

この記事では、Redis について詳しく学び、永続性を詳細に分析し、その動作原理や永続化プロセスなどを紹介します。お役に立てば幸いです。
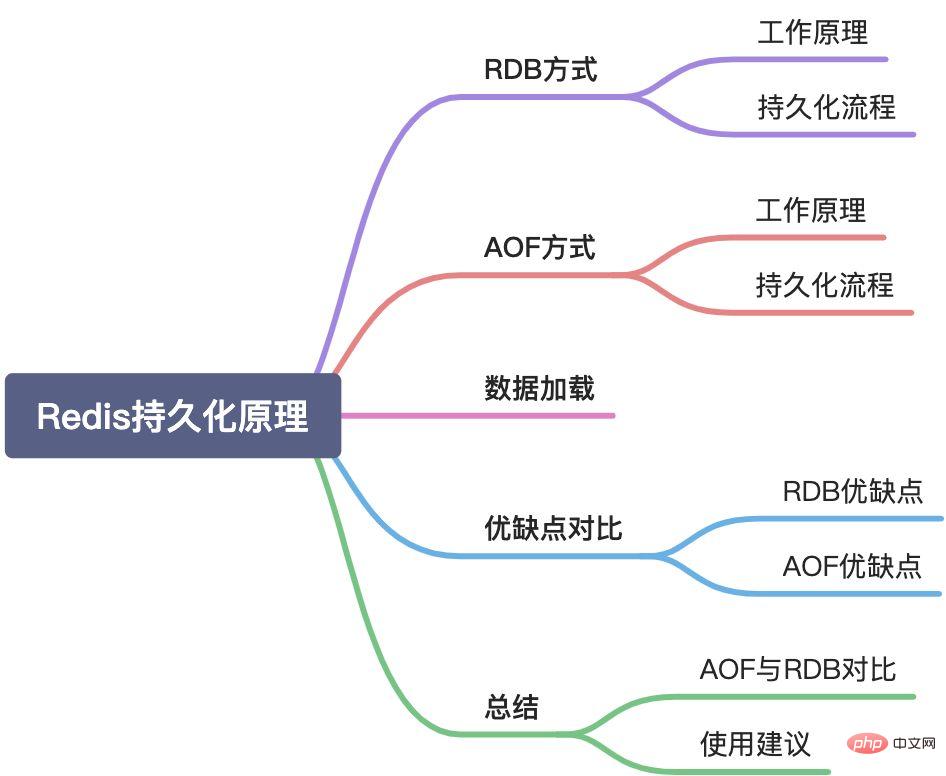
この記事では、次の側面から Redis の永続化メカニズムを紹介します。
 ## 前に書いてあります
## 前に書いてあります
この記事は全体的に詳しく説明されていますRedis の 2 つの永続化メソッドを、動作原理、永続化プロセス、実践的な戦略、およびその背後にある理論的知識を含めて紹介します。前回の記事ではRDBの永続化についてのみ紹介しましたが、Redisの永続化は全体であり個別に紹介できないため再整理しました。 [関連する推奨事項: Redis ビデオ チュートリアル]
Redis はインメモリ データベースです。すべてのデータはメモリに保存されます。これは、MySQL、Oracle、 Redis はハードディスクにデータを保存する場合と比べて、読み書き効率が非常に高いです。ただし、メモリへの保存には大きな欠点があり、電源が切れたり、コンピュータがダウンしたりすると、メモリ データベースの内容はすべて失われます。この欠点を補うために、Redis では、メモリ データをハードディスク ファイルに永続化し、バックアップ ファイルを通じてデータを復元する機能 (Redis 永続化メカニズム) を提供します。
Redis は、RDB スナップショットと AOF という 2 つの永続化方法をサポートしています。
RDB スナップショット 正式な言葉: RDB 永続性ソリューションは、指定された時間間隔でデータ セットに対して生成されるポイントツータイム スナップショットです。特定の時点での Redis データベース内のすべてのデータ オブジェクトのメモリ スナップショットを圧縮バイナリ ファイルに保存します。これは、Redis データのバックアップ、転送、リカバリに使用できます。これまでのところ、これはまだ公式のデフォルトのサポート ソリューションです。
RDB は Redis 内のデータセットの特定時点のスナップショットであるため、まず Redis 内のデータ オブジェクトがどのようにメモリ内に保存され編成されるかを簡単に理解しましょう。
デフォルトでは、Redis には 16 のデータベースがあり、0 ~ 15 の番号が付けられています。各 Redis データベースはredisDbオブジェクトによって表され、redisDbはハッシュテーブル ストレージ K-V オブジェクトを使用します。理解を容易にするために、データベースの 1 つを例として、Redis の内部データのストレージ構造の概略図を描きました。

ポイントインタイム スナップショットは、特定の瞬間における Redis の各 DB 内の各データ オブジェクトのステータスです。データ オブジェクトは変更されなくなりました。これらのデータ オブジェクトを 1 つずつ読み取り、上図のデータ構造関係に従ってファイルに書き込むことで、Redis の永続性を実現できます。その後、Redis が再起動すると、このファイルの内容がルールに従って読み取られ、Redis メモリに書き込まれて永続的な状態に復元されます。
RDB 永続化のトリガーは、上記の 2 つのメソッドから分離できない必要があります。トリガー方法は手動と自動に分けられます。手動トリガーは理解しやすいです。これは、Redis クライアントを通じて Redis サーバーへの永続化バックアップ命令を手動で開始し、Redis サーバーが永続化プロセスの実行を開始することを意味します。ここでの命令には、save と bgsave が含まれます。自動トリガーは、独自の動作要件に基づいて事前に設定された条件が満たされたときに Redis が自動的にトリガーする永続化プロセスです。自動トリガーされるシナリオは次のとおりです (この記事から抜粋):
save m n構成ルールは自動的にトリガーされます;debug reloadコマンドが redis を再ロードするとき;ソース コードと参考記事を組み合わせて、全体的な理解を助けるために RDB 永続化プロセスを整理し、その後、いくつか詳細に説明します。
上の図からわかるように:
rdbSaveメソッドをブロック的に呼び出すことで完了します。自動トリガー プロセスは、rdbSaveBackground、rdbSave などをカバーする完全なリンクです。次に、プロセス全体を分析するための例として、serverCron を使用します。
serverCron は Redis の定期関数であり、100 ミリ秒ごとに実行されます。そのジョブの 1 つは、構成ファイル内の保存ルールに基づいて現在の状況を判断することです。自動永続化プロセスが必要であり、条件が満たされると永続化の開始が試行されます。この部分の実装について学習します。
redisServerには RDB の永続化に関連するフィールドがいくつかあります。コードからそれらを抽出し、中国語と英語で調べました:
struct redisServer { /* 省略其他字段 */ /* RDB persistence */ long long dirty; /* Changes to DB from the last save * 上次持久化后修改key的次数 */ struct saveparam *saveparams; /* Save points array for RDB, * 对应配置文件多个save参数 */ int saveparamslen; /* Number of saving points, * save参数的数量 */ time_t lastsave; /* Unix time of last successful save * 上次持久化时间*/ /* 省略其他字段 */ } /* 对应redis.conf中的save参数 */ struct saveparam { time_t seconds; /* 统计时间范围 */ int changes; /* 数据修改次数 */ };
saveparamsは、redis.confの保存ルールに対応します。保存パラメータは、Redis が自動バックアップをトリガーするためのトリガー戦略です。秒は統計時間 (単位: 秒)、changesは、統計時間内に発生した書き込みの数です。save m nは、m 秒以内に n 回の書き込みがある場合、スナップショット、つまりバックアップがトリガーされることを意味します。保存パラメータの複数のグループを構成して、さまざまな条件下でのバックアップ要件を満たすことができます。 RDB の自動バックアップ ポリシーをオフにする必要がある場合は、save ""を使用できます。以下に、いくつかの構成について説明します。
# 表示900秒(15分钟)内至少有1个key的值发生变化,则执行 save 900 1 # 表示300秒(5分钟)内至少有1个key的值发生变化,则执行 save 300 10 # 表示60秒(1分钟)内至少有10000个key的值发生变化,则执行 save 60 10000 # 该配置将会关闭RDB方式的持久化 save ""
serverCronRDB 保存ルールの検出コードは次のとおりです。
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) { /* 省略其他逻辑 */ /* 如果用户请求进行AOF文件重写时,Redis正在执行RDB持久化,Redis会安排在RDB持久化完成后执行AOF文件重写, * 如果aof_rewrite_scheduled为true,说明需要执行用户的请求 */ /* Check if a background saving or AOF rewrite in progress terminated. */ if (hasActiveChildProcess() || ldbPendingChildren()) { run_with_period(1000) receiveChildInfo(); checkChildrenDone(); } else { /* 后台无 saving/rewrite 子进程才会进行,逐个检查每个save规则*/ for (j = 0; j = sp->changes && server.unixtime-server.lastsave > sp->seconds &&(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK)) { serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds); rdbSaveInfo rsi, *rsiptr; rsiptr = rdbPopulateSaveInfo(&rsi); /* 执行bgsave过程 */ rdbSaveBackground(server.rdb_filename,rsiptr); break; } } /* 省略:Trigger an AOF rewrite if needed. */ } /* 省略其他逻辑 */ }
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) { pid_t childpid; if (hasActiveChildProcess()) return C_ERR; server.dirty_before_bgsave = server.dirty; server.lastbgsave_try = time(NULL); // fork子进程 if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) { int retval; /* Child 子进程:修改进程标题 */ redisSetProcTitle("redis-rdb-bgsave"); redisSetCpuAffinity(server.bgsave_cpulist); // 执行rdb持久化 retval = rdbSave(filename,rsi); if (retval == C_OK) { sendChildCOWInfo(CHILD_TYPE_RDB, 1, "RDB"); } // 持久化完成后,退出子进程 exitFromChild((retval == C_OK) ? 0 : 1); } else { /* Parent 父进程:记录fork子进程的时间等信息*/ if (childpid == -1) { server.lastbgsave_status = C_ERR; serverLog(LL_WARNING,"Can't save in background: fork: %s", strerror(errno)); return C_ERR; } serverLog(LL_NOTICE,"Background saving started by pid %ld",(long) childpid); // 记录子进程开始的时间、类型等。 server.rdb_save_time_start = time(NULL); server.rdb_child_type = RDB_CHILD_TYPE_DISK; return C_OK; } return C_OK; /* unreached */ }
Redis的rdbSave函数是真正进行RDB持久化的函数,流程、细节贼多,整体流程可以总结为:创建并打开临时文件、Redis内存数据写入临时文件、临时文件写入磁盘、临时文件重命名为正式RDB文件、更新持久化状态信息(dirty、lastsave)。其中“Redis内存数据写入临时文件”最为核心和复杂,写入过程直接体现了RDB文件的文件格式,本着一图胜千言的理念,我按照源码流程绘制了下图。
补充说明一下,上图右下角“遍历当前数据库的键值对并写入”这个环节会根据不同类型的Redis数据类型及底层数据结构采用不同的格式写入到RDB文件中,不再展开了。我觉得大家对整个过程有个直观的理解就好,这对于我们理解Redis内部的运作机制大有裨益。
上一节我们知道RDB是一种时间点(point-to-time)快照,适合数据备份及灾难恢复,由于工作原理的“先天性缺陷”无法保证实时性持久化,这对于缓存丢失零容忍的系统来说是个硬伤,于是就有了AOF。
AOF是Append Only File的缩写,它是Redis的完全持久化策略,从1.1版本开始支持;这里的file存储的是引起Redis数据修改的命令集合(比如:set/hset/del等),这些集合按照Redis Server的处理顺序追加到文件中。当重启Redis时,Redis就可以从头读取AOF中的指令并重放,进而恢复关闭前的数据状态。
AOF持久化默认是关闭的,修改redis.conf以下信息并重启,即可开启AOF持久化功能。
# no-关闭,yes-开启,默认no appendonly yes appendfilename appendonly.aof
AOF本质是为了持久化,持久化对象是Redis内每一个key的状态,持久化的目的是为了在Reids发生故障重启后能够恢复至重启前或故障前的状态。相比于RDB,AOF采取的策略是按照执行顺序持久化每一条能够引起Redis中对象状态变更的命令,命令是有序的、有选择的。把aof文件转移至任何一台Redis Server,从头到尾按序重放这些命令即可恢复如初。举个例子:
首先执行指令set number 0,然后随机调用incr number、get number各5次,最后再执行一次get number,我们得到的结果肯定是5。
因为在这个过程中,能够引起number状态变更的只有set/incr类型的指令,并且它们执行的先后顺序是已知的,无论执行多少次get都不会影响number的状态。所以,保留所有set/incr命令并持久化至aof文件即可。按照aof的设计原理,aof文件中的内容应该是这样的(这里是假设,实际为RESP协议):
set number 0 incr number incr number incr number incr number incr number
最本质的原理用“命令重放”四个字就可以概括。但是,考虑实际生产环境的复杂性及操作系统等方面的限制,Redis所要考虑的工作要比这个例子复杂的多:
set命令,存在很大的压缩空间。从流程上来看,AOF的工作原理可以概括为几个步骤:命令追加(append)、文件写入与同步(fsync)、文件重写(rewrite)、重启加载(load),接下来依次了解每个步骤的细节及背后的设计哲学。
AOF 永続化機能がオンになっている場合、Redis は書き込みコマンドを実行した後、プロトコル形式 (つまり、Redis クライアントと Redis クライアントとの間の対話用の通信プロトコル RESP) を使用します。サーバー) 実行された書き込みコマンドを、Redis サーバーによって維持される AOF バッファーの末尾に追加します。 AOF ファイルの追加操作はシングルスレッドのみであり、シークなどの複雑な操作はなく、停電やダウンタイムが発生してもファイルが破損する心配はありません。さらに、テキスト プロトコルを使用することには多くの利点があります:
AOF バッファ タイプは、Redissdsによって独自に設計されたデータ構造です。Redis はコマンドの種類 (catAppendOnlyGenericCommand、#) に応じて異なるメソッドを使用します。 ## catAppendOnlyExpireAtCommandなど) はコマンドの内容を処理し、最終的にバッファーに書き込みます。
aof_rewrite_buffer) にも追加されることに注意してください。

beforeSleep) に関数flushAppendOnlyFileを呼び出し、flushAppendOnlyFileが AOF バッファー (aof_buf) をフラッシュします。) はカーネル バッファに書き込まれ、カーネル バッファ内のデータをディスクに書き込むために使用される戦略は、appendfsync構成に基づいて決定されます。つまり、fsync()# を呼び出します。 ##。この構成には 3 つのオプション オプションalways、no、everysecがあり、詳細は次のとおりです。
no-appendfsync-on-rewriteの影響を受けます。その機能は、AOF ファイルの書き換え中かどうかを Redis に通知することです。 fsync() の呼び出しを無効にします。デフォルトは no です。
がalwaysまたはeverysecに設定されている場合、BGSAVEまたはは進行中です。バックグラウンドの BGREWRITEAOFはディスク I/O を大量に消費します。特定の Linux システム構成では、Redis による fsync() の呼び出しが長時間ブロックされる可能性があります。ただし、fsync()が別のスレッドで実行された場合でも同期書き込み操作はブロックされるため、この問題はまだ修正されていません。この問題を軽減するには、このオプションを使用して、
またはBGREWRITEAOFの実行中にメイン プロセスで fsync() が呼び出されないようにすることができます。
yes意味着,如果子进程正在进行BGSAVE或BGREWRITEAOF,AOF的持久化能力就与appendfsync设置为no有着相同的效果。最糟糕的情况下,这可能会导致30秒的缓存数据丢失。
yes,否则保持为no。如前面提到的,Redis长时间运行,命令不断写入AOF,文件会越来越大,不加控制可能影响宿主机的安全。
为了解决AOF文件体积问题,Redis引入了AOF文件重写功能,它会根据Redis内数据对象的最新状态生成新的AOF文件,新旧文件对应的数据状态一致,但是新文件会具有较小的体积。重写既减少了AOF文件对磁盘空间的占用,又可以提高Redis重启时数据恢复的速度。还是下面这个例子,旧文件中的6条命令等同于新文件中的1条命令,压缩效果显而易见。
我们说,AOF文件太大时会触发AOF文件重写,那到底是多大呢?有哪些情况会触发重写操作呢?
**
与RDB方式一样,AOF文件重写既可以手动触发,也会自动触发。手动触发直接调用bgrewriteaof命令,如果当时无子进程执行会立刻执行,否则安排在子进程结束后执行。自动触发由Redis的周期性方法serverCron检查在满足一定条件时触发。先了解两个配置项:
BGREWRITEAOF时AOF文件占用空间最小值,默认为64MB;Redis启动时把aof_base_size初始化为当时aof文件的大小,Redis运行过程中,当AOF文件重写操作完成时,会对其进行更新;aof_current_size为serverCron执行时AOF文件的实时大小。当满足以下两个条件时,AOF文件重写就会触发:
增长比例:(aof_current_size - aof_base_size) / aof_base_size > auto-aof-rewrite-percentage 文件大小:aof_current_size > auto-aof-rewrite-min-size
手动触发与自动触发的代码如下,同样在周期性方法serverCron中:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) { /* 省略其他逻辑 */ /* 如果用户请求进行AOF文件重写时,Redis正在执行RDB持久化,Redis会安排在RDB持久化完成后执行AOF文件重写, * 如果aof_rewrite_scheduled为true,说明需要执行用户的请求 */ if (!hasActiveChildProcess() && server.aof_rewrite_scheduled) { rewriteAppendOnlyFileBackground(); } /* Check if a background saving or AOF rewrite in progress terminated. */ if (hasActiveChildProcess() || ldbPendingChildren()) { run_with_period(1000) receiveChildInfo(); checkChildrenDone(); } else { /* 省略rdb持久化条件检查 */ /* AOF重写条件检查:aof开启、无子进程运行、增长百分比已设置、当前文件大小超过阈值 */ if (server.aof_state == AOF_ON && !hasActiveChildProcess() && server.aof_rewrite_perc && server.aof_current_size > server.aof_rewrite_min_size) { long long base = server.aof_rewrite_base_size ? server.aof_rewrite_base_size : 1; /* 计算增长百分比 */ long long growth = (server.aof_current_size*100/base) - 100; if (growth >= server.aof_rewrite_perc) { serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth); rewriteAppendOnlyFileBackground(); } } } /**/ }
AOF文件重写的流程是什么?听说Redis支持混合持久化,对AOF文件重写有什么影响?
从4.0版本开始,Redis在AOF模式中引入了混合持久化方案,即:纯AOF方式、RDB+AOF方式,这一策略由配置参数aof-use-rdb-preamble(使用RDB作为AOF文件的前半段)控制,默认关闭(no),设置为yes可开启。所以,在AOF重写过程中文件的写入会有两种不同的方式。当aof-use-rdb-preamble的值是:
结合源码(6.0版本,源码太多这里不贴出,可参考aof.c)及参考资料,绘制AOF重写(BGREWRITEAOF)流程图:
结合上图,总结一下AOF文件重写的流程:
父进程:
子进程:
aof-use-rdb-preamble構成に従って、 RDB または AOF を使用する 前半を AOF モードで書き込み、ハードディスクに同期する;Redis の起動後、loadDataFromDisk関数を通じてデータの読み込み作業が実行されます。ここで注意すべき点は、永続化メソッドは AOF、RDB、またはその両方を使用できますが、データをロードするときに選択する必要があり、2 つのメソッドを別々にロードすると混乱が生じることになります。
理論的には、AOF 永続性は RDB よりも優れたリアルタイム パフォーマンスを備えています。AOF 永続性が有効になっている場合、Redis はデータのロード時に AOF を優先します。さらに、Redis 4.0 バージョン以降、AOF はハイブリッド永続性をサポートするため、AOF ファイルをロードするときにバージョンの互換性を考慮する必要があります。 Redis データの読み込みプロセスを次の図に示します。
AOF モードでは、ハイブリッド永続化メカニズムをオンにすることによって生成されるファイルは「RDB head AOF tail」です。電源が入っていない場合は「」が発生し、ファイルはすべてAOF形式です。 2 つのファイル形式の互換性を考慮して、AOF ファイルが RDB ヘッダーであると Redis が検出した場合、RDB データ ロード メソッドを使用して前半を読み取り、復元し、次に AOF メソッドを使用して後半を読み取り、復元します。 。 AOF 形式で保存されたデータは RESP プロトコル コマンドであるため、Redis は擬似クライアントを使用してコマンドを実行し、データを回復します。
AOF コマンドの追加プロセス中にダウンタイムが発生した場合、遅延書き込みの技術的特性により、AOF の RESP コマンドが不完全 (切り捨て) になる可能性があります。この状況が発生した場合、Redis は構成項目aof-load-truncatedに従ってさまざまな処理戦略を実行します。この構成は、Redis に起動時に aof ファイルを読み取るように指示し、ファイルが切り詰められている (不完全である) ことが判明した場合にどうするかを指示します:
Redis は 2 つの永続化オプションを提供します: RDB は、特定の実質的な間隔でデータ セットのポイントインタイム スナップショットの生成をサポートします; AOF は、Redis サーバーが受信した各データを保存します書き込みコマンドはログに保存され、Redis の再起動時にコマンドを再実行することでデータを復元できます。ログ形式は RESP プロトコルであり、ログ ファイルに対して追加操作のみが実行されるため、破損の危険はありません。また、AOF ファイルが大きすぎる場合、圧縮ファイルを自動的に書き換えることができます。
もちろん、データを永続化する必要がない場合は、Redis の永続化機能を無効にすることもできますが、これはほとんどの場合には当てはまりません。実際、RDB と AOF を同時に使用することがありますが、最も重要なことは、RDB と AOF を合理的に使用するために 2 つの違いを理解することです。
redis-check-aofツールを使用して簡単に修復できます。RDB と AOF の 2 つの永続化方式の動作原理、実行プロセス、長所と短所を理解した後、長所と短所を比較検討する方法を考えてみましょう。実際のシナリオでは、2 つの永続化メソッドを合理的に使用します。 Redis をキャッシュツールとしてのみ使用する場合は、永続化データベースに基づいてすべてのデータを再構築することができ、永続化機能をオフにして、予熱、キャッシュの侵入、ブレークダウン、アバランチなどの保護作業を行うことができます。
通常の状況では、Redis は分散ロック、ランキング、登録センターなど、より多くの作業を引き受けます。永続化機能は、災害復旧やデータ移行においてより大きな役割を果たします。
上記の分析を通じて、RDB スナップショットと AOF の書き換えには fork が必要であることがわかりましたが、これは Redis ブロックにダメージを与える負荷の高い操作です。したがって、Redis メインプロセスの応答に影響を与えないように、ブロッキングを可能な限り減らす必要があります。
プログラミング関連の知識について詳しくは、プログラミング入門をご覧ください。 !
以上がRedis の深層学習の永続化原理の詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



