


Les systèmes de recommandations sont importants pour relever le défi de la surcharge d'informations, car ils fournissent des recommandations personnalisées basées sur les préférences personnelles des utilisateurs. Ces dernières années, la technologie du deep learning a grandement favorisé le développement de systèmes de recommandation et amélioré la compréhension du comportement et des préférences des utilisateurs.
Cependant, les méthodes traditionnelles d'apprentissage supervisé sont confrontées à des défis dans les applications pratiques en raison du problème de la rareté des données, ce qui limite leur capacité à apprendre efficacement les performances des utilisateurs.
Pour protéger et surmonter ce problème, la technologie d'apprentissage auto-supervisé (SSL) est appliquée aux étudiants, qui utilise la structure inhérente des données pour générer des signaux de supervision et ne s'appuie pas entièrement sur des données étiquetées.
Cette méthode utilise un système de recommandation qui peut extraire des informations significatives à partir de données non étiquetées et faire des prédictions et des recommandations précises même lorsque les données sont rares.

Adresse de l'article : https://arxiv.org/abs/2404.03354
Base de données open source : https://github.com/HKUDS/Awesome-SSLRec-Papers
Open source Bibliothèque de codes : https://github.com/HKUDS/SSLRec
Cet article passe en revue les cadres d'apprentissage auto-supervisés conçus pour les systèmes de recommandation et effectue une analyse approfondie de plus de 170 articles connexes. Nous avons exploré neuf scénarios d'application différents pour acquérir une compréhension complète de la manière dont SSL peut améliorer les systèmes de recommandation dans différents scénarios.
Pour chaque domaine, nous discutons en détail de différents paradigmes d'apprentissage auto-supervisé, notamment l'apprentissage contrastif, l'apprentissage génératif et l'apprentissage contradictoire, montrant comment SSL peut améliorer les performances des systèmes de recommandation dans différentes situations.
La recherche sur les systèmes de recommandation couvre diverses tâches dans différents scénarios, tels que le filtrage collaboratif, la recommandation de séquences, la recommandation multi-comportement, etc. Ces tâches ont des paradigmes et des objectifs de données différents. Ici, nous fournissons d’abord une définition générale sans entrer dans des variations spécifiques pour différentes tâches de recommandation. Dans les systèmes de recommandation, il existe deux ensembles principaux : les ensembles d'utilisateurs, notés 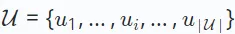 , et les ensembles d'éléments, notés
, et les ensembles d'éléments, notés 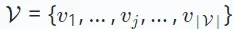 .
.
Ensuite, utilisez une matrice d'interaction 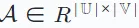 pour représenter les interactions enregistrées entre l'utilisateur et l'élément. Dans cette matrice, l'entrée Ai,j de la matrice reçoit la valeur 1 si l'utilisateur ui a interagi avec l'élément vj, sinon elle vaut 0.
pour représenter les interactions enregistrées entre l'utilisateur et l'élément. Dans cette matrice, l'entrée Ai,j de la matrice reçoit la valeur 1 si l'utilisateur ui a interagi avec l'élément vj, sinon elle vaut 0.
La définition de l'interaction peut être adaptée à différents contextes et ensembles de données (par exemple, regarder un film, cliquer sur un site de commerce électronique ou effectuer un achat).
De plus, dans différentes tâches de recommandation, il existe différentes données d'observation auxiliaires, enregistrées sous forme de relations correspondantes.
Et dans la recommandation sociale, X inclut les relations au niveau de l'utilisateur, telles que l'amitié. Sur la base de la définition ci-dessus, le modèle de recommandation optimise une fonction de prédiction f(⋅), visant à estimer avec précision le score de préférence entre tout utilisateur u et l'élément v :
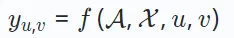
Le score de préférence yu,v représente l'utilisateur u et article v Possibilité d'interaction.
Sur la base de ce score, le système de recommandation peut recommander des éléments sans interaction à chaque utilisateur en fournissant une liste classée d'éléments en fonction du score de préférence estimé. Dans la revue, nous explorons plus en détail la forme de données de (A, X) dans différents scénarios de recommandation et le rôle de l'apprentissage auto-supervisé dans celui-ci.
Au cours des dernières années, les réseaux de neurones profonds ont donné de bons résultats dans l'apprentissage supervisé, ce qui s'est reflété dans divers domaines, notamment la vision par ordinateur, le traitement du langage naturel et les systèmes de recommandation. Cependant, en raison de sa forte dépendance à l’égard des données étiquetées, l’apprentissage supervisé est confronté à des défis liés à la rareté des étiquettes, qui constitue également un problème courant dans les systèmes de recommandation.
Pour remédier à cette limitation, l'apprentissage auto-supervisé est apparu comme une méthode prometteuse, qui utilise les données elles-mêmes comme étiquette apprise. L'apprentissage auto-supervisé dans les systèmes de recommandation comprend trois paradigmes différents : l'apprentissage contrastif, l'apprentissage génératif et l'apprentissage contradictoire.
En tant que méthode d'apprentissage auto-supervisée de premier plan, l'objectif principal de l'apprentissage contrastif est de maximiser la cohérence entre les différentes vues améliorées à partir des données. Dans l'apprentissage contrastif du système de recommandation, le but est de minimiser la fonction de perte suivante :
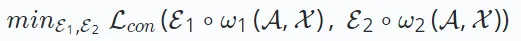
E∗∘ω∗ représente l'opération de création de vue contrastive, et différents algorithmes de recommandation basés sur l'apprentissage contrastif ont un processus de création différent. La construction de chaque vue consiste en un processus d'augmentation des données ω∗ (qui peut impliquer des nœuds/arêtes dans le graphe augmenté) et un processus de codage d'intégration E∗. L'objectif de
minimiser  est d'obtenir une fonction d'encodage robuste qui maximise la cohérence entre les vues. Cette cohérence entre les vues peut être obtenue grâce à des méthodes telles que la maximisation mutuelle des informations ou la discrimination des instances.
est d'obtenir une fonction d'encodage robuste qui maximise la cohérence entre les vues. Cette cohérence entre les vues peut être obtenue grâce à des méthodes telles que la maximisation mutuelle des informations ou la discrimination des instances.
L'objectif de l'apprentissage génératif est de comprendre la structure et le modèle des données pour apprendre des représentations significatives. Il optimise un modèle d'encodeur-décodeur approfondi qui reconstruit les données d'entrée manquantes ou corrompues. Le
encodeur  crée une représentation latente à partir de l'entrée, tandis que le décodeur
crée une représentation latente à partir de l'entrée, tandis que le décodeur 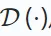 reconstruit les données originales à partir de la sortie de l'encodeur. Le but est de minimiser la différence entre les données reconstruites et originales comme suit :
reconstruit les données originales à partir de la sortie de l'encodeur. Le but est de minimiser la différence entre les données reconstruites et originales comme suit :
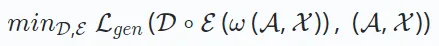
Ici, ω représente une opération comme le masquage ou la perturbation. D∘E représente le processus d’encodage et de décodage pour reconstruire la sortie. Des recherches récentes ont également introduit une architecture uniquement décodeur qui reconstruit efficacement les données sans configuration codeur-décodeur. Cette approche utilise un modèle unique (par exemple, Transformer) pour la reconstruction et est généralement appliquée aux recommandations sérialisées basées sur l'apprentissage génératif. Le format de la fonction de perte 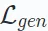 dépend du type de données, tel que l'erreur quadratique moyenne pour les données continues et la perte d'entropie croisée pour les données catégorielles.
dépend du type de données, tel que l'erreur quadratique moyenne pour les données continues et la perte d'entropie croisée pour les données catégorielles.
L'apprentissage contradictoire est une méthode de formation qui utilise un générateur G(⋅) pour générer une sortie de haute qualité et contient un discriminateur Ω(⋅), qui Le discriminateur détermine si un échantillon donné est réel ou généré. Contrairement à l'apprentissage génératif, l'apprentissage contradictoire diffère en incluant un discriminateur qui utilise des interactions compétitives pour améliorer la capacité du générateur à produire un résultat de haute qualité afin de tromper le discriminateur.
Par conséquent, l'objectif d'apprentissage de l'apprentissage contradictoire peut être défini comme suit :
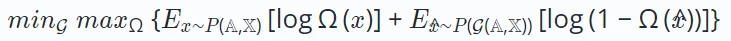
Ici, la variable x représente l'échantillon réel obtenu à partir de la distribution de données sous-jacente, tandis que 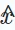 représente l'échantillon synthétique généré par le générateur G(⋅). Au cours de la formation, le générateur et le discriminateur améliorent leurs capacités grâce à des interactions compétitives. En fin de compte, le générateur s’efforce de produire des résultats de haute qualité bénéfiques pour les tâches en aval.
représente l'échantillon synthétique généré par le générateur G(⋅). Au cours de la formation, le générateur et le discriminateur améliorent leurs capacités grâce à des interactions compétitives. En fin de compte, le générateur s’efforce de produire des résultats de haute qualité bénéfiques pour les tâches en aval.
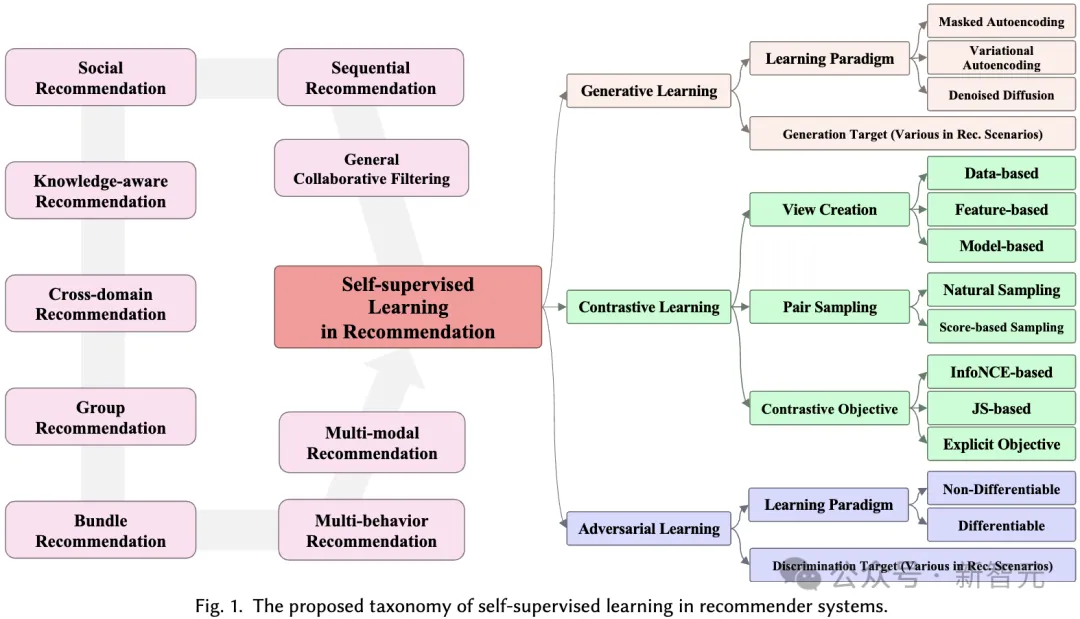
Dans cette section, nous proposons un système de classification complet pour l'application de l'apprentissage auto-supervisé dans les systèmes de recommandation. Comme mentionné précédemment, les paradigmes d’apprentissage auto-supervisé peuvent être divisés en trois catégories : l’apprentissage contrastif, l’apprentissage génératif et l’apprentissage contradictoire. Par conséquent, notre système de classification est construit sur la base de ces trois catégories, fournissant des informations plus approfondies sur chaque catégorie.
Le principe de base de l'apprentissage contrastif (AC) est de maximiser la cohérence entre les différentes vues. Par conséquent, nous proposons une taxonomie centrée sur les vues composée de trois éléments clés à prendre en compte lors de l'application de l'apprentissage contrastif : la création de vues, l'association de vues pour maximiser la cohérence et l'optimisation de la cohérence.
Voir la création. Créez des vues qui mettent l'accent sur les différents aspects des données sur lesquels le modèle se concentre. Il peut combiner des informations collaboratives globales pour améliorer la capacité du système de recommandation à gérer les relations globales, ou introduire du bruit aléatoire pour améliorer la robustesse du modèle.
Nous considérons l'amélioration des données d'entrée (par exemple, graphiques, séquences, fonctionnalités d'entrée) comme une création de vue au niveau des données, tandis que l'amélioration des fonctionnalités latentes lors de l'inférence est considérée comme une création de vue au niveau des fonctionnalités. Nous proposons un système de classification hiérarchique qui inclut des techniques de création de vues depuis le niveau des données de base jusqu'au niveau du modèle neuronal.
Échantillonnage de paires. Le processus de création de vue génère au moins deux vues différentes pour chaque échantillon dans les données. Le cœur de l’apprentissage contrastif est de maximiser l’alignement de certaines vues (c’est-à-dire de les rapprocher) tout en repoussant d’autres vues.
Pour ce faire, la clé est d'identifier les paires d'échantillons positifs qui doivent être rapprochées, et d'identifier d'autres vues qui forment des paires d'échantillons négatives. Cette stratégie est appelée échantillonnage par paires, et elle se compose principalement de deux méthodes d'échantillonnage par paires :
Objectif Contrastif. L'objectif de l'apprentissage contrastif est de maximiser les informations mutuelles entre des paires d'échantillons positifs, ce qui peut à son tour améliorer les performances du modèle de recommandation d'apprentissage. Puisqu’il n’est pas possible de calculer directement les informations mutuelles, une limite inférieure réalisable est généralement utilisée comme cible d’apprentissage dans l’apprentissage contrastif. Cependant, il existe également des objectifs explicites visant à rapprocher les paires positives.

Dans l'apprentissage génératif auto-supervisé, l'objectif principal est de maximiser l'estimation de la vraisemblance de la distribution des données réelles. Cela permet aux représentations apprises et significatives de capturer la structure et les modèles sous-jacents des données, qui peuvent ensuite être utilisés dans des tâches en aval. Dans notre système de classification, nous considérons deux aspects pour distinguer les différentes méthodes de recommandation basées sur l'apprentissage génératif : le paradigme d'apprentissage génératif et l'objectif génératif.
Paradigme d'apprentissage génératif. Dans le cadre de la recommandation, les méthodes auto-supervisées utilisant l'apprentissage génératif peuvent être classées en trois paradigmes :
Cible de génération. Dans l'apprentissage génératif, quel modèle de données est considéré comme une étiquette générée est une autre question qui doit être prise en compte pour apporter des signaux auxiliaires auto-supervisés significatifs. En général, les objectifs de génération varient selon les méthodes et selon les scénarios de recommandation. Par exemple, dans la recommandation de séquence, la cible de génération peut être les éléments de la séquence, dans le but de simuler la relation entre les éléments de la séquence. Dans la recommandation de graphiques interactifs, les cibles de génération peuvent être des nœuds/arêtes du graphique, visant à capturer des corrélations topologiques de haut niveau dans le graphique.
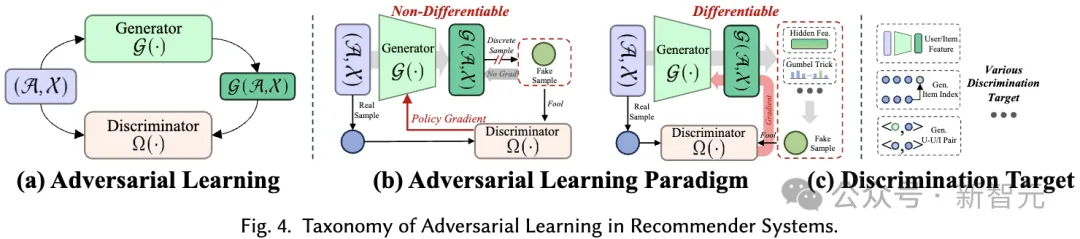
Dans l'apprentissage contradictoire des systèmes de recommandation, le discriminateur joue un rôle crucial dans la distinction des faux échantillons générés des échantillons réels. Semblable à l'apprentissage génératif, le système de classification que nous proposons couvre les méthodes d'apprentissage contradictoire dans les systèmes de recommandation sous deux perspectives : le paradigme d'apprentissage et l'objectif de discrimination :
Paradigme d'apprentissage contradictoire. Dans les systèmes de recommandation, l'apprentissage contradictoire se compose de deux paradigmes différents, selon que la perte discriminante du discriminateur peut être rétropropagée au générateur de manière différentiable.
Cible de discrimination. Différents algorithmes de recommandation amènent le générateur à générer différentes entrées, qui sont ensuite transmises au discriminateur pour la discrimination. Ce processus vise à améliorer la capacité du générateur à produire un contenu de haute qualité et plus proche de la réalité. Des objectifs de discrimination spécifiques sont conçus sur la base de tâches de recommandation spécifiques.
Dans cette revue, nous discutons en profondeur de la conception de différentes méthodes d'apprentissage autosupervisé à partir de neuf scénarios de recommandation différents. Ces neuf recommandations Les scénarios sont les suivants (veuillez. lisez l'article pour plus de détails) :
Cet article fournit un examen complet de l'application de l'apprentissage auto-supervisé (SSL) dans les systèmes de recommandation, avec une analyse approfondie de plus de 170 articles. Nous avons proposé un système de classification auto-supervisé couvrant neuf scénarios de recommandation, discuté en détail de trois paradigmes SSL d'apprentissage contrastif, d'apprentissage génératif et d'apprentissage contradictoire, et discuté des orientations de recherche futures dans l'article.
Nous soulignons l'importance du SSL dans la gestion de la rareté des données et l'amélioration des performances des systèmes de recommandation, et soulignons le potentiel d'intégration de grands modèles de langage dans les systèmes de recommandation, les environnements de recommandation dynamiques adaptatifs et l'établissement d'une base théorique pour le paradigme SSL. .orientation de la recherche. Nous espérons que cette revue pourra fournir des ressources précieuses aux chercheurs, inspirer de nouvelles idées de recherche et promouvoir le développement ultérieur de systèmes de recommandation.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Construisez votre propre serveur git
Construisez votre propre serveur git
 La différence entre git et svn
La différence entre git et svn
 git annuler le commit soumis
git annuler le commit soumis
 Comment annuler l'erreur de commit git
Comment annuler l'erreur de commit git
 Comment comparer le contenu des fichiers de deux versions dans git
Comment comparer le contenu des fichiers de deux versions dans git
 Comment changer pycharm en chinois
Comment changer pycharm en chinois
 Qu'est-ce que la blockchain web3.0
Qu'est-ce que la blockchain web3.0
 Quels sont les quatre principaux modèles d'E/S en Java ?
Quels sont les quatre principaux modèles d'E/S en Java ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



