


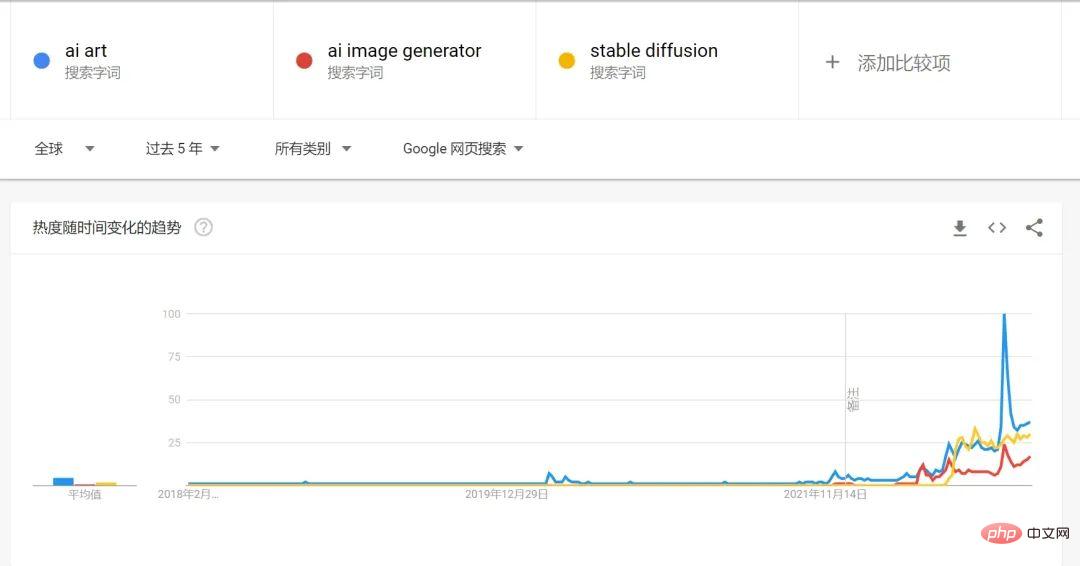
2022 peut certainement être considéré comme la première année de l'AIGC. À en juger par les tendances de recherche sur Google, le volume de recherche pour la peinture IA et l'art généré par l'IA augmentera en 2022.
Une raison très importante de l'explosion de la peinture IA cette année est l'open source de Stable Diffusion, qui est également indissociable du développement rapide du modèle de diffusion ces dernières années, combiné avec OPENAI Le langage de texte déjà développé le modèle GPT-3 facilite le processus de génération du texte aux images.
De sa naissance en 2014 à StyleGAN en 2018, le GAN a fait de grands progrès dans le domaine de la génération d'images. Tout comme les prédateurs et les proies dans la nature rivalisent et évoluent ensemble, le principe du GAN est simplement d'utiliser deux réseaux de neurones : un comme générateur et un comme discriminateur. Le générateur génère différentes images pour que le discriminateur puisse juger si le résultat est qualifié. ou non, les deux s'affrontent pour entraîner le modèle.
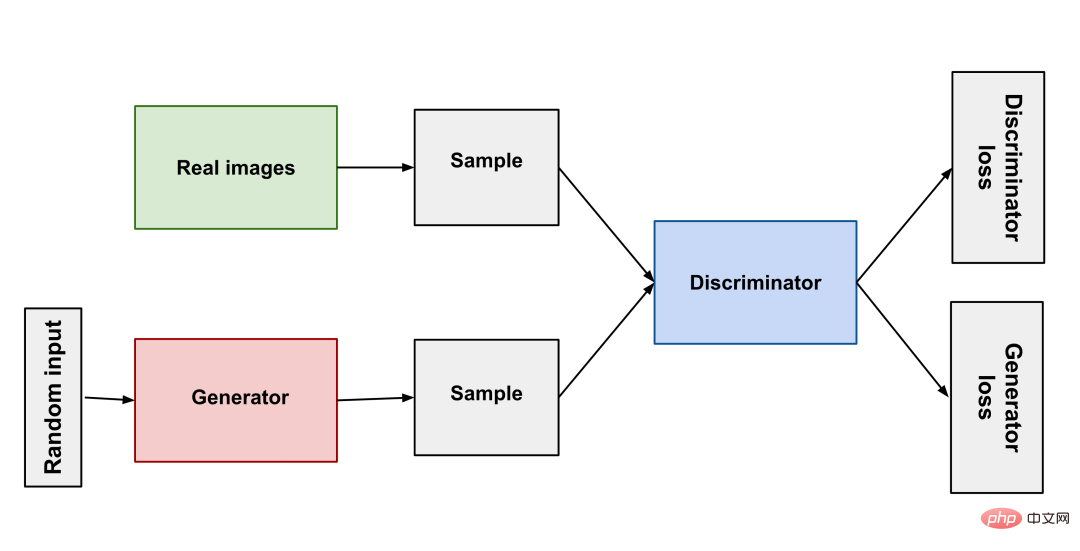
GAN (Generative Adversarial Network) a obtenu de bons résultats grâce à un développement continu, mais il y a certains problèmes qui sont toujours difficiles à surmonter : manque de diversité dans les résultats générés, effondrement du mode (le générateur ne fonctionne pas après avoir trouvé le meilleur mode) Encore mieux), l'entraînement est difficile. Ces difficultés ont rendu difficile la production de produits pratiques par l’art généré par l’IA.
Après des années de goulots d'étranglement dans le GAN, les scientifiques ont mis au point une méthode de modèle de diffusion très magique pour entraîner le modèle : utiliser des chaînes de Markov pour combiner les images originales qui y sont continuellement ajoutées, et finalement, cela devient une image de bruit aléatoire, puis le réseau neuronal d'entraînement est autorisé à inverser ce processus et à restaurer progressivement l'image de bruit aléatoire à l'image d'origine. De cette manière, le réseau neuronal peut générer une image à partir de zéro. Pour générer des images à partir du texte, le texte de description est traité et ajouté sous forme de bruit à l'image d'origine. Cela permet au réseau neuronal de générer des images à partir du texte.

Le modèle de diffusion (modèle de diffusion) facilite la formation du modèle. Il ne nécessite qu'un grand nombre d'images. La qualité des images générées peut également atteindre un niveau très élevé et les résultats générés peuvent être excellents. La diversité est la raison pour laquelle la nouvelle génération d’IA peut avoir une « imagination » incroyable.
Bien sûr, la technologie a fait des percées. La version améliorée de StyleGAN-T lancée par NVIDIA fin janvier a fait des progrès incroyables par rapport à Stable Diffusion, il faut 3 secondes pour générer une image avec la même puissance de calcul. StyleGAN -T ne prend que 0,1 seconde. Et StyleGAN-T est meilleur que le modèle de diffusion dans les images basse résolution, mais dans la génération d'images haute résolution, le modèle de diffusion domine toujours. Étant donné que StyleGAN-T n'est pas aussi largement utilisé que Stable Diffusion, cet article se concentrera sur l'introduction de Stable Diffusion.
Plus tôt cette année, le cercle de la peinture IA a connu une ère de combats entre Disco Diffusion, DALL-E2 et Midjouney. Ce n'est que lorsque Stable Diffusion est devenu open source que la poussière est retombée. une période de temps. En tant que modèle de peinture IA le plus puissant, Stable Diffusion, a provoqué un carnaval dans la communauté IA. Fondamentalement, de nouveaux modèles et de nouvelles bibliothèques open source naissent chaque jour. Surtout après le lancement de la version WebUI d'Auto1111, utiliser Stable Diffusion est devenu très simple, qu'il soit déployé dans le cloud ou localement. Avec le développement continu de la communauté, de nombreux excellents projets, tels que Dreambooth et deforum, sont devenus Stable. Un plug-in pour la version Diffusion WEBUI a été ajouté, permettant de réaliser en un seul arrêt des fonctions telles que la mise au point de modèles et la génération d'animations. 5. Introduction au gameplay et aux capacités de peinture de l'IA introduction (les images suivantes sont utilisées) Sortie du modèle SD1.5)
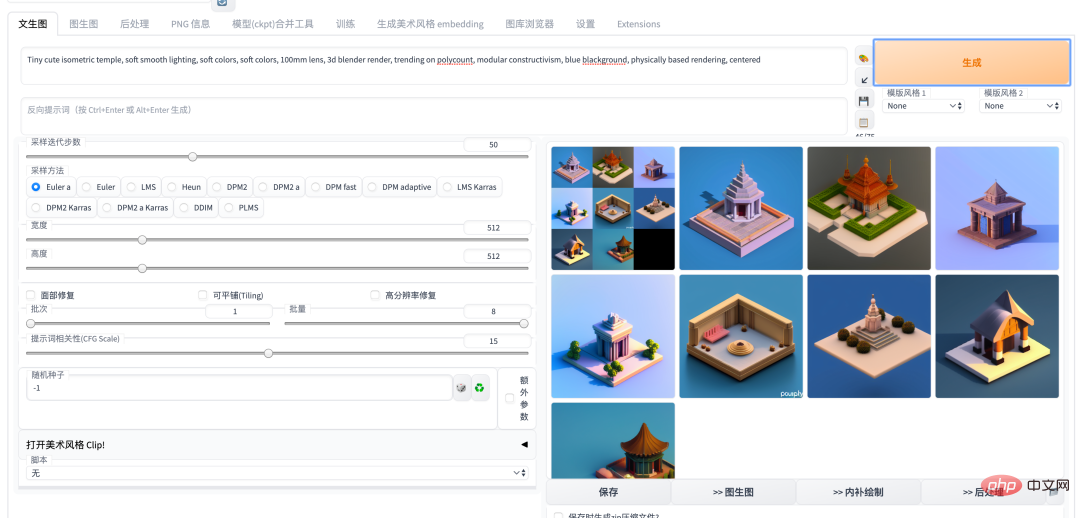
Introduction
Input
Output
text2img
Générez des images via une description textuelle, et vous pouvez spécifier le style de l'artiste et le type d'art via une description textuelle. Voici un exemple dans le style de l’artiste Greg Rutkowski.
une belle fille avec une chemise à fleurs posant pour une photo avec son menton posé sur sa main droite, par Greg Rutkowski


inpainting
Basé sur img2img, en définissant le masque, seul le une zone à l'intérieur du masque est dessinée, ce qui est généralement utilisé pour modifier des mots-clés afin d'affiner l'image.



utilisation DreamBooth est un grand modèle affiné basé sur la formation du modèle SD. Après la formation, le modèle peut utiliser le text2img img2img mentionné ci-dessus et d'autres capacités
NovelAI
text2img
La meilleure animation bidimensionnelle. À l'heure actuelle, NAI est formé sur la base d'images publiques du site Web de Danbooru en tant qu'ensemble de données. Cependant, en raison de problèmes de droits d'auteur sur Danbooru lui-même, NovelAI a été relativement controversé et le modèle a été divulgué par des services commerciaux, alors utilisez-le. avec prudence.
une belle fille avec une chemise à fleurs posant pour une photo avec son menton posé sur sa main droite

NovelAI
img2img
Utilisez le modèle de NovelAI pour img2img. La peinture Yijian AI, qui est actuellement très populaire dans diverses communautés, utilise également cette capacité. Mais Yiyi a mentionné dans la clause de non-responsabilité que leur modèle d'animation avait été formé sur l'ensemble de données collectées.
*La description textuelle de l'exemple de droite est basée sur le contenu de l'image et l'inférence de l'IA. Le style de l'artiste est aléatoire
une belle fille avec une chemise à fleurs posant pour une photo avec son menton posé sur sa main droite.


Modèle de sujet formé sur la base des photos des utilisateurs
Formez un modèle pour le sujet basé sur plusieurs photos fournies par l'utilisateur. Ce modèle peut être utilisé pour générer n'importe quelle image contenant le sujet en fonction de la description.
Cet ensemble d'images utilise 20 photos de collègues pour former un modèle 2000 step-out basé sur le modèle Stable Diffusion 1.5, avec plusieurs sorties d'invite stylisées.
exemple rapide (Figure 1) :
portrait d'Alicepoizon, portrait vfx très détaillé, moteur irréel, greg rutkowski, loish, rhads, caspar david friedrich, makoto shinkai et lois van baarle, ilya kuvshinov, rossdraws, elegent, tom bagshaw , alphonse mucha, illumination globale, environnement détaillé et complexe
*alicepoizon est le nom donné à ce personnage lors de la formation de ce modèle






Scarlett Johansson

Introduction |
Échantillons |
|
De belles images, Douyin, 6pen, Yijian et d'autres sociétés fournissent Le Le service de peinture AI |
offre une expérience de peinture AI plus pratique et vous pouvez utiliser de nombreux grands modèles personnalisés avec différents styles. |
|
midjouney et DallE 2 |
Deux commercialisations AI painting service. Midjouney possède son propre modèle unique avec un degré élevé de productisation ; DallE 2 fournit des services API payants et a des effets de génération de meilleure qualité. |
|
Lensa, Manjing, etc. fournissent des services de formation de modèles personnels |
fourni Le précédent service Dreambooth + Stable Diffusion coûte environ 18 à 25 yuans par fois. Il télécharge 15 à 20 photos d'utilisateurs et génère environ 20 photos artistiques personnalisées. |
|
AI Communauté Open Source Huggingface |
//m.sbmmt.com/link/81d7118d88d5570189ace943bd14f142 La communauté open source grand public actuelle, similaire à github, compte un grand nombre d'utilisateurs qui ont affiné (affiné) Modèles de diffusion stable, qui peuvent être téléchargés et déployés sur votre propre serveur ou ordinateur local. Par exemple, le modèle pix2pix à droite est un modèle de diffusion stable combiné à GPT3, qui peut compléter la fonction d'inpainting mentionnée ci-dessus grâce à une description en langage naturel. |
|
est construite ici en utilisant la puissance de cloud computing fournie par AutoDL. Vous pouvez également utiliser d'autres plateformes telles que Google Colab ou Baidu Fei Paddle.
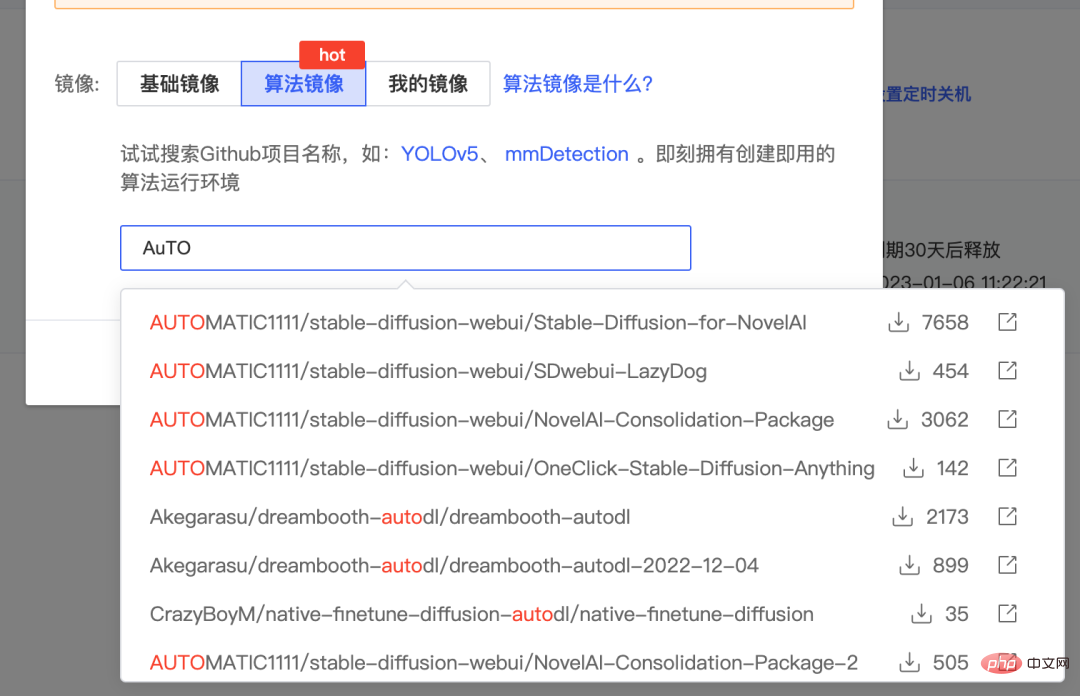

exécutez la commande suivante pour démarrer le service. Si vous rencontrez un espace disque système insuffisant, vous pouvez également déplacer le dossier stable-diffusion-webui/ vers le disque de données et redémarrer autodl-tmp. Si vous rencontrez un échec de démarrage, vous pouvez configurer l'accélération des ressources académiques en fonction de l'emplacement de votre machine.
cd stable-diffusion-webui/ rm -rf outputs && ln -s /root/autodl-tmp outputs python launch.py --disable-safe-unpickle --port=6006 --deepdanbooru
6.2 本地版本
Si vous disposez d'un ordinateur avec une bonne carte graphique, vous pouvez la déployer localement. Voici une introduction à la construction de la version Windows :
Cet article présente des informations pertinentes sur la peinture IA. Les amis intéressés peuvent également déployer le service eux-mêmes et essayer d'apprendre à utiliser DreamBooth ou la dernière version de Lora pour affiner les grands modèles. Je crois qu'en 2023, à mesure que la popularité de l'AIGC continue d'augmenter, notre travail et notre vie apporteront d'énormes changements grâce à l'IA. Le lancement de ChatGPT il y a quelque temps nous a donné un énorme choc. Tout comme la possibilité de rechercher des informations lorsque nous sommes entrés sur Internet, apprendre à utiliser l'IA pour nous aider dans notre travail sera également une capacité très importante à l'avenir.
https://sspai.com/post/76277
https://blog.csdn.net/qq_45848817/article/details/127808815
https://theaisummer. com/diffusion-models/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Utilisation de fixe en langage C
Utilisation de fixe en langage C
 Collection complète d'instructions de requête SQL
Collection complète d'instructions de requête SQL
 Structure de données en langage C
Structure de données en langage C
 Fichier au format DAT
Fichier au format DAT
 Que signifie le wifi désactivé ?
Que signifie le wifi désactivé ?
 La différence entre les pages Web statiques et les pages Web dynamiques
La différence entre les pages Web statiques et les pages Web dynamiques
 La valeur d'entrée Excel est illégale
La valeur d'entrée Excel est illégale
 Quelle monnaie est l'u-coin ?
Quelle monnaie est l'u-coin ?











![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



