


Google a publié un nouveau cadre vidéo :
Vous n'avez besoin que d'une photo de vous et d'un enregistrement de votre discours, et vous pouvez obtenir une vidéo réaliste de votre discours.
La durée de la vidéo est variable et l'exemple actuel vu va jusqu'à 10 secondes.
Vous pouvez voir que qu'il s'agisse de la forme de la bouche ou de l'expression du visage, c'est très naturel.
Si l'image d'entrée couvre tout le haut du corps, elle peut également être utilisée avec de riches gestes :

Après l'avoir lue, les internautes ont dit :
Avec elle, nous n'aurons plus besoin de tenir les vidéoconférences en ligne à l'avenir Finissez de vous coiffer et habillez-vous avant de partir.
Eh bien, prenez simplement un portrait et enregistrez l'audio de la parole (tête de chien manuelle)
Ce cadre s'appelle VLOGGER.
Il est principalement basé sur le modèle de diffusion et contient deux parties :
L'une est le modèle de diffusion aléatoire humain-à-3D-motion(humain à-3D-motion).
L'autre est une nouvelle architecture de diffusion pour améliorer les modèles texte-image.
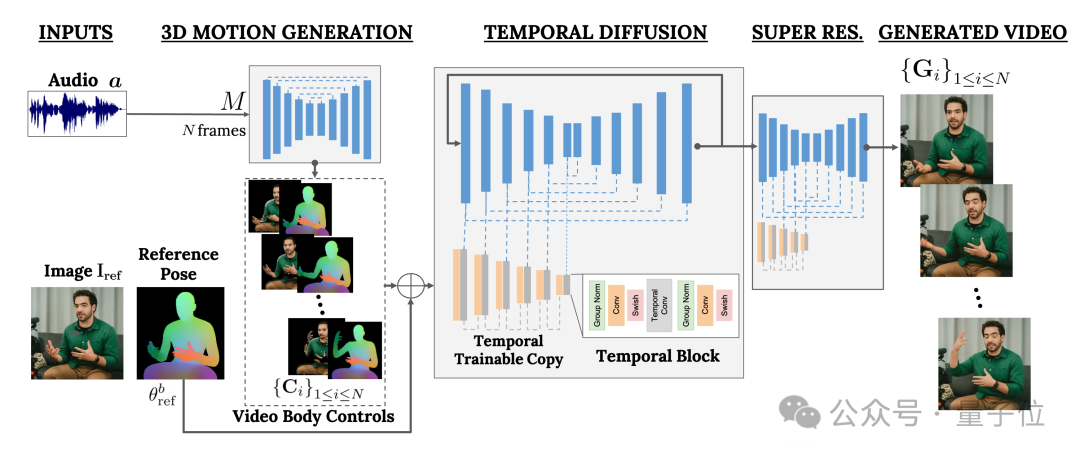
Parmi eux, le premier est chargé d'utiliser la forme d'onde audio comme entrée pour générer les actions de contrôle corporel du personnage, y compris les yeux, les expressions et les gestes, la posture globale du corps, etc.
Ce dernier est un modèle image à image de dimension temporelle qui est utilisé pour étendre le modèle de diffusion d'images à grande échelle et utiliser les actions qui viennent d'être prédites pour générer les images correspondantes.
Afin de rendre les résultats conformes à une image de personnage spécifique, VLOGGER prend également le diagramme de pose de l'image de paramètre en entrée.
La formation de VLOGGER est complétée sur un très grand ensemble de données (nommé MENTOR) .
Quelle est sa taille ? Il dure 2 200 heures et contient 800 000 vidéos de personnages.
Parmi eux, la durée vidéo de l'ensemble de test est également de 120 heures, avec un total de 4 000 caractères.
Google a présenté que la performance la plus remarquable de VLOGGER est sa diversité :
Comme le montre l'image ci-dessous, plus la partie (rouge) de l'image finale en pixels est sombre, plus les actions sont riches.

Par rapport aux méthodes similaires précédentes dans l'industrie, le plus grand avantage de VLOGGER est qu'il n'a pas besoin de former tout le monde, ne repose pas sur la détection et le recadrage des visages, et la vidéo générée est très complète (y compris les visages et lèvres, y compris les mouvements du corps) et ainsi de suite.

Plus précisément, comme le montre le tableau suivant :
La méthode de reconstitution du visage ne peut pas contrôler une telle génération de vidéo avec de l'audio et du texte.
Audio-to-motion peut générer de l'audio en codant l'audio en mouvements du visage 3D, mais l'effet qu'il génère n'est pas assez réaliste.
La synchronisation labiale peut gérer des vidéos de différents thèmes, mais elle ne peut que simuler les mouvements de la bouche.
En comparaison, les deux dernières méthodes, SadTaker et Styletalk, fonctionnent le plus proche de Google VLOGGER, mais elles sont également vaincues par l'incapacité de contrôler le corps et de modifier davantage la vidéo.

En parlant de montage vidéo, comme le montre l'image ci-dessous, l'une des applications du modèle VLOGGER est la suivante : il peut faire taire le personnage, fermer les yeux, fermer uniquement l'œil gauche ou ouvrir l'œil entier. en un clic :

Une autre application est la traduction vidéo :
Par exemple, changer le discours anglais de la vidéo originale en espagnol avec la même forme de bouche.
Enfin, selon "l'ancienne règle", Google n'a pas publié le modèle. Maintenant, tout ce que nous pouvons voir, ce sont plus d'effets et de papiers.
Eh bien, il y a beaucoup de plaintes :
La qualité d'image du modèle, la synchronisation labiale ne correspond pas, ça a toujours l'air très robotique, etc.
Certaines personnes n'ont donc pas hésité à laisser un avis négatif :
Est-ce le niveau de Google ?

Je suis un peu désolé pour le nom « VLOGGER ».

——Par rapport à Sora d'OpenAI, la déclaration de l'internaute n'est en effet pas déraisonnable. .
Qu'en pensez-vous ?
Plus d'effets :https://enriccorona.github.io/vlogger/
Article complet : https://enriccorona.github.io/vlogger/paper.pdf
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Cache mybatis de premier niveau et cache de deuxième niveau
Cache mybatis de premier niveau et cache de deuxième niveau
 Comment utiliser le paramètre Oracle
Comment utiliser le paramètre Oracle
 Solution au problème xlive.dll manquant
Solution au problème xlive.dll manquant
 Qu'est-ce que la certification 3c
Qu'est-ce que la certification 3c
 Combien coûte un Bitcoin en RMB ?
Combien coûte un Bitcoin en RMB ?
 Comment ouvrir le fichier img
Comment ouvrir le fichier img
 Les données entre le système Hongmeng et le système Android peuvent-elles être interopérables ?
Les données entre le système Hongmeng et le système Android peuvent-elles être interopérables ?
 Tutoriel C#
Tutoriel C#








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



