


Mise à jour : ajout d'un nouvel exemple, un véhicule de livraison autonome entrant dans le sol en ciment de Xinpu
Sous beaucoup d'attention, GPT4 a finalement lancé aujourd'hui des fonctions liées à la vision. Cet après-midi, j'ai rapidement testé les capacités de perception d'images de GPT avec mes amis. Même si nous avions des attentes, nous avons quand même été très choqués. TL;DR est Je pense que les problèmes sémantiques liés à la conduite autonome auraient dû être très bien résolus par les grands modèles, mais la crédibilité et les capacités de perception spatiale des grands modèles ne sont toujours pas satisfaisantes. Cela devrait être plus que suffisant pour résoudre certains cas dits difficiles liés à l'efficacité, mais il est encore très loin de s'appuyer entièrement sur de gros modèles pour mener à bien la conduite de manière autonome et assurer la sécurité.


Description GPT4
Pièce précise : 3 camions ont été détectés et le numéro de plaque d'immatriculation du camion avant était fondamentalement correct (ignoré s'il y a des caractères chinois) (barre), la météo et l'environnement sont corrects, Obstacles inconnus identifiés avec précision sans invite
Pièces inexactes : la position du troisième camion est indiscernable de gauche à droite et le texte au-dessus de la tête du deuxième camion est une supposition. Un (à cause d'une résolution insuffisante ?)
Cela ne suffit pas, nous continuons à donner un petit indice pour demander ce qu'est cet objet et s'il peut être pressé dessus.
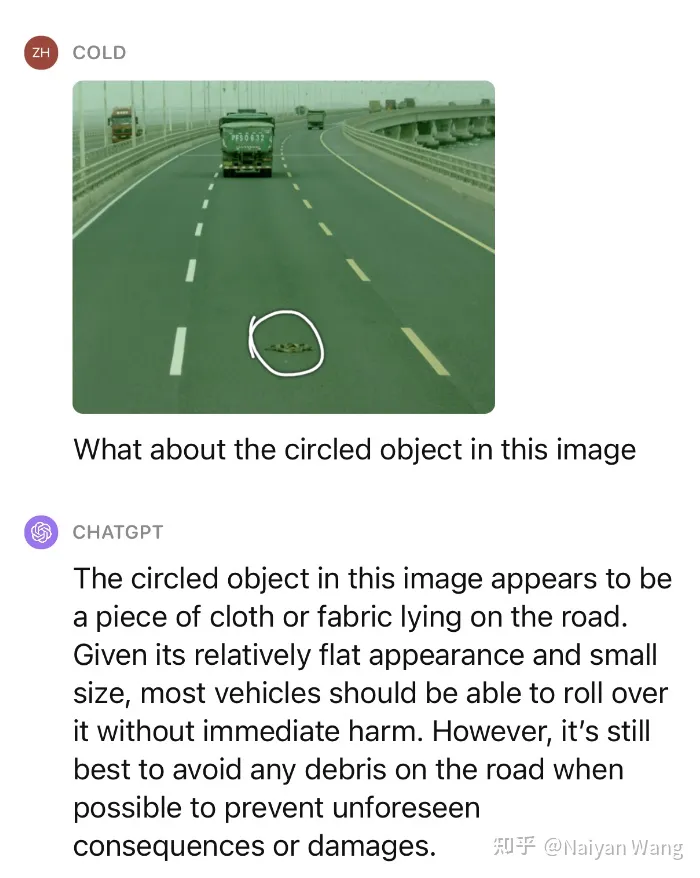
Impressionnant ! Nous avons testé plusieurs scénarios similaires, et les performances sur des obstacles inconnus peuvent être considérées comme très étonnantes.
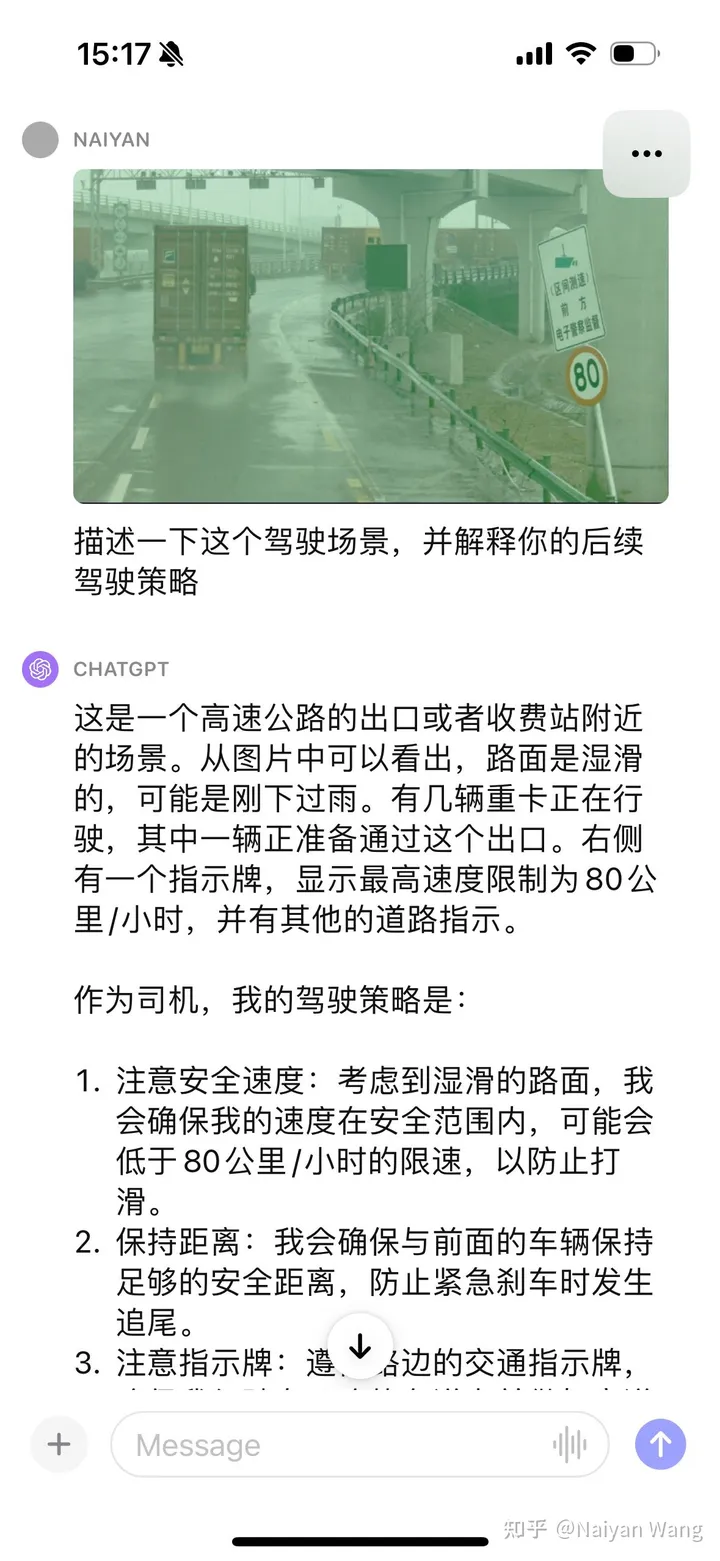
Il n'y a pas d'invite pour reconnaître automatiquement le panneau Cela devrait être basique, nous continuons à donner quelques indices

J'ai encore été choqué. . . Il pouvait automatiquement reconnaître le brouillard derrière le camion et a également mentionné la flaque d'eau, mais a encore une fois indiqué que la direction était à gauche. . . Je pense qu'une ingénierie rapide peut être nécessaire ici pour mieux permettre à GPT d'afficher la position et la direction.




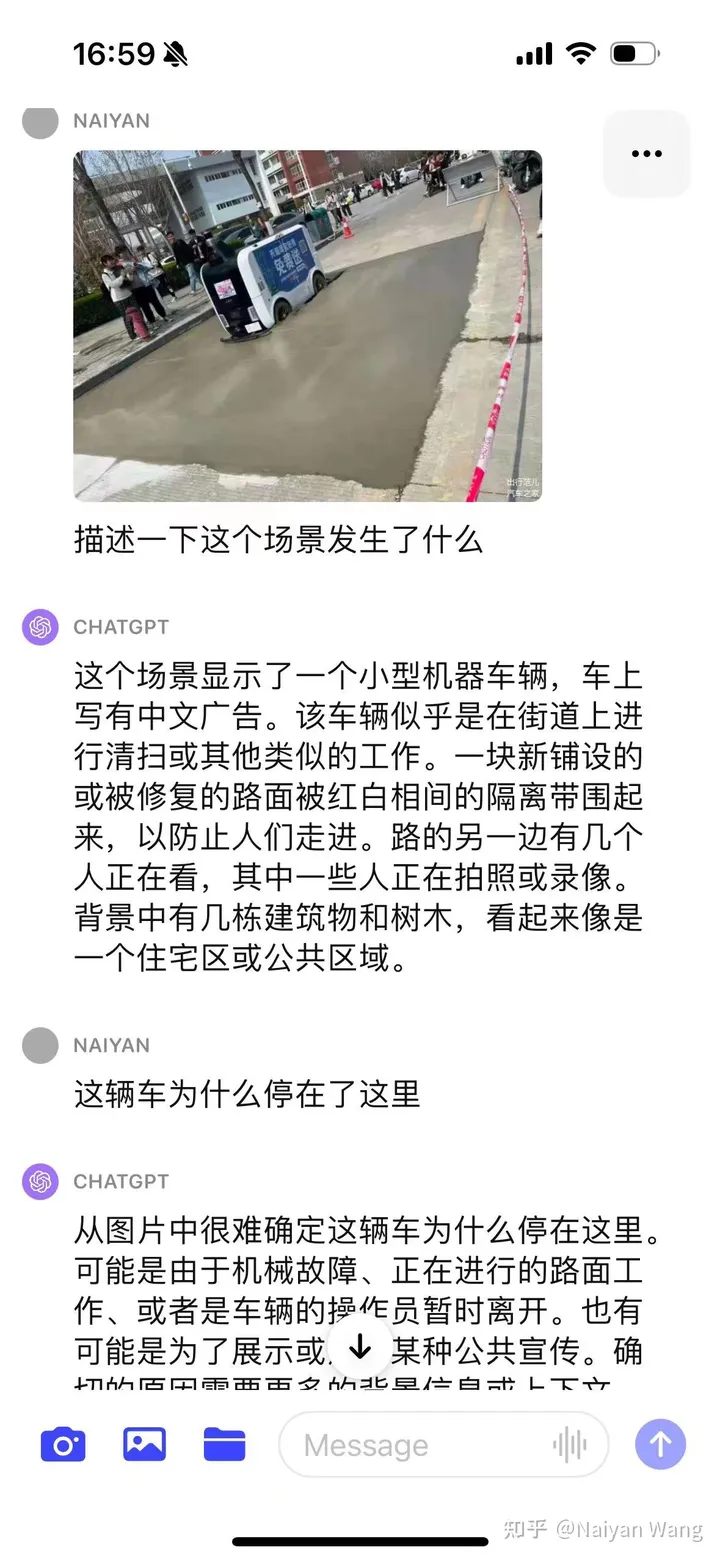
J'étais relativement conservateur au début et je n'ai pas directement deviné la raison. J'ai donné diverses suppositions. Cela est conforme à l'objectif d'alignement. Après avoir utilisé CoT, il a été découvert que le problème était que la voiture n'était pas considérée comme un véhicule autonome, donc donner ces informations via une invite peut donner des informations plus précises. Enfin, grâce à un certain nombre d'invites, on peut conclure que l'asphalte nouvellement posé n'est pas adapté à la conduite. Le résultat final est toujours correct, mais le processus est plus tortueux et nécessite une ingénierie plus rapide et une conception plus soignée. Cette raison peut également être due au fait qu'il ne s'agit pas d'une image en perspective à la première personne et qu'elle ne peut être spéculée qu'à partir d'une perspective à la troisième personne. Cet exemple n'est donc pas très précis.
Certaines tentatives rapides ont pleinement prouvé la puissance et les performances de généralisation de GPT4V. Des invites appropriées devraient pouvoir utiliser pleinement la force de GPT4V. La résolution du cas du coin sémantique devrait être très prometteuse, mais le problème de l’illusion continuera de nuire à certaines applications dans des scénarios liés à la sécurité. Très excitant. Je pense personnellement que l'utilisation rationnelle de modèles aussi grands peut considérablement accélérer le développement de la conduite autonome L4 et même L5. Cependant, LLM doit-il conduire directement ? La conduite de bout en bout, en particulier, reste une question discutable. J'ai beaucoup réfléchi ces derniers temps, alors je trouverai le temps d'écrire un article pour discuter avec vous tous~

Lien original : https://mp.weixin.qq.com/s/RtEek6HadErxXLSdtsMWHQ
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
 Quel est l'impact de la fermeture du port 445 ?
Quel est l'impact de la fermeture du port 445 ?
 Connecté au wifi mais impossible d'accéder à Internet
Connecté au wifi mais impossible d'accéder à Internet
 Quelles sont les fonctions couramment utilisées d'informix ?
Quelles sont les fonctions couramment utilisées d'informix ?
 Que signifie la liquidation ?
Que signifie la liquidation ?
 La pièce d'or Toutiao d'aujourd'hui est égale à 1 yuan
La pièce d'or Toutiao d'aujourd'hui est égale à 1 yuan
 La signification du titre en HTML
La signification du titre en HTML
 Commande cmd pour nettoyer les fichiers indésirables du lecteur C
Commande cmd pour nettoyer les fichiers indésirables du lecteur C








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



