


machineheartreport
Département éditorial Machine Heart
Récemment, Meta a dévoilé ses dernières avancées en matière d’intelligence artificielle.
Quand les gens pensent à Meta, ils pensent généralement à ses applications, notamment Facebook, Instagram, WhatsApp ou le prochain Metaverse. Mais ce que beaucoup de gens ignorent, c'est que cette entreprise conçoit et construit des centres de données très sophistiqués pour exploiter ces services.
Contrairement aux fournisseurs de services cloud comme AWS, GCP ou Azure, Meta n'est pas tenu de divulguer des détails sur sa sélection de silicium, son infrastructure ou la conception de son centre de données, sauf que son OCP est conçu pour impressionner les acheteurs. Les utilisateurs de Meta souhaitent une expérience meilleure et plus cohérente, quelle que soit la manière dont elle est réalisée.
Chez Meta, les charges de travail de l'IA sont omniprésentes et constituent la base d'un large éventail de cas d'utilisation, notamment la compréhension du contenu, le flux d'informations, l'IA générative et le classement des annonces. Ces charges de travail s'exécutent sur PyTorch, avec la meilleure intégration Python de sa catégorie, un développement en mode impatient et la simplicité de l'API. En particulier, les modèles de recommandation d’apprentissage profond (DLRM) sont très importants pour améliorer les services et l’expérience des applications de Meta. Mais à mesure que ces modèles augmentent en taille et en complexité, les systèmes matériels sous-jacents doivent fournir exponentiellement plus de mémoire et de puissance de calcul tout en restant efficaces.
Meta a constaté que pour les opérations d'IA à l'échelle actuelle et les charges de travail spécifiques, les GPU sont inefficaces et ne constituent pas le meilleur choix. Par conséquent, la société a proposé l’accélérateur d’inférence MTIA pour aider à former plus rapidement les systèmes d’IA.
MTIA V1
Puce MTIA v1 (inférence) (die)
En 2020, Meta a conçu l'accélérateur d'inférence MTIA ASIC de première génération pour ses charges de travail internes. L'accélérateur d'inférence fait partie de sa solution full-stack, qui comprend des modèles de silicium, PyTorch et de recommandation.
MTIA L'accélérateur est fabriqué selon le processus TSMC 7 nm et fonctionne à 800 MHz, délivrant 102,4 TOPS avec une précision INT8 et 51,2 TFLOPS avec une précision FP16. Il a une puissance thermique nominale (TDP) de 25 W.
L'accélérateur MTIA se compose d'éléments de traitement (PE), de ressources de mémoire sur puce et hors puce et d'interconnexions. L'accélérateur est équipé d'un sous-système de contrôle dédié exécutant le micrologiciel du système. Le micrologiciel gère les ressources de calcul et de mémoire disponibles, communique avec l'hôte via une interface hôte dédiée et coordonne l'exécution des tâches sur l'accélérateur.
Le sous-système de mémoire utilise LPDDR5 comme ressource DRAM hors puce, extensible jusqu'à 128 Go. La puce dispose également de 128 Mo de SRAM intégrée, partagée par tous les PE, offrant une bande passante plus élevée et une latence plus faible pour les données et instructions fréquemment consultées.
La grille d'accélérateur MTIA est composée de 64 PE organisés dans une configuration 8x8 qui sont connectés entre eux et aux blocs mémoire via un réseau maillé. La grille entière peut être utilisée dans son ensemble pour exécuter une tâche, ou elle peut être divisée en plusieurs sous-grilles pouvant exécuter des tâches indépendantes.
Chaque PE est équipé de deux cœurs de processeur (dont l'un est équipé d'extensions vectorielles) et d'un certain nombre d'unités à fonction fixe optimisées pour effectuer des opérations critiques telles que la multiplication matricielle, l'accumulation, le mouvement des données et les opérations non liées. calculs de fonctions linéaires. Le cœur du processeur est basé sur l'architecture de jeu d'instructions ouverte (ISA) RISC-V et est fortement personnalisé pour effectuer les tâches de calcul et de contrôle nécessaires.
Chaque PE dispose également de 128 Ko de mémoire SRAM locale pour un stockage et une manipulation rapides des données. Cette architecture maximise le parallélisme et la réutilisation des données, qui sont fondamentaux pour exécuter efficacement les charges de travail.
La puce offre à la fois un parallélisme au niveau des threads et des données (TLP et DLP), exploite le parallélisme au niveau des instructions (ILP) et permet un parallélisme massif au niveau de la mémoire (MLP) en permettant le traitement d'un grand nombre de requêtes de mémoire. simultanément.
Conception du système MTIA v1
Les accélérateurs MTIA sont montés sur de petites cartes doubles M.2 pour une intégration plus facile dans les serveurs. Les cartes utilisent une liaison PCIe Gen4 x8 pour se connecter au processeur hôte du serveur, consommant aussi peu que 35 W.

Exemple de carte de test avec MTIA
Les serveurs hébergeant ces accélérateurs utilisent la spécification de serveur Yosemite V3 de l'Open Compute Project. Chaque serveur contient 12 accélérateurs connectés au processeur hôte et entre eux à l'aide d'une hiérarchie de commutateurs PCIe. Par conséquent, la communication entre différents accélérateurs n’a pas besoin d’impliquer le processeur hôte. Cette topologie permet aux charges de travail d'être réparties sur plusieurs accélérateurs et exécutées en parallèle. Le nombre d'accélérateurs et les paramètres de configuration du serveur sont soigneusement sélectionnés pour exécuter au mieux les charges de travail actuelles et futures.
Pile logicielle MTIA
La pile logicielle (SW) MTIA est conçue pour offrir aux développeurs une meilleure efficacité de développement et une expérience hautes performances. Il est entièrement intégré à PyTorch, offrant aux utilisateurs une expérience de développement familière. Utiliser PyTorch avec MTIA est aussi simple que d'utiliser PyTorch avec un CPU ou un GPU. Et, grâce à l'écosystème et aux outils de développement PyTorch en plein essor, la pile SW MTIA peut désormais utiliser PyTorch FX IR pour effectuer des transformations et des optimisations au niveau du modèle, et LLVM IR pour les optimisations de bas niveau, tout en prenant également en charge les architectures personnalisées et ISA de l'accélérateur MTIA.
L'image ci-dessous montre le diagramme du framework de la pile logicielle MTIA :
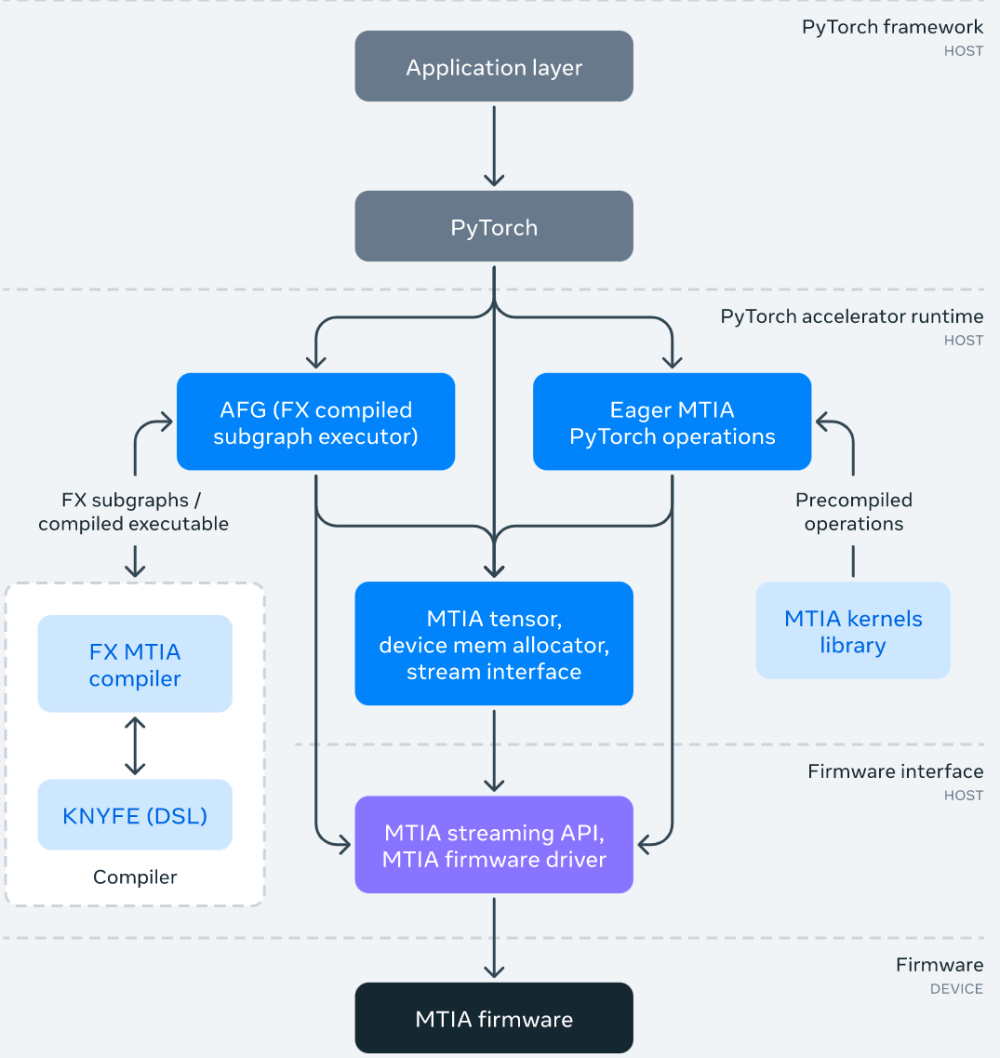
Dans le cadre de la pile SW, Meta a également développé une bibliothèque de noyau réglée à la main et hautement optimisée pour les noyaux ML critiques en termes de performances, tels que les opérateurs de packages entièrement connectés et intégrés. Les niveaux supérieurs de la pile logicielle ont la possibilité d'instancier et d'utiliser ces noyaux hautement optimisés lors de la compilation et de la génération de code.
De plus, la pile MTIA SW continue d'évoluer avec l'intégration avec PyTorch 2.0, qui est plus rapide et plus Pythonique, mais toujours aussi dynamique. Cela permettra de nouvelles fonctionnalités telles que TorchDynamo et TorchInductor. Meta étend également le Triton DSL pour prendre en charge l'accélérateur MTIA et utiliser MLIR pour la représentation interne et l'optimisation avancée.
Performances MTIA
Meta a comparé les performances du MTIA avec d'autres accélérateurs et les résultats sont les suivants :
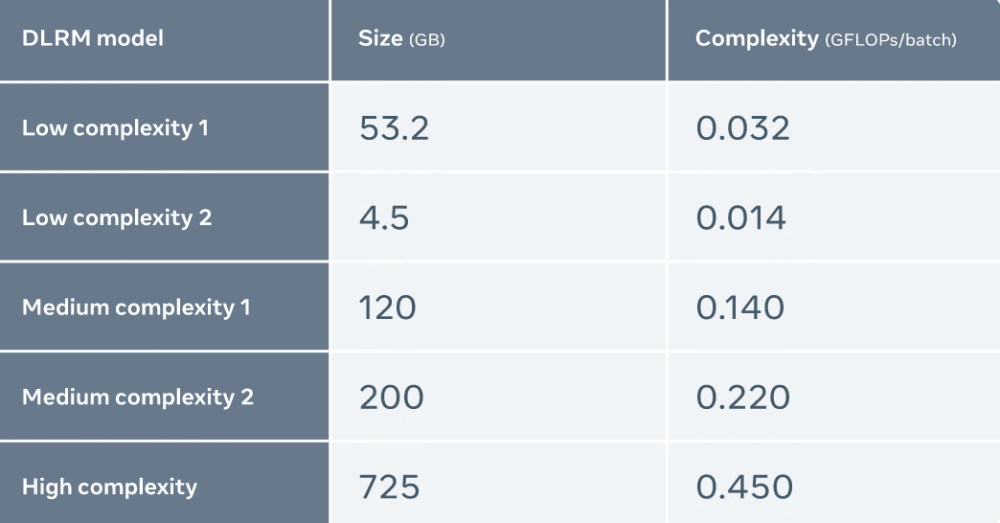
Meta utilise cinq DLRM différents (de faible à haute complexité) pour évaluer MTIA
De plus, Meta a comparé MTIA avec NNPI et GPU, et les résultats sont les suivants :

L'évaluation a révélé que MTIA est plus efficace dans le traitement des modèles de faible complexité (LC1 et LC2) et de complexité moyenne (MC1 et MC2) que NNPI et GPU. De plus, Meta n'a pas été optimisé pour MTIA pour les modèles de haute complexité (HC).
Lien de référence :
https://ai.facebook.com/blog/meta-training-inference-accelerator-AI-MTIA/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 utilisation des instructions mul
utilisation des instructions mul
 Fichier au format DAT
Fichier au format DAT
 Comment régler la luminosité de l'écran d'un ordinateur
Comment régler la luminosité de l'écran d'un ordinateur
 Comment augmenter le nombre de fans de Douyin rapidement et efficacement
Comment augmenter le nombre de fans de Douyin rapidement et efficacement
 Comment fermer la bibliothèque de ressources d'application
Comment fermer la bibliothèque de ressources d'application
 présentation de l'interface Lightning
présentation de l'interface Lightning
 vue fait référence aux fichiers js
vue fait référence aux fichiers js
 Formules de permutation et de combinaison couramment utilisées
Formules de permutation et de combinaison couramment utilisées








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



