


Un journal est une séquence complètement ordonnée d'enregistrements ajoutés par ordre chronologique. Il s'agit en fait d'un format de fichier spécial. Le fichier est un tableau d'octets, et le journal ici est une donnée d'enregistrement, mais par rapport au fichier, chaque élément ici est un enregistrement. organisé dans un ordre relatif dans le temps.On peut dire que le journal est le modèle de stockage le plus simple.Par exemple, les files d'attente de messages écrivent généralement de manière linéaire dans le fichier journal.L'ordre du consommateur commence à partir du décalage. .
En raison des caractéristiques inhérentes du journal lui-même, les enregistrements sont insérés séquentiellement de gauche à droite, ce qui signifie que les enregistrements de gauche sont « plus anciens » que ceux de droite. En d'autres termes, nous n'avons pas besoin de nous fier aux enregistrements. horloge système. Cette fonctionnalité est très utile pour les distributions très importantes pour le système.
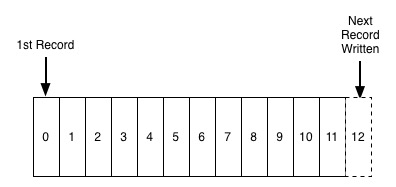
Il est impossible de savoir quand le journal est apparu. Il se peut que son concept soit trop simple. Dans le domaine de la base de données, les journaux sont davantage utilisés pour synchroniser les données et les index lorsque le système tombe en panne, comme le journal redo dans MySQL. Le journal redo est une structure de données basée sur le disque utilisée pour garantir l'exactitude et l'exhaustivité des données en cas de panne du système. Le système est également appelé journaux à écriture anticipée. Par exemple, lors de l'exécution d'une chose, le journal redo sera écrit en premier, puis les modifications réelles seront appliquées de cette façon, lorsque le système récupère après un crash. réécrit en fonction du journal redo. Remettez-le pour restaurer les données (pendant le processus d'initialisation, il n'y aura pas de connexion client pour le moment). Le journal peut également être utilisé pour la synchronisation entre le maître et l'esclave de la base de données, car essentiellement, tous les enregistrements d'opérations de la base de données ont été écrits dans le journal. Il nous suffit de synchroniser le journal avec l'esclave et de le relire sur l'esclave pour devenir maître. -synchronisation esclave. De nombreux autres composants requis peuvent également être implémentés ici. Nous pouvons obtenir toutes les modifications dans la base de données en nous abonnant au redo log, implémentant ainsi une logique métier personnalisée, telle que l'audit, la synchronisation du cache, etc.
Les services système distribués concernent essentiellement les changements d'état, qui peuvent être compris comme des machines à états. Deux processus indépendants (ne dépendant pas de l'environnement externe, comme les horloges système, les interfaces externes, etc.) produiront des sorties cohérentes avec des entrées cohérentes et, en fin de compte, les maintiendront. un état cohérent et le journal ne dépend pas de l'horloge système en raison de sa séquence inhérente, qui peut être utilisée pour résoudre le problème de l'ordre de modification.
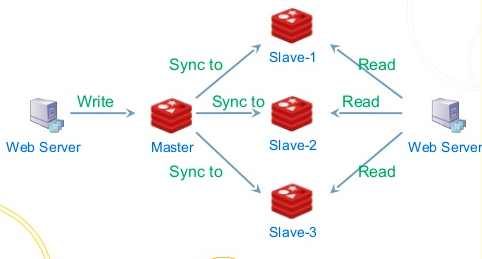
Nous utilisons cette fonctionnalité pour résoudre de nombreux problèmes rencontrés dans les systèmes distribués. Par exemple, dans le nœud de veille de RocketMQ, le courtier principal reçoit la demande du client et enregistre le journal, puis le synchronise avec l'esclave en temps réel. L'esclave le relit localement. Lorsque le maître raccroche, l'esclave peut continuer à le faire. traiter la demande, par exemple rejeter la demande d'écriture et continuer. Gérer les demandes de lecture. Le journal peut non seulement enregistrer des données, mais également enregistrer directement des opérations, telles que des instructions SQL.
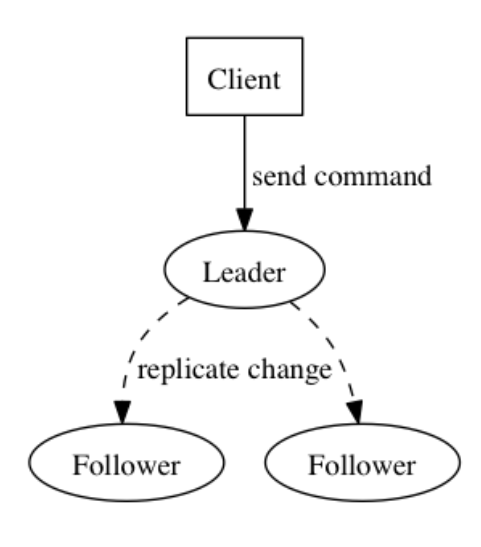
Le journal est la structure de données clé pour résoudre le problème de cohérence. Le journal est comme une séquence d'opérations. Par exemple, les protocoles Paxos et Raft largement utilisés sont tous des protocoles de cohérence construits sur la base du journal.
Les journaux peuvent être facilement utilisés pour gérer les entrées et les sorties de données. Chaque source de données peut générer son propre journal. Les sources de données ici peuvent provenir de divers aspects, tels qu'un flux d'événements (clic sur une page, rappel d'actualisation du cache, modifications du journal binaire de la base de données). ), nous pouvons stocker les journaux de manière centralisée dans un cluster, et les abonnés peuvent lire chaque enregistrement du journal en fonction du décalage et appliquer leurs propres modifications en fonction des données et des opérations dans chaque enregistrement.
Le journal ici peut être compris comme une file d'attente de messages, et la file d'attente de messages peut jouer le rôle de découplage asynchrone et de limitation de courant. Pourquoi parle-t-on de découplage ? Parce que pour les consommateurs et les producteurs, les responsabilités des deux rôles sont très claires, ils sont responsables de produire des messages et de consommer des messages, sans se soucier de qui est en aval ou en amont, qu'il s'agisse du journal des modifications de la base de données ou d'un certain événement. Je n'ai pas du tout besoin de me soucier d'une certaine partie. Je dois seulement faire attention aux journaux qui m'intéressent et à chaque enregistrement dans les journaux.
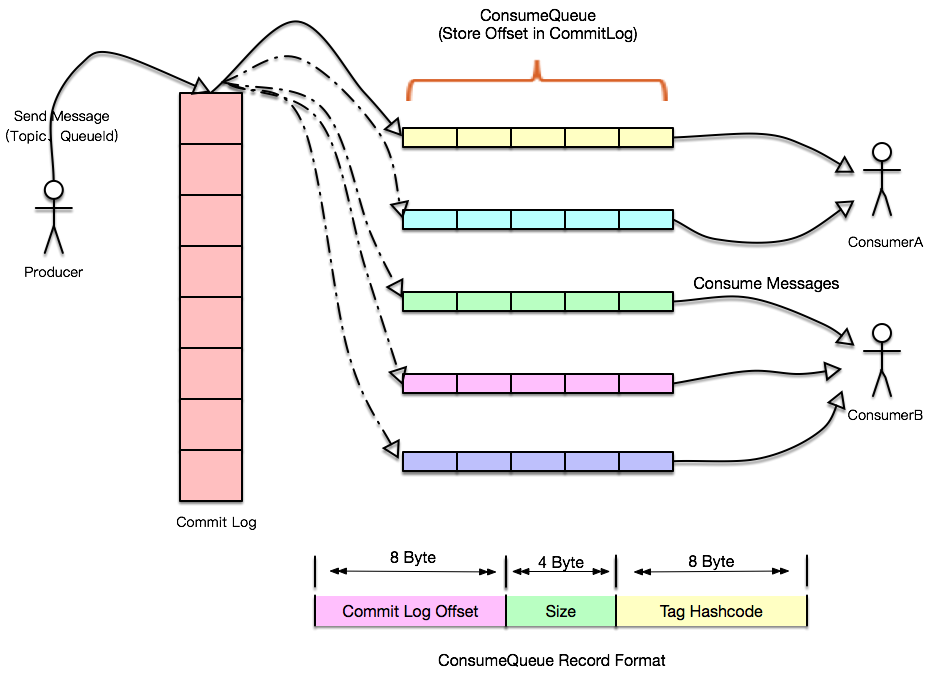
Nous savons que le QPS de la base de données est certain et que les applications de couche supérieure peuvent généralement être étendues horizontalement. À ce stade, s'il y a un scénario de demande soudaine comme Double 11, la base de données sera submergée, nous pouvons alors introduire des files d'attente de messages. pour combiner les opérations de la base de données de chaque équipe Écrivez dans le journal, et une autre application est responsable de la consommation de ces enregistrements de journal et de leur application à la base de données. Même si la base de données se bloque, le traitement peut continuer à partir de la position du dernier message lors de la récupération (les deux). RocketMQ et Kafka prennent en charge la sémantique Exactly Once), ici même si la vitesse du producteur est différente de la vitesse du consommateur, il n'y aura aucun impact ici. Il peut stocker tous les enregistrements dans le journal et les synchroniser. au nœud esclave régulièrement, de sorte que le message La capacité du backlog peut être considérablement améliorée car l'écriture des journaux est traitée par le nœud maître. Il existe deux types de demandes de lecture. L'une est la lecture finale, ce qui signifie que la vitesse de consommation peut suivre. avec la vitesse d'écriture. Ce type de lecture Vous pouvez accéder directement au cache, et l'autre est le consommateur qui est en retard sur la demande d'écriture. Ce type de lecture peut être lu à partir du nœud esclave, via l'isolation des E/S et certaines politiques de fichiers qui viennent. avec le système d'exploitation, tel que le cache de page, la lecture anticipée du cache, etc., les performances peuvent être considérablement améliorées.
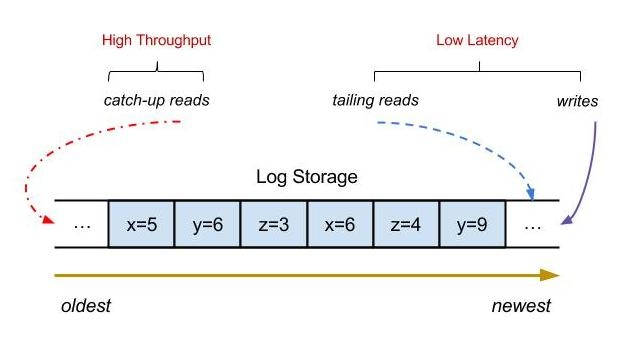
L'évolutivité horizontale est une fonctionnalité très importante dans un système distribué. Les problèmes qui peuvent être résolus en ajoutant des machines ne sont pas un problème. Alors, comment implémenter une file d'attente de messages capable de réaliser une expansion horizontale ? Si nous avons une file d'attente de messages autonome, à mesure que le nombre de sujets augmente, les E/S, le processeur, la bande passante, etc. comment procéder ici ? Qu'en est-il de l'optimisation des performances ?
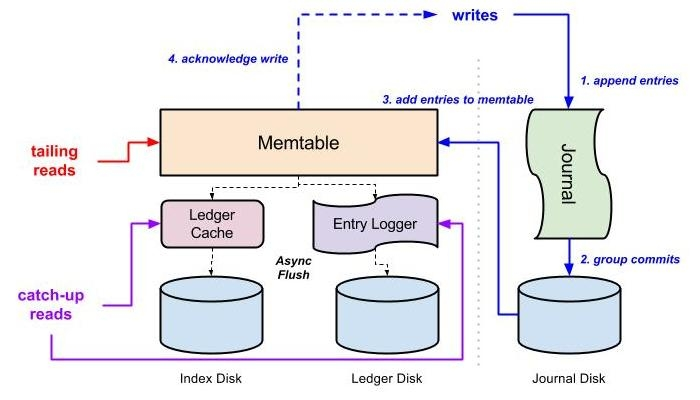
Les journaux jouent un rôle très important dans les systèmes distribués et sont la clé pour comprendre divers composants des systèmes distribués. À mesure que notre compréhension s'approfondit, nous constatons que de nombreux middleware distribués sont construits sur la base de journaux, tels que Zookeeper, HDFS, Kafka, RocketMQ, Google. Spanner, etc., et même des bases de données telles que Redis, MySQL, etc., leur maître-esclave est basé sur la synchronisation des journaux. En nous appuyant sur le système de journaux partagés, nous pouvons implémenter de nombreux systèmes : synchronisation des données et concurrence entre les nœuds. Problèmes d'ordre des données de mise à jour. (problèmes de cohérence), de persistance (le système peut continuer à fournir des services via d'autres nœuds lorsque le système tombe en panne), de services de verrouillage distribués, etc. Je crois que grâce à la pratique et à la lecture d'un grand nombre d'articles, il y aura des niveaux de compréhension plus profonds. compréhension.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



