Récemment, j'ai participé à plusieurs activités académiques de haute intensité, notamment des séminaires fermés du Comité de vision par ordinateur du CCF et la conférence hors ligne VALSE. Après avoir communiqué avec d'autres chercheurs, j'ai eu de nombreuses idées et j'espère les trier pour référence par moi-même et mes collègues. Bien sûr, limité par le niveau personnel et la portée de la recherche, il y aura certainement de nombreuses inexactitudes, voire des erreurs, dans l'article. Bien entendu, il est impossible de couvrir toutes les directions de recherche importantes. J'ai hâte de communiquer avec des universitaires intéressés pour étoffer ces perspectives et mieux explorer les orientations futures.
Dans cet article, je me concentrerai sur l'analyse des difficultés et des orientations de recherche potentielles dans le domaine de la vision par ordinateur, notamment dans le sens de la perception visuelle (c'est-à-dire la reconnaissance). Plutôt que d'améliorer les détails d'algorithmes spécifiques, je préfère explorer les limites et les goulots d'étranglement des algorithmes actuels (en particulier le paradigme de pré-formation + réglage fin basé sur l'apprentissage en profondeur) et en tirer des conclusions préliminaires en matière de développement, y compris les problèmes importants. , quelles questions sont sans importance, quelles directions méritent d'être avancées, quelles directions sont moins rentables, etc.
Avant de commencer, je dessine d'abord la carte mentale suivante. Afin de trouver un point d'entrée approprié, je commencerai par la différence entre la vision par ordinateur et le traitement du langage naturel (les deux domaines de recherche les plus populaires en intelligence artificielle), et j'introduirai trois propriétés fondamentales des signaux d'image : la rareté de l'information, la diversité inter-domaines. , une granularité infinie, et les font correspondre à plusieurs axes de recherche importants. De cette façon, nous pouvons mieux comprendre l'état de chaque direction de recherche : quels problèmes elle a résolus et quels problèmes importants n'ont pas été résolus, puis analyser de manière ciblée les tendances de développement futures.
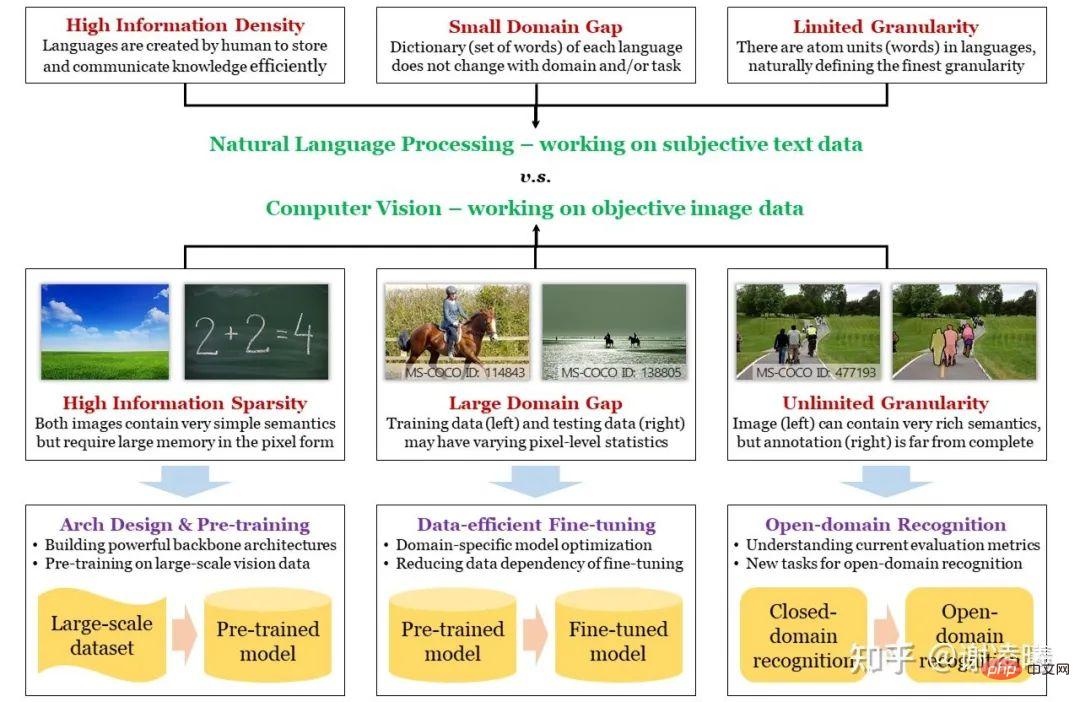
Photo : La différence entre CV et PNL, les trois défis majeurs du CV et comment les relever
Les trois difficultés fondamentales du CV et les orientations de recherche correspondantes
PNL est toujours placé devant le CV. Que les réseaux neuronaux profonds dépassent les méthodes manuelles ou que les grands modèles pré-entraînés commencent à montrer une tendance à l'unification, ces choses se sont produites pour la première fois dans le domaine de la PNL et ont rapidement été déplacées vers le domaine du CV. La raison essentielle ici est que la PNL a un point de départ plus élevé : l’unité de base du langage naturel est constituée de mots, tandis que l’unité de base des images est constituée de pixels ; la première possède des informations sémantiques naturelles, tandis que la seconde peut ne pas être capable d’exprimer la sémantique. Fondamentalement, le langage naturel est un support créé par les humains pour stocker des connaissances et communiquer des informations, il doit donc avoir les caractéristiques d'une efficacité élevée et d'une densité d'informations élevée ; tandis que les images sont des signaux optiques capturés par les humains à travers divers capteurs, qui peuvent objectivement refléter le bien la situation réelle, mais par conséquent elle n’a pas une sémantique forte et la densité de l’information peut être très faible. D'un autre point de vue, l'espace image est beaucoup plus grand que l'espace texte, et la structure de l'espace est également beaucoup plus complexe. Cela signifie que si vous souhaitez échantillonner un grand nombre d'échantillons dans l'espace et utiliser ces données pour caractériser la distribution de l'espace entier, les données d'image échantillonnées seront plusieurs ordres de grandeur plus grandes que les données de texte échantillonnées. D'ailleurs, c'est aussi la raison essentielle pour laquelle les modèles de pré-entraînement en langage naturel sont meilleurs que les modèles de pré-entraînement visuels - nous le mentionnerons plus tard.
Sur la base de l'analyse ci-dessus, nous avons introduit la première difficulté fondamentale du CV à travers la différence entre CV et PNL, qui est la parcimonie sémantique. Les deux autres difficultés, les différences inter-domaines et la granularité infinie, sont en quelque sorte liées aux différences essentielles mentionnées ci-dessus. C'est précisément parce que la sémantique n'est pas prise en compte lors de l'échantillonnage des images que lors de l'échantillonnage de différents domaines (c'est-à-dire différentes distributions, comme le jour et la nuit, les jours ensoleillés et pluvieux, etc.), les résultats de l'échantillonnage (c'est-à-dire les pixels de l'image) sont fortement liés à caractéristiques du domaine, ce qui entraîne des différences de domaine entre. Dans le même temps, parce que l'unité sémantique de base d'une image est difficile à définir (alors que le texte est facile à définir) et que les informations exprimées par l'image sont riches et diverses, les humains peuvent obtenir des informations sémantiques presque infinies à partir de l'image, bien au-delà de tout champ CV actuel. La capacité définie par cet indice d'évaluation est une granularité infinie. Concernant la granularité infinie, j'ai écrit un jour un article traitant spécifiquement de cette question. https://zhuanlan.zhihu.com/p/376145664
En prenant comme guide les trois difficultés fondamentales ci-dessus, nous résumons les orientations de recherche de l'industrie ces dernières années comme suit :
-
Préparité sémantique : La solution est de construire des modèles informatiques efficaces (réseaux de neurones) et une pré-formation visuelle. La logique principale ici est que si vous souhaitez augmenter la densité d'informations des données, vous devez supposer et modéliser la distribution non uniforme des données (théorie de l'information) (c'est-à-dire apprendre la distribution préalable des données). Actuellement, il existe deux types de méthodes de modélisation les plus efficaces. L'une consiste à utiliser la conception d'une architecture de réseau neuronal pour capturer des distributions a priori indépendantes des données (par exemple, le module de convolution correspond à la distribution a priori locale des données d'image et le module de transformation correspond à les données d'image. attention préalable) ; l'une consiste à capturer la distribution préalable liée aux données grâce à un pré-entraînement sur des données à grande échelle. Ces deux axes de recherche sont aussi les plus fondamentaux et les plus concernés dans le domaine de la reconnaissance visuelle.
-
Variabilité inter-domaines : La solution est un algorithme de réglage fin efficace en matière de données. Selon l'analyse ci-dessus, plus la taille du réseau est grande et plus l'ensemble de données de pré-entraînement est grand, plus le prior stocké dans le modèle de calcul est fort. Cependant, lorsqu'il existe une grande différence dans la distribution des données entre le domaine de pré-formation et le domaine cible, cet a priori fort entraînera des inconvénients, car la théorie de l'information nous le dit : augmenter la densité d'information de certaines parties (domaine de pré-formation) Réduire définitivement la densité d'information des autres parties (parties non incluses dans le domaine de pré-formation, c'est-à-dire parties considérées comme sans importance lors du processus de pré-formation). En réalité, il est probable qu'une partie ou la totalité du domaine cible se situe dans la partie non impliquée, ce qui entraîne un mauvais transfert direct du modèle pré-entraîné (c'est-à-dire un surajustement). A cette époque, il est nécessaire de s'adapter à la nouvelle répartition des données en affinant le domaine cible. Étant donné que le volume de données du domaine cible est souvent bien inférieur à celui du domaine de pré-formation, l'efficacité des données est une hypothèse essentielle. En outre, d’un point de vue pratique, les modèles doivent être capables de s’adapter à des domaines changeants, c’est pourquoi l’apprentissage tout au long de la vie est indispensable.
-
Granularité infinie : La solution est un algorithme de reconnaissance de domaine ouvert. La granularité infinie inclut des fonctionnalités de domaine ouvert et constitue un objectif de recherche plus élevé. Les recherches dans cette direction sont encore préliminaires, d'autant plus qu'il n'existe pas d'ensembles de données de reconnaissance de domaine ouvert ni d'indicateurs d'évaluation généralement acceptés dans l'industrie. L’une des questions les plus essentielles ici est de savoir comment introduire des capacités de domaine ouvert dans la reconnaissance visuelle. La bonne nouvelle est qu'avec l'émergence de méthodes de pré-formation multimodales (notamment CLIP en 2021), le langage naturel se rapproche de plus en plus du moteur de la reconnaissance de domaine ouvert. Je pense que ce sera la direction dominante dans le prochain. 2-3 ans. Cependant, je ne suis pas d'accord avec les diverses tâches de reconnaissance sans tir qui ont émergé dans la poursuite de la reconnaissance de domaine ouvert. Je pense que le tir zéro en lui-même est une fausse proposition. Il n’existe pas de méthode d’identification du tir zéro dans le monde et elle n’est pas nécessaire. Les tâches Zero-shot existantes utilisent toutes des méthodes différentes pour divulguer des informations à l'algorithme, et les méthodes de fuite varient considérablement, ce qui rend difficile une comparaison équitable entre les différentes méthodes. Dans cette direction, je propose une méthode appelée reconnaissance visuelle à la demande pour révéler et explorer davantage la granularité infinie de la reconnaissance visuelle.
Une explication supplémentaire est nécessaire ici. En raison des différences dans la taille de l'espace de données et la complexité structurelle, du moins jusqu'à présent, le domaine CV ne peut pas résoudre directement le problème des différences inter-domaines via des modèles pré-entraînés, mais le domaine PNL est proche de ce point. Par conséquent, nous avons vu des spécialistes de la PNL utiliser des méthodes basées sur des invites pour unifier des dizaines ou des centaines de tâches en aval, mais la même chose ne s'est pas produite dans le domaine du CV. De plus, l'essence de la loi d'échelle proposée en PNL est d'utiliser un modèle plus grand pour surajuster l'ensemble de données de pré-entraînement. En d'autres termes, pour la PNL, le surajustement n'est plus un problème, car l'ensemble de données de pré-entraînement avec de petites invites est suffisant pour représenter la distribution de l'ensemble de l'espace sémantique. Cependant, cela n'a pas été réalisé dans le domaine du CV, la migration de domaine doit donc également être prise en compte, et l'essentiel de la migration de domaine est d'éviter le surajustement. En d’autres termes, au cours des deux ou trois prochaines années, les axes de recherche de la CV et de la PNL seront très différents. Il est donc très dangereux de copier le mode de pensée d’une direction dans l’autre.
Ce qui suit est une brève analyse de chaque direction de recherche
Direction 1a : Conception d'architecture de réseau neuronal
AlexNet en 2012 a jeté les bases des réseaux neuronaux profonds dans le domaine du CV . Au cours des 10 années suivantes (à ce jour), la conception de l'architecture des réseaux neuronaux est passée par un processus allant de la conception manuelle à la conception automatique, puis de retour à la conception manuelle (introduisant des modules informatiques plus complexes) :
- 2012-2017, construction manuelle de réseaux neuronaux convolutifs plus profonds et exploration des techniques d'optimisation générales. Mots-clés : ReLU, Dropout, convolution 3x3, BN, saut de connexion, etc. À ce stade, l’opération de convolution est l’unité la plus basique, qui correspond à la localité avant les caractéristiques de l’image.
- 2017-2020, construisez automatiquement des réseaux de neurones plus complexes. Parmi eux, Network Architecture Search (NAS) a été populaire pendant un certain temps et s'est finalement imposé comme outil de base. Dans n’importe quel espace de recherche donné, la conception automatique peut obtenir des résultats légèrement meilleurs et s’adapter rapidement à différents coûts de calcul.
- Depuis 2020, le module transformateur issu de la PNL a été introduit dans CV, utilisant le mécanisme d'attention pour compléter les capacités de modélisation longue distance des réseaux de neurones. Aujourd'hui, des résultats optimaux pour la plupart des tâches visuelles sont obtenus à l'aide d'architectures incluant des transformateurs.
Pour l'avenir de cette direction, mon jugement est le suivant :
- Si la tâche de reconnaissance visuelle ne change pas de manière significative, alors ni la conception automatique ni l'ajout de modules informatiques plus complexes ne le feront être capable de propulser le CV vers de nouveaux sommets. Les changements possibles dans les tâches de reconnaissance visuelle peuvent être grossièrement divisés en deux parties : l'entrée et la sortie. Les changements possibles dans la partie d'entrée, comme la caméra événementielle, peuvent modifier le statu quo du traitement régulier des signaux visuels statiques ou séquentiels et donner lieu à des structures de réseau neuronal spécifiques. Les changements possibles dans la partie de sortie sont une sorte de cadre (direction) qui ; unifie diverses tâches de reconnaissance. 3 sera discuté), il a le potentiel de déplacer la reconnaissance visuelle de tâches indépendantes vers une tâche unifiée, donnant ainsi naissance à une architecture de réseau plus adaptée aux invites visuelles.
- Si vous devez choisir entre la convolution et le transformateur, alors le transformateur a un plus grand potentiel, principalement parce qu'il peut unifier différentes modalités de données, en particulier le texte et l'image, les deux modalités les plus courantes et les plus importantes.
- L'interprétabilité est une direction de recherche très importante, mais je suis personnellement pessimiste quant à l'interprétabilité des réseaux de neurones profonds. Le succès de la PNL ne repose pas sur l’interprétabilité, mais sur le surajustement de corpus à grande échelle. Ce n’est peut-être pas un bon signe pour une véritable IA.
Direction 1b : Pré-formation visuelle
En tant que direction en vogue dans le domaine du CV aujourd'hui, les méthodes de pré-formation ont de grands espoirs. À l'ère du deep learning, la pré-formation visuelle peut être divisée en trois catégories : supervisée, non supervisée et cross-modale. La description générale est la suivante :
- Le développement de la pré-formation supervisée est relativement. clair. Étant donné que les données de classification au niveau de l'image sont les plus faciles à obtenir, bien avant l'apparition de l'apprentissage profond, il existait l'ensemble de données ImageNet qui poserait les bases de l'apprentissage profond à l'avenir, et il est toujours utilisé aujourd'hui. L'ensemble total de données ImageNet dépasse les 15 millions et n'a pas été dépassé par d'autres ensembles de données non classifiés. Il s'agit donc toujours des données les plus couramment utilisées dans la pré-formation supervisée. Une autre raison est que les données de classification au niveau de l'image introduisent moins de biais, ce qui est plus bénéfique pour la migration en aval : la pré-formation non supervisée réduit encore davantage les biais.
- La pré-formation non supervisée a connu un processus de développement tortueux. À partir de 2014, la première génération de méthodes de pré-entraînement non supervisées basées sur la géométrie est apparue, comme le jugement basé sur les relations de position des patchs, la rotation des images, etc., et les méthodes génératives sont également en constante évolution (les méthodes génératives remontent à des périodes antérieures). , qui ne sera pas décrit ici). À l’heure actuelle, la méthode de pré-formation non supervisée est encore nettement plus faible que la méthode de pré-formation supervisée. En 2019, après des améliorations techniques, la méthode d'apprentissage contrastif a montré pour la première fois le potentiel de surpasser la méthode de pré-formation supervisée dans les tâches en aval. L'apprentissage non supervisé est véritablement devenu le centre d'intérêt du monde du CV. À partir de 2021, l’essor des transformateurs visuels a donné naissance à un type particulier de tâche générative, le MIM, qui est progressivement devenu la méthode dominante.
- En plus de la pré-formation purement supervisée et non supervisée, il existe également un type de méthode intermédiaire, qui est la pré-formation crossmodale. Il utilise des images et des textes faiblement appariés comme matériel de formation, d'une part, il évite les biais causés par les signaux de supervision d'images, et d'autre part, il peut mieux apprendre la sémantique faible que les méthodes non supervisées. De plus, avec l'aide du transformateur, l'intégration du langage visuel et naturel est plus naturelle et raisonnable.
Sur la base de l'avis ci-dessus, je porte le jugement suivant :
- D'un point de vue pratique, différentes tâches de pré-formation doivent être combinées. Autrement dit, un ensemble de données mixtes doit être collecté, contenant une petite quantité de données étiquetées (des étiquettes encore plus fortes telles que la détection et la segmentation), une quantité moyenne de données appariées image-texte et une grande quantité de données d'image sans toutes les étiquettes, et dans ces données mixtes Concevoir de manière centralisée des méthodes de pré-formation.
- Dans le domaine du CV, la pré-formation non supervisée est l'orientation de recherche qui reflète le mieux l'essence de la vision. Même si la pré-formation multimodale a eu un grand impact sur l'ensemble de la direction, je pense toujours que la pré-formation non supervisée est très importante et doit être maintenue. Il convient de souligner que l'idée de pré-formation visuelle est largement influencée par la pré-formation en langage naturel, mais la nature des deux est différente, elles ne peuvent donc pas être généralisées. En particulier, le langage naturel lui-même est constitué de données créées par des humains, dans lesquelles chaque mot et caractère est écrit par des humains et a naturellement une signification sémantique. Par conséquent, au sens strict, les tâches de pré-formation en PNL ne peuvent pas être considérées comme de véritables pré-formations non supervisées. au mieux une pré-formation faiblement encadrée. Mais la vision est différente. Les signaux d’image sont des données brutes qui existent objectivement et qui n’ont pas été traitées par des humains. La tâche de pré-entraînement non supervisée doit être plus difficile. En bref, même si la pré-formation multimodale peut faire progresser l’algorithme visuel en ingénierie et obtenir de meilleurs résultats de reconnaissance, le problème essentiel de la vision doit encore être résolu par la vision elle-même.
- Actuellement, l'essence de la pré-formation purement visuelle et non supervisée est d'apprendre de la dégradation. La dégradation fait ici référence à la suppression de certaines informations existantes du signal d'image, nécessitant que l'algorithme restaure ces informations : les méthodes géométriques suppriment les informations de distribution géométrique (telles que la position relative des patchs), les méthodes de contraste suppriment l'image globale (en extrayant différentes vues) ; ); la méthode de génération telle que MIM supprime les informations locales de l'image. Cette méthode basée sur la dégradation présente un goulot d'étranglement insurmontable, à savoir le conflit entre l'intensité de la dégradation et la cohérence sémantique. Puisqu'il n'y a pas de signal supervisé, l'apprentissage de la représentation visuelle repose entièrement sur la dégradation, donc la dégradation doit être suffisamment forte ; lorsque la dégradation est suffisamment forte, il n'y a aucune garantie que les images avant et après dégradation soient sémantiquement cohérentes, ce qui conduit à un mauvais conditionnement ; objectifs de pré-formation. Par exemple, si deux vues extraites d'une image en apprentissage comparatif n'ont aucune relation, il n'est pas raisonnable de rapprocher leurs caractéristiques ; si la tâche MIM supprime des informations clés (telles que les visages) de l'image, il n'est pas raisonnable de reconstruire ces informations ; . Raisonnable. L’accomplissement forcé de ces tâches introduira un certain biais et affaiblira la capacité de généralisation du modèle. À l'avenir, il devrait y avoir une tâche d'apprentissage qui ne nécessite pas de dégradation, et je crois personnellement que l'apprentissage par compression est une voie réalisable.
Direction 2 : Ajustement du modèle et apprentissage tout au long de la vie
En tant que problème fondamental, l'ajustement du modèle a développé un grand nombre de paramètres différents. Si vous souhaitez unifier différents paramètres, vous pouvez les considérer comme considérant trois ensembles de données, à savoir l'ensemble de données de pré-entraînement Dpre (invisible), l'ensemble d'entraînement cible Dtrain et l'ensemble de test cible Dtest (invisible et imprévisible). En fonction des hypothèses sur la relation entre les trois, les paramètres les plus populaires peuvent être résumés comme suit :
- Apprentissage par transfert : supposons que la distribution des données de Dpre ou Dtrain et Dtest sont très différentes ;
- Apprentissage faiblement supervisé : supposons que Dtrain ne fournit que des informations d'annotation incomplètes ; apprentissage : Supposons que seule une partie des données de Dtrain soit étiquetée ; être étiqueté de manière interactive (en choisissant les échantillons les plus difficiles) pour améliorer l'efficacité de l'étiquetage
- Apprentissage continu : supposez que de nouveaux Dtrains continuent d'apparaître, de sorte que le contenu appris de Dpre peut être oublié pendant le processus d'apprentissage ;
- ...
- D'une manière générale, il est difficile de trouver un cadre unifié pour analyser le développement et le genre des méthodes de réglage fin des modèles. D’un point de vue technique et pratique, la clé du réglage fin du modèle réside dans le jugement préalable de l’ampleur des différences entre les domaines. Si vous pensez que la différence entre Dpre et Dtrain peut être très importante, vous devez réduire la proportion de poids transférés du réseau pré-entraîné vers le réseau cible, ou ajouter une tête spéciale pour vous adapter à cette différence ; la différence entre Dtrain et Dtest peut être très grande, il est nécessaire d'ajouter une régularisation plus forte pendant le processus de réglage fin pour éviter le surajustement, ou d'introduire des statistiques en ligne pendant le processus de test pour compenser autant que possible les différences. Quant aux différents contextes évoqués ci-dessus, il existe sur chacun d’eux de nombreux travaux de recherche, très ciblés et qui ne seront pas détaillés ici.
- Concernant cette orientation, je pense qu'il y a deux enjeux importants :
- L'unification du milieu isolé à l'apprentissage tout au long de la vie. Du monde universitaire à l'industrie, nous devons abandonner la réflexion sur le « modèle de livraison unique » et comprendre le contenu de la livraison comme une chaîne d'outils centrée sur le modèle et dotée de multiples fonctions telles que la gouvernance des données, la maintenance des modèles et le déploiement du modèle. En termes industriels, un modèle ou un ensemble de systèmes doit être entièrement pris en charge pendant tout le cycle de vie du projet. Il faut tenir compte du fait que les besoins des utilisateurs sont changeants et imprévisibles. Aujourd'hui, la caméra peut être modifiée, demain de nouveaux types de cibles peuvent être détectés, etc. Nous ne recherchons pas l'IA pour résoudre tous les problèmes de manière autonome, mais les algorithmes d'IA devraient avoir un processus de fonctionnement standardisé afin que les personnes qui ne comprennent pas l'IA puissent suivre ce processus, ajouter les besoins qu'elles souhaitent et résoudre les problèmes qu'elles rencontrent habituellement. Comment l'IA peut-elle vraiment la rendre accessible aux masses et résoudre des problèmes pratiques. Pour le monde universitaire, il est nécessaire de définir le plus rapidement possible un cadre d’apprentissage tout au long de la vie conforme à des scénarios réels, d’établir des références correspondantes et de promouvoir la recherche dans cette direction.
Résoudre les conflits entre le big data et les petits échantillons lorsqu'il existe des différences évidentes entre les domaines. C'est une autre différence entre le CV et la PNL : la PNL n'a fondamentalement pas besoin de prendre en compte les différences inter-domaines entre les tâches de pré-formation et en aval, car la structure grammaticale est exactement la même que celle des mots courants, tandis que le CV doit supposer que les tâches en amont et en aval ; les distributions de données sont très différentes, de sorte que lorsque le modèle n'est pas affiné en amont, les caractéristiques sous-jacentes ne peuvent pas être extraites des données en aval (elles sont directement filtrées par des unités telles que ReLU). Par conséquent, utiliser de petites données pour affiner un grand modèle n'est pas un gros problème dans le domaine de la PNL (la tendance actuelle consiste uniquement à affiner les invites), mais c'est un gros problème dans le domaine du CV. Ici, la conception d’invites visuellement conviviales peut être une bonne direction, mais les recherches actuelles n’ont pas encore atteint le problème principal.
Direction 3 : Tâche de reconnaissance visuelle infiniment fine
- Il n'y a pas beaucoup de recherches pertinentes sur la reconnaissance visuelle infiniment fine (et les concepts similaires). Par conséquent, je vais décrire ce problème à ma manière. Dans le rapport VALSE de cette année, j'ai donné une explication détaillée des méthodes existantes et de notre proposition. Je vais donner une description textuelle ci-dessous. Pour une explication plus détaillée, veuillez vous référer à mon article spécial ou au rapport que j'ai fait sur VALSE :
https://zhuanlan.zhihu.com/p/546510418https://zhuanlan. zhihu.com/p/555377882Tout d'abord, je veux expliquer la signification de la reconnaissance visuelle infiniment fine. En termes simples, les images contiennent des informations sémantiques très riches mais n’ont pas d’unités sémantiques de base claires. Tant que les humains le souhaitent, ils peuvent identifier des informations sémantiques de plus en plus fines à partir d'une image (comme le montre la figure ci-dessous), mais ces informations sont difficiles à transmettre à travers des annotations limitées et standardisées (même si des coûts d'annotation suffisants sont dépensés) ; Formez un ensemble de données sémantiquement complet pour l’apprentissage des algorithmes.

Même les ensembles de données finement annotés tels que ADE20K manquent d'une grande quantité de contenu sémantique que les humains peuvent reconnaître
Nous pensons que la reconnaissance visuelle infiniment fine est plus efficace que la reconnaissance visuelle en domaine ouvert reconnaissance. Objectif difficile et plus essentiel. Nous examinons les méthodes de reconnaissance existantes, les divisons en deux catégories, à savoir les méthodes basées sur la classification et les méthodes basées sur le langage, et discutons des raisons pour lesquelles elles ne peuvent pas atteindre une granularité infinie.
- Méthodes basées sur la classification : Cela inclut la classification, la détection, la segmentation et d'autres méthodes au sens traditionnel. Sa fonctionnalité de base est d'attribuer chaque unité sémantique de base dans l'image (image, boîte, masque, point clé, etc. .) Une étiquette de catégorie. Le défaut fatal de cette méthode est que lorsque la granularité de la reconnaissance augmente, la certitude de la reconnaissance diminue inévitablement, c'est-à-dire que la granularité et la certitude sont en conflit. Par exemple, dans ImageNet, il existe deux grandes catégories : « meubles » et « appareils électriques » ; évidemment « chaise » appartient aux « meubles » et « TV » appartient aux « appareils électroménagers », mais « chaise de massage » appartient-il à « ? meubles » ou « appareils électroménagers » est difficile à juger - il s'agit de la diminution de la certitude provoquée par l'augmentation de la granularité sémantique. S'il y a une « personne » avec une très petite résolution sur la photo, et que la « tête » ou même les « yeux » de cette « personne » sont étiquetés de force, alors les jugements des différents annotateurs peuvent être différents, mais à ce moment-là, même s'il s'agit d'un ou deux pixels, l'écart affectera également grandement des indicateurs tels que l'IoU - il s'agit de la diminution de la certitude causée par l'augmentation de la granularité spatiale.
- Méthodes basées sur le langage : cela inclut la méthode de classe d'invite visuelle pilotée par CLIP, ainsi que le problème de base visuelle de plus longue date, etc. Sa fonctionnalité de base est d'utiliser le langage pour faire référence aux informations sémantiques dans le l’image et l’identifier. L'introduction du langage améliore en effet la flexibilité de la reconnaissance et apporte des propriétés naturelles de domaine ouvert. Cependant, le langage lui-même a des capacités de référence limitées (imaginez faire référence à un individu spécifique dans une scène comptant des centaines de personnes) et ne peut pas répondre aux besoins d’une reconnaissance visuelle infiniment fine. En dernière analyse, dans le domaine de la reconnaissance visuelle, le langage devrait jouer un rôle d'aide à la vision, et les méthodes d'invite visuelle existantes semblent quelque peu écrasantes.
L'enquête ci-dessus nous dit que les méthodes de reconnaissance visuelle actuelles ne peuvent pas atteindre l'objectif d'un grain fin infini et rencontreront des difficultés insurmontables sur le chemin vers un grain fin infini. Nous souhaitons donc analyser comment les gens résolvent ces difficultés. Tout d'abord, dans la plupart des cas, les humains n'ont pas besoin d'effectuer explicitement des tâches de classification : pour revenir à l'exemple ci-dessus, une personne se rend dans un centre commercial pour acheter quelque chose, que le centre commercial place ou non le "fauteuil de massage" dans les "meubles". ou la section « appareils électroménagers ». Les humains peuvent trouver rapidement la zone où se trouve le « fauteuil de massage » grâce à un simple guidage. Deuxièmement, les humains ne se limitent pas à utiliser le langage pour faire référence à des objets dans des images. Ils peuvent utiliser des méthodes plus flexibles (telles que pointer des objets avec leurs mains) pour compléter la référence et effectuer une analyse plus détaillée.
En combinant ces analyses, pour atteindre l'objectif d'une finesse infinie, les trois conditions suivantes doivent être remplies.
- Ouverture : la reconnaissance de domaine ouverte est un sous-objectif de reconnaissance infinie et fine. À l’heure actuelle, l’introduction de la langue constitue l’une des meilleures solutions pour parvenir à l’ouverture.
- Spécificité : lors de l'introduction d'une langue, vous ne devez pas être lié par la langue, mais devez concevoir un schéma de référence visuellement convivial (c'est-à-dire une tâche de reconnaissance).
- Granularité variable : il n'est pas toujours nécessaire de reconnaître la granularité la plus fine, mais la granularité de reconnaissance peut être modifiée de manière flexible en fonction des besoins.
Sous la direction de ces trois conditions, nous avons conçu une tâche de reconnaissance visuelle à la demande. Différente de la reconnaissance visuelle unifiée au sens traditionnel, la reconnaissance visuelle à la demande utilise les requêtes comme unités d'annotation, d'apprentissage et d'évaluation. Actuellement, le système prend en charge deux types de requêtes, qui réalisent une segmentation d'une instance à une sémantique et une segmentation de sémantique à une autre. Par conséquent, la combinaison des deux peut permettre d'obtenir une segmentation d'image avec n'importe quel degré de finesse. Un autre avantage de la reconnaissance visuelle à la demande est que l'arrêt après avoir terminé un certain nombre de requêtes n'affectera pas la précision de l'annotation (même si une grande quantité d'informations n'est pas annotée), ce qui est bénéfique pour l'évolutivité des domaines ouverts (comme l'ajout de nouvelles catégories sémantiques) présentent de grands avantages. Pour plus de détails, veuillez vous référer à l'article sur la reconnaissance visuelle à la demande (voir lien ci-dessus).
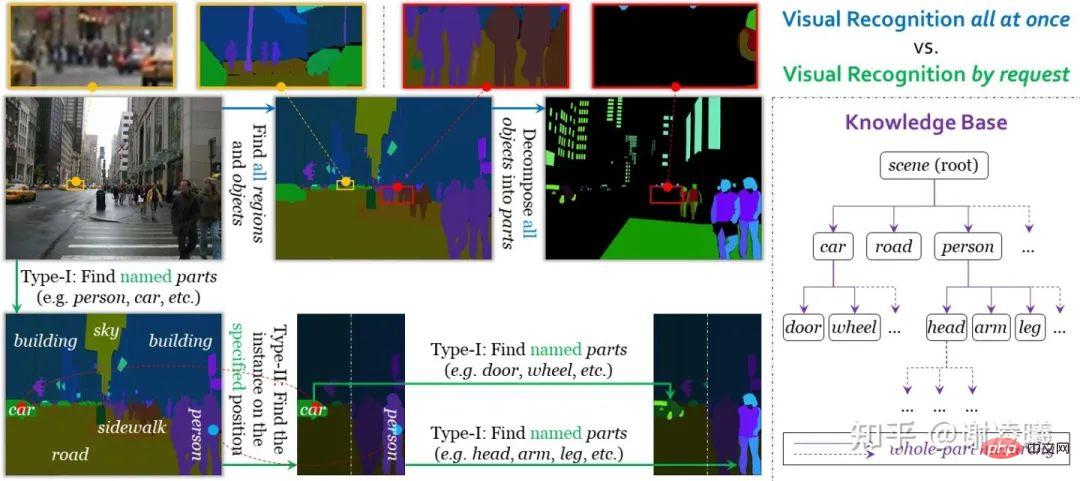
Comparaison entre l'identité visuelle unifiée et l'identité visuelle à la demande
Après avoir terminé cet article, je réfléchis toujours à l'impact de l'identité visuelle à la demande dans d'autres directions. Deux perspectives sont proposées ici :
- La demande de reconnaissance visuelle à la demande est essentiellement une invite visuellement conviviale. Il peut non seulement atteindre l'objectif d'interroger le modèle visuel, mais également éviter l'ambiguïté de référence causée par des invites linguistiques pures. À mesure que de nouveaux types de demandes seront introduits, ce système devrait devenir plus mature.
- La reconnaissance visuelle à la demande offre la possibilité d'unifier formellement diverses tâches visuelles. Par exemple, des tâches telles que la classification, la détection et la segmentation sont unifiées dans ce cadre. Cela peut inspirer la pré-formation visuelle. À l'heure actuelle, la frontière entre la pré-formation visuelle et le réglage fin en aval n'est pas claire. On ne sait toujours pas si le modèle pré-entraîné doit être adapté à différentes tâches ou se concentrer sur l'amélioration de tâches spécifiques. Toutefois, si une tâche de reconnaissance formellement unifiée émerge, ce débat pourrait alors ne plus être pertinent. D’ailleurs, l’unification formelle des tâches en aval constitue également un avantage majeur dont bénéficie le domaine de la PNL.
En dehors des directions ci-dessus
Je divise les problèmes dans le domaine du CV en trois grandes catégories : la reconnaissance, la génération et l'interaction, et la reconnaissance n'est que le problème le plus simple parmi eux. Concernant ces trois sous-domaines, une brève analyse est la suivante :
- Dans le domaine de la reconnaissance, les indicateurs de reconnaissance traditionnels sont évidemment dépassés, les gens ont donc besoin d'indicateurs d'évaluation mis à jour. À l’heure actuelle, l’introduction du langage naturel dans la reconnaissance visuelle est une tendance évidente et irréversible, mais c’est loin d’être suffisant. L’industrie a besoin de davantage d’innovations au niveau des tâches.
- La génération est une capacité plus avancée que la reconnaissance. Les humains peuvent facilement reconnaître une variété d’objets courants, mais peu sont capables de dessiner des objets réalistes. Du langage de l'apprentissage statistique, cela est dû au fait que le modèle génératif doit modéliser la distribution conjointe p(x,y), tandis que le modèle discriminant n'a besoin que de modéliser la distribution conditionnelle p(y|x) : le premier peut dériver la seconde ne peut pas être dérivé de la seconde, mais la première ne peut pas être dérivée de la seconde. À en juger par le développement de l'industrie, même si la qualité de la génération d'images continue de s'améliorer, la stabilité et la contrôlabilité du contenu généré (sans générer de contenu manifestement irréel) doivent encore être améliorées. Dans le même temps, le contenu généré est encore relativement faible pour aider l'algorithme de reconnaissance, et il est difficile pour les gens d'utiliser pleinement les données virtuelles et les données synthétiques pour obtenir des résultats comparables à la formation sur les données réelles. Pour ces deux problématiques, notre point de vue est qu'il faut concevoir des indicateurs d'évaluation meilleurs et plus essentiels pour remplacer les indicateurs existants (en remplacement du FID, du SI, etc. pour les tâches de génération, tandis que les tâches de génération et d'identification doivent être combinées pour définir un indice d'évaluation unifié).
- En 1978, le pionnier de la vision par ordinateur David Marr envisageait que la fonction principale de la vision était de construire un modèle tridimensionnel de l'environnement et d'acquérir des connaissances par l'interaction. Comparée à la reconnaissance et à la génération, l'interaction est plus proche de l'apprentissage humain, mais il existe relativement peu d'études dans l'industrie. La principale difficulté de la recherche sur l'interaction réside dans la construction d'un environnement d'interaction réel - pour être précis, la méthode actuelle de construction d'ensembles de données visuelles provient d'un échantillonnage clairsemé de l'environnement, mais l'interaction nécessite un échantillonnage continu. Évidemment, pour résoudre le problème essentiel de la vision, l’interaction est essentielle. Bien qu'il y ait eu de nombreuses études connexes dans l'industrie (telles que l'intelligence incorporée), aucun objectif d'apprentissage universel et axé sur les tâches n'a encore émergé. Nous répétons une fois de plus l'idée avancée par le pionnier de la vision par ordinateur David Marr : la fonction principale de la vision est de construire un modèle tridimensionnel de l'environnement et d'acquérir des connaissances par interaction. La vision par ordinateur, y compris d’autres domaines de l’IA, devrait évoluer dans cette direction pour devenir véritablement pratique.
En bref, dans différents sous-domaines, les tentatives de s'appuyer uniquement sur l'apprentissage statistique (en particulier l'apprentissage profond) pour obtenir de fortes capacités d'ajustement ont atteint leurs limites. Le développement futur doit être basé sur une compréhension plus essentielle du CV, et l'établissement d'indicateurs d'évaluation plus raisonnables pour diverses tâches est la première étape que nous devons franchir.
Conclusion
Après plusieurs échanges académiques intensifs, je sens clairement la confusion dans l'industrie Au moins pour la perception visuelle (reconnaissance), il y a de moins en moins de questions de recherche intéressantes et précieuses, et le seuil est C'est. de plus en plus haut. Si cela continue, il est possible que dans un avenir proche, la recherche de CV s'engage sur la voie de la PNL et se divise progressivement en deux catégories :
Une catégorie utilise d'énormes quantités de ressources informatiques pour la pré-formation et se rafraîchit en permanence. SOTA en vain ; les classes conçoivent constamment des paramètres nouveaux mais dénués de sens pour forcer l'innovation. Ce n’est évidemment pas une bonne chose pour le domaine du CV. Afin d'éviter ce genre de choses, en plus d'explorer constamment la nature de la vision et de créer des indicateurs d'évaluation plus précieux, l'industrie doit également accroître la tolérance, en particulier la tolérance à l'égard des orientations non traditionnelles. Ne vous plaignez pas de l'homogénéité de la recherche. tout en se plaignant de l'homogénéité de la recherche, les soumissions qui n'atteignent pas SOTA sont une plaie. Le goulot d’étranglement actuel constitue un défi auquel tout le monde est confronté si le développement de l’IA stagne, personne ne peut être à l’abri. Merci d'avoir regardé jusqu'à la fin. Discussion amicale bienvenue.
Déclaration de l'auteur
Tout le contenu ne représente que les propres opinions de l'auteur et peut être annulé. Les réimpressions secondaires doivent être accompagnées de la déclaration. Merci!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



 Qu'est-ce que j2ee
Qu'est-ce que j2ee
 Quelles sont les méthodes pour se connecter au serveur vps
Quelles sont les méthodes pour se connecter au serveur vps
 Comment transformer deux pages en un seul document Word
Comment transformer deux pages en un seul document Word
 Comment créer un clone WeChat sur un téléphone mobile Huawei
Comment créer un clone WeChat sur un téléphone mobile Huawei
 Quels sont les moyens de dégager les flotteurs ?
Quels sont les moyens de dégager les flotteurs ?
 largeur de décalage
largeur de décalage
 Que dois-je faire si le disque temporaire ps est plein ?
Que dois-je faire si le disque temporaire ps est plein ?
 Tableau de mots réparti sur plusieurs pages
Tableau de mots réparti sur plusieurs pages








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



