


Les chercheurs ont souligné que CoDi-2 marque une avancée majeure dans le domaine du développement de modèles de base multimodaux complets
En mai de cette année, l'Université de Caroline du Nord à Chapel Hill et Microsoft ont proposé une diffusion composable (Composable Le modèle Diffusion (appelé CoDi) permet d'unifier plusieurs modalités avec un seul modèle. CoDi prend non seulement en charge la génération monomodale à monomodale, mais peut également recevoir plusieurs entrées conditionnelles et la génération conjointe multimodale.
Récemment, de nombreux chercheurs de l'UC Berkeley, de Microsoft Azure AI, de Zoom et de l'Université de Caroline du Nord à Chapel Hill ont mis à niveau le système CoDi vers la version CoDi-2

Adresse papier : https:// arxiv.org/pdf/2311.18775.pdf
Adresse du projet : https://codi-2.github.io/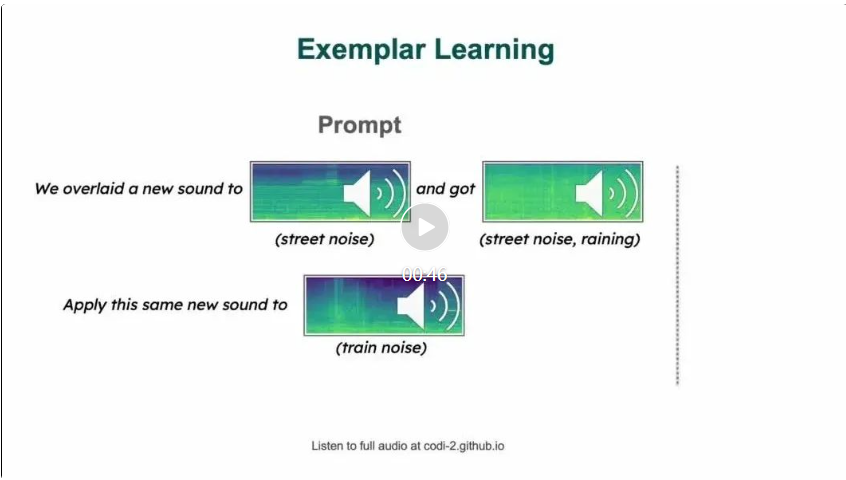
Réécrire le contenu sans changer le sens original. réécrit en langue chinoise, la phrase originale n'a pas besoin d'apparaître
Selon l'article de Zineng Tang, CoDi-2 suit des instructions contextuelles entrelacées multimodales complexes pour générer n'importe quelle modalité (texte, visuel et audio) avec un plan zéro ou interactions en quelques instants

Ce lien est la source de l'image : https://twitter.com/ZinengTang/status/1730658941414371820
On peut dire qu'en tant que grand langage multimodal polyvalent et interactif (MLLM), CoDi-2 peut effectuer un apprentissage contextuel, un raisonnement, un chat, une édition et d'autres tâches dans un paradigme modal d'entrée-sortie de n'importe quel type. En alignant les modalités et les langages lors de l'encodage et de la génération, CoDi-2 permet à LLM non seulement de comprendre des instructions d'entrelacement modal complexes et des exemples contextuels, mais également de générer de manière autorégressive une sortie multimodale raisonnable et cohérente dans un espace de fonctionnalités continu.
Pour entraîner CoDi-2, les chercheurs ont construit un ensemble de données génératives à grande échelle contenant des instructions multimodales contextuelles à travers du texte, des éléments visuels et audio. CoDi-2 démontre une gamme de capacités zéro-shot pour la génération multimodale, telles que l'apprentissage contextuel, le raisonnement et les combinaisons de génération modale tout-à-tout à travers plusieurs cycles de dialogue interactif. Parmi eux, il surpasse les modèles spécifiques à un domaine précédents dans des tâches telles que la génération d'images thématiques, la transformation visuelle et l'édition audio.

Plusieurs cycles de dialogue entre les humains et CoDi-2 fournissent des instructions multimodales contextuelles pour l'édition d'images.
Ce qui doit être réécrit est : l'architecture du modèle
CoDi-2 est conçu pour gérer les entrées multimodales telles que le texte, les images et l'audio en contexte, en utilisant des instructions spécifiques pour promouvoir l'apprentissage contextuel et générer le texte correspondant , sortie image et audio. Ce qui doit être réécrit pour CoDi-2 est le suivant : Le schéma d'architecture du modèle est le suivant.
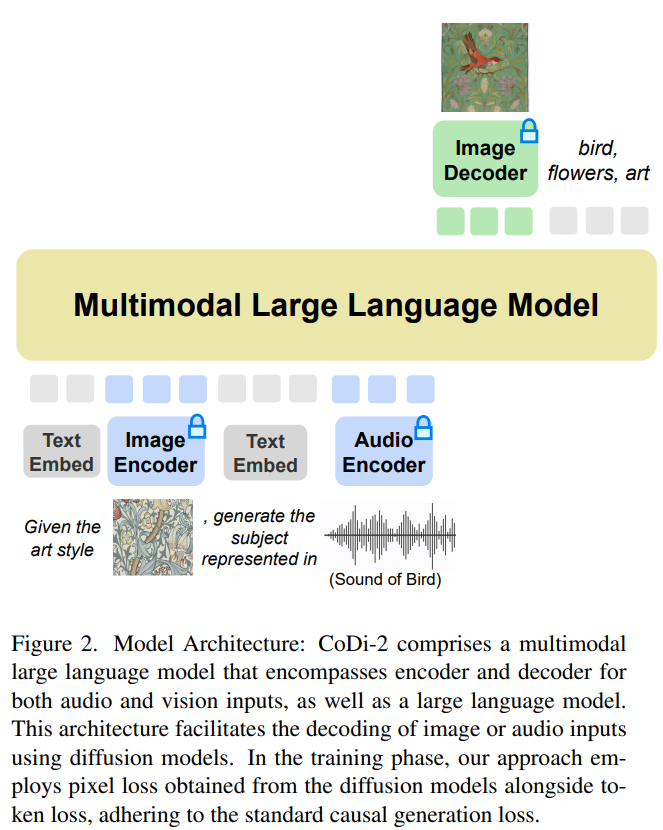
Utilisation d'un grand modèle de langage multimodal comme moteur de base
Ce modèle de base n'importe lequel peut digérer les entrées modales entrelacées, comprendre et raisonner sur des instructions complexes (telles que des conversations à plusieurs tours, des exemples) , et interagir avec le diffuseur multimodal La condition préalable pour réaliser tout cela est un moteur de base puissant. Les chercheurs ont proposé MLLM comme moteur, conçu pour fournir une perception multimodale pour les LLM contenant uniquement du texte.
Grâce au mappage d'encodeurs multimodaux alignés, les chercheurs peuvent de manière transparente rendre LLM conscient des séquences d'entrée modalement entrelacées. Plus précisément, lors du traitement de séquences d'entrée multimodales, ils utilisent d'abord des encodeurs multimodaux pour mapper les données multimodales aux séquences de fonctionnalités, puis des jetons spéciaux sont ajoutés avant et après la séquence de fonctionnalités, tels que "〈audio〉 [séquence de fonctionnalités audio " ] 〈/audio〉”.
La base de la génération multimodale est MLLM
Les chercheurs ont proposé d'intégrer le modèle de diffusion (DM) dans MLLM pour générer une sortie multimodale. Au cours de ce processus, des instructions et des invites multimodales entrelacées détaillées ont été suivies. Les objectifs de formation du modèle de diffusion sont les suivants :
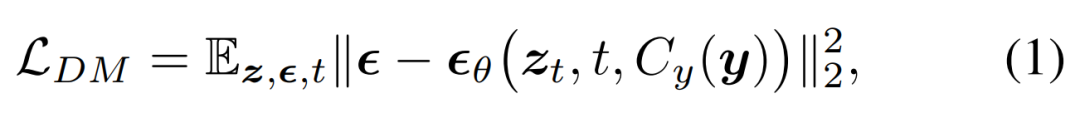
Ils ont ensuite proposé de former un MLLM pour générer des caractéristiques conditionnelles c = C_y (y), qui sont introduites dans un modèle de diffusion pour synthétiser la sortie cible x. De cette manière, la perte générative du modèle de diffusion est utilisée pour entraîner le MLLM.
Types de tâches
Le modèle démontre de fortes capacités dans les exemples de types de tâches suivants, qui fournissent une approche unique qui incite le modèle à générer ou à transformer du contenu multimodal en contexte, y compris du texte, des images, de l'audio, de la vidéo et leur combinaison
Le contenu réécrit est : 1. Inférence à échantillon nul. Les tâches d'inférence sans tir nécessitent que le modèle raisonne et génère un nouveau contenu sans aucun exemple précédent
2. Un ou quelques exemples d'invites fournissent au modèle un ou quelques exemples à partir desquels apprendre avant d'effectuer des tâches similaires. Cette approche est évidente dans les tâches où le modèle applique les concepts appris d'une image à une autre, ou crée une nouvelle œuvre d'art en comprenant le style décrit dans l'exemple fourni.
Expériences et résultats
Paramètres du modèle
L'implémentation du modèle dans cet article est basée sur Llama2, en particulier Llama-2-7b-chat-hf. Les chercheurs ont utilisé ImageBind, qui a aligné les encodeurs d’image, vidéo, audio, texte, profondeur, thermique et IMU. Nous utilisons ImageBind pour encoder les fonctionnalités d'image et audio et les projeter via un perceptron multicouche (MLP) vers les dimensions d'entrée d'un LLM (Llama-2-7b-chat-hf). MLP comprend une cartographie linéaire, une activation, une normalisation et une autre cartographie linéaire. Lorsque les LLM génèrent des fonctionnalités d’image ou audio, ils les projettent à nouveau dans la dimension de fonctionnalité ImageBind via un autre MLP. Le modèle de diffusion d'image dans cet article est basé sur StableDiffusion2.1 (stabilityai/stable-diffusion-2-1-unclip), AudioLDM2 et zeroscope v2.
Afin d'obtenir des images ou des audios d'entrée originaux d'une plus grande fidélité, les chercheurs les saisissent dans le modèle de diffusion et génèrent des caractéristiques en concaténant le bruit de diffusion. Cette méthode est très efficace, elle peut préserver au maximum les caractéristiques perceptuelles du contenu d'entrée et être capable d'ajouter du nouveau contenu ou de modifier le style et d'autres modifications d'instructions
Le contenu qui doit être réécrit est : Génération d'images évaluation
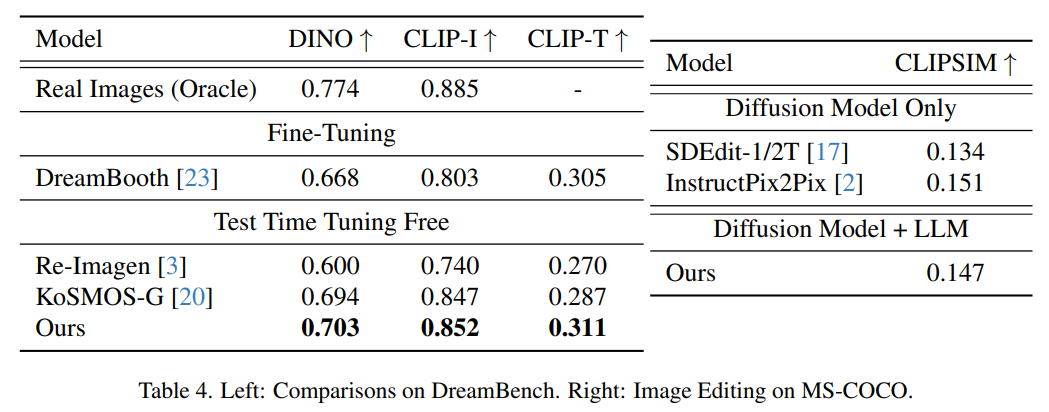
La figure suivante montre les résultats de l'évaluation de la génération d'images thématiques sur Dreambench et des scores FID sur MSCOCO. La méthode présentée dans cet article atteint des performances de tir zéro très compétitives, démontrant sa capacité de généralisation à de nouvelles tâches inconnues.
Évaluation de la génération audio
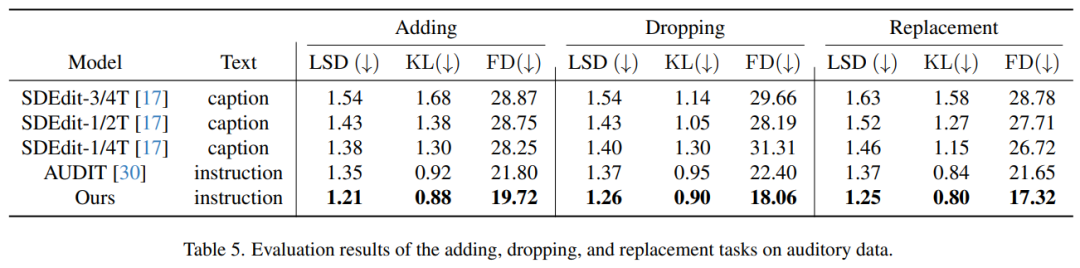
Le tableau 5 montre les résultats de l'évaluation de la tâche de traitement audio, c'est-à-dire l'ajout, la suppression et le remplacement d'éléments dans la piste audio. Il ressort clairement du tableau que notre méthode présente d’excellentes performances par rapport aux méthodes précédentes. Notamment, dans les trois tâches d'édition, il a obtenu les scores les plus bas pour toutes les mesures : distance spectrale log (LSD), divergence de Kullback-Leibler (KL) et distance de Fréchet (FD)
Lisez l'article original pour en savoir plus sur les aspects techniques. détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



