

この記事では、Redis チュートリアルに関する関連知識を提供します。主に、Redis の LRU キャッシュ削除アルゴリズムの実装に関連する問題を紹介します。LRU は、リンクされたリストを使用して、キャッシュ内の各データを維持します。アクセス ステータス、データへのリアルタイムのアクセスに基づいて、リンクされたリスト内のデータの位置を調整します。

最も最近使用されていない(最も最近使用されていない、LRU)、古典的なキャッシュ アルゴリズム。#LRU は、リンク リストを使用してキャッシュ内の各データのアクセス ステータスを維持し、データのリアルタイム アクセスに基づいてリンク リスト内のデータの位置を調整し、リンクされたリスト内のデータの位置。データが最近アクセスされたか、またはしばらくアクセスされていないことを示します。
LRU は、チェーンの先頭と末尾をそれぞれ MRU 端と LRU 端に設定します。
MRU (最近使用したデータの略語) は、ここのデータがちょうど最近使用されたことを意味します。アクセスされました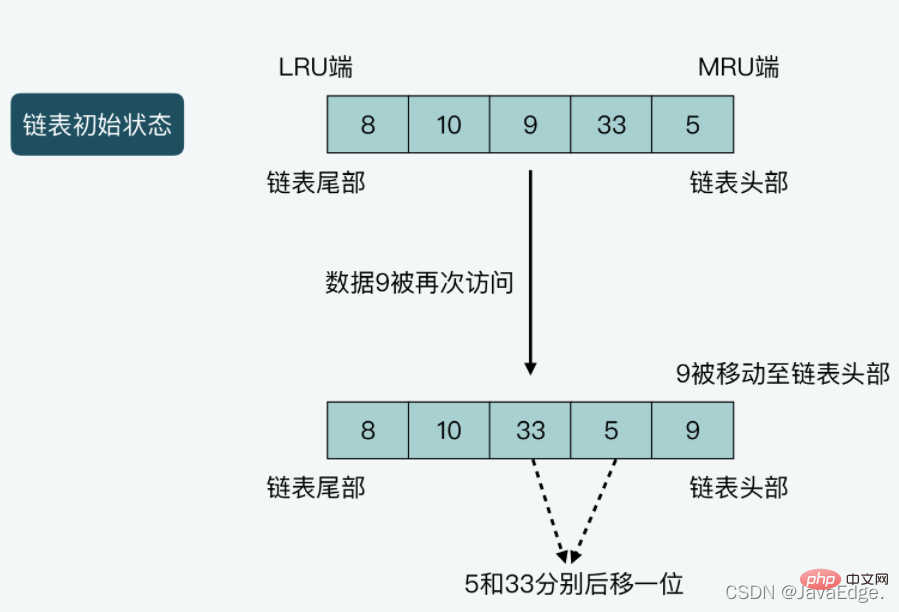
は、Redis が最大メモリを使用する場合、収容可能なすべてのデータのリンク リストを維持します
## リンク リストを保存するには追加のメモリ領域が必要です#新しいデータが挿入されるか、既存のデータが削除されるたびに、再度アクセスするには、複数のリンク リスト操作を実行する必要があります。
データにアクセスするプロセスで、Redis はデータの移動とリンクのオーバーヘッドの影響を受けます。リスト操作
最終的には Redis アクセスのパフォーマンスの低下につながります。
したがって、メモリを節約するためでも、Redis の高パフォーマンスを維持するためでも、Redis は LRU の基本原則に従って厳密に実装されていませんが、
は近似的な LRU アルゴリズムの実装を提供します。
maxmemory-policyを実行し、Redis サーバーのメモリ削除ポリシーを設定します。これには、おおよその LRU、LFU、TTL 値の削除やランダムな削除などが含まれます。
つまり、maxmemory オプションが設定されたら、maxmemory-policy を実行します。 allkeys-lru または volatile-lru として構成されている場合、近似 LRU が有効になります。 allkeys-lru と volatile-lru は両方とも、近似 LRU を使用してデータを削除します。違いは次のとおりです:
 volatile- lru は、TTL セットを使用して KV ペアで削除されるデータをフィルター処理します
volatile- lru は、TTL セットを使用して KV ペアで削除されるデータをフィルター処理します
データ アクセスの適時性を判断するためにグローバル LRU クロック値を計算する方法
キーと値のペアの LRU クロック値の初期化と更新
各キーと値のペアに対応する LRU クロック値を初期化および更新する関数はどれですか?
近似 LRU アルゴリズムの実際の実行
近似 LRU アルゴリズムの実行方法、つまり、データ削除がトリガーされたとき、および実際の削除メカニズムの実装
近似 LRU アルゴリズムでは、さまざまなデータ、つまり Redis のアクセス適時性を区別する必要があります。データの最新のアクセス時刻を知る必要があります。したがって、LRU クロックは、データへの各アクセスのタイムスタンプを記録します。
Redis は、redisObject 構造体を使用して、KV ペア内の各 V の V へのポインターを保存します。 redisObject は、値を記録するポインターに加えて、lru メンバー変数に対応する LRU クロック情報を保存するために 24 ビットも使用します。このようにして、各 KV ペアは、最後にアクセスされたタイムスタンプを lru 変数に記録します。redisObject 定義には、lru メンバー変数の定義が含まれています:各 KV ペアの LRU クロック値はどのように計算されますか? Redis Server はインスタンス レベルのグローバル LRU クロックを使用し、各 KV ペアの LRU 時間はグローバル LRU クロックに従って設定されます。
このグローバル LRU クロックは、Redis グローバル変数サーバーのメンバー変数に保存されますlru Clock

Redis サーバーが起動すると、 initServerConfig を呼び出して初期化します。 さまざまなパラメータを設定するとき、getLRUClock が呼び出されて lru Clock の値を設定します。

したがって、注意する必要があります。データへの 2 回のアクセスが 1 秒未満の場合、これら 2 回のアクセスのタイムスタンプは同じです。 **LRU クロックの精度は 1 秒であるため、1 秒未満の間隔で異なるタイムスタンプを区別することはできません。
getLRUClock 関数は、LRU_CLOCK_RESOLUTION によって取得された UNIX タイムスタンプを除算して、LRU クロック精度で計算された UNIX タイムスタンプ (現在の LRU クロック値) を取得します。
getLRUClock は、LRU クロック値とマクロ定義 LRU_CLOCK_MAX (LRU クロックが表現できる最大値) の間で AND 演算を実行します。

したがって、デフォルトでは、グローバル LRU クロック値は 1 秒の精度で計算された UNIX タイムスタンプであり、initServerConfig で初期化されます。
Redis サーバーの実行中にグローバル LRU クロック値はどのように更新されますか?イベントドリブンフレームワークにおけるRedisサーバーの定期実行時間イベントに対応するserverCronに関係します。
serverCron, は、タイム イベントのコールバック関数として、定期的に実行されます。その頻度の値は、redis.conf のhz 設定項目によって決定されます。デフォルト値は 10 です。 、serverCron 関数は 100 ミリ秒 (1 秒/10 = 100 ミリ秒) ごとに 1 回実行されます。 serverCron では、グローバル LRU クロック値は、getLRUClock を呼び出すことにより、この関数の実行頻度に従って定期的に更新されます。

このようにして、各 KV ペアは最新のクロック値を取得できます。グローバル LRU クロックからのアクセス タイムスタンプ。
各 KV ペアについて、対応する redisObject.lru はどの関数で初期化および更新されますか?
KV ペアの場合、LRU クロック値は KV ペアの作成時に初期設定されます。この初期化操作は # で呼び出されます。 ##createObject function、この関数は、Redis が KV ペアを作成するときに呼び出されます。
createObject は、メモリ領域を redisObject に割り当てるだけでなく、maxmemory_policy 構成に従って redisObject.lru も初期化します。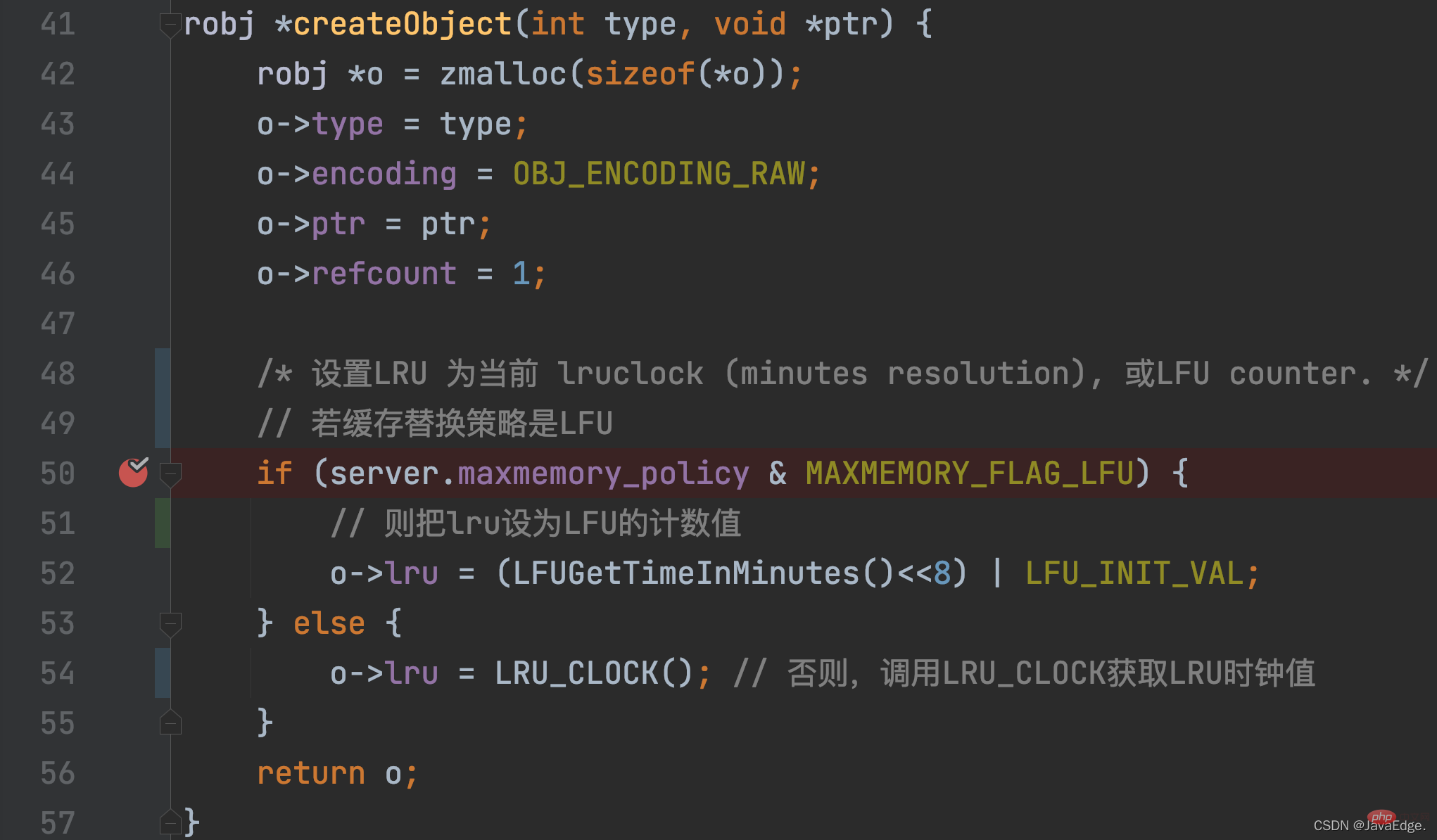 どの KV ペアですか? LRU クロックはいつになりますか?値は再度更新されますか?
どの KV ペアですか? LRU クロックはいつになりますか?値は再度更新されますか?
KV ペアがアクセスされている限り、その LRU クロック値は更新されます。 KV ペアにアクセスすると、アクセス操作は最終的に
lookupKeyを呼び出します。lookupKey は、グローバル ハッシュ テーブルからアクセスする KV ペアを検索します。 KV ペアが存在する場合、lookupKey は、maxmemory_policy の構成値に基づいて、キーと値のペアの LRU クロック値 (アクセス タイムスタンプ) を更新します。
maxmemory_policy が LFU ポリシーとして構成されていない場合、lookupKey 関数は LRU_CLOCK 関数を呼び出して現在のグローバル LRU クロック値を取得し、それをキーと値のペアの redisObject 構造内の lru 変数に割り当てます
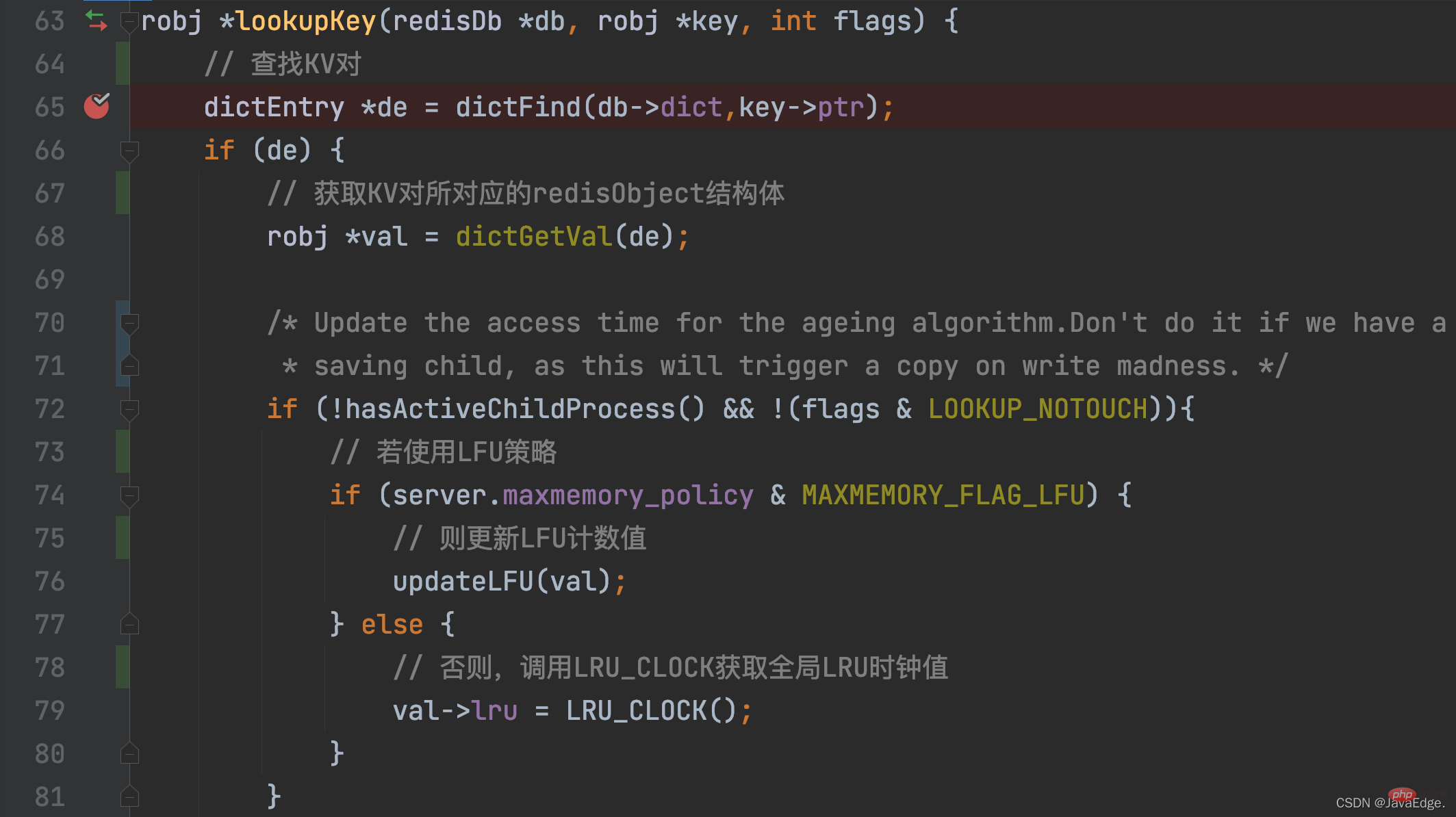 このようにして、各 KV ペアにアクセスすると、最新のアクセス タイムスタンプを取得できます。しかし、気になるかもしれません。データ削除のための LRU アルゴリズムを近似するために、これらのアクセス タイムスタンプは最終的にどのように使用されるのでしょうか?
このようにして、各 KV ペアにアクセスすると、最新のアクセス タイムスタンプを取得できます。しかし、気になるかもしれません。データ削除のための LRU アルゴリズムを近似するために、これらのアクセス タイムスタンプは最終的にどのように使用されるのでしょうか?
2.3 近似 LRU アルゴリズムの実際の実行
2.3.1 アルゴリズムの実行はいつトリガーされますか?
performEvictions は evictionTimeProc によって呼び出され、evictionTimeProc 関数は processCommand によって呼び出されます。
processCommand、Redis は各コマンドの処理時に呼び出します:
次に、isSafeToPerformEvictions は次の条件に基づいて、performEvictions の実行を継続するかどうかを再度判断します:

performEvictions が呼び出され、maxmemory-policy が allkeys-lru または volatile-lru に設定されると、おおよその LRU 実行がトリガーされます。
実行は次のステップに分割できます。
getMaxmemoryState を呼び出して現在のメモリ使用量を評価し、Redis Server によって使用されている現在のメモリ容量が maxmemory 構成値を超えているかどうかを判断します。
maxmemoryを超えない場合は C_OK が返され、performEvictions も直接返されます。

getMaxmemoryState が現在のメモリ使用量を評価し、使用されているメモリが maxmemory を超えていることが判明した場合は、解放する必要があるメモリの量を計算します。この解放されたメモリのサイズ = 使用されたメモリの量 - maxmemory。
ただし、使用メモリ量には、マスター/スレーブ レプリケーションに使用されるコピー バッファ サイズは含まれません。これは、freeMemoryGetNotCountedMemory を呼び出して getMaxmemoryState によって計算されます。
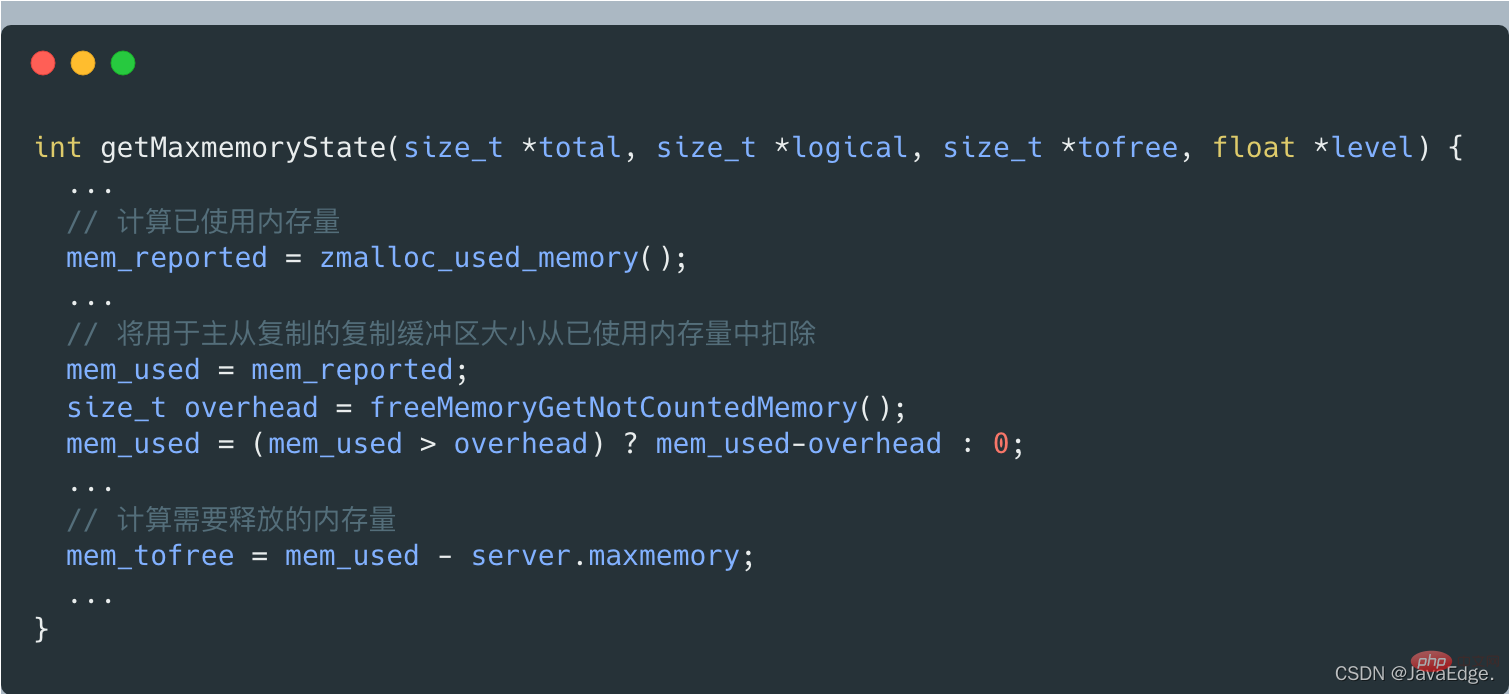
#サーバーによって現在使用されているメモリ量が maxmemory の上限を超える場合、performEvictions は while ループを実行してデータを削除し、メモリを解放します。 。
削除データの場合、Redis は削除する候補 KV ペアを保存するための配列 EvictionPoolLRU を定義します。要素タイプは evictionPoolEntry 構造体で、アイドル時間、対応する K、および KV ペアのその他の情報を保存します。

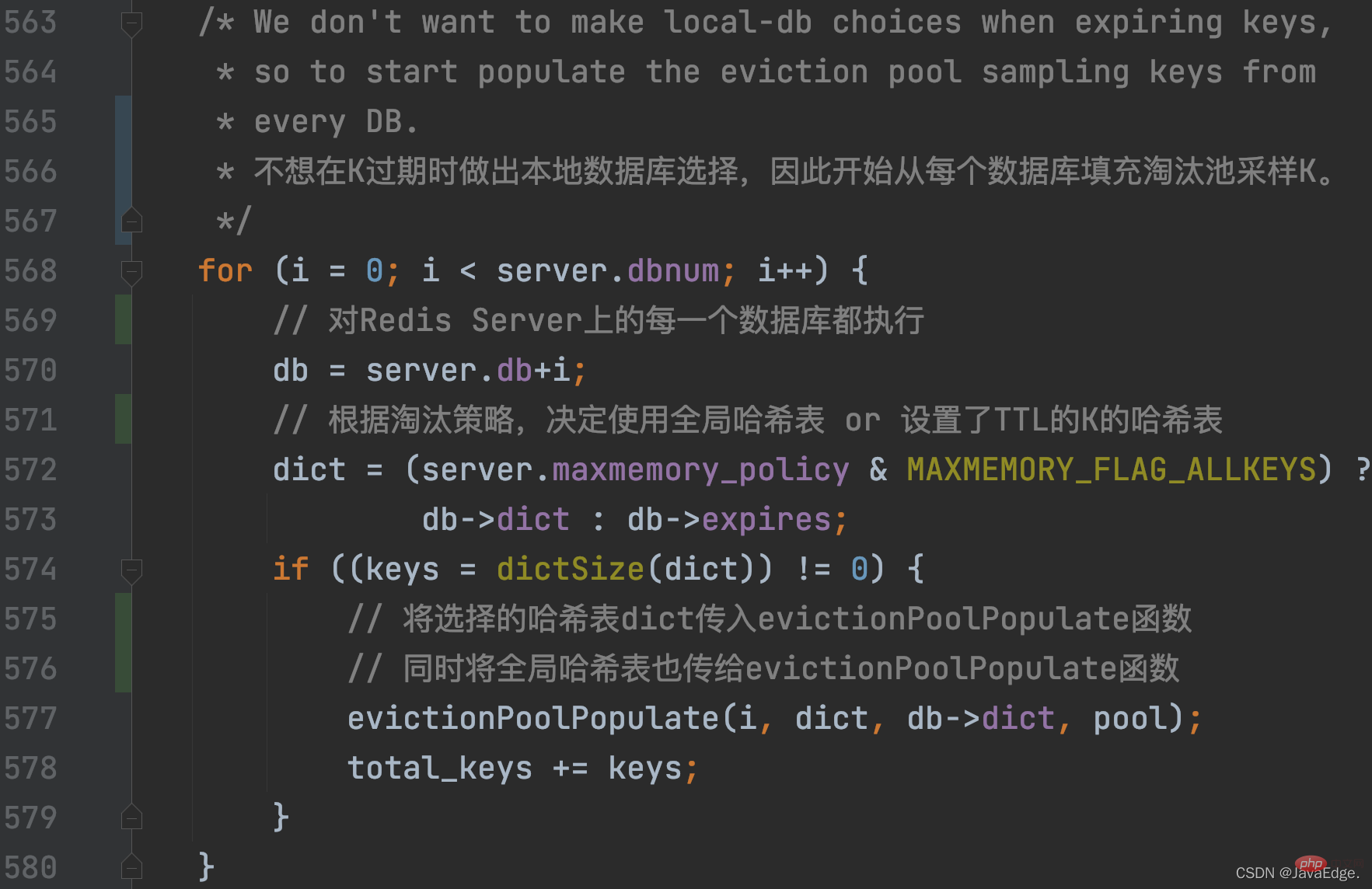
 #したがって、dictGetSomeKeys はサンプリングされた KV ペア セットを返します。 evictionPoolPopulate は、サンプリングされた KV ペアの実際の数に基づいてループを実行します。estimateObjectIdleTime を呼び出して、サンプリング セット内の各 KV ペアのアイドル時間を計算します。
#したがって、dictGetSomeKeys はサンプリングされた KV ペア セットを返します。 evictionPoolPopulate は、サンプリングされた KV ペアの実際の数に基づいてループを実行します。estimateObjectIdleTime を呼び出して、サンプリング セット内の各 KV ペアのアイドル時間を計算します。
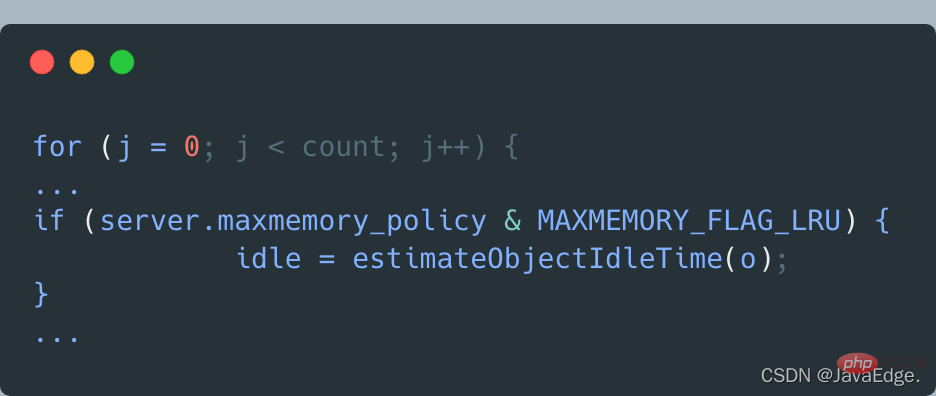 その後、evictionPoolPopulate が実行されます。待機中 排除された候補 KV ペアのセット、つまり EvictionPoolLRU 配列は、次の条件のいずれかに応じて、サンプリングされた各 KV ペアを EvictionPoolLRU 配列に挿入しようとします。
その後、evictionPoolPopulate が実行されます。待機中 排除された候補 KV ペアのセット、つまり EvictionPoolLRU 配列は、次の条件のいずれかに応じて、サンプリングされた各 KV ペアを EvictionPoolLRU 配列に挿入しようとします。
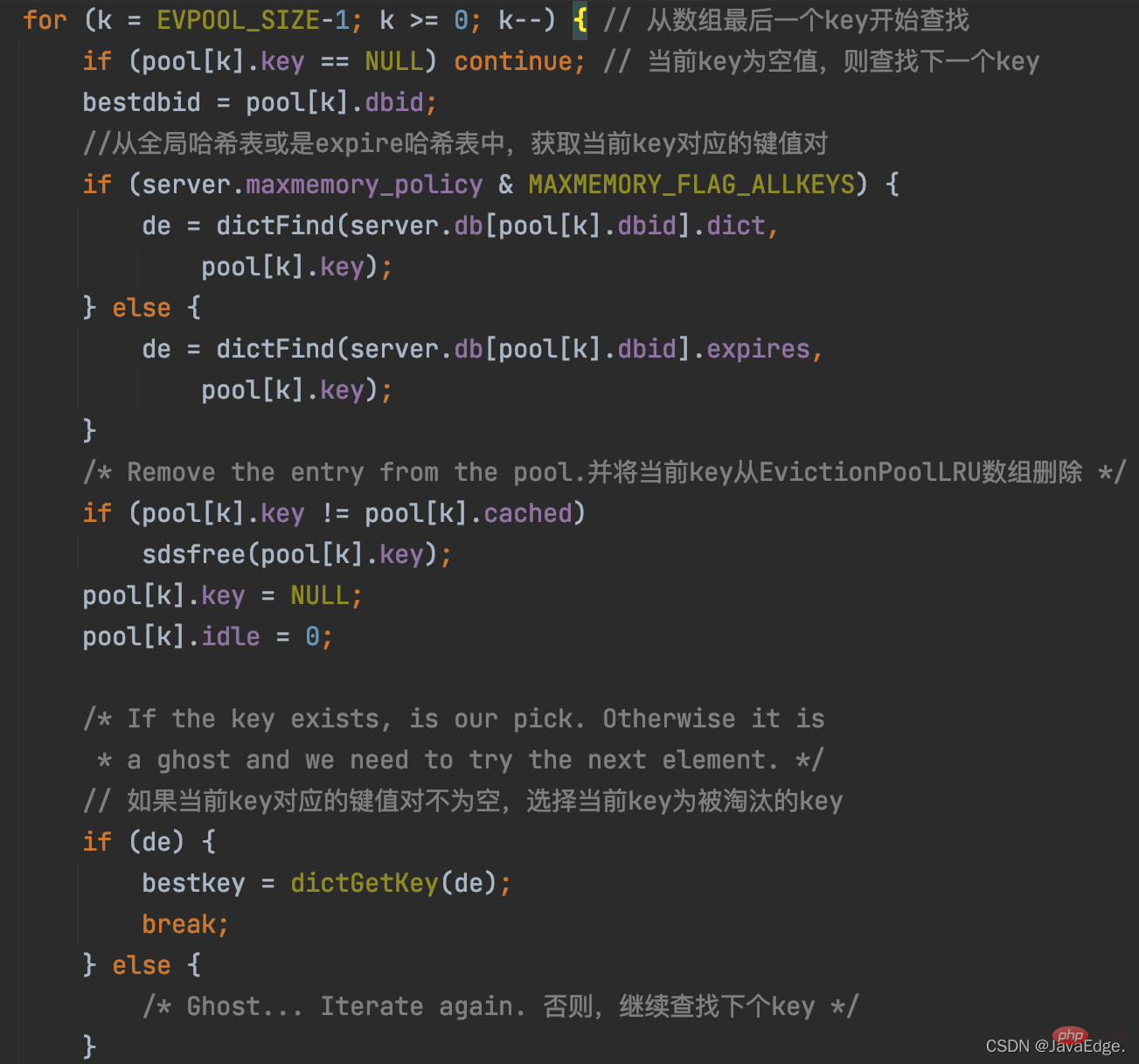
次に、performEvictions は、最終的に削除される KV ペアの選択を開始します。
2.3.2.3 削除された KV ペアを選択して削除します。
このプロセスの実行ロジック:
 削除された K が選択されると、performEvictions は、次の遅延削除構成に基づいて同期削除または非同期削除を実行します。削除:
削除された K が選択されると、performEvictions は、次の遅延削除構成に基づいて同期削除または非同期削除を実行します。削除:
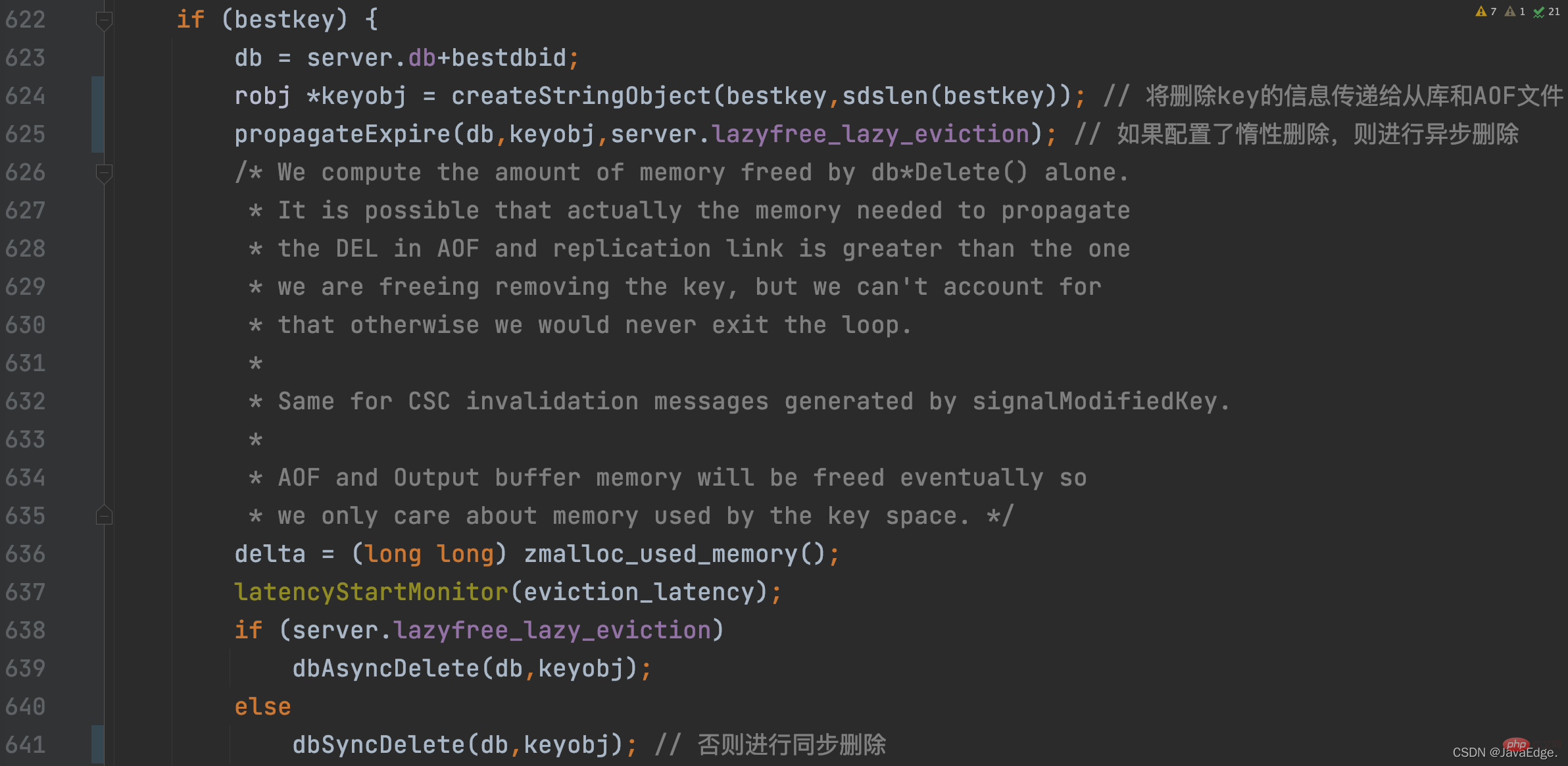 この時点で、performEvictions によって K が削除されました。このとき解放されたメモリ空間が十分ではない、つまり解放すべき空間に達していない場合、performEvictions は排除対象となる KV ペアの候補のセットを更新し、KV ペアを選択する処理を
この時点で、performEvictions によって K が削除されました。このとき解放されたメモリ空間が十分ではない、つまり解放すべき空間に達していない場合、performEvictions は排除対象となる KV ペアの候補のセットを更新し、KV ペアを選択する処理を
performEvictions プロセス:
近似 LRU アルゴリズムは、時間とスペースを消費するリンク リストを使用しませんが、固定サイズのデータ セットを削除して使用し、いくつかの K をランダムに選択してデータに追加します。毎回削除されるように設定されています。
最後に、削除するセット内の K のアイドル時間の長さに応じて、アイドル時間が最も長い K を削除します。 要約 LRU アルゴリズムの基本原則によれば、LRU アルゴリズムが基本原則に従って厳密に実装された場合、開発されたシステムはメモリ領域を節約するために追加のメモリ スペースを必要とすることがわかりました。リンク リスト操作のオーバーヘッドの影響。 Redis のメモリ リソースとパフォーマンスは非常に重要であるため、Redis はおおよその LRU アルゴリズムを実装します。以上がRedis の LRU キャッシュ削除アルゴリズムの実装を簡単に理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



