


Cet article est dédié à la résolution des principaux défis des grands modèles de langage multimodaux (MLLM) actuels dans les applications de conduite autonome, c'est-à-dire l'extension des MLLM de la compréhension 2D à l'espace 3D. question. Cette expansion est particulièrement importante car les véhicules autonomes (VA) doivent prendre des décisions précises concernant les environnements 3D. La compréhension spatiale 3D est essentielle pour les véhicules utilitaires car elle a un impact direct sur la capacité du véhicule à prendre des décisions éclairées, à prédire les états futurs et à interagir en toute sécurité avec l’environnement.
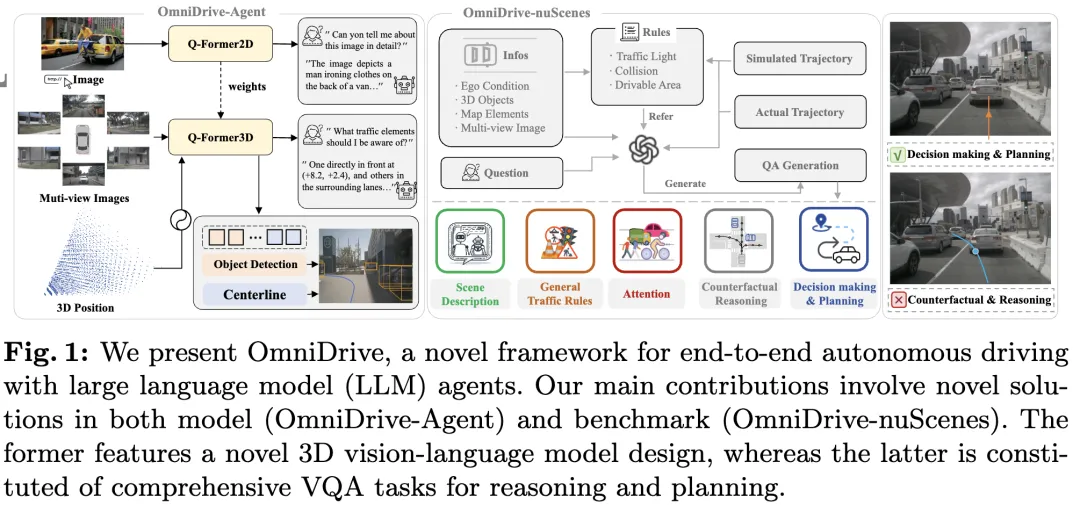
Les grands modèles de langage multimodaux actuels (tels que LLaVA-1.5) ne peuvent généralement gérer que des entrées d'images de résolution inférieure (par exemple) en raison des limitations de résolution de l'encodeur visuel et des limitations de longueur de séquence LLM. Cependant, les applications de conduite autonome nécessitent une entrée vidéo multi-vues haute résolution pour garantir que les véhicules peuvent percevoir l'environnement et prendre des décisions en toute sécurité sur de longues distances. De plus, de nombreuses architectures de modèles 2D existantes ont du mal à gérer efficacement ces entrées car elles nécessitent des ressources de calcul et de stockage étendues. Pour résoudre ces problèmes, les chercheurs travaillent au développement de nouvelles architectures de modèles et de nouvelles ressources de stockage.
Dans ce contexte, cet article propose une nouvelle architecture MLLM 3D, s'appuyant sur la conception de style Q-Former. L'architecture utilise un décodeur d'attention croisée pour compresser les informations visuelles haute résolution en requêtes clairsemées, ce qui facilite l'adaptation aux entrées haute résolution. Cette architecture présente des similitudes avec des familles de modèles de vue telles que DETR3D, PETR(v2), StreamPETR et Far3D, car ils exploitent tous des mécanismes de requête 3D clairsemés. En ajoutant un codage positionnel 3D à ces requêtes et en interagissant avec une entrée multi-vues, notre architecture permet une compréhension spatiale 3D et exploite ainsi mieux les connaissances pré-entraînées dans les images 2D.
En plus de l'innovation de l'architecture des modèles, cet article propose également un benchmark plus stimulant, OmniDrive-nuScenes. Le benchmark couvre une gamme de tâches complexes nécessitant une compréhension spatiale 3D et un raisonnement à longue portée, et introduit un benchmark de raisonnement contrefactuel pour évaluer les résultats en simulant des solutions et des trajectoires. Ce benchmark compense efficacement le problème de biais en faveur d’une trajectoire experte unique dans les évaluations ouvertes actuelles, évitant ainsi le surajustement des trajectoires expertes.
Cet article présente OmniDrive, un cadre complet de conduite autonome de bout en bout qui fournit un modèle de raisonnement et de planification 3D efficace basé sur l'agent LLM et construit une référence plus exigeante qui stimule les développements ultérieurs dans le domaine de la conduite autonome. Les contributions spécifiques sont les suivantes :
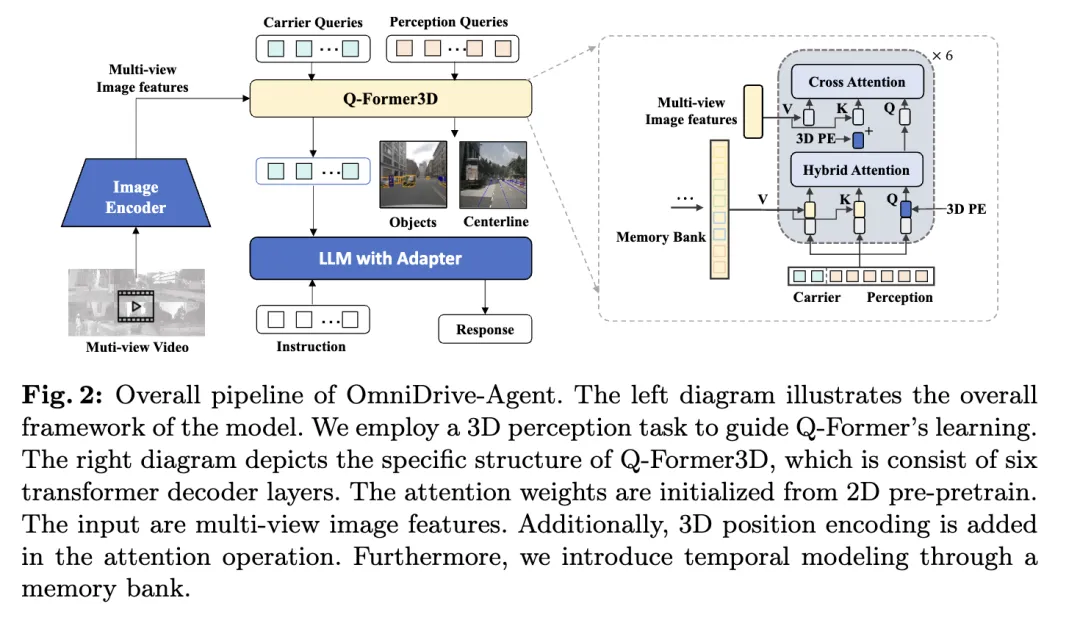
L'agent OmniDrive proposé dans cet article combine les avantages de Q-Former et des modèles de perception 3D basés sur des requêtes pour obtenir efficacement des informations spatiales 3D dans plusieurs -afficher les caractéristiques de l'image, résoudre les tâches de perception 3D et de planification en conduite autonome. L'architecture globale est représentée sur la figure.
Grâce à cette conception d'architecture, OmniDrive-Agent peut obtenir efficacement de riches informations spatiales 3D à partir d'images multi-vues et les combiner avec LLM pour la génération de texte, offrant ainsi une perception de l'espace 3D. et la conduite autonome offre de nouvelles solutions.
La méthode de l'auteur bénéficie de l'apprentissage multitâche et de la modélisation temporelle. Dans l'apprentissage multi-tâches, l'auteur peut intégrer des modules Q-Former3D spécifiques pour chaque tâche de perception et adopter une stratégie d'initialisation unifiée (voir cref{Training Strategy}). Dans différentes tâches, les requêtes des opérateurs peuvent collecter des informations sur différents éléments du trafic. L'implémentation de l'auteur couvre des tâches telles que la construction de la ligne centrale et la détection d'objets 3D. Lors des phases d'entraînement et d'inférence, ces modules partagent le même encodage de position 3D. Notre méthode enrichit des tâches telles que la construction de la ligne médiane et la détection d'objets 3D. Lors des phases de formation et d'inférence, ces modules partagent le même encodage de position 3D. Notre méthode enrichit des tâches telles que la construction de la ligne médiane et la détection d'objets 3D. Lors des phases d'entraînement et d'inférence, ces modules partagent le même encodage de position 3D.
Concernant la modélisation temporelle, les auteurs stockent les requêtes perceptuelles avec les scores de classification top-k dans la banque mémoire et les propagent image par image. La requête propagée interagit avec la requête perceptuelle et la requête porteuse de l'image actuelle par le biais d'une attention croisée, étendant ainsi les capacités de traitement du modèle pour l'entrée vidéo.
La stratégie de formation d'OmniDrive-Agent est divisée en deux étapes : la pré-formation 2D et la mise au point 3D. Dans la phase initiale, les auteurs ont d'abord pré-entraîné de grands modèles multimodaux (MLLM) sur des tâches d'image 2D pour initialiser les requêtes Q-Former et vectorielles. Après avoir supprimé la requête de détection, le modèle OmniDrive peut être considéré comme un modèle de langage visuel standard, capable de générer du texte à partir d'images. Par conséquent, l'auteur a utilisé la stratégie de formation et les données de LLaVA v1.5 pour pré-entraîner OmniDrive sur 558 000 paires d'images et de textes. Pendant le pré-entraînement, tous les paramètres restent figés sauf Q-Former. Par la suite, les MLLM ont été affinés à l’aide de l’ensemble de données de réglage des instructions de LLaVA v1.5. Pendant le réglage fin, l'encodeur d'image reste figé et d'autres paramètres peuvent être entraînés.
Dans la phase de mise au point 3D, l'objectif est d'améliorer les capacités de positionnement 3D du modèle tout en conservant autant que possible ses capacités de compréhension sémantique 2D. À cette fin, l’auteur a ajouté des modules d’encodage de position et de synchronisation 3D au Q-Former original. À ce stade, l'auteur utilise la technologie LoRA pour affiner l'encodeur visuel et le grand modèle de langage avec un faible taux d'apprentissage, et former Q-Former3D avec un taux d'apprentissage relativement élevé. Dans ces deux étapes, le calcul des pertes d'OmniDrive-Agent inclut uniquement la perte de génération de texte, sans tenir compte des pertes d'apprentissage et de correspondance contrastées dans BLIP-2.

Pour comparer la conduite d'agents de grands modèles multimodaux, les auteurs proposent OmniDrive-nuScenes, un nouveau benchmark basé sur l'ensemble de données nuScenes contenant des réponses visuelles aux questions (QA) de haute qualité. Oui, couvrant tâches de perception, de raisonnement et de planification dans le domaine 3D.
Le point fort d'OmniDrive-nuScenes est son processus de génération d'assurance qualité entièrement automatisé, qui utilise GPT-4 pour générer des questions et des réponses. Semblable à LLaVA, notre pipeline fournit des annotations 3D comme informations contextuelles à GPT-4. Sur cette base, l'auteur utilise en outre les règles de circulation et la simulation de planification comme contribution supplémentaire pour aider GPT-4 à mieux comprendre l'environnement 3D. Le benchmark de l'auteur teste non seulement les capacités de perception et de raisonnement du modèle, mais remet également en question les capacités réelles de compréhension spatiale et de planification du modèle dans l'espace 3D à travers des problèmes à long terme impliquant l'attention, le raisonnement contrefactuel et la planification en boucle ouverte, car ces problèmes nécessitent une planification de conduite. dans les prochaines secondes est simulé pour arriver à la bonne réponse.
En plus du processus de génération de questions et réponses hors ligne, l'auteur propose également un processus de génération en ligne de questions de positionnement diverses. Ce processus peut être considéré comme une méthode implicite d’amélioration des données pour améliorer la compréhension spatiale 3D et les capacités de raisonnement du modèle.
Dans le processus de génération d'assurance qualité hors ligne, l'auteur utilise des informations contextuelles pour générer des paires d'assurance qualité sur nuScenes. Tout d’abord, l’auteur utilise GPT-4 pour générer une description de scène, divise la vue avant à trois perspectives et la vue arrière à trois perspectives en deux images indépendantes et les saisit dans GPT-4. Grâce à une saisie rapide, GPT-4 peut décrire des informations telles que la météo, l'heure, le type de scène, etc., et identifier la direction de chaque angle de vue. En même temps, il évite la description par angle de vue, mais décrit le contenu par rapport au. position de votre propre véhicule.
Ensuite, afin que GPT-4V puisse mieux comprendre la relation spatiale relative entre les éléments de trafic, l'auteur représente la relation entre les objets et les lignes de voie dans une structure de type arborescence de fichiers, et sur la base du cadre de délimitation 3D de l'objet, ses informations Convertir en description en langage naturel.
Ensuite, l'auteur a généré des trajectoires en simulant différentes intentions de conduite, notamment le maintien de la voie, le changement de voie de gauche et le changement de voie de droite, et a utilisé un algorithme de recherche en profondeur d'abord pour relier les lignes centrales des voies afin de générer tous les chemins de conduite possibles. De plus, l'auteur a regroupé les trajectoires des véhicules autonomes dans l'ensemble de données nuScenes, sélectionné des trajets de conduite représentatifs et les a utilisés dans le cadre de la trajectoire simulée.
Enfin, en combinant différentes informations contextuelles dans le processus de génération d'AQ hors ligne, les auteurs sont capables de générer plusieurs types de paires d'AQ, notamment la description de scène, la reconnaissance d'objets d'attention, le raisonnement contrefactuel et la planification de décision. GPT-4 peut identifier les objets menaçants sur la base de simulations et de trajectoires d'experts, et donner des suggestions de conduite raisonnables en raisonnant sur la sécurité du trajet.

Afin d'utiliser pleinement les annotations de perception 3D dans l'ensemble de données de conduite autonome, l'auteur a généré un grand nombre de tâches de positionnement en ligne pendant le processus de formation. Ces tâches sont conçues pour améliorer la compréhension spatiale 3D et les capacités de raisonnement du modèle, notamment :
OmniDrive-nuScenes implique une description de scène, une planification en boucle ouverte et des tâches de raisonnement contrefactuel. Chaque tâche se concentre sur différents aspects, ce qui rend difficile son évaluation à l'aide d'une seule métrique. Par conséquent, les auteurs ont conçu différents critères d’évaluation pour différentes tâches.
Pour les tâches liées à la description de scènes (telles que la description de scènes et la sélection d'objets d'attention), l'auteur utilise des indicateurs d'évaluation linguistique couramment utilisés, notamment METEOR, ROUGE et CIDEr, pour évaluer la similarité des phrases. Dans la tâche de planification en boucle ouverte, les auteurs ont utilisé les taux de collision et les taux de franchissement des limites routières pour évaluer les performances du modèle. Pour la tâche de raisonnement contrefactuel, les auteurs utilisent GPT-3.5 pour extraire des mots-clés dans les prédictions et comparer ces mots-clés avec la vérité terrain afin de calculer la précision et le rappel pour différentes catégories d'accidents.
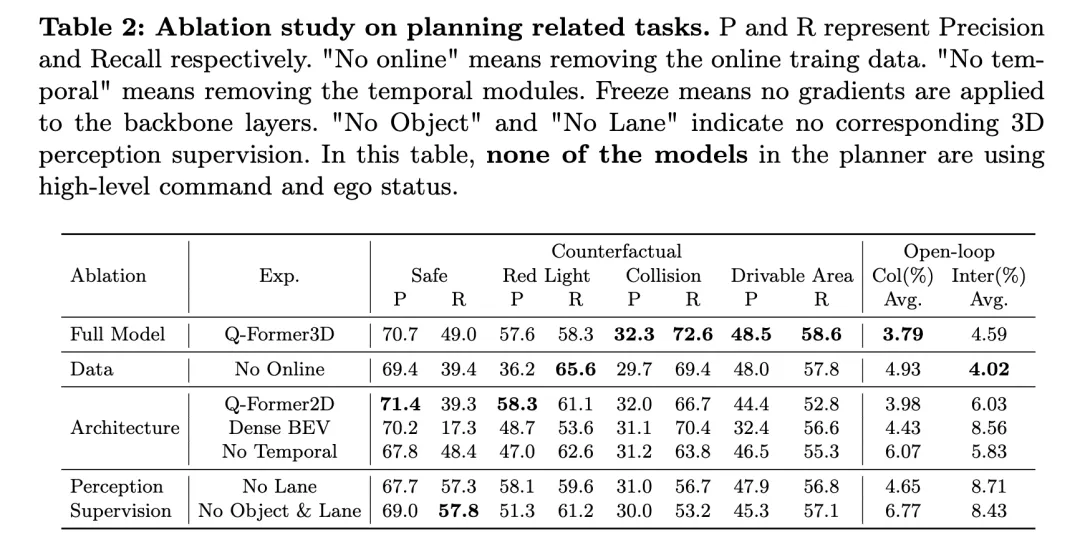
Le tableau ci-dessus montre les résultats de la recherche sur l'ablation sur les tâches liées à la planification, y compris l'évaluation des performances du raisonnement contrefactuel et de la planification en boucle ouverte.
Le modèle complet, Q-Former3D, fonctionne bien à la fois sur le raisonnement contrefactuel et sur les tâches de planification en boucle ouverte. Dans la tâche de raisonnement contrefactuel, le modèle a démontré une précision et des taux de rappel élevés dans les catégories « violation du feu rouge » et « violation de la zone accessible », qui étaient respectivement de 57,6 %/58,3 % et 48,5 %/58,6 %. Dans le même temps, le modèle a atteint le taux de rappel le plus élevé (72,6 %) dans la catégorie « collision ». Dans la tâche de planification en boucle ouverte, Q-Former3D a obtenu de bons résultats en termes de taux de collision moyen et de taux d'intersection des limites de route, atteignant respectivement 3,79 % et 4,59 %.
Après avoir supprimé les données de formation en ligne (No Online), le taux de rappel de la catégorie « Violation du feu rouge » dans la tâche de raisonnement contrefactuel a augmenté (65,6 %), mais la performance globale a légèrement diminué. Le taux de précision et le taux de rappel des collisions et des infractions aux zones praticables sont légèrement inférieurs à ceux du modèle complet, tandis que le taux de collision moyen de la tâche de planification en boucle ouverte a augmenté à 4,93 % et le taux moyen de franchissement des limites routières a chuté à 4,02 %. , qui reflète l'importance des données de formation en ligne pour L'importance d'améliorer les performances globales de planification du modèle.
Dans l'expérience d'ablation d'architecture, la version Q-Former2D a atteint la plus haute précision (58,3 %) et le plus haut rappel (61,1 %) dans la catégorie « Violation de la lumière rouge », mais les performances dans les autres catégories n'étaient pas aussi bonnes que la version complète. modèle, en particulier " Les rappels pour les catégories " Collision " et " Violations des zones accessibles " ont diminué de manière significative. Dans la tâche de planification en boucle ouverte, le taux moyen de collisions et le taux d’intersection des limites routières sont supérieurs à ceux du modèle complet, soit 3,98 % et 6,03 % respectivement.
Le modèle utilisant l'architecture Dense BEV est plus performant sur toutes les catégories de tâches de raisonnement contrefactuel, mais le taux de rappel global est faible. Le taux moyen de collisions et le taux d’intersection des limites routières dans la tâche de planification en boucle ouverte ont atteint respectivement 4,43 % et 8,56 %.
Lorsque le module temporel est supprimé (No Temporal), les performances du modèle dans la tâche de raisonnement contrefactuel diminuent considérablement, en particulier le taux de collision moyen augmente à 6,07 % et le taux de franchissement des limites routières atteint 5,83 %.
En termes de supervision perceptuelle, après avoir supprimé la supervision de ligne de voie (No Lane), le taux de rappel du modèle dans la catégorie « collision » a chuté de manière significative, tandis que la performance d'autres catégories de tâches de raisonnement contrefactuel et de tâches de planification en boucle ouverte a été relativement stable. Après avoir complètement supprimé la supervision de la perception 3D des objets et des lignes de voie (No Object & Lane), les taux de précision et de rappel de chaque catégorie de la tâche de raisonnement contrefactuel ont diminué, en particulier le taux de rappel de la catégorie « collision » est tombé à 53,2 %. Le taux moyen de collisions et le taux d'intersection des limites de route dans la tâche de planification en boucle ouverte ont augmenté respectivement à 6,77 % et 8,43 %, ce qui était nettement supérieur à celui du modèle complet.
Comme le montrent les résultats expérimentaux ci-dessus, le modèle complet fonctionne bien dans les tâches de raisonnement contrefactuel et de planification en boucle ouverte. Les données de formation en ligne, les modules de temps et la supervision de la perception 3D des lignes de voie et des objets jouent un rôle important dans l'amélioration des performances du modèle. Le modèle complet peut utiliser efficacement les informations multimodales pour une planification et une prise de décision efficaces, et les résultats de l'expérience d'ablation vérifient davantage le rôle clé de ces composants dans les tâches de conduite autonome.
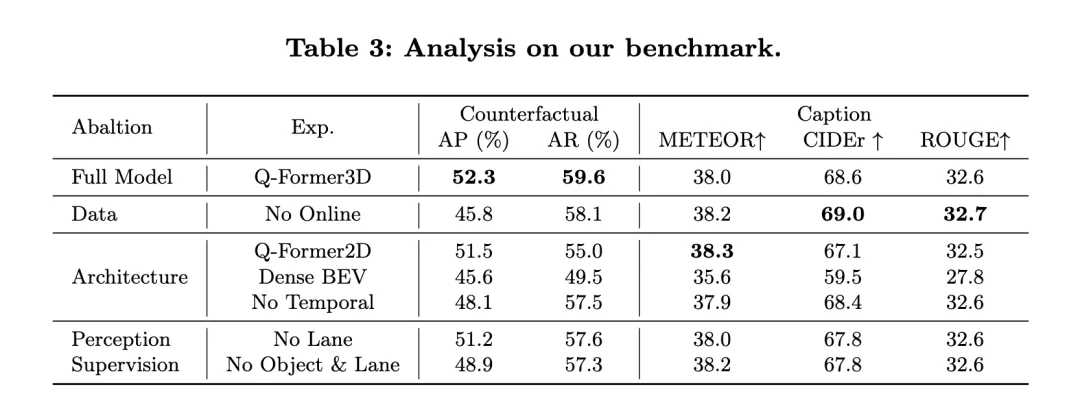
Gleichzeitig werfen wir einen Blick auf die Leistung von NuScenes-QA: Es demonstriert die Leistung von OmniDrive bei Open-Loop-Planungsaufgaben und vergleicht sie mit anderen bestehenden Methoden. Die Ergebnisse zeigen, dass OmniDrive++ (Vollversion) bei allen Indikatoren die beste Leistung erzielt, insbesondere beim durchschnittlichen Fehler der Open-Loop-Planung, der Kollisionsrate und der Kreuzungsrate von Straßengrenzen, was besser ist als bei anderen Methoden.
Leistung von OmniDrive++: Das OmniDrive++-Modell hat durchschnittliche L2-Fehler von 0,14, 0,29 und 0,55 Metern in der Vorhersagezeit von 1 Sekunde, 2 Sekunden bzw. 3 Sekunden, und der endgültige durchschnittliche Fehler beträgt nur 0,33 Meter. Darüber hinaus erreichten die durchschnittliche Kollisionsrate und die durchschnittliche Kreuzungsrate der Straßengrenzen dieses Modells ebenfalls 0,30 % bzw. 3,00 %, was viel niedriger ist als bei anderen Methoden. Insbesondere im Hinblick auf die Kollisionsrate erreichte OmniDrive++ innerhalb des Vorhersagezeitraums von 1 Sekunde und 2 Sekunden eine Kollisionsrate von Null und stellte damit seine hervorragenden Planungs- und Hindernisvermeidungsfähigkeiten voll unter Beweis.
Vergleich mit anderen Methoden: Im Vergleich zu anderen erweiterten Benchmark-Modellen wie UniAD, BEV-Planner++ und Ego-MLP übertrifft OmniDrive++ alle wichtigen Kennzahlen. Wenn UniAD High-Level-Befehle und Informationen zum Status des eigenen Fahrzeugs verwendet, beträgt sein durchschnittlicher L2-Fehler 0,46 Meter, während OmniDrive++ bei denselben Einstellungen einen noch geringeren Fehler von 0,33 Metern aufweist. Gleichzeitig sind die Kollisionsrate und die Kreuzungsrate von Straßengrenzen bei OmniDrive++ deutlich niedriger als bei UniAD, insbesondere ist die Kollisionsrate um fast die Hälfte reduziert.
Im Vergleich zu BEV-Planner++ wird der L2-Fehler von OmniDrive++ in allen Vorhersagezeiträumen deutlich reduziert, insbesondere im 3-Sekunden-Vorhersagezeitraum wird der Fehler von 0,57 Meter auf 0,55 Meter reduziert. Gleichzeitig ist OmniDrive++ auch hinsichtlich der Kollisionsrate und der Straßengrenzüberschreitungsrate besser als BEV-Planner++. Die Kollisionsrate sank von 0,34 % auf 0,30 % und die Straßengrenzüberschreitungsrate sank von 3,16 % auf 3,00 %.
Ablationsexperiment: Um den Einfluss von Schlüsselmodulen in der OmniDrive-Architektur auf die Leistung weiter zu bewerten, verglich der Autor auch die Leistung verschiedener Versionen des OmniDrive-Modells. OmniDrive (das keine Befehle auf hoher Ebene und keine Informationen zum Status des eigenen Fahrzeugs verwendet) ist dem Gesamtmodell in Bezug auf Vorhersagefehler, Kollisionsrate und Geschwindigkeit des Überquerens von Straßengrenzen deutlich unterlegen, insbesondere beim Erreichen des L2-Fehlers in der 3-Sekunden-Vorhersageperiode 2,84 Meter, mit einem Durchschnitt von 3,79 %.
Bei alleiniger Verwendung des OmniDrive-Modells (ohne übergeordnete Befehle und Informationen zum eigenen Fahrzeugstatus) haben sich der Vorhersagefehler, die Kollisionsrate und die Kreuzungsrate von Straßengrenzen verbessert, es besteht jedoch immer noch eine Lücke im Vergleich zum vollständigen Modell. Dies zeigt, dass die Integration von Befehlen auf hoher Ebene und Informationen zum Status des eigenen Fahrzeugs einen erheblichen Einfluss auf die Verbesserung der Gesamtplanungsleistung des Modells hat.
Insgesamt belegen die experimentellen Ergebnisse deutlich die hervorragende Leistung von OmniDrive++ bei Open-Loop-Planungsaufgaben. Durch die Integration multimodaler Informationen, hochrangiger Befehle und Informationen zum eigenen Fahrzeugstatus erreicht OmniDrive++ bei komplexen Planungsaufgaben eine genauere Pfadvorhersage und eine geringere Kollisionsrate sowie eine geringere Rate an Straßengrenzüberschneidungen, wodurch starke Informationen für die autonome Fahrplanung und Entscheidungsfindung bereitgestellt werden Unterstützung.

Der vom Autor vorgeschlagene OmniDrive-Agent und OmniDrive-nuScenes-Datensatz führt ein neues Paradigma im Bereich multimodaler großer Modelle ein, das in der Lage ist, Fahrprobleme in 3D-Umgebungen zu lösen und eine neue Plattform dafür bereitzustellen Solche Modelle Die Bewertung liefert einen umfassenden Benchmark. Allerdings hat jede neue Methode und jeder neue Datensatz ihre Vor- und Nachteile.
OmniDrive-Agent schlägt eine zweistufige Trainingsstrategie vor: 2D-Vortraining und 3D-Feinabstimmung. In der 2D-Vortrainingsphase wird eine bessere Ausrichtung zwischen Bildmerkmalen und großen Sprachmodellen durch das Vortraining von Q-Former- und Trägerabfragen mithilfe des Bild-Text-Paardatensatzes von LLaVA v1.5 erreicht. In der 3D-Feinabstimmungsphase werden 3D-Positionsinformationskodierungs- und Zeitmodule eingeführt, um die 3D-Positionierungsfunktionen des Modells zu verbessern. Durch die Nutzung von LoRA zur Feinabstimmung des visuellen Encoders und des Sprachmodells behält OmniDrive das Verständnis der 2D-Semantik bei und verbessert gleichzeitig seine Beherrschung der 3D-Lokalisierung. Diese abgestufte Trainingsstrategie schöpft das Potenzial des multimodalen Großmodells voll aus und verleiht ihm bessere Wahrnehmungs-, Argumentations- und Planungsfähigkeiten in 3D-Fahrszenarien. Andererseits dient OmniDrive-nuScenes als neuer Benchmark, der speziell für die Bewertung der Fähigkeit zum Fahren großer Modelle entwickelt wurde. Sein vollautomatischer QA-Generierungsprozess generiert über GPT-4 hochwertige Frage-Antwort-Paare, die verschiedene Aufgaben von der Wahrnehmung bis zur Planung abdecken. Darüber hinaus bietet die online generierte Positionierungsaufgabe auch eine implizite Datenverbesserung für das Modell und hilft ihm so, die 3D-Umgebung besser zu verstehen. Der Vorteil dieses Datensatzes besteht darin, dass er nicht nur die Wahrnehmungs- und Argumentationsfähigkeiten des Modells testet, sondern auch das räumliche Verständnis und die Planungsfähigkeiten des Modells anhand langfristiger Probleme bewertet. Dieser umfassende Benchmark bietet starke Unterstützung für die Entwicklung zukünftiger multimodaler Großmodelle.
Der OmniDrive-Agent und der OmniDrive-nuScenes-Datensatz weisen jedoch auch einige Mängel auf. Da der OmniDrive-Agent zunächst das gesamte Modell während der 3D-Feinabstimmungsphase optimieren muss, sind die Anforderungen an die Trainingsressourcen hoch, was die Trainingszeit und die Hardwarekosten erheblich erhöht. Darüber hinaus basiert die Datengenerierung von OmniDrive-nuScenes vollständig auf GPT-4. Dies stellt zwar die Qualität und Vielfalt der Fragen sicher, führt jedoch auch dazu, dass die generierten Fragen eher zu Modellen mit starken Fähigkeiten in natürlicher Sprache neigen, was das Modell beeinträchtigen kann hängt eher von Benchmark-Tests ab, die auf sprachlichen Merkmalen basieren, als auf tatsächlichen Fahrfähigkeiten. Obwohl OmniDrive-nuScenes einen umfassenden QA-Benchmark bietet, ist die Abdeckung von Fahrszenarien immer noch begrenzt. Die im Datensatz enthaltenen Verkehrsregeln und Planungssimulationen basieren nur auf dem nuScenes-Datensatz, was es für die generierten Probleme schwierig macht, verschiedene Fahrszenarien in der realen Welt vollständig darzustellen. Darüber hinaus sind die generierten Fragen aufgrund der hohen Automatisierung des Datengenerierungsprozesses unweigerlich von Datenverzerrungen und promptem Design betroffen.
Der vom Autor vorgeschlagene OmniDrive-Agent und der OmniDrive-nuScenes-Datensatz bringen eine neue Perspektive und Bewertungsmaßstäbe für die multimodale Großmodellforschung in 3D-Fahrszenen. Die zweistufige Trainingsstrategie des OmniDrive-Agenten kombiniert erfolgreich 2D-Vortraining und 3D-Feinabstimmung, was zu Modellen führt, die sich durch Wahrnehmung, Argumentation und Planung auszeichnen. Als neuer QA-Benchmark bietet OmniDrive-nuScenes umfassende Indikatoren zur Bewertung großer Fahrmodelle. Es bedarf jedoch noch weiterer Forschung, um den Trainingsressourcenbedarf des Modells zu optimieren, den Datensatzgenerierungsprozess zu verbessern und sicherzustellen, dass die generierten Fragen die reale Fahrumgebung genauer darstellen. Insgesamt sind die Methode und der Datensatz des Autors von großer Bedeutung für die Weiterentwicklung der multimodalen Großmodellforschung im Bereich Fahren und legen eine solide Grundlage für zukünftige Arbeiten.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Une collection de commandes informatiques couramment utilisées
Une collection de commandes informatiques couramment utilisées
 win10 se connecte à une imprimante partagée
win10 se connecte à une imprimante partagée
 Comment devenir un ami proche sur TikTok
Comment devenir un ami proche sur TikTok
 Logiciel gratuit de récupération de données
Logiciel gratuit de récupération de données
 Quelles sont les fonctions de création de sites Web ?
Quelles sont les fonctions de création de sites Web ?
 Comment représenter des nombres négatifs en binaire
Comment représenter des nombres négatifs en binaire
 python configurer les variables d'environnement
python configurer les variables d'environnement
 Comment ouvrir le fichier HTML WeChat
Comment ouvrir le fichier HTML WeChat








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



