


Afin de résoudre le problème de l'extraction insuffisante d'informations visuelles dans les grands modèles de langage multimodaux, des chercheurs de l'Institut de technologie de Harbin (Shenzhen) ont proposé un modèle de grand langage multimodal à double couche amélioré par les connaissances, JiuTian-LION.

Le contenu qui doit être réécrit est : Lien papier : https://arxiv.org/abs/2311.11860
GitHub : https://github.com/rshaojimmy/JiuTian
Page d'accueil du projet : https://rshaojimmy.github.io/Projects/JiuTian-LION
Par rapport aux travaux existants, JiuTian a analysé pour la première fois les conflits internes entre les tâches de compréhension au niveau de l'image et les tâches de positionnement au niveau de la région. , et a proposé une stratégie de réglage fin des instructions segmentées et un adaptateur hybride pour parvenir à une amélioration mutuelle des deux tâches.
En injectant une perception spatiale fine et des connaissances visuelles sémantiques de haut niveau, Jiutian a obtenu des améliorations significatives des performances sur 17 tâches de langage visuel, notamment la description d'image, les problèmes visuels et la localisation visuelle (par exemple jusqu'à 5 sur le raisonnement spatial visuel). ) % d'amélioration des performances), atteignant le premier niveau international dans 13 tâches d'évaluation. La comparaison des performances est présentée dans la figure 1.
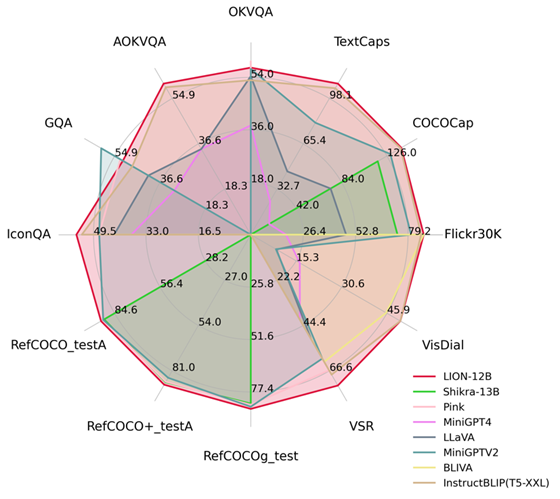
Figure 1 : Comparé à d'autres MLLM, Jiutian a atteint des performances optimales sur la plupart des tâches.
En donnant aux grands modèles de langage (LLM) des capacités de perception multimodale, certains travaux ont commencé pour générer de grands modèles de langage (MLLM) multimodaux et ont fait des progrès révolutionnaires sur de nombreuses tâches de langage visuel. Cependant, les MLLM existants utilisent principalement des encodeurs visuels pré-entraînés sur des paires image-texte, tels que CLIP-ViT
La tâche principale de ces encodeurs visuels est d'apprendre l'alignement modal image-texte à gros grain au niveau de l'image, mais ils manquent de capacités complètes de perception visuelle et d'extraction d'informations, incapables d'effectuer une compréhension visuelle fine
Dans une large mesure, ce problème d'extraction d'informations visuelles insuffisante et de compréhension insuffisante entraînera un biais de positionnement visuel, un raisonnement spatial insuffisant et une insuffisance compréhension des MLLM. Il existe de nombreux défauts tels que l'illusion d'objet, comme le montre la figure 2
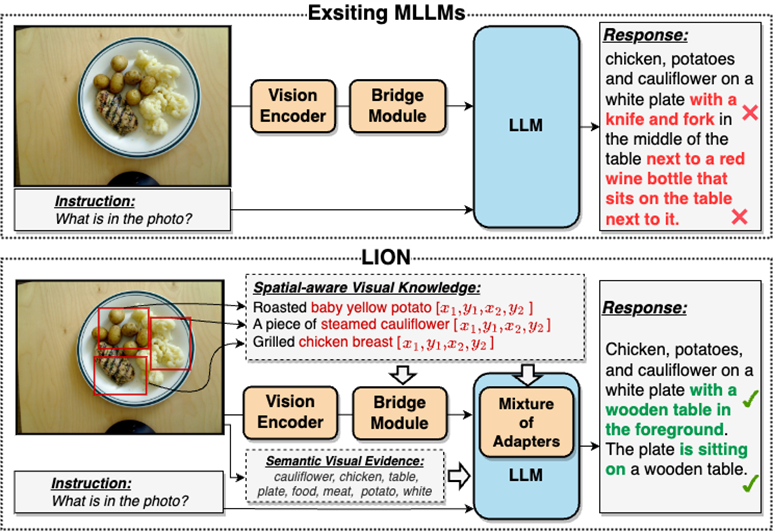
Veuillez vous référer à la figure 2 : JiuTian-LION est un grand modèle de langage multimodal amélioré avec des connaissances visuelles à double couche
Par rapport aux grands modèles de langage multimodaux (MLLM) existants, Jiutian améliore efficacement les capacités de compréhension visuelle des MLLM en injectant des connaissances visuelles de conscience spatiale à granularité fine et des preuves visuelles sémantiques de haut niveau, génère des réponses textuelles plus précises et réduit Le phénomène d'hallucination des MLLM
Modèle de grand langage multimodal à double couche amélioré par les connaissances visuelles-JiuTian-LION
Afin de résoudre les lacunes des MLLM dans l'extraction et la compréhension des informations visuelles, les chercheurs ont proposé un Une méthode MLLM améliorée de connaissances visuelles à double couche est proposée, appelée JiuTian-LION. Le cadre spécifique de la méthode est présenté dans la figure 3
Cette méthode améliore principalement les MLLM sous deux aspects, l'intégration progressive de connaissances visuelles spatiales à grain fin (Incorporation progressive de connaissances visuelles spatiales à grain fin) et de haut niveau. logiciel sous invites logicielles Invite douce de preuves visuelles sémantiques de haut niveau.
Plus précisément, les chercheurs ont proposé une stratégie de réglage fin des instructions segmentées pour résoudre le conflit interne entre la tâche de compréhension au niveau de l'image et la tâche de localisation au niveau de la région. Ils injectent progressivement des connaissances fines en matière de conscience spatiale dans les MLLM. Dans le même temps, ils ont ajouté des étiquettes d'image comme preuve visuelle sémantique de haut niveau aux MLLM et ont utilisé des méthodes d'invite douces pour atténuer l'impact négatif que des étiquettes incorrectes peuvent apporter. Le diagramme du cadre du modèle JiuTian-LION est le suivant :
.Ce travail utilise une stratégie de formation segmentée pour apprendre d'abord la compréhension au niveau de l'image et les tâches de positionnement au niveau de la région basées respectivement sur les branches Q-Former et Vision Aggregator-MLP, puis utilise un adaptateur hybride avec un mécanisme de routage pour fusionner dynamiquement différentes tâches. dans la phase finale de formation. Exécution du modèle d'amélioration des connaissances ramifiées sur deux tâches.
Ce travail extrait également les étiquettes d'image en tant que preuve visuelle sémantique de haut niveau via la RAM, puis propose une méthode d'invite douce pour améliorer l'effet de l'injection sémantique de haut niveau
Fusionner progressivement les visuels de conscience spatiale à granularité fine connaissances
Lors de l'exécution directe d'une formation mixte en une seule étape sur des tâches de compréhension au niveau de l'image (y compris la description de l'image et la réponse visuelle aux questions) et des tâches de localisation au niveau régional (y compris la compréhension d'expression dirigée, la génération d'expression dirigée, etc.), les MLLM rencontrera des conflits internes entre les deux tâches. En conséquence, une meilleure performance globale ne pourra pas être obtenue sur toutes les tâches.
Les chercheurs estiment que ce conflit interne est principalement causé par deux problèmes. Le premier problème est le manque de pré-formation à l'alignement modal au niveau régional. Actuellement, la plupart des MLLM dotés de capacités de positionnement au niveau régional utilisent d'abord une grande quantité de données pertinentes pour la pré-formation, sinon il sera difficile d'utiliser le niveau image. alignement modal basé sur des ressources de formation limitées. Adaptation des fonctionnalités visuelles aux tâches au niveau régional.
Un autre problème est la différence dans les modèles d'entrée-sortie entre les tâches de compréhension au niveau de l'image et les tâches de localisation au niveau de la région, ces dernières nécessitant que le modèle comprenne en outre des phrases courtes spécifiques sur les coordonnées des objets (sous la forme de 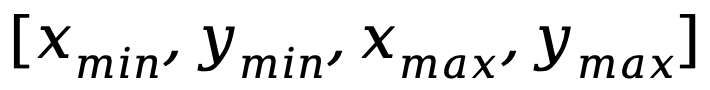 ) . Afin de résoudre les problèmes ci-dessus, les chercheurs ont proposé une stratégie de réglage fin des instructions segmentées et un adaptateur hybride avec un mécanisme de routage.
) . Afin de résoudre les problèmes ci-dessus, les chercheurs ont proposé une stratégie de réglage fin des instructions segmentées et un adaptateur hybride avec un mécanisme de routage.
Comme le montre la figure 4, les chercheurs ont divisé le processus de réglage fin des instructions en une seule étape en trois étapes :
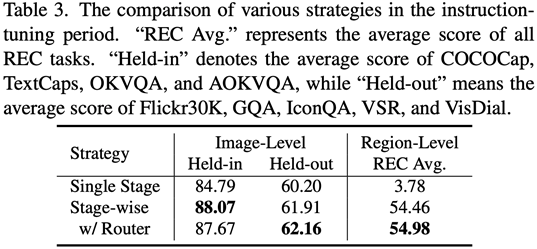
Utilisez ViT, Q-Former et l'adaptateur au niveau de l'image pour apprendre la tâche de compréhension au niveau de l'image de connaissances visuelles globales ; utiliser Vision Aggregator, MLP et les adaptateurs au niveau régional pour apprendre les tâches de positionnement au niveau régional avec des connaissances visuelles spatiales à granularité fine ; un adaptateur hybride avec un mécanisme de routage est proposé pour intégrer dynamiquement les connaissances visuelles de différentes granularités apprises dans différents branches. Le tableau 3 montre les avantages en termes de performances de la stratégie de réglage fin de l'instruction segmentée par rapport à la formation en une seule étape
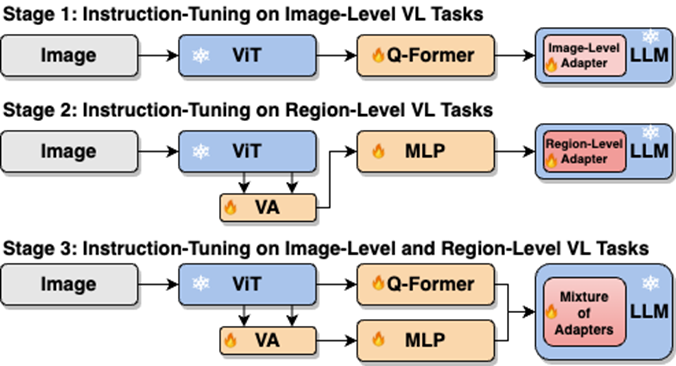
Figure 4 : La stratégie de réglage fin de l'instruction segmentée
pour l'injection de logiciels invites Les preuves visuelles sémantiques de haut niveau doivent être réécrites
Les chercheurs ont proposé d'utiliser des étiquettes d'images comme un complément efficace aux preuves visuelles sémantiques de haut niveau pour améliorer encore la capacité de compréhension de la perception visuelle globale des MLLM
Plus précisément, extrayez d'abord les balises de l'image via la RAM, puis utilisez le modèle de commande spécifique « Selon
Couplé à l'expression spécifique « utiliser ou utiliser partiellement » dans le modèle, le vecteur d'indice doux peut guider le modèle pour atténuer l'impact négatif potentiel des étiquettes incorrectes.
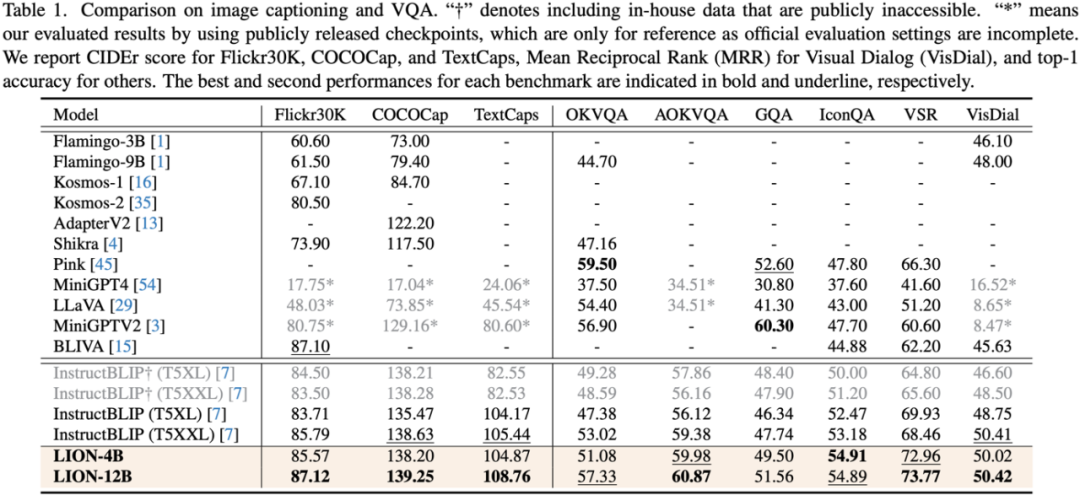
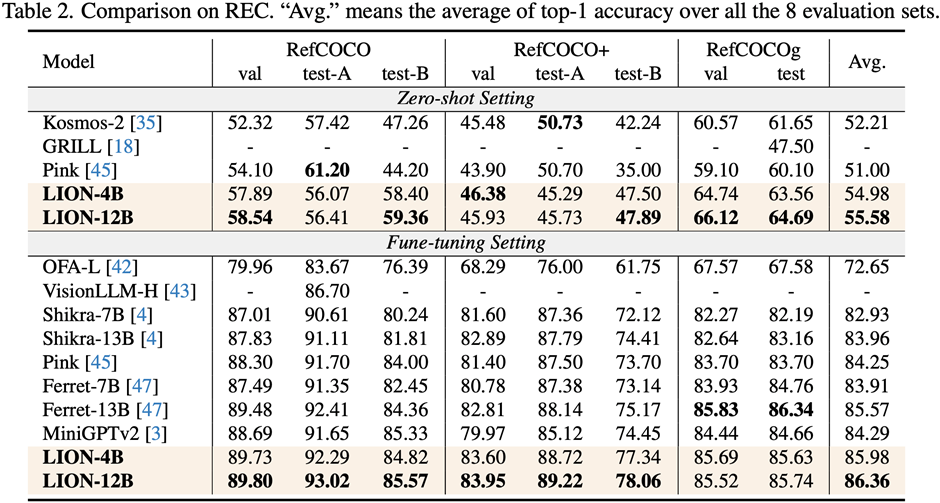
Les chercheurs ont mené des évaluations sur 17 ensembles de tâches de référence, notamment le sous-titrage d'images, la réponse visuelle aux questions (VQA) et la compréhension de l'expression pédagogique (REC).
Les résultats expérimentaux montrent que Jiutian a atteint le premier niveau international dans 13 ensembles d'évaluation. En particulier, par rapport à InstructBLIP et Shikra, Jiutian a obtenu des améliorations complètes et cohérentes des performances dans les tâches de compréhension au niveau de l'image et les tâches de positionnement au niveau de la région, respectivement, et peut atteindre jusqu'à 5 % d'amélioration dans les tâches de raisonnement visuel spatial (VSR).
Comme le montre la figure 5, il existe des différences dans les capacités de Jiutian et d'autres MLLM dans différentes tâches multimodales de langage visuel, indiquant que Jiutian est plus performant en termes de compréhension visuelle fine et de capacités de raisonnement spatial visuel, et est capable pour produire une sortie avec une réponse textuelle moins hallucinante

Le contenu réécrit est : La cinquième figure montre une analyse qualitative de la différence de capacités du grand modèle Jiutian, InstructBLIP et Shikra
Figure 6 Par analyse d'échantillon , Cela montre que le modèle Jiutian possède d'excellentes capacités de compréhension et de reconnaissance dans les tâches de langage visuel au niveau de l'image et au niveau régional.

La sixième image : Grâce à l'analyse de plus d'exemples, les capacités du grand modèle Jiutian sont démontrées du point de vue de l'image et de la compréhension visuelle au niveau régional
(1) Ceci le travail propose Un nouveau modèle de grand langage multimodal - Jiutian : un grand modèle de langage multimodal amélioré par des connaissances visuelles à double couche.
(2) Ce travail a été évalué sur 17 ensembles de référence de tâches de langage visuel comprenant la description d'image, la réponse visuelle aux questions et la compréhension des expressions pédagogiques, parmi lesquels 13 ensembles d'évaluation ont obtenu la meilleure performance actuelle.
(3) Ce travail propose une stratégie de réglage fin de l'instruction segmentée pour résoudre le conflit interne entre les tâches de compréhension au niveau de l'image et de localisation au niveau de la région, et parvenir à une amélioration mutuelle entre les deux tâches
(4) Ce Le travail intègre avec succès la compréhension au niveau de l'image et les tâches de positionnement au niveau régional pour comprendre de manière globale les scènes visuelles à plusieurs niveaux. À l'avenir, cette capacité de compréhension visuelle complète pourra être appliquée aux scènes intelligentes incarnées pour aider les robots à fonctionner de manière plus efficace et plus intelligente. comprendre l’environnement actuel pour prendre des décisions efficaces.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment flasher le téléphone Xiaomi
Comment flasher le téléphone Xiaomi
 Introduction au protocole xmpp
Introduction au protocole xmpp
 Comment lire une vidéo avec python
Comment lire une vidéo avec python
 Quel est le nom chinois du fil coin ?
Quel est le nom chinois du fil coin ?
 Que signifie le format XML
Que signifie le format XML
 Comment débloquer les restrictions d'autorisation Android
Comment débloquer les restrictions d'autorisation Android
 utilisation de la fonction date
utilisation de la fonction date
 Comment envoyer votre position à quelqu'un d'autre
Comment envoyer votre position à quelqu'un d'autre








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



