


Traducteur | Li Rui
Critique | Sun Shujuan
Le projet de recherche BigScience a récemment publié un grand modèle de langage BLOOM À première vue, cela ressemble à une autre tentative de copier le GPT-3 d'OpenAI.
Mais ce qui distingue BLOOM des autres modèles de langage naturel (LLM) à grande échelle, ce sont ses efforts en matière de recherche, de développement, de formation et de publication de modèles d'apprentissage automatique.
Ces dernières années, les grandes entreprises technologiques ont caché des modèles de langage naturel (LLM) à grande échelle comme des secrets commerciaux strictement gardés, et l'équipe BigScience a mis la transparence et l'ouverture au centre de BLOOM dès le début du projet.
Le résultat est un grand modèle de langage prêt pour la recherche et l'apprentissage, et accessible à tous. Les exemples d'open source et de collaboration ouverte établis par BLOOM seront très bénéfiques pour les recherches futures sur les modèles de langage naturel (LLM) à grande échelle et d'autres domaines de l'intelligence artificielle. Mais il reste encore certains défis inhérents aux grands modèles linguistiques qui doivent être résolus.
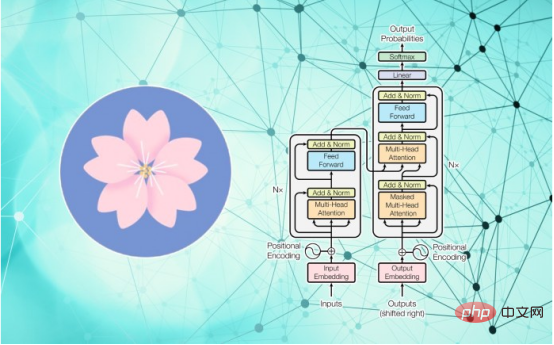
BLOOM est l'abréviation de "BigScience Large-Scale Open Science Open Access Multilingual Model". Du point de vue des données, ce n'est pas très différent de GPT-3 et OPT-175B. Il s'agit d'un très grand modèle Transformer, avec 176 milliards de paramètres, entraînés à l'aide de 1,6 To de données, y compris le langage naturel et le code source du logiciel.
Comme GPT-3, il peut effectuer de nombreuses tâches grâce à un apprentissage sans ou en quelques coups, notamment la génération de texte, le résumé, la réponse aux questions et la programmation.
Mais l'importance de BLOOM réside dans l'organisation et le processus de construction qui se cachent derrière.
BigScience est un projet de recherche lancé en 2021 par le Machine Learning Model Center "Hugging Face". Selon la description de son site Web, le projet « vise à démontrer une manière alternative de créer, d’apprendre et de partager de grands modèles de langage et de grands artefacts de recherche au sein de la communauté de recherche en IA/NLP
À cet égard, BigScience from Europe Inspiration est tirée. d'initiatives scientifiques telles que le Centre de recherche nucléaire (CERN) et le Grand collisionneur de hadrons (LHC), où une collaboration scientifique ouverte facilite la création d'artefacts à grande échelle utiles à l'ensemble de la communauté de recherche.
En un an depuis mai 2021, plus de 1 000 chercheurs de 60 pays et plus de 250 institutions ont co-créé BLOOM dans BigScience.
Alors que la plupart des grands modèles de langage naturel (LLM) à grande échelle sont formés uniquement sur du texte anglais, le corpus de formation de BLOOM comprend 46 langues naturelles et 13 langages de programmation. Ceci est utile dans de nombreuses régions où la langue principale n'est pas l'anglais.
BLOOM brise également la dépendance actuelle aux modèles des grandes entreprises de formation technologique. L’un des principaux problèmes des grands modèles de langage naturel (LLM) est le coût élevé de la formation et du réglage. Cette barrière fait des grands modèles de langage naturel (LLM) comportant 100 milliards de paramètres le domaine exclusif des grandes entreprises technologiques aux poches profondes. Ces dernières années, les laboratoires d’intelligence artificielle ont été attirés par les grandes entreprises technologiques pour obtenir des ressources de cloud computing subventionnées et financer leurs recherches.
En revanche, l'équipe de recherche BigScience a reçu une subvention de 3 millions d'euros du Centre national de la recherche scientifique pour former BLOOM sur le supercalculateur Jean Zay. Il n’existe aucun accord accordant une licence exclusive sur la technologie à une entreprise commerciale, ni aucun engagement de commercialiser le modèle et de le transformer en un produit rentable.
De plus, l'équipe BigScience est totalement transparente sur l'ensemble du processus de formation des modèles. Ils publient des ensembles de données, des transcriptions de réunions, des discussions et du code, ainsi que des journaux et des détails techniques des modèles de formation.
Les chercheurs étudient les données et métadonnées du modèle et publient des résultats intéressants.
Par exemple, le chercheur David McClure a tweeté le 12 juillet 2022 : « J'ai examiné l'ensemble de données d'entraînement derrière le modèle BLOOM vraiment cool de Bigscience et Hugging Face. Il existe un ensemble de données du corpus anglais de 10 millions d'échantillons, soit environ 1,25. % du total, codé avec 'all-distilroberta-v1', puis UMAP en 2d. "
Bien sûr, le modèle formé lui-même peut être téléchargé sur la plateforme Hugging Face, ce qui atténue ce problème. Les chercheurs ont dépensé des millions de dollars en formation.
Facebook a open source l'un de ses modèles de langage naturel à grande échelle (LLM) sous certaines restrictions le mois dernier. Cependant, la transparence apportée par BLOOM est sans précédent et promet d'établir une nouvelle norme pour l'industrie.
Teven LeScao, co-responsable de la formation BLOOM, a déclaré : « Contrairement au secret des laboratoires de recherche industriels en IA, BLOOM démontre que les modèles d'IA les plus puissants peuvent être formés de manière responsable et ouverte par la communauté de recherche au sens large et diffusés. . »
Bien que les efforts de BigScience pour apporter ouverture et transparence à la recherche sur l'IA et aux modèles de langage à grande échelle soient louables, les défis inhérents au domaine restent inchangés.
La recherche sur les modèles de langage naturel (LLM) à grande échelle s'oriente vers des modèles de plus en plus grands, ce qui augmentera encore les coûts de formation et de fonctionnement. BLOOM utilise 384 GPU Nvidia Tesla A100 (au prix d'environ 32 000 $ chacun) pour la formation. Et les modèles plus grands nécessiteront des clusters informatiques plus grands. L'équipe BigScience a annoncé qu'elle continuerait à créer d'autres grands modèles de langage naturel (LLM) open source, mais il reste à voir comment l'équipe financera ses recherches de plus en plus coûteuses. Par exemple, OpenAI a commencé comme une organisation à but non lucratif, puis est devenue une organisation à but lucratif qui vend des produits et dépend du financement de Microsoft.
Un autre problème à résoudre est le coût énorme de fonctionnement de ces modèles. Le modèle BLOOM compressé a une taille de 227 Go et son exécution nécessite un matériel spécialisé avec des centaines de Go de mémoire. À titre de comparaison, GPT-3 nécessite un cluster informatique équivalent à un Nvidia DGX 2, qui coûte environ 400 000 dollars. Hugging Face prévoit de lancer une plate-forme API qui permettra aux chercheurs d'utiliser le modèle pour environ 40 dollars de l'heure, ce qui représente un coût important.
Le coût de fonctionnement de BLOOM aura également un impact sur la communauté de l'apprentissage automatique appliqué, les startups et les organisations cherchant à créer des produits alimentés par de grands modèles de langage naturel (LLM). Actuellement, l'API GPT-3 fournie par OpenAI est plus adaptée au développement de produits. Il sera intéressant de voir quelle direction prendront BigScience et Hugging Face pour permettre aux développeurs de créer des produits basés sur leurs précieuses recherches.
À cet égard, on s’attend à des versions plus petites des modèles de BigScience dans les prochaines versions. Contrairement à ce qui est souvent présenté dans les médias, les grands modèles de langage naturel (LLM) adhèrent toujours au principe du « pas de repas gratuit ». Cela signifie que lors de l’application du machine learning, un modèle plus compact et affiné pour une tâche spécifique est plus efficace qu’un très grand modèle avec des performances moyennes sur de nombreuses tâches. Par exemple, Codex est une version modifiée de GPT-3 qui fournit une grande aide à la programmation pour une fraction de la taille et du coût de GPT-3. GitHub propose actuellement un produit basé sur le Codex, Copilot, pour 10 $ par mois.
Il sera intéressant d’examiner où ira l’IA académique et appliquée à l’avenir, alors que la nouvelle culture que BLOOM espère construire.
Titre original : BLOOM peut établir une nouvelle culture pour la recherche sur l'IA, mais des défis demeurent, auteur : Ben Dickson
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Formules de permutation et de combinaison couramment utilisées
Formules de permutation et de combinaison couramment utilisées
 Tutoriel de modification du logiciel C++ en chinois
Tutoriel de modification du logiciel C++ en chinois
 Solution d'erreur SQL 5120
Solution d'erreur SQL 5120
 Comment télécharger Binance
Comment télécharger Binance
 Qu'est-ce qu'Avalanche
Qu'est-ce qu'Avalanche
 La différence entre ancrer et viser
La différence entre ancrer et viser








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



