


En décembre, alors que le ChatGPT d’OpenAI prend de l’ampleur, AlphaCode, qui accablait autrefois la moitié des programmeurs, fait la couverture de Science !

Lien papier : https://www.science.org/doi/10.1126/science.abq1158
En parlant d'AlphaCode, tout le monde doit le connaître.
Dès février de cette année, il a participé discrètement à 10 concours de programmation sur les célèbres Codeforces et a vaincu la moitié des codeurs humains d'un seul coup.
La moitié des codeurs sont allongés
Nous savons tous qu'un tel test est très populaire parmi les compétitions de programmeurs-programmation.
Dans le concours, le test principal est la capacité du programmeur à réfléchir de manière critique à travers son expérience et à créer des solutions à des problèmes imprévus.
Cela incarne la clé de l'intelligence humaine, et les modèles d'apprentissage automatique sont souvent difficiles à imiter cette intelligence humaine.
Mais les scientifiques de DeepMind ont enfreint cette règle.
YujiA Li et al. ont développé AlphaCode en utilisant une architecture d'apprentissage auto-supervisé et de convertisseur codeur-décodeur.

Le travail de développement d'AlphaCode a été complété à la maison
Bien qu'AlphaCode soit également basé sur l'architecture de codec Transformer standard, DeepMind l'a amélioré à un "niveau épique" ——
Il utilise un modèle de langage basé sur Transformer pour générer du code à une échelle sans précédent, puis filtre intelligemment un petit ensemble de programmes disponibles.
Les étapes spécifiques sont :
1) Attention multi-demandes : laissez chaque bloc d'attention partager l'en-tête de clé et de valeur, et combinez-le avec le modèle d'encodeur-décodeur en même temps pour augmenter la vitesse d'échantillonnage de AlphaCode Plus de 10 fois.
2) Modélisation en langage masqué (MLM) : En ajoutant une perte MLM à l'encodeur, le taux de solution du modèle est amélioré.
3) Trempe : Rendre la répartition de l'entraînement plus nette, évitant ainsi l'effet de régularisation du surapprentissage.
4) Conditionnement des valeurs et prédiction : fournissez un signal de formation supplémentaire en distinguant les soumissions de questions correctes et incorrectes dans l'ensemble de données CodeContests.
5) Génération d'apprentissage hors stratégie exemplaire (GOLD) : laissez le modèle générer la bonne solution pour chaque problème en concentrant la formation sur la solution la plus probable à chaque problème.
Eh bien, tout le monde connaît le résultat.
Avec un score Elo de 1238, AlphaCode s'est classé dans le top 54,3% sur ces 10 jeux. Si l'on considère les 6 mois précédents, ce résultat atteint le top 28 %.
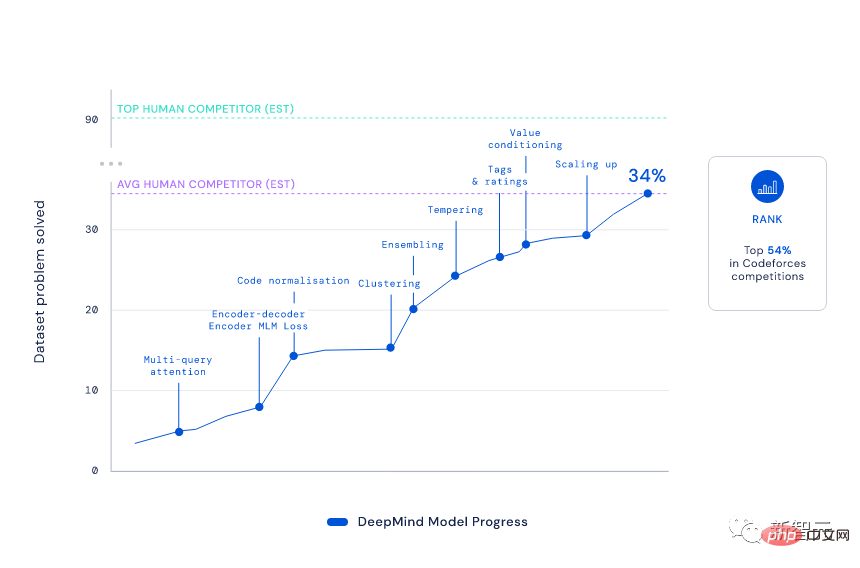
Il faut savoir que pour atteindre ce classement, AlphaCode doit "passer cinq niveaux et vaincre six généraux" et résoudre divers nouveaux problèmes qui combinent pensée critique, logique, algorithmes, codage et compréhension du langage naturel.
À en juger par les résultats, AlphaCode a non seulement résolu 29,6 % des problèmes de programmation dans l'ensemble de données CodeContests, mais 66 % d'entre eux ont été résolus dès la première soumission. (Le nombre total de soumissions est limité à 10 fois)
En comparaison, le taux de solution du modèle Transformer traditionnel est relativement faible, à seulement un chiffre.
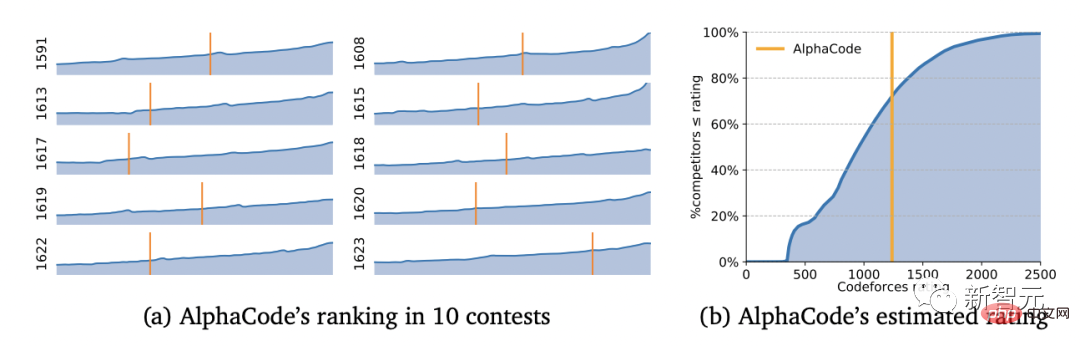
Même le fondateur de Codeforces, Mirzayanov, a été très surpris par ce résultat.
Après tout, les concours de programmation testent la capacité à inventer des algorithmes, ce qui a toujours été la faiblesse de l'IA et la force des humains.
Je peux certainement dire que les résultats d'AlphaCode ont dépassé mes attentes. J'étais sceptique au début car même dans des problèmes de concurrence simples, il faut non seulement implémenter l'algorithme mais aussi l'inventer (ce qui est la partie la plus difficile). AlphaCode est devenu un redoutable rival pour de nombreux humains. J'ai hâte de voir ce que l'avenir nous réserve !
——Mike Mirzayanov, fondateur de Codeforces
AlphaCode peut-il voler les emplois des programmeurs ?
Bien sûr, pas encore.
AlphaCode ne peut effectuer que des tâches de programmation simples. Si les tâches deviennent plus complexes et les problèmes deviennent plus "imprévisibles", AlphaCode, qui ne traduit que les instructions en codes, sera impuissant.
Après tout, d'un certain point de vue, un score de 1238 équivaut au niveau d'un collégien qui apprend tout juste à programmer. À ce niveau, cela ne constitue pas une menace pour les vrais experts en programmation.
Mais il ne fait aucun doute que le développement de ce type de plateforme de codage aura un impact énorme sur la productivité des programmeurs.
Même la culture de la programmation dans son ensemble pourrait être modifiée : peut-être qu'à l'avenir, les humains ne seront responsables que de la formulation des problèmes, et les tâches de génération et d'exécution du code pourront être confiées à l'apprentissage automatique.
Nous savons que même si l'apprentissage automatique a fait de grands progrès dans la génération et la compréhension de texte, la plupart des IA se limitent encore à de simples problèmes de mathématiques et de programmation.
Ce qu'ils feront, c'est récupérer et copier les solutions existantes (je pense que tous ceux qui ont joué à ChatGPT récemment le comprendront bien).
Alors, pourquoi est-il si difficile pour l'IA d'apprendre à générer des programmes corrects ?
1. Pour générer du code qui résout une tâche spécifiée, vous devez rechercher dans toutes les séquences de caractères possibles. Il s'agit d'un espace énorme, et seule une petite partie correspond à un programme correct et efficace.
2. La modification d'un seul personnage peut complètement changer le comportement du programme ou même provoquer son crash, et chaque tâche a de nombreuses solutions distinctes et valables.
Pour les compétitions de programmation extrêmement difficiles, l'IA doit comprendre des descriptions complexes en langage naturel ; elle doit raisonner sur des problèmes qu'elle n'a jamais vus auparavant, plutôt que de simplement mémoriser des extraits de code ; elle doit maîtriser divers algorithmes et structures de données, et avec précision ; code complet pouvant contenir des centaines de lignes.
De plus, afin d'évaluer le code qu'elle génère, l'IA doit également effectuer des tâches sur un ensemble exhaustif de tests cachés et vérifier la vitesse d'exécution et l'exactitude des cas extrêmes.

(A) Problème 1553D, le score de difficulté moyen est de 1500 ; (B) Solution du problème générée par AlphaCode
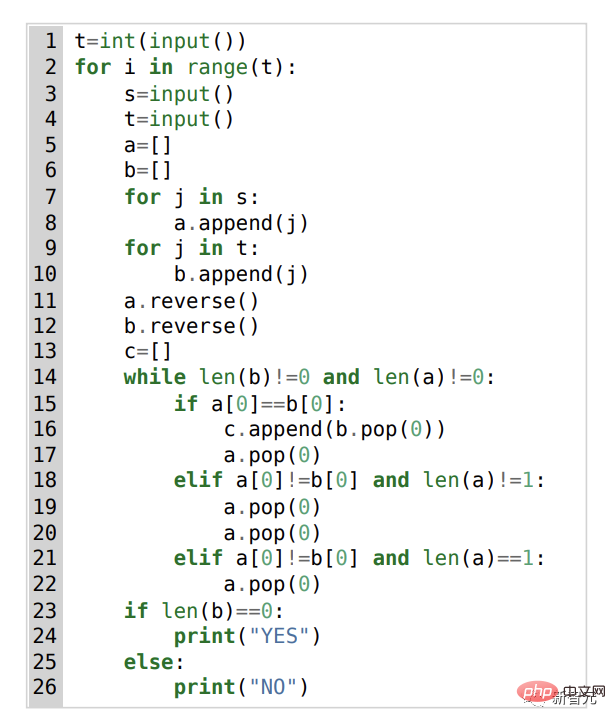
Prenez ce problème 1553D comme exemple, les candidats doivent trouver un moyen, convertir une chaîne répétée aléatoirement de lettres s et t dans une autre chaîne des mêmes lettres en utilisant un ensemble limité d'entrées.
Les candidats ne peuvent pas simplement saisir de nouvelles lettres, mais doivent utiliser la commande "retour arrière" pour supprimer plusieurs lettres de la chaîne d'origine. Les questions spécifiques sont les suivantes :

À cet égard, la solution d'AlphaCode est la suivante :
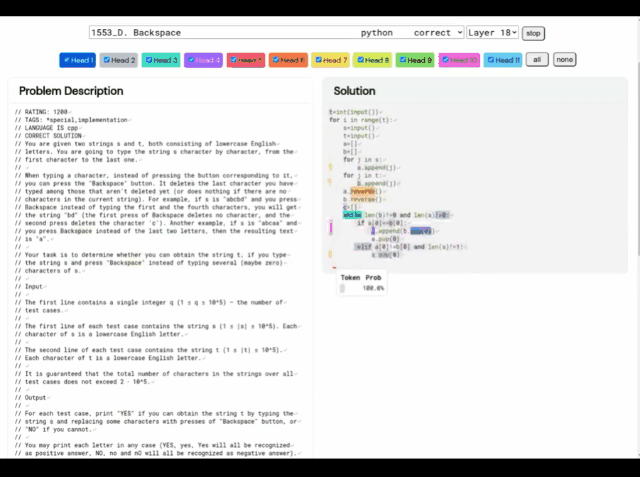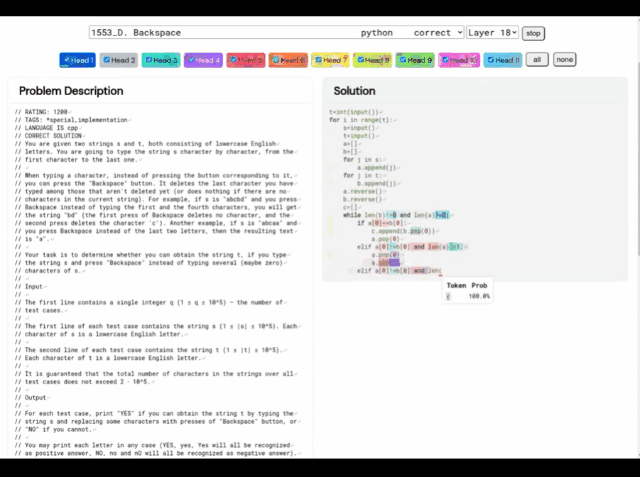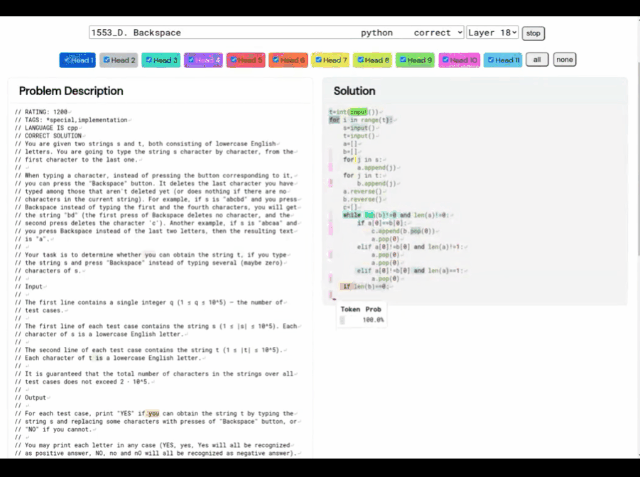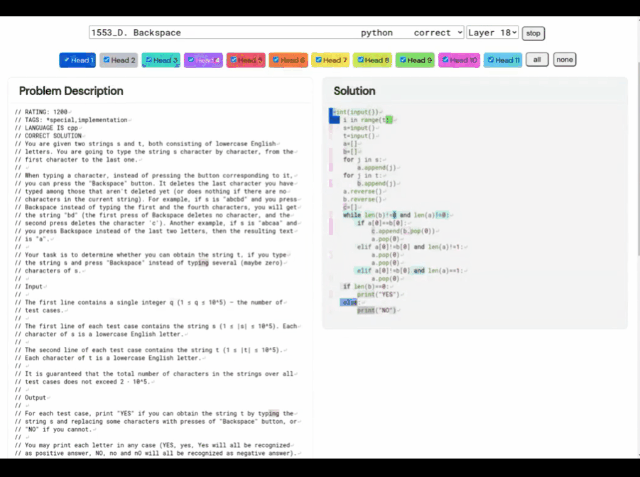
De plus, les « idées de résolution de problèmes » d'AlphaCode ne sont plus une boîte noire, il peut également afficher le code et l'emplacement des points forts de l'attention.
Les principaux défis rencontrés par AlphaCode lors de la participation à des concours de programmation sont :
(i) la nécessité de rechercher dans un immense espace de programme, (ii) seulement environ 13 000 peuvent être obtenu des exemples de tâches pour la formation, et (iii) un nombre limité de soumissions par question.
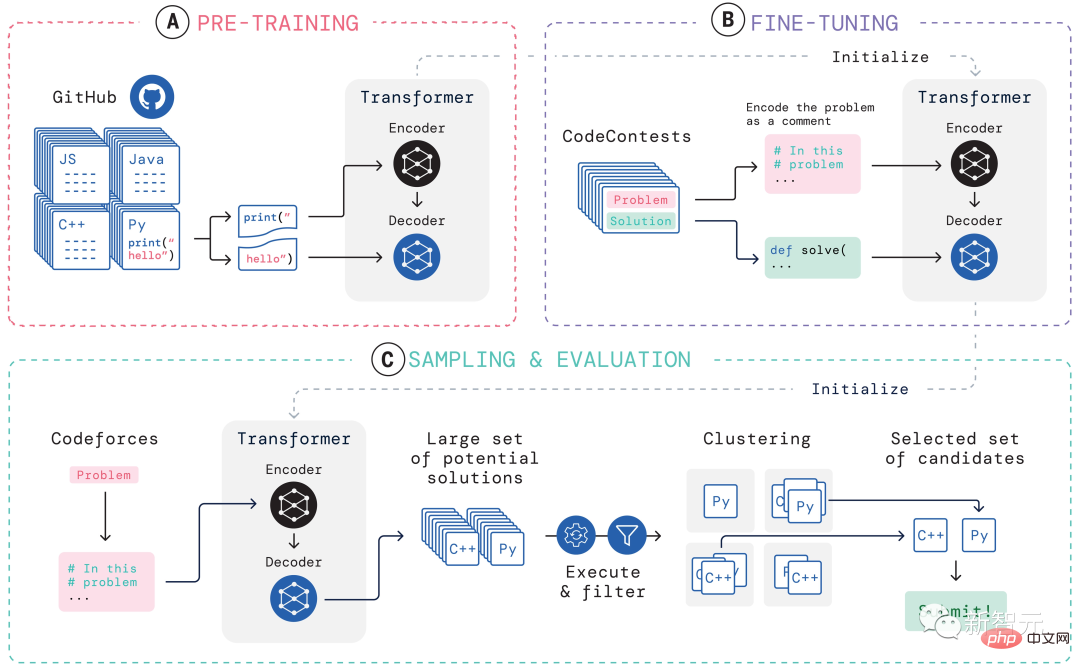
Afin de résoudre ces problèmes, la construction de l'ensemble du système d'apprentissage d'AlphaCode est divisée en trois maillons, pré-formation, mise au point, échantillonnage et évaluation, comme le montre la figure ci-dessus.
Pré-formation
Dans la phase de pré-formation, le modèle est pré-entraîné à l'aide de 715 Go d'instantanés de code de codeurs humains collectés sur GitHub, et le prochain jeton d'entropie croisée est utilisé pour prédire la perte. Au cours du processus de pré-entraînement, le fichier de code est divisé de manière aléatoire en deux parties, la première partie est utilisée comme entrée de l'encodeur et le modèle est entraîné pour générer la deuxième partie sans l'encodeur.
Cette pré-formation apprend un préalable solide pour l'encodage, permettant d'effectuer des ajustements ultérieurs spécifiques à des tâches sur un ensemble de données plus petit.
Réglage fin
Dans la phase de réglage fin, le modèle a été affiné et évalué sur un ensemble de données de problèmes de programmation compétitif de 2,6 Go créé par DeepMind et rendu public sous le nom de CodeContests.
L'ensemble de données CodeContests comprend des questions et des cas de test. L'ensemble de formation contient 13 328 questions, avec une moyenne de 922,4 réponses soumises par question. L'ensemble de validation et l'ensemble de test contiennent respectivement 117 et 165 questions.
Pendant le réglage fin, encodez l'énoncé du problème en langage naturel dans les annotations du programme afin qu'il ressemble davantage aux fichiers vus lors de la pré-formation (qui peuvent inclure des annotations étendues en langage naturel) et utilisez la même prédiction du prochain jeton. perte.
Sampling
Afin de sélectionner les 10 meilleurs échantillons à soumettre, des méthodes de filtrage et de clustering sont utilisées pour exécuter les échantillons à l'aide des exemples de tests inclus dans l'énoncé du problème et supprimer ceux qui échouent à ces échantillons de tests.
Filtrez près de 99 % des échantillons du modèle, regroupez les échantillons candidats restants, exécutez ces échantillons sur l'entrée générée par un modèle de transformateur distinct et produisez la même sortie sur les programmes d'entrée générés sont regroupés dans une seule catégorie.
Ensuite, sélectionnez un échantillon de chacun des 10 plus grands clusters à soumettre. Intuitivement, les programmes corrects se comportent de manière identique et forment de grands clusters, tandis que les programmes incorrects échouent de diverses manières.
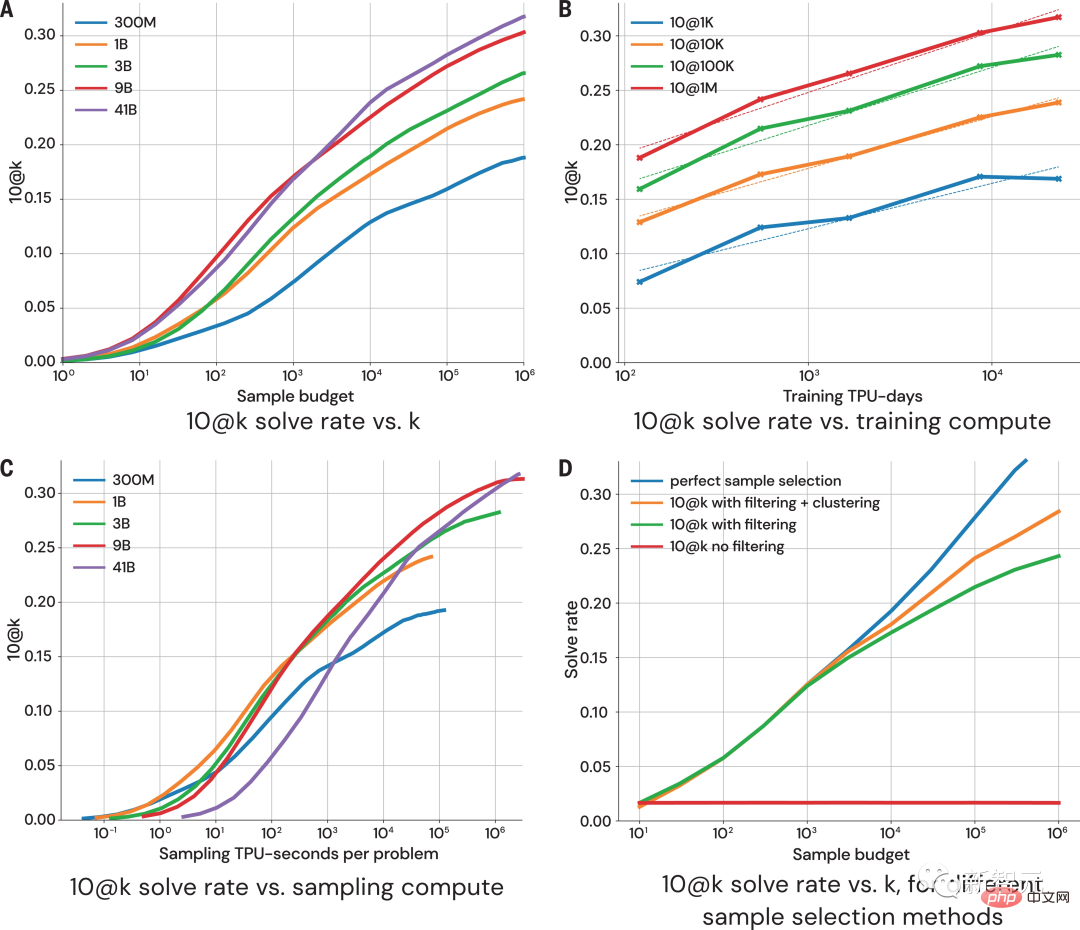
Évaluation
La figure ci-dessus montre comment les performances du modèle changent avec une taille d'échantillon et un montant de calcul plus élevés sur les indicateurs 10@k. À partir de l'évaluation des performances des résultats d'échantillonnage, les chercheurs sont arrivés aux quatre conclusions suivantes :
1. Le taux de solution augmente de manière logarithmique avec une taille d'échantillon plus grande.
2. courbe d'échelle ;
3. Le taux de solution est logarithmiquement proportionnel à plus de calculs ;
4.
Purement "data-driven"
Il ne fait aucun doute que l'introduction d'AlphaCode représente un pas en avant dans le développement de modèles d'apprentissage automatique Une étape substantielle.
Fait intéressant, AlphaCode ne contient pas de connaissances intégrées explicites sur la structure du code informatique.
Au lieu de cela, il s'appuie sur une approche d'écriture de code purement « basée sur les données », qui consiste à apprendre la structure des programmes informatiques en observant simplement de grandes quantités de code existant. .

Adresse de l'article : https://www.science.org/doi/10.1126/science .add8258
Fondamentalement, ce qui rend AlphaCode meilleur que les autres systèmes sur les tâches de programmation compétitives se résume à deux attributs principaux : #🎜 🎜#
1. Données de formation
2. Post-traitement des solutions candidates
#🎜 🎜#Mais le code informatique est un support hautement structuré, et les programmes doivent adhérer à une syntaxe définie et doivent produire des pré- et post-conditions claires dans différentes parties de la solution.La méthode utilisée par AlphaCode lors de la génération du code est exactement la même que lors de la génération d'un autre contenu textuel - un jeton à la fois, et elle n'est vérifiée qu'après l'intégralité du programme est écrit.
Compte tenu des données appropriées et de la complexité du modèle, AlphaCode peut générer des structures cohérentes. Cependant, la recette finale de cette procédure de génération séquentielle est profondément enfouie dans les paramètres du LLM et est insaisissable.
Cependant, peu importe si AlphaCode peut vraiment « comprendre » les problèmes de programmation, il atteint le niveau humain moyen dans les compétitions de codage.
"Résoudre les problèmes de compétition de programmation est une chose très difficile et nécessite que les humains aient de bonnes compétences en codage et une créativité en matière de résolution de problèmes. AlphaCode puis-je être impressionné par les progrès réalisés dans ce domaine, et je suis impatient de voir comment le modèle utilise sa compréhension des instructions pour générer du code et guider son exploration aléatoire pour créer des solutions. 🎜# - Petr Mitrichev, ingénieur logiciel Google et programmeur compétitif de classe mondialeCes modèles exploitent avec élégance l'apprentissage automatique moderne pour exprimer des solutions aux problèmes sous forme de code, remontant aux racines du raisonnement symbolique de l'IA il y a plusieurs décennies.
AlphaCode a été nommé dans le concours de programmation Classé dans le top 54 %, démontrant le potentiel des modèles d’apprentissage profond dans les tâches qui nécessitent une pensée critique.
Et ce n'est que le début.
Dans le futur, une IA plus puissante naîtra pour résoudre les problèmes. Peut-être que ce jour n'est pas loin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que comprend le stockage par cryptage des données ?
Que comprend le stockage par cryptage des données ?
 Le rôle de l'attribut caption
Le rôle de l'attribut caption
 Historique des opérations de la table de vue Oracle
Historique des opérations de la table de vue Oracle
 Tutoriel de modification du logiciel C++ en chinois
Tutoriel de modification du logiciel C++ en chinois
 Qu'est-ce que le logiciel système
Qu'est-ce que le logiciel système
 Utilisation de caractères arbitraires dans les expressions régulières
Utilisation de caractères arbitraires dans les expressions régulières
 Quel navigateur est Edge ?
Quel navigateur est Edge ?
 Comment utiliser fusioncharts.js
Comment utiliser fusioncharts.js








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



