D 特徴を現在のフレーム ビューと位置合わせし、過去および現在のすべての状態と融合します。特徴表現を強化します。
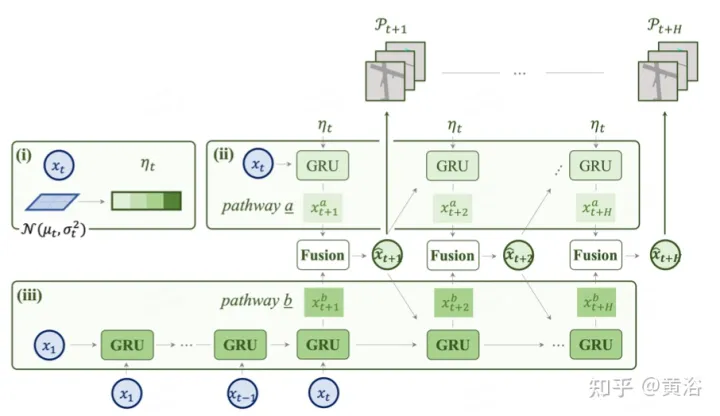
図に示されているのは、prediction に使用される 2 方向モデルです。 (i) 潜在コードは特徴マップからの分布です。 (ii iii) ロード a には、将来のマルチモダリティを示す不確実性分布が組み込まれていますが、パス b は過去の変化から学習し、パス a の情報を補うのに役立ちます。
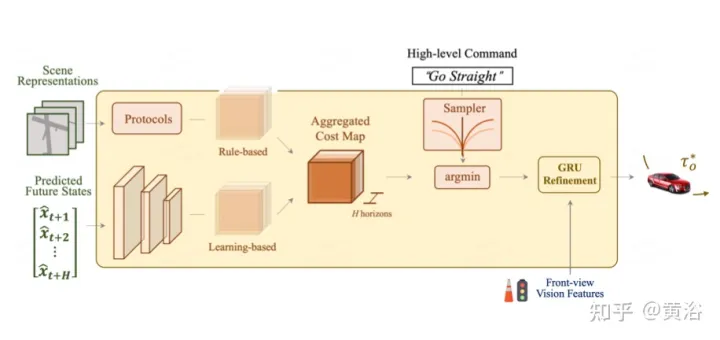
#最終的な目標として、目標点に到達するための安全で快適な軌道を計画する必要があります。このモーション プランナーは、さまざまな軌道のセットをサンプリングし、学習されたコスト関数を最小化する軌道を選択します。ただし、ターゲット ポイントや信号機からの情報をタイム ドメイン モデルを通じて統合すると、追加の最適化手順が追加されます。
この図は、計画のための事前知識の統合と改良を示しています。全体のコスト図には 2 つのサブコストが含まれています。カメラ入力からのビジョンベースの情報を集約する将来予測機能を使用して、最小コストの軌道がさらに再定義されます。
大きな横加速度、ジャーク、または曲率を伴う軌道にペナルティを与えます。この軌道が効率的に目的地に到達し、前進が報われることを願っています。ただし、上記のコスト項目には、通常ルートマップで提供されるターゲット情報は含まれません。前進、左折、右折などの高レベルのコマンドを使用し、対応するコマンドのみに基づいて軌道を評価します。
さらに、SDV にとって信号機は、GRU ネットワークを通じて軌道を最適化するために不可欠です。隠れ状態はエンコーダ モジュールのフロント カメラ機能で初期化され、コスト項の各サンプル ポイントが入力として使用されます。
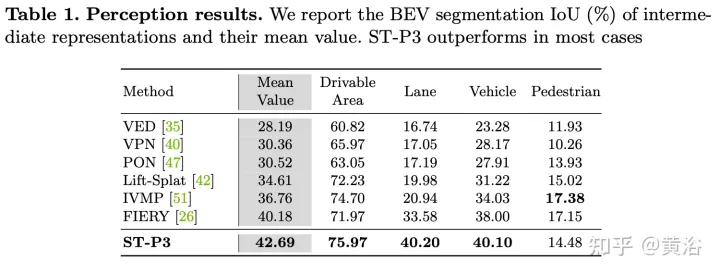
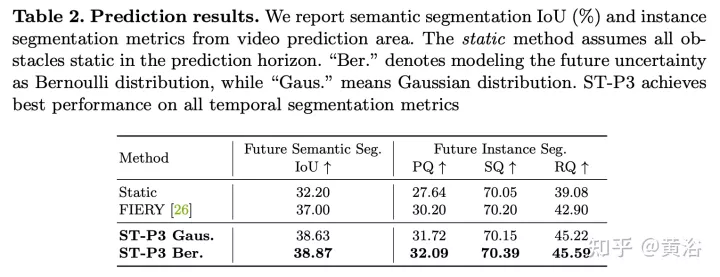
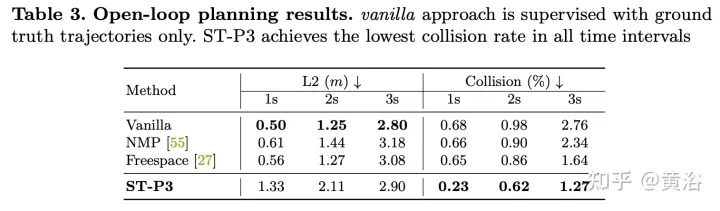
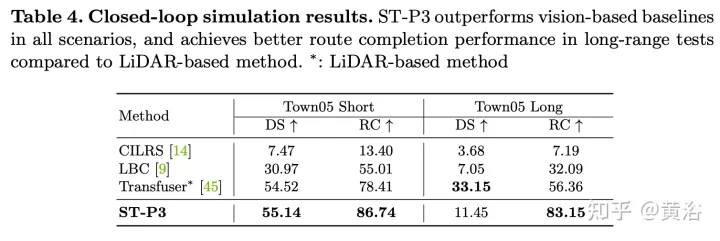
実験結果は次のとおりです:
 #
#
以上がST-P3: 自動運転のためのエンドツーエンドの時空間特徴学習ビジョン手法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



