


Afin de ne pas changer le sens original, ce qui doit être réexprimé est : d'abord, nous devons comprendre pourquoi une validation croisée est nécessaire ?
La validation croisée est une technique couramment utilisée dans l'apprentissage automatique et les statistiques pour évaluer les performances et la capacité de généralisation d'un modèle prédictif, en particulier lorsque les données sont limitées ou lorsque l'évaluation de la capacité du modèle à généraliser à de nouvelles données invisibles est extrêmement précieuse.

Dans quelles circonstances la validation croisée sera-t-elle utilisée ?
L'idée générale de la validation croisée peut être illustrée dans la figure 5 fois croisée. À chaque itération, le nouveau modèle est formé sur quatre sous-ensembles de données et testé sur le dernier sous-ensemble de données conservé pour garantir que toutes les données. sont obtenus utilisation. Grâce à des indicateurs tels que le score moyen et l'écart type, une véritable mesure des performances du modèle est fournie
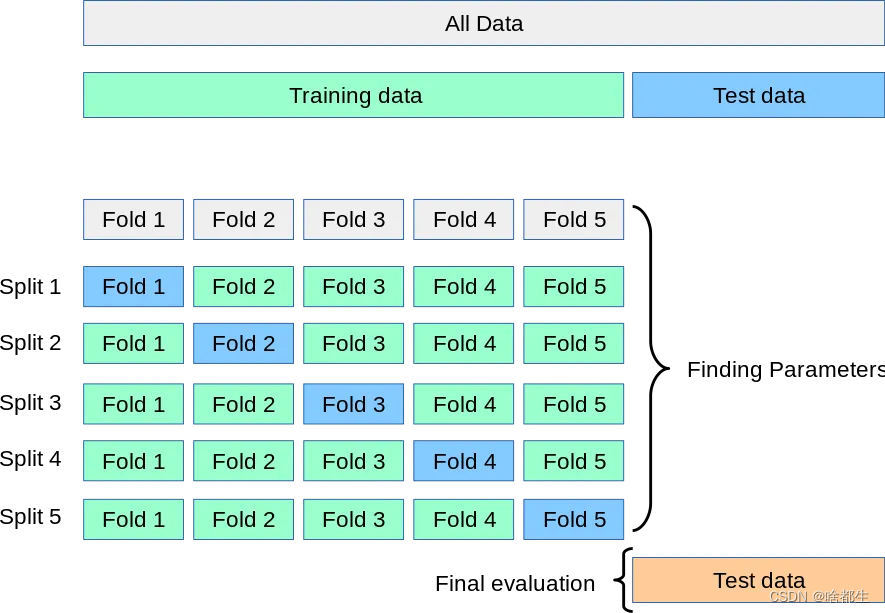
Tout doit commencer par un croisement K-fold.
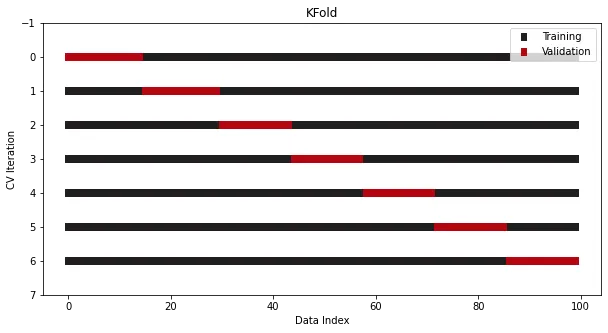
La validation croisée K-fold a été intégrée dans Sklearn. Voici un exemple 7 fois :
from sklearn.datasets import make_regressionfrom sklearn.model_selection import KFoldx, y = make_regression(n_samples=100)# Init the splittercross_validation = KFold(n_splits=7)
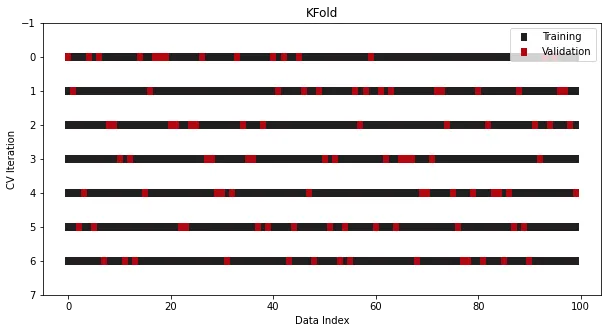
Une autre opération courante consiste à effectuer un Shuffle avant d'effectuer le fractionnement, détruisant ainsi l'ordre d'origine des échantillons. Minimise le risque de surajustement :
cross_validation = KFold(n_splits=7, shuffle=True)
De cette façon, une simple validation croisée k-fold peut être effectuée, assurez-vous de vérifier le code source ! Assurez-vous de consulter le code source ! Assurez-vous de consulter le code source !
StratifiedKFold est spécialement conçu pour les problèmes de classification.
Dans certains problèmes de classification, même si les données sont divisées en plusieurs ensembles, la distribution cible doit rester inchangée. Par exemple, dans la plupart des cas, une cible binaire avec un ratio de classes de 30 à 70 devrait toujours conserver le même ratio dans l'ensemble d'entraînement et l'ensemble de test, dans KFold ordinaire, cette règle est enfreinte car les données sont mélangées avant la division. les proportions des catégories ne seront pas maintenues.
Pour résoudre ce problème, une autre classe de séparation spécifiquement destinée à la classification est utilisée dans Sklearn - StratifiedKFold :
from sklearn.datasets import make_classificationfrom sklearn.model_selection import StratifiedKFoldx, y = make_classification(n_samples=100, n_classes=2)cross_validation = StratifiedKFold(n_splits=7, shuffle=True, random_state=1121218)
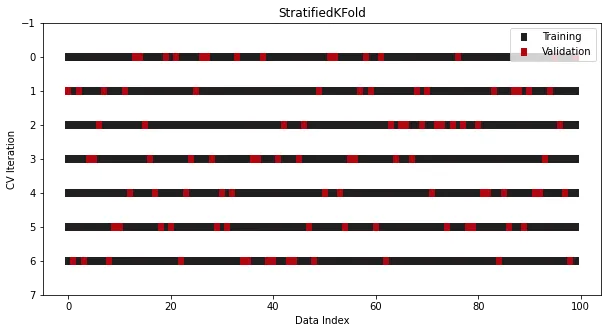
Bien qu'elle ressemble à KFold, désormais dans toutes les divisions et itérations, les proportions de classe restent cohérentes
Parfois le processus de division des ensembles de formation/test est simplement répété plusieurs fois, d'une manière très similaire à la validation croisée
Logiquement, en utilisant différentes graines aléatoires pour générer plusieurs ensembles de formation/test. L'ensemble de test doit être similaire à un ensemble de tests croisés robuste. processus de validation en suffisamment d'itérations. L'interface correspondante est également fournie dans la bibliothèque Scikit-learn :
from sklearn.model_selection import ShuffleSplitcross_validation = ShuffleSplit(n_splits=7, train_size=0.75, test_size=0.25)
 TimeSeriesSplit
TimeSeriesSplit
from sklearn.model_selection import TimeSeriesSplitcross_validation = TimeSeriesSplit(n_splits=7)
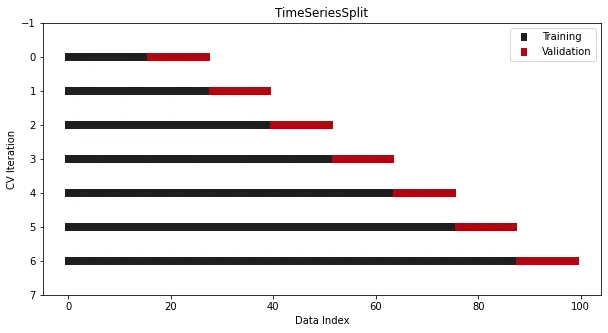 La situation où l'ensemble de validation est toujours situé après l'index de l'ensemble d'entraînement. Ci-dessous, nous pouvons voir le graphique. Cela est dû au fait que l'index est une date, ce qui signifie que nous ne pouvons pas accidentellement entraîner un modèle de série chronologique à une date future et faire une prédiction pour une date antérieure
La situation où l'ensemble de validation est toujours situé après l'index de l'ensemble d'entraînement. Ci-dessous, nous pouvons voir le graphique. Cela est dû au fait que l'index est une date, ce qui signifie que nous ne pouvons pas accidentellement entraîner un modèle de série chronologique à une date future et faire une prédiction pour une date antérieure
La méthode ci-dessus est traitée pour des ensembles de données indépendants et distribués de manière identique, c'est-à-dire que le processus de génération de données ne sera pas affecté par d'autres échantillons
Cependant , dans certains cas , les données ne satisfont pas à la condition de distribution indépendante et identique (IID), c'est-à-dire qu'il existe une relation de dépendance entre certains échantillons. Cette situation se produit également dans les compétitions Kaggle, comme le concours Google Brain Ventilator Pressure. Ces données enregistrent les valeurs de pression atmosphérique du poumon artificiel pendant des milliers de respirations (inspiration et expiration), et sont enregistrées à chaque instant de chaque respiration. Il existe environ 80 lignes de données pour chaque processus respiratoire, et ces lignes sont liées les unes aux autres. Dans ce cas, les méthodes traditionnelles de validation croisée ne peuvent pas être utilisées car le partitionnement des données peut « se produire en plein milieu d'un processus respiratoire »
Cela peut être compris comme la nécessité de « regrouper » ces données en raison de la données de groupe C'est lié. Par exemple, lors de la collecte de données médicales auprès de plusieurs patients, chaque patient dispose de plusieurs échantillons. Cependant, ces données sont susceptibles d'être affectées par les différences individuelles entre les patients et doivent donc également être regroupées.
Nous espérons souvent qu'un modèle formé sur un groupe spécifique pourra bien se généraliser à d'autres groupes invisibles. Ainsi, lors de la validation croisée, donnez à ces groupes de données des « balises » et dites-leur comment les distinguer.
Plusieurs interfaces sont fournies dans Sklearn pour gérer ces situations :
Il est fortement recommandé de comprendre l'idée de la validation croisée , et comment implémentez-le, regardez le code source de Sklearn : Ce n'est pas une mauvaise façon de grossir vos intestins. De plus, vous devez avoir une définition claire de votre propre ensemble de données, et le prétraitement des données est très important.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 La différence entre Scilab et Matlab
La différence entre Scilab et Matlab
 Méthode de production de rapports Intouch
Méthode de production de rapports Intouch
 Les dix principaux échanges de devises numériques
Les dix principaux échanges de devises numériques
 Introduction à la méthode d'imbrication des répéteurs
Introduction à la méthode d'imbrication des répéteurs
 Le commutateur Bluetooth Win10 est manquant
Le commutateur Bluetooth Win10 est manquant
 Configurer les variables d'environnement Java
Configurer les variables d'environnement Java
 tutoriel d'installation de pycharm
tutoriel d'installation de pycharm
 chaîne de correspondance d'expression régulière Java
chaîne de correspondance d'expression régulière Java








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



